PolarDB PostgreSQL版是一款阿里云自主研发的企业级数据库产品,采用计算存储分离架构,兼容PostgreSQL与Oracle。PolarDB PostgreSQL版的存储与计算能力均可横向扩展,具有高可靠、高可用、弹性扩展等企业级数据库特性。同时,PolarDB PostgreSQL版具有大规模并行计算能力,可以应对OLTP与OLAP混合负载。还具有时空、向量、搜索、图谱等多模创新特性,可以满足企业对数据处理日新月异的新需求。
本文通过以下几个方面介绍PolarDB PostgreSQL版的架构:
传统数据库的问题
随着用户业务数据量越来越大,业务越来越复杂,传统数据库系统面临巨大挑战,例如:
存储空间无法超过单机上限。
通过只读实例进行读扩展,每个只读实例独享一份存储,成本增加。
随着数据量增加,创建只读实例的耗时增加。
主备延迟高。
PolarDB PostgreSQL版云原生数据库的优势
针对上述传统数据库的问题,阿里云研发了PolarDB PostgreSQL版云原生数据库。采用了自主研发的计算集群和存储集群分离的架构。具备如下优势:
扩展性:存储计算分离,极致弹性。
成本:共享一份数据,存储成本低。
易用性:一写多读,透明读写分离。
可靠性:三副本、秒级备份。
PolarDB PostgreSQL版整体架构概述
存储计算分离架构概述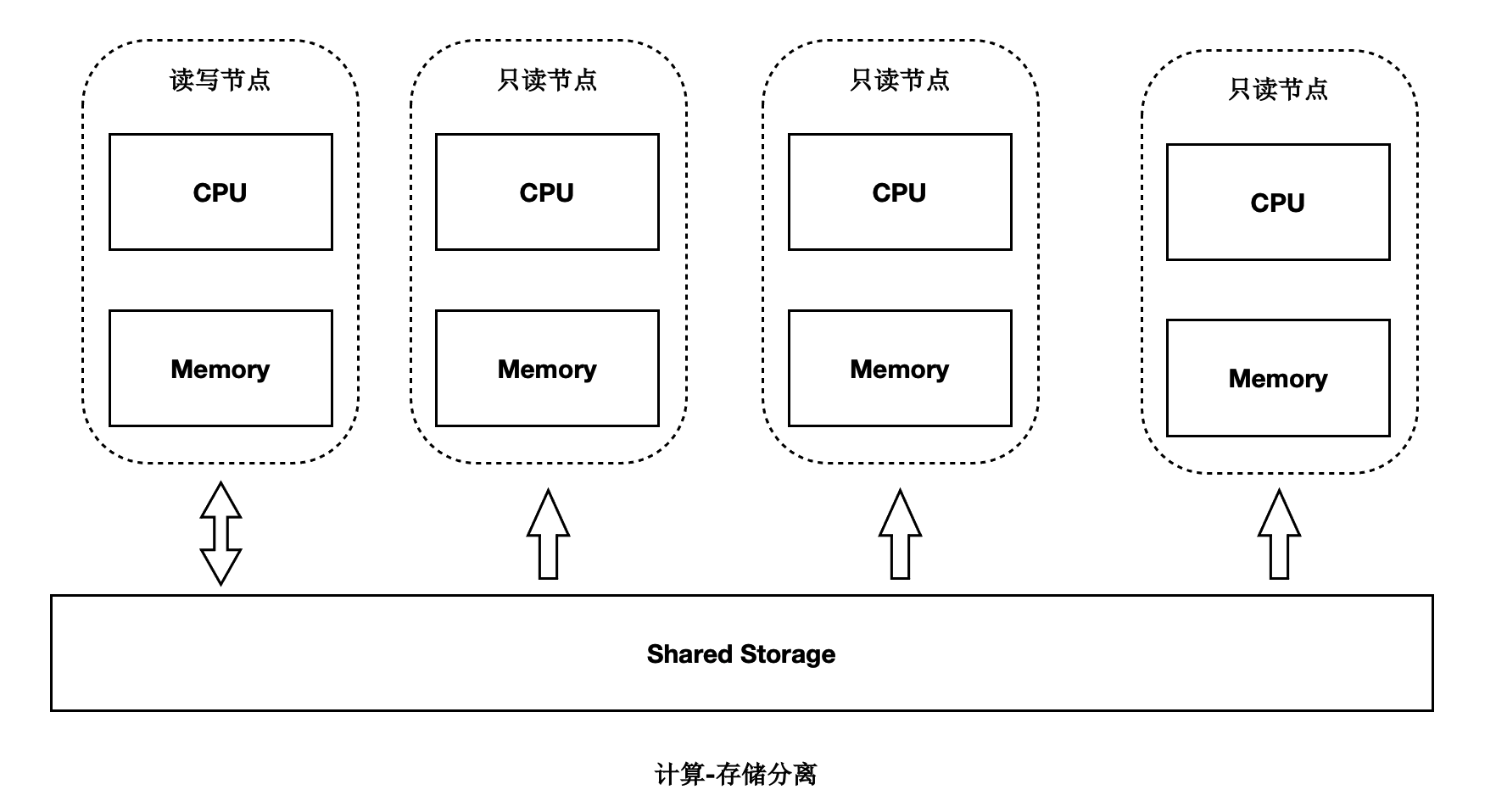
PolarDB PostgreSQL版是存储计算分离的设计,存储集群和计算集群可以分别独立扩展:
当计算能力不够时,可以单独扩展计算集群。
当存储容量不够时,可以单独扩展存储集群。
基于Shared-Storage,主节点和多个只读节点共享一份存储数据,主节点刷脏不能再按照传统的刷脏方式,否则会导致以下问题:
只读节点在存储中读取的页面,可能是比较老的版本,不符合当前的状态。
只读节点读取到的页面比自身内存中想要的数据要超前。
主节点切换到只读节点时,只读节点接管数据更新时,存储中的页面可能是旧的,需要读取日志重新对脏页的恢复。
对于第一个问题,我们需要有页面多版本能力;对于第二个问题,我们需要主库控制脏页的刷脏速度。
HTAP架构概述
读写分离后,单个计算节点无法发挥出存储侧大IO带宽的优势,也无法通过增加计算资源来加速大的查询。PolarDB PostgreSQL版推出了基于Shared-Storage的MPP分布式并行执行,来加速在OLTP场景下OLAP查询。
