本文以MySQL分库分表实时写入Hologres场景为例,为您介绍如何通过数据集成同步分库分表数据至Hologres。
前提条件
- 已完成Hologres和MySql数据源配置。您需要将数据库添加至DataWorks上,以便在同步任务配置时,可通过选择数据源名称来控制同步读取和写入的数据库。本实践中创建的数据源名为
doc_mysql1,详情请参见配置MySQL数据源、配置Hologres数据源。说明 数据源相关能力介绍详情请参见:数据源概述。 - 已购买合适规格的独享数据集成资源组。详情请参见:新增和使用独享数据集成资源组。
- 已完成独享数据集成资源组与数据源的网络连通。详情请参见:配置资源组与网络连通。
- 已完成数据源环境准备。
- Hologres:本实践需要在目标端创建Schema,所以您需要先授权数据源配置账号在Hologres创建Schema的权限,详情请参见Hologres权限模型概述。
- MySQL:来源数据源为MySQL时,您需要开启Binlog相关功能,详情请参见MySQL环境准备。
背景信息
实际业务场景下数据同步通常不能通过一个或多个简单离线同步或者实时同步任务完成,而是由多个离线同步、实时同步和数据处理等任务组合完成,这就会导致数据同步场景下的配置复杂度非常高。尤其是在MySQL分库分表的场景下,上游的数据库和表非常多,都需要同时写入一张Hologres表,如果同时配置多个任务会导致配置非常复杂且运维困难。
针对以上痛点,DataWorks数据集成一键同步解决方案提供了面向业务场景的同步任务配置化方案,支持不同数据源的一键同步功能,方便业务简单快速的进行数据同步。
注意事项
同步数据至Hologres时,目前仅支持将数据写入分区表子表,暂不支持写入数据至分区表父表。
需求分析
- 场景描述:MySQL实例有三个分库分表数据库
order_db01、order_db02、order_db03。业务上有两种逻辑表:订单表t_order和用户表t_user,其中每张逻辑表分别对应三个数据库下的两张物理表。如下图所示总共3个物理库,12张分表,分表分别对应两种逻辑表。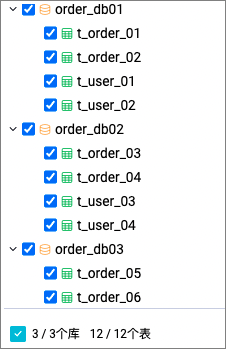 现在需要将这12张分库分表的历史全量数据一次性迁移到Hologres对应的逻辑表中,并且后续能够实时增量写入,以满足用户实时数仓数据分析等需求。
现在需要将这12张分库分表的历史全量数据一次性迁移到Hologres对应的逻辑表中,并且后续能够实时增量写入,以满足用户实时数仓数据分析等需求。同时,为了便于在Hologres表里区分某条记录属于源端哪个物理库、物理表,则需要在Hologres表中添加上三个附加字段(src_datasource、src_database、src_table),标识某条记录的来源数据源实例、数据库以及表,这三个附加字段和物理表中的主键在Hologres里构成了唯一键,保障了某条物理表记录在Hologres逻辑表里的唯一性,全量数据迁移以及实时增量数据写入时均需要对这三个附加字段赋值。
