
AHPA可以根据从Prometheus Adapter获取到的GPU利用率数据,结合历史负载趋势和预测算法,提前预估未来的GPU资源需求,并自动调整Pod副本数量或者GPU资源分配,确保在GPU资源紧张前完成扩容操作,而在资源闲置时及时缩容,从而达到节省成本和提高集群效率的目标。
前提条件
已创建托管GPU集群。具体操作,请参见创建GPU集群。
已安装AHPA组件,并配置相关指标源。具体操作,请参见弹性伸缩预测(AHPA)。
已开启Prometheus监控,且Prometheus监控中至少已收集7天应用历史数据(GPU)。具体操作,请参见使用阿里云Prometheus监控。
原理介绍
在高性能计算领域,特别是深度学习模型训练和推理中,精细化管理和动态调整GPU资源可以提升资源利用率并降低成本。容器服务 Kubernetes 版支持基于GPU指标进行弹性伸缩。您可以使用Prometheus采集GPU的实时利用率和显存使用情况等关键指标。然后,通过Prometheus Adapter将这些指标转换为Kubernetes可识别的metrics格式,并与AHPA集成。AHPA根据这些数据,结合历史负载趋势和预测算法,预估未来的GPU资源需求,自动调整Pod副本数量或GPU资源分配,确保在资源紧张前完成扩容,在资源闲置时及时缩容,从而节省成本并提高集群效率。
步骤一:部署Metrics Adapter
获取HTTP API的内网地址。
登录ARMS控制台。
在左侧导航栏选择,进入可观测监控 Prometheus 版的实例列表页面。
在实例列表页面顶部,选择容器服务K8s集群所在的地域。
单击目标Prometheus实例名称,然后在左侧导航栏单击设置,获取HTTP API地址下的内网地址。
部署ack-alibaba-cloud-metrics-adapter。
步骤二:基于GPU指标实现AHPA弹性预测
本文通过在GPU上部署一个模型推理服务,然后对其进行持续请求访问,根据GPU利用率进行AHPA弹性预测。
部署推理服务。
执行以下命令,部署推理服务。
执行以下命令,查看Pod状态。
kubectl get pods -o wide预期输出:
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES bert-intent-detection-7b486f6bf-f**** 1/1 Running 0 3m24s 10.15.1.17 cn-beijing.192.168.94.107 <none> <none>执行以下命令,调用推理服务,验证部署是否成功。
您可以通过
kubectl get svc bert-intent-detection-svc命令获取GPU节点的IP地址,替换如下命令中的47.95.XX.XX。curl -v "http://47.95.XX.XX/predict?query=Music"预期输出:
* Trying 47.95.XX.XX... * TCP_NODELAY set * Connected to 47.95.XX.XX (47.95.XX.XX) port 80 (#0) > GET /predict?query=Music HTTP/1.1 > Host: 47.95.XX.XX > User-Agent: curl/7.64.1 > Accept: */* > * HTTP 1.0, assume close after body < HTTP/1.0 200 OK < Content-Type: text/html; charset=utf-8 < Content-Length: 9 < Server: Werkzeug/1.0.1 Python/3.6.9 < Date: Wed, 16 Feb 2022 03:52:11 GMT < * Closing connection 0 PlayMusic #意图识别结果。当HTTP请求返回状态码
200和意图识别结果,说明推理服务部署成功。
配置AHPA。
本文以GPU利用率为例,当Pod的GPU利用率大于20%时,触发扩容。
配置AHPA指标源。
使用以下内容,创建application-intelligence.yaml文件。