PolarDB PostgreSQL版支持一套OLTP场景型的数据在以下两种计算引擎中使用:
单机执行引擎:处理高并发的OLTP型负载。
分布式执行引擎:处理大查询的OLAP型负载。
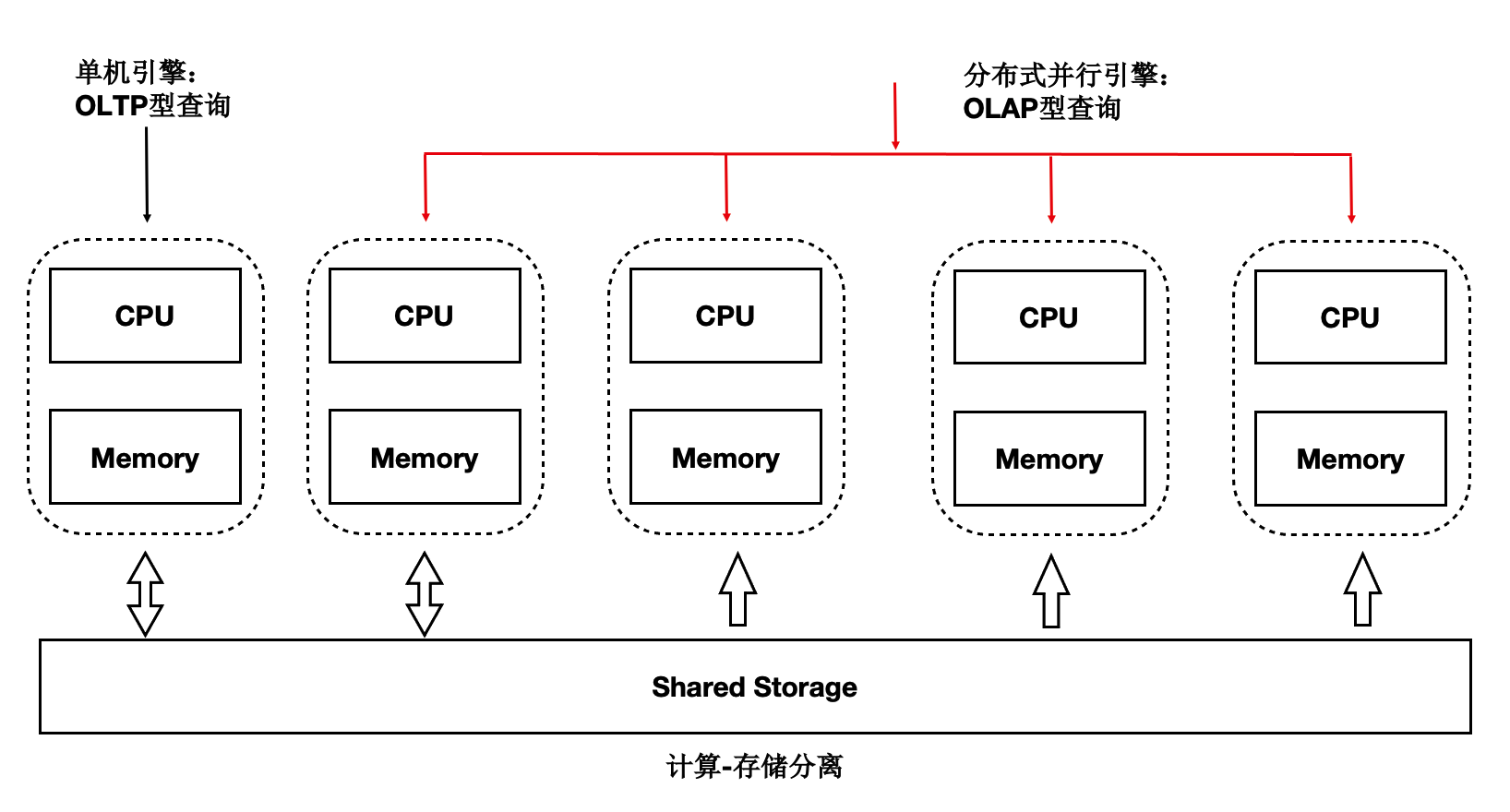 在使用相同的硬件资源时性能达到了传统MPP数仓的90%,同时具备了SQL级别的弹性:在计算能力不足时,可随时增加参与OLAP分析查询的CPU,而数据无需重分布。
在使用相同的硬件资源时性能达到了传统MPP数仓的90%,同时具备了SQL级别的弹性:在计算能力不足时,可随时增加参与OLAP分析查询的CPU,而数据无需重分布。
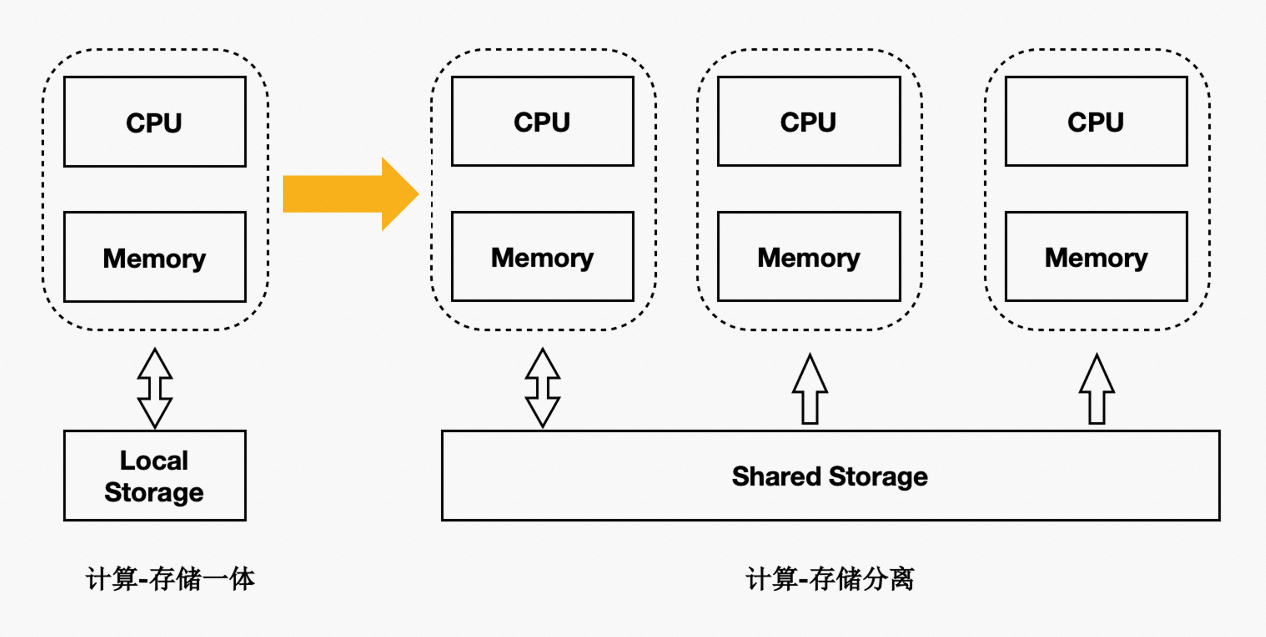
PolarDB PostgreSQL版:存储计算分离架构详解
Shared-Storage带来的挑战
基于Shared-Storage,数据库由传统的share nothing,转变成了Shared-Storage架构。需要解决以下问题:
数据一致性:由原来的N份计算+N份存储,转变成了N份计算+1份存储。
读写分离:如何基于新架构做到低延迟的复制。