- 需求汇总:
- 数据:将MySQL全量数据一次性同步至Hologres,增量数据后续实时写入目标端。
- 表:将源端分表数据写入目标单表,并为写入的Hologres表添加统一前缀。
- 将分表数据写入目标单表:将源表满足
t_order.*正则表达式的表数据写入到Hologres名为t_order的表中,所有满足t_user.*正则表达式的表数据写入到Hologres名为t_user的表中。 - 为表加上统一前缀:在目标名前统一加上
cdo_前缀。
- 将分表数据写入目标单表:将源表满足
- schema:需要将源端所有满足
order_db.*正则表达式的库写入目标Hologres名为order_db的schema中。 - 字段:目标表在原有表结构基础上,增加src_datasource、src_database、src_table字段用于记录源端表数据来源。
源端分库 源端待同步表 写入的目标表 目标表新增字段 order_db01 t_order_01 cdo_t_order src_datasource
src_database
src_table
t_order_02 t_user_01 cdo_t_user t_user_02 order_db02 t_order_03 cdo_t_order t_order_04 t_user_03 cdo_t_user t_user_04 order_db03 t_order_05 cdo_t_order t_order_06 t_user_05 cdo_t_user t_user_06
操作流程
步骤一:选择同步方案
创建同步解决方案任务,选择需要同步的源端数据源MySQL,目标端数据源Hologres,并选择一键实时同步至Hologres方案。
步骤二:配置网络连通
源端选择已创建的数据源doc_mysql1,目标数据源为DataWorks工作空间引擎绑定的默认Hologres数据源。并测试连通性。步骤三:设置同步来源与规则
- 在基本配置区域,配置同步解决方案的名称、任务存放位置等信息。
- 在数据来源区域,确认需要同步的源端数据源相关信息。
- 在选择同步的源表区域,选中需要同步的源表,单击
 图标,将其移动至已选源表。
图标,将其移动至已选源表。该区域会为您展示所选数据源下所有的表,您可以选择整库全表或部分表进行同步。