prometheusUrl用于设置阿里云Prometheus的访问地址,值为步骤1获取的内网地址。apiVersion: v1 kind: ConfigMap metadata: name: application-intelligence namespace: kube-system data: prometheusUrl: "http://cn-shanghai-intranet.arms.aliyuncs.com:9090/api/v1/prometheus/da9d7dece901db4c9fc7f5b*******/1581204543170*****/c54417d182c6d430fb062ec364e****/cn-shanghai"执行以下命令,部署application-intelligence。
kubectl apply -f application-intelligence.yaml
部署AHPA。
使用以下内容,创建fib-gpu.yaml文件。
此处设置为
observer观察模式,关于参数的更多信息,请参见参数说明。执行以下命令,部署AHPA。
kubectl apply -f fib-gpu.yaml执行以下命令,查看AHPA状态。
kubectl get ahpa预期输出:
NAME STRATEGY REFERENCE METRIC TARGET(%) CURRENT(%) DESIREDPODS REPLICAS MINPODS MAXPODS AGE fib-gpu observer bert-intent-detection gpu 20 0 0 1 10 50 6d19h由预期输出得到,
CURRENT(%)为0,TARGET(%)为20。说明当前GPU利用率是0%,当GPU利用率超过20%时触发弹性扩容。
测试推理服务弹性伸缩。
执行以下命令,对推理服务进行访问。
访问过程中,执行以下命令,查看AHPA的状态。
kubectl get ahpa预期输出:
NAME STRATEGY REFERENCE METRIC TARGET(%) CURRENT(%) DESIREDPODS REPLICAS MINPODS MAXPODS AGE fib-gpu observer bert-intent-detection gpu 20 189 10 4 10 50 6d19h由预期输出得到,当前GPU利用率
CURRENT(%)已超过TARGET(%)的值,触发弹性伸缩,期望的Pod数DESIREDPODS为10。执行以下命令,查看预测效果趋势。
kubectl get --raw '/apis/metrics.alibabacloud.com/v1beta1/namespaces/default/predictionsobserver/fib-gpu'|jq -r '.content' |base64 -d > observer.html基于历史7天的GPU指标数据预测的GPU趋势示例结果如下:
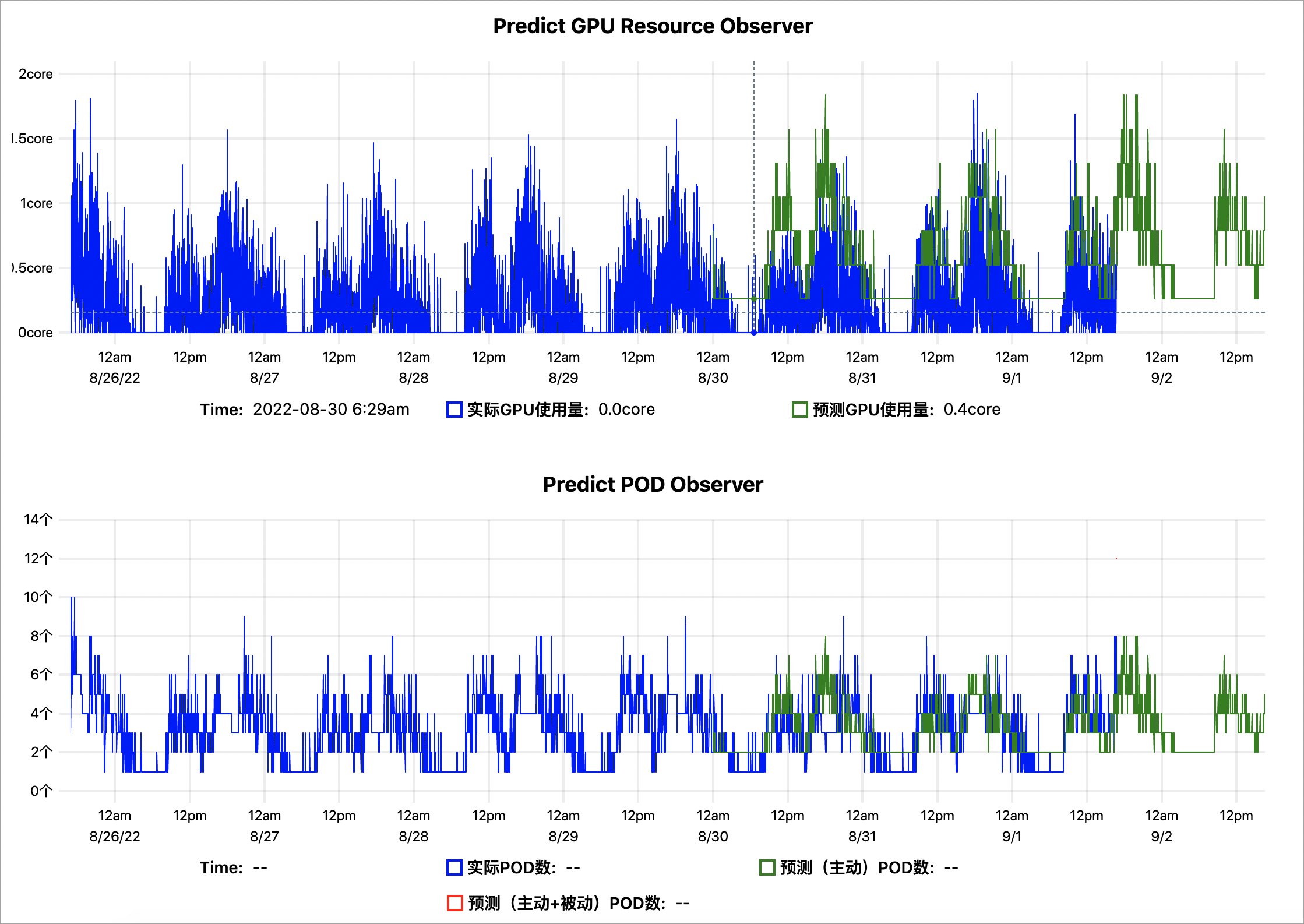
Predict GPU Resource Observer:蓝色表示实际的GPU使用量,绿色表示AHPA预测出来的GPU使用量。绿色曲线大部分均大于蓝色,表明预测的GPU容量相对充足。
Predict POD Oberserver:蓝色表示使用实际的扩缩容Pod数,绿色表示AHPA预测出来的扩缩容Pod数,绿色曲线大部分均小于蓝色,表明预测的Pod数量更少。您可以将弹性伸缩模式设置为
auto,以预测的Pod数进行设置,为您节省更多的Pod资源,避免资源的浪费。
通过预测结果表明,弹性预测趋势符合预期。若经过观察后,符合预期,您可以将弹性伸缩模式设置为
auto,由AHPA负责扩缩容。
相关文档
Knative Serverless支持AHPA(Advanced Horizontal Pod Autoscaler)的弹性能力,当应用所需资源具备周期性时,可通过弹性预测,预热资源,解决您在使用Knative中遇到的冷启动问题。详细信息,请参见在Knative中使用AHPA弹性预测。
很多场景中需要根据自定义指标(例如HTTP请求的QPS、消息队列的长度等)对应用进行扩缩容。AHPA提供了External Metrics机制,结合alibaba-cloud-metrics-adapter组件,可以为应用提供更加丰富的扩缩机制。详细信息,请参见通过AHPA配置自定义指标以实现应用扩缩。