高可用:如何Recovery和Failover。
IO模型:如何从Buffer-IO向Direct-IO优化。
架构原理
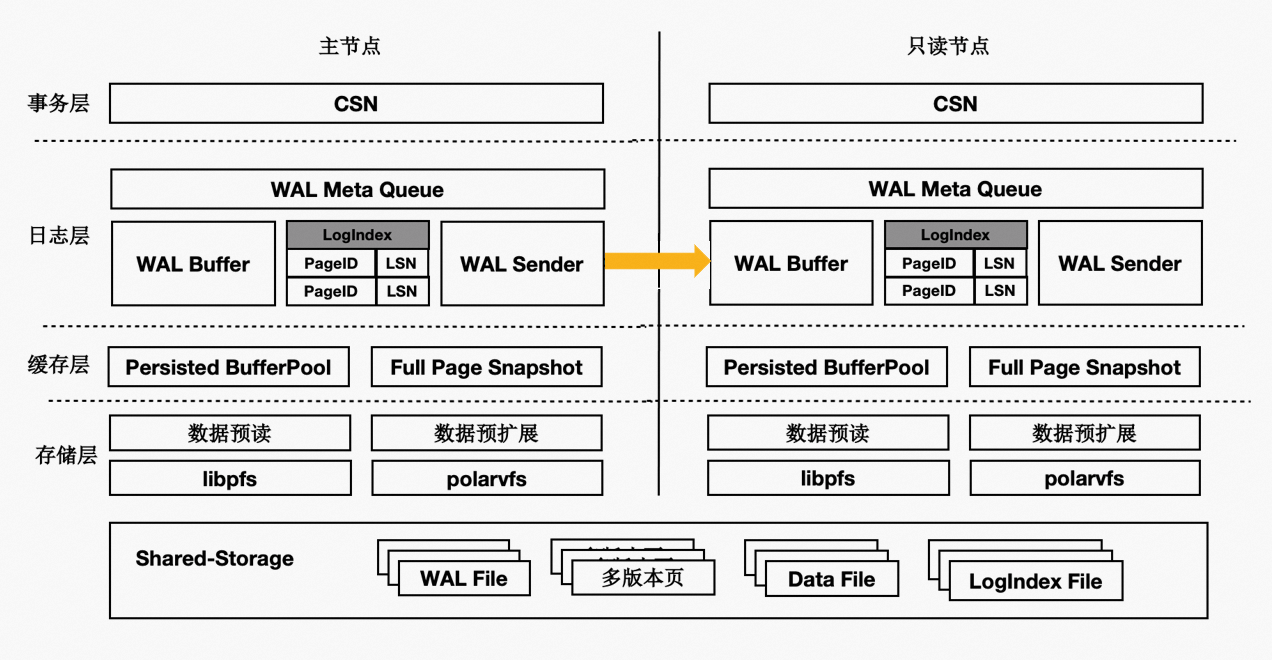 基于Shared-Storage的PolarDB PostgreSQL版的架构原理如下:
基于Shared-Storage的PolarDB PostgreSQL版的架构原理如下:
主节点为可读可写节点(RW),只读节点为只读(RO)。
Shared-Storage层,只有主节点能写入,因此主节点和只读节点能看到一致的落盘的数据。
只读节点的内存状态是通过回放WAL保持和主节点同步的。
主节点的WAL日志写到Shared-Storage,仅复制WAL的meta给只读节点。
只读节点从Shared-Storage上读取WAL并回放。
数据一致性
传统数据库的内存状态同步
传统share nothing的数据库,主节点和只读节点都有各自的内存和存储,只需要从主节点复制WAL日志到只读节点,并在只读节点上依次回放日志即可,这也是复制状态机的基本原理。
基于Shared-Storage的内存状态同步