- 在设置表(库)名的映射规则区域,单击添加规则,选择相应的规则进行添加。同步时默认将源端数据表写入目的端同名schema或同名表中,同时,您可以通过添加映射规则定义最终写入目的端的schema或表名称,实现将多张表数据写入到同一个目标表中,或统一将源端某固定前缀的表名在写入目标表时更新为其他前缀。支持通过正则表达式转换写入的schema名或表名,还支持使用内置变量拼接目标表名。配置逻辑请参见:设置同步来源与规则。在本实践中,我们需要将MySQL数据库中的12张分库分表写入对应的两张Hologres表中。设置表(库)名映射规则如下:
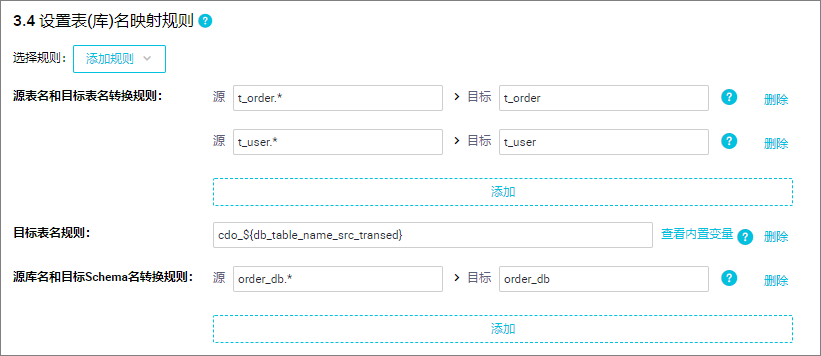
- 源表名和目标表名转换规则:支持将源表名通过正则表达式转换为目标表名。
如上图所示设置源为要搜索的字符串
t_order.*,将源表所有满足t_order.*正则表达式的表数据写入到Hologres名为t_order表中;所有满足t_user.*正则表达式的源表写入到Hologres名为t_user表中。 - 目标表名规则:支持您使用内置的变量组合生成目标表名,同时,对转换后的目标表名支持添加前缀和后缀。如上图所示为源表名和目标表名转换规则转换后的表名前统一加上
cdo_前缀。 - 源表名和目标Schema名转换规则:若要将多个物理库实时写入一个目标Schema中,您需要将物理库和目标schema进行转换(默认源库写入目标同名schema)。如上图所示将所有满足
order_db.*正则表达式的源库写入目标Hologres名为order_db的schema中。
- 源表名和目标表名转换规则:支持将源表名通过正则表达式转换为目标表名。
步骤四:设置目标表
- 确认写入Hologres的策略。写入Hologres策略目前仅支持重放,重放表示镜像功能,即源端INSERT一条记录,Hologres中也INSERT一条记录;源端执行UPDATE或DELETE操作,Hologres中也进行UPDATE或DELETE。
- 刷新源表和Hologres表映射。单击刷新源表和Hologres表映射,将根据您在步骤三配置的目标表映射规则来生成目标表,若步骤三未配置映射规则,将默认写入与源表同名的目标表,若目标端不存在该同名表,将默认新建。同时,您可以修改表建立方式、为目标表在源有表字段基础上增加附加字段。该步骤数据集成会自动拉取要同步的源表表结构,并按照表(库)名转换规则将其自动映射到目标Hologres表。单击刷新源表和Hologres表映射,结果如下:
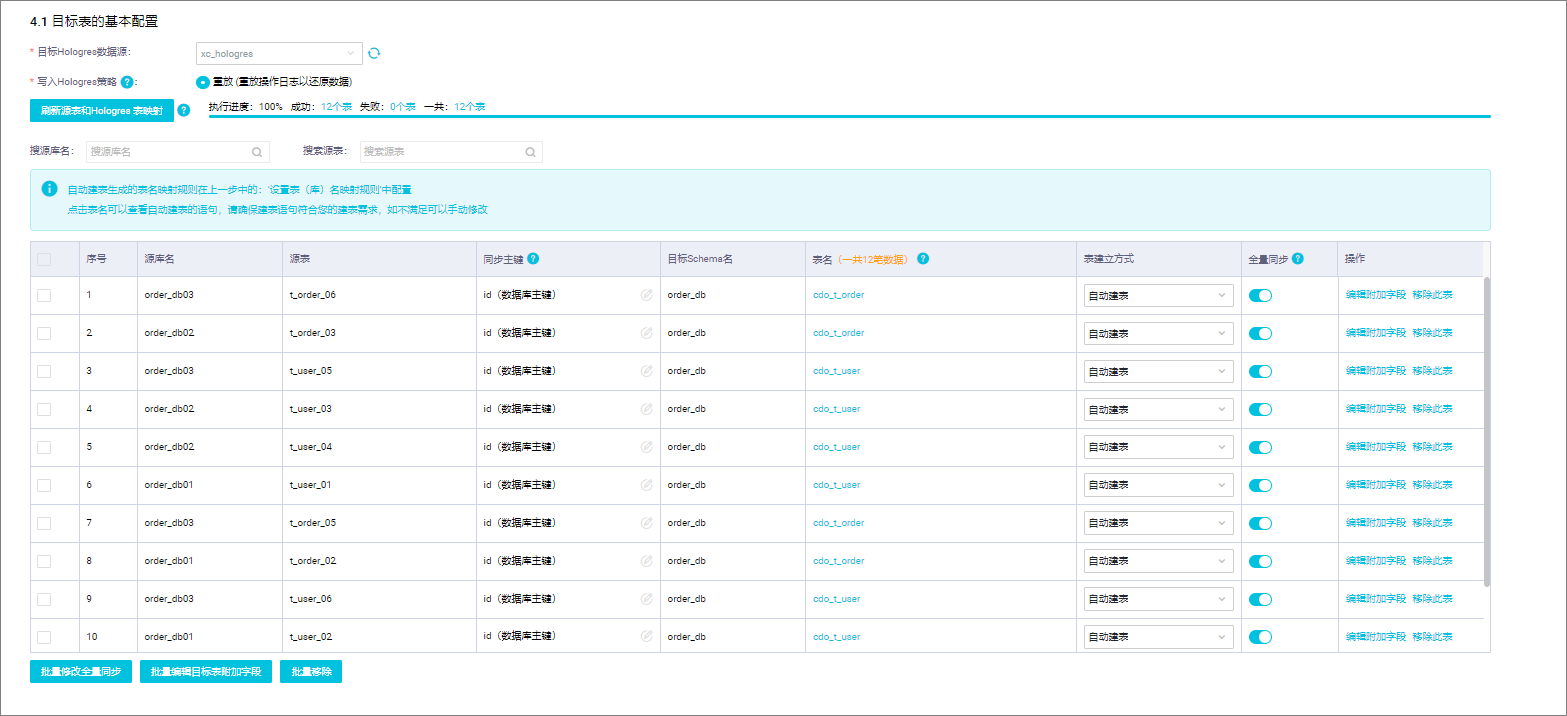
- 批量添加附加字段。为了更好的区分上游表的来源,需要为目标表添加附加字段。
- 勾选所有的任务,并单击批量编辑目标表附加字段。说明 仅在表建立方式为自动建表时,可以使用此功能。