存储计算分离后,Shared-Storage上读取到的页面是一致的,内存状态是通过从Shared-Storage上读取最新的WAL并回放得来,如下图所示: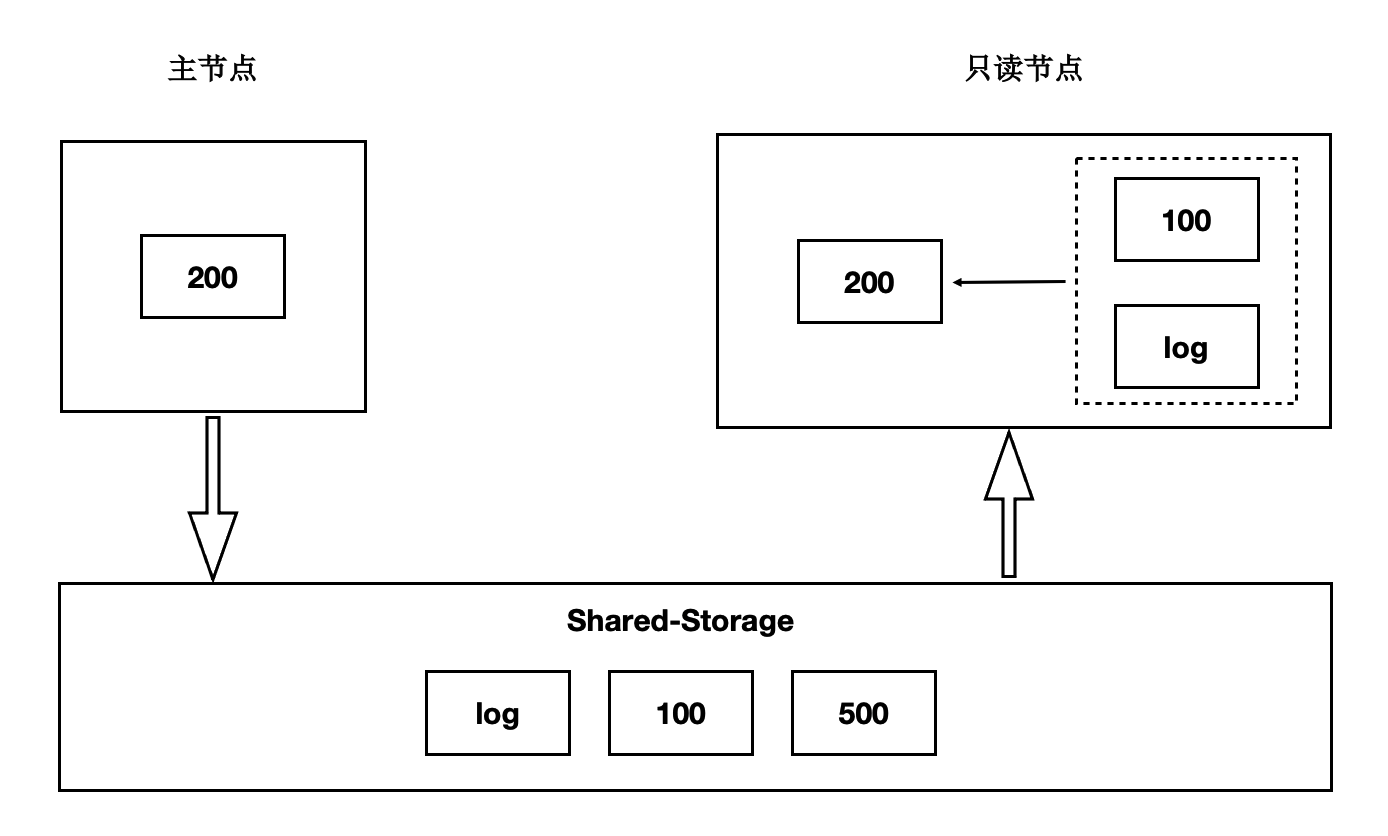
主节点通过刷脏将版本200写入到Shared-Storage。
只读节点基于版本100,并回放日志得到200。
基于Shared-Storage的过去页面
上述流程中,只读节点中基于日志回放出来的页面会被淘汰掉,此后需要再次从存储上读取页面,会出现读取的页面是之前的老页面,称为过去页面。如下图所示: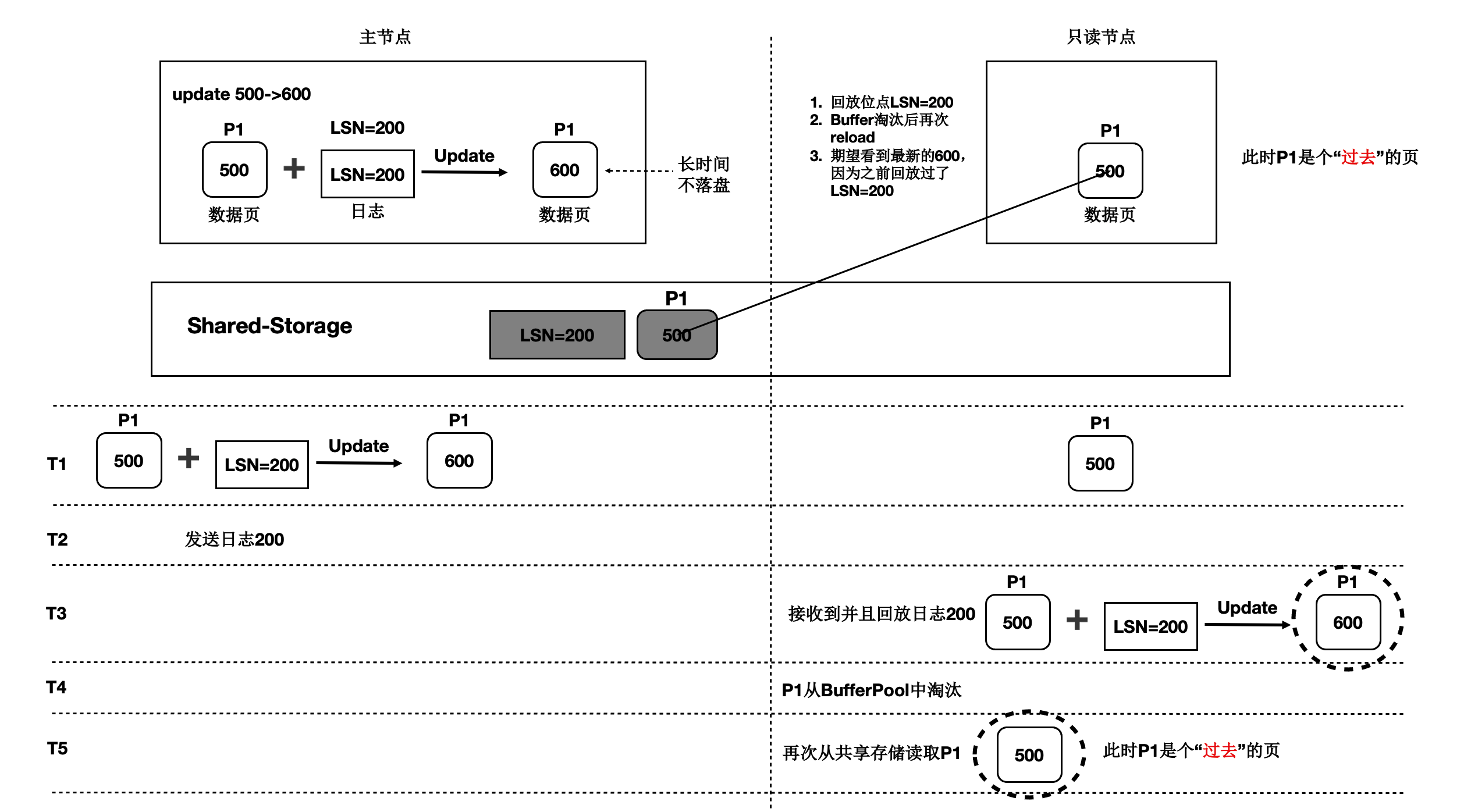
T1时刻,主节点在T1时刻写入日志LSN=200,把页面P1的内容从500更新到600。
只读节点此时页面P1的内容是500。
T2时刻,主节点将日志200的meta信息发送给只读节点,只读节点得知存在新的日志。
T3时刻,此时在只读节点上读取页面P1,需要读取页面P1和LSN=200的日志,进行一次回放,得到P1的最新内容为600。
T4时刻,只读节点上由于BufferPool不足,将回放出来的最新页面P1淘汰掉。
主节点没有将最新的页面P1为600的最新内容刷脏到Shared-Storage上。
T5时刻,再次从只读节点上发起读取P1操作,由于内存中已经将P1淘汰掉了,因此从Shared-Storage上读取,此时读取到了过去页面的内容。
过去页面的解法
只读节点在任意时刻读取页面时,需要找到对应的Base页面和对应起点的日志,依次回放。如下图所示: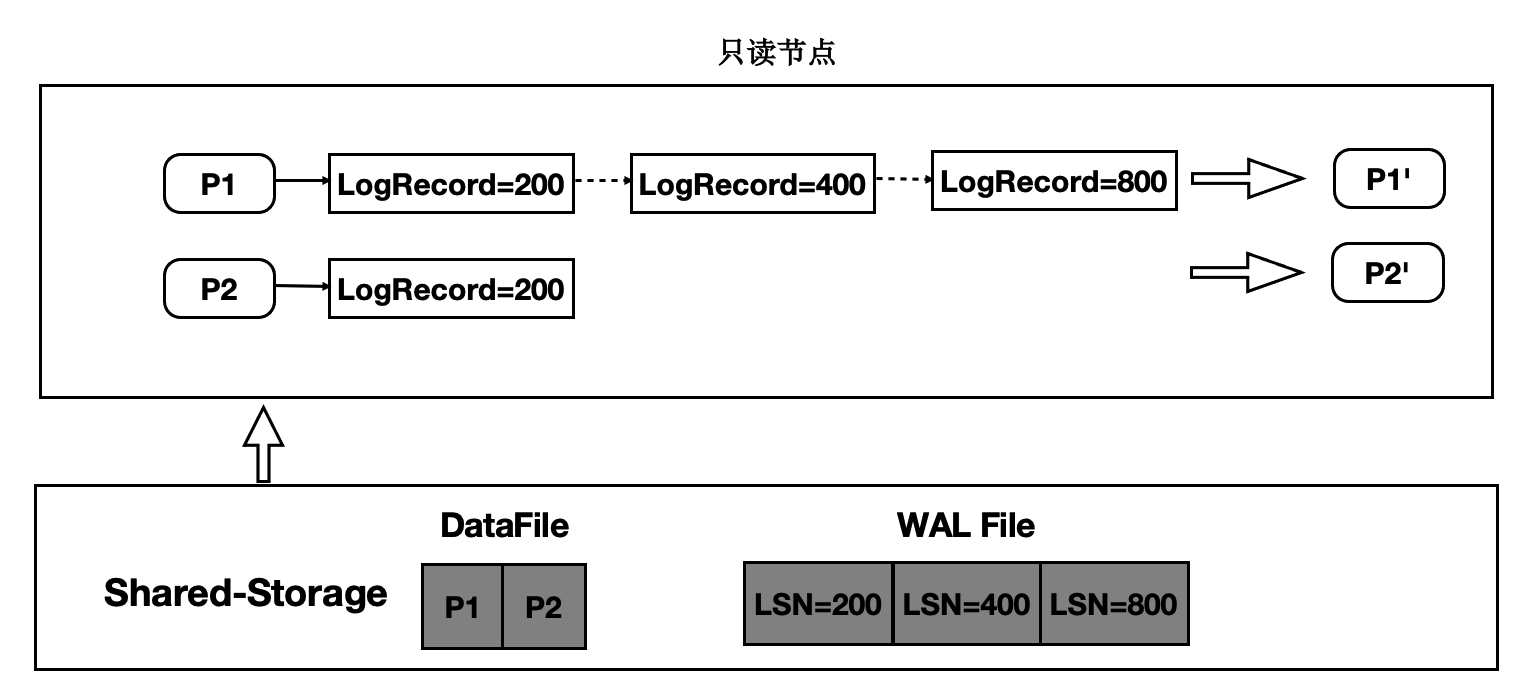
在只读节点内存中维护每个Page对应的日志meta。
在读取时一个Page时,按需逐个应用日志直到期望的Page版本。
应用日志时,通过日志的meta从Shared-Storage上读取。
通过上述分析,需要维护每个Page到日志的倒排索引,而只读节点的内存是有限的,因此这个Page到日志的索引需要持久化,PolarDB PostgreSQL版设计了一个可持久化的索引结构-LogIndex。LogIndex本质是一个可持久化的hash数据结构。
只读节点通过WAL receiver接收从主节点过来的WAL meta信息。
WAL meta记录该条日志修改了哪些Page。
将该条WAL meta插入到LogIndex中。其中,key是Page ID,value是LSN。