- 在批量编辑目标表附加字段弹窗,单击新增字段,新增src_datasource、src_database和src_table三个字段。并为字段赋值。
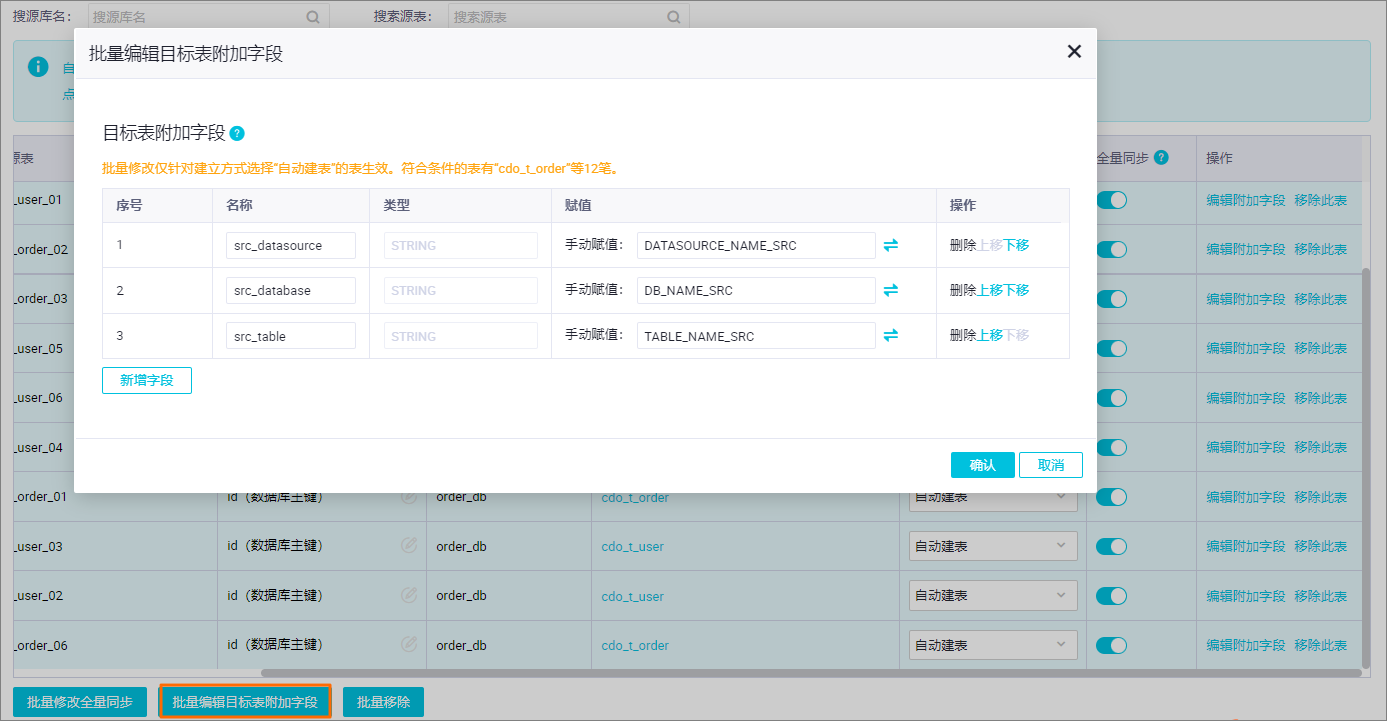 说明数据集成附加字段支持的变量字段如下:
说明数据集成附加字段支持的变量字段如下:EXECUTE_TIME:执行时间 UPDATE_TIME:更新时间 DB_NAME_SRC:原始数据库名称 DB_NAME_SRC_TRANSED:转换后数据库名称 DATASOURCE_NAME_SRC:源端数据源名称 DATASOURCE_NAME_DEST:目的端数据源名称 DB_NAME_DEST:目的端数据库名称 TABLE_NAME_DEST:目的端表名称 TABLE_NAME_SRC:源端表名称
- 勾选所有的任务,并单击批量编辑目标表附加字段。
步骤五:设置表粒度同步规则
即当源表发生插入、更新、删除时,您可以在此处定义对应的处理策略。- 正常处理:源端DML消息将会继续下发给目标数据源,由目标数据源来处理。
- 忽略:直接丢弃该消息,不再向目标数据源发送对应的DML消息,对应数据不会改变。
- 有条件的正常处理:选择后,您可以配置过滤条件,同步任务将按照您配置的过滤表达式对源端数据进行过滤,满足过滤条件的数据会被正常处理,不满足的会被忽略掉。
步骤六:DDL消息处理规则
来源数据源会包含许多DDL操作,数据集成体提供默认处理策略,您也可以根据业务需求,对不同的DDL消息设置同步至目标端的处理策略。不同DDL消息处理策略请参见:DDL消息处理规则。
步骤七:运行资源设置
当前方案创建后将分别生成全量数据离线同步子任务和增量数据实时同步子任务。您需要在运行资源设置界面配置离线同步任务和实时同步任务的相关属性。
包括实时增量同步及离线全量同步使用的独享数据集成资源组,同时,单击高级配置可配置是否容忍脏数据、任务最大并发数、源库允许支持的最大连接数等参数。
- DataWorks的离线同步任务通过调度资源组将其下发到数据集成任务执行资源组上执行,所以离线同步任务除了涉及数据集成任务执行资源组外,还会占用调度资源组资源。如果使用了独享调度资源组,将会产生调度实例费用。您可通过任务下发机制对该机制进行了解。
- 离线和实时同步任务推荐使用不同的资源组,以便任务分开执行。如果选择同一个资源组,任务混跑会带来资源抢占、运行态互相影响等问题。例如,CPU、内存、网络等互相影响,可能会导致离线任务变慢或实时任务延迟等问题,甚至在资源不足的极端情况下,可能会出现任务被OOM KILLER杀掉等问题。
步骤八:执行同步任务
- 进入界面,找到已创建的同步方案。
- 单击操作列的提交执行按钮,启动同步的运行。
- 单击操作列的执行详情,查看任务的详细执行过程。