一条WAL日志可能更新了多个Page(索引分裂),在LogIndex中有多条记录。
同时在BufferPool中给该Page打上outdate标记,以便下次读取的时候从LogIndex重回放对应的日志。
当内存达到一定阈值时,LogIndex异步将内存中的hash刷到盘上。
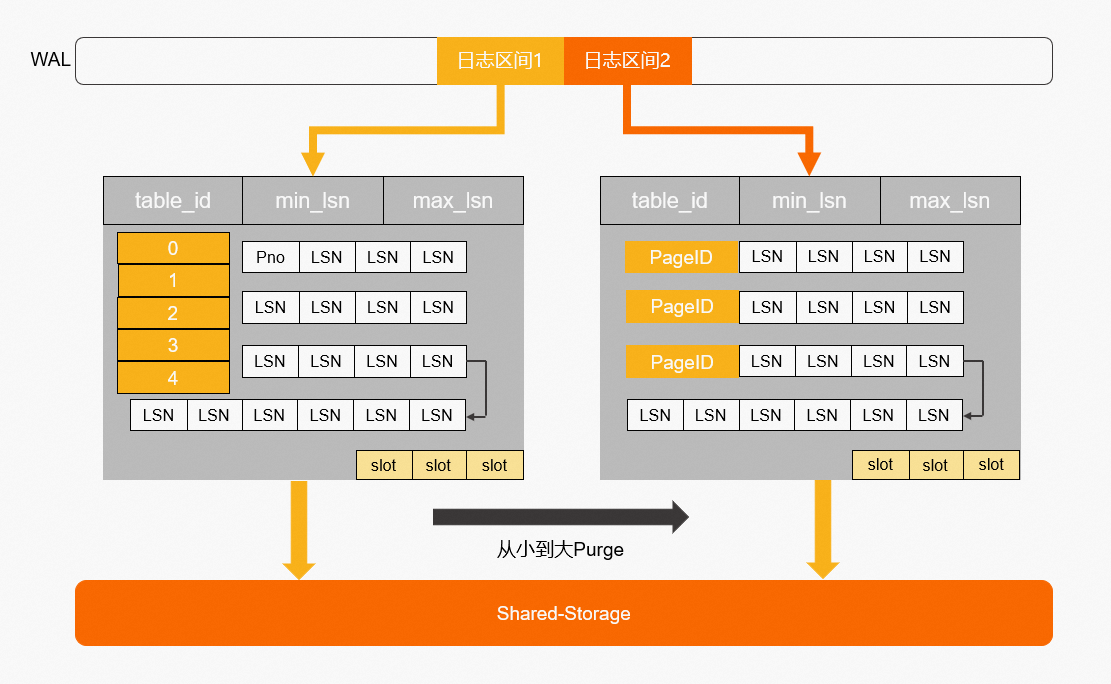
通过LogIndex解决了刷脏依赖过去页面的问题,也是将只读节点的回放转变成了Lazy的回放:只需要回放日志的meta信息即可。
基于Shared-Storage的未来页面
在存储计算分离后,刷脏依赖还存在未来页面的问题。如下图所示: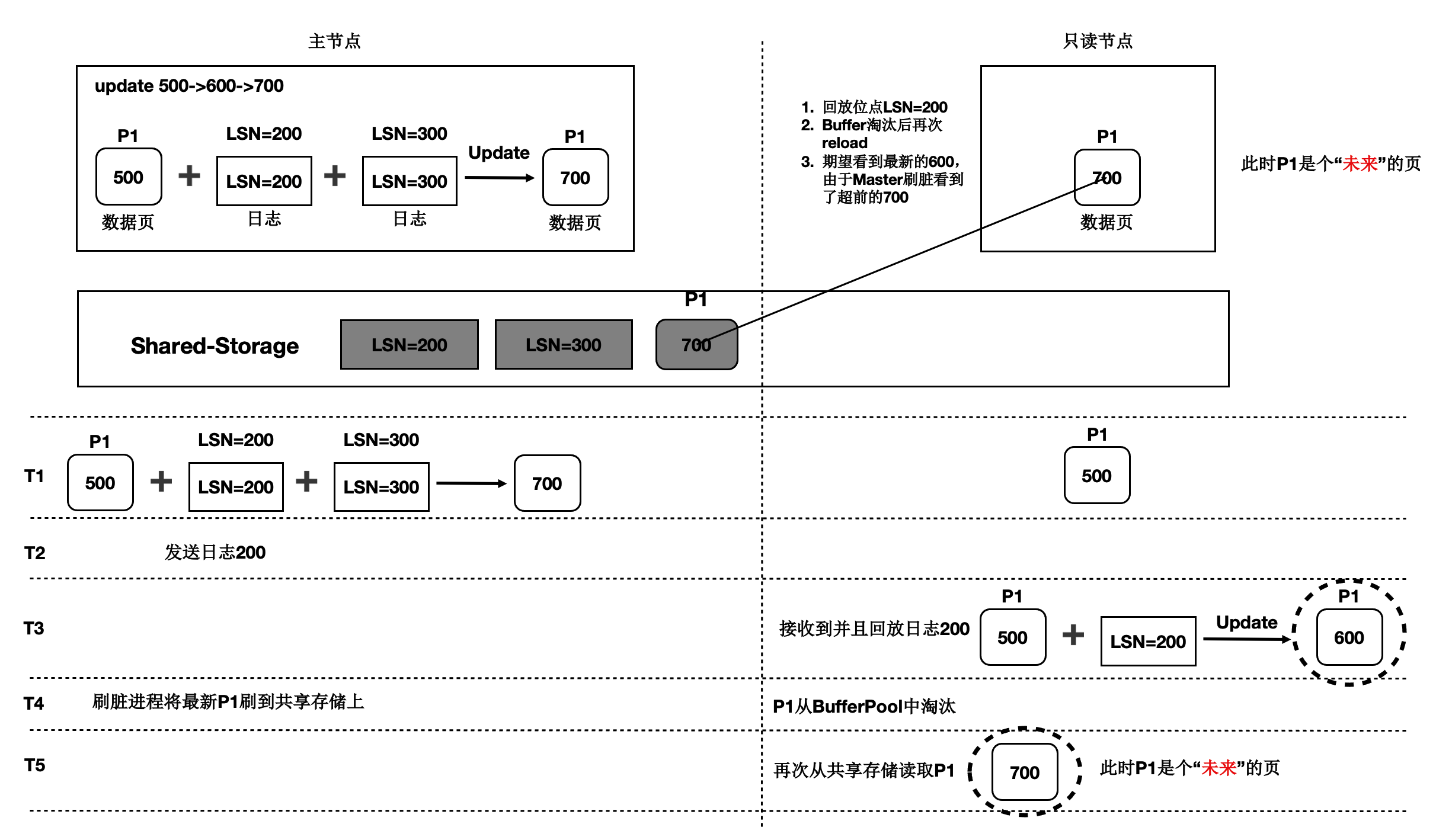
T1时刻,主节点对P1更新了2次,产生了2条日志,此时主节点和只读节点上页面P1的内容都是500。
T2时刻, 发送日志LSN=200给只读节点。
T3时刻,只读节点回放LSN=200的日志,得到P1的内容为600,此时只读节点日志回放到了200,后面的LSN=300的日志对其来说还不存在。
T4时刻,主节点刷脏,将P1最新的内容700刷到了Shared-Storage上,同时只读节点上BufferPool淘汰掉了页面P1。
T5时刻,只读节点再次读取页面P1,由于BufferPool中不存在P1,因此从共享内存上读取了最新的P1,但是只读节点并没有回放LSN=300的日志,读取到了一个对其来说超前的未来页面。
未来页面的问题是:部分页面是未来页面,部分页面是正常的页面,会导致数据不一致。例如,索引分裂成2个Page后,一个读取到了正常的Page,另一个读取到了未来页面,B+Tree的索引结构会被破坏。
未来页面的解法
未来页面的原因是主节点刷脏的速度超过了任一只读节点的回放速度(虽然只读节点的Lazy回放已经很快了)。因此,解法就是对主节点刷脏进度时做控制:不能超过最慢的只读节点的回放位点。如下图所示:
只读节点回放到T4位点。
主节点在刷脏时,对所有脏页按照LSN排序,仅刷在T4之前的脏页(包括T4),之后的脏页不刷。
其中,T4的LSN位点称为一致性位点。
低延迟复制
传统流复制的问题
同步链路:日志同步路径IO多,网络传输量大。
页面回放:读取和Buffer修改慢(IO密集型+CPU密集型)。
DDL回放:修改文件时需要对修改的文件加锁,而加锁的过程容易被阻塞,导致DDL慢。
快照更新:RO高并发引起事务快照更新慢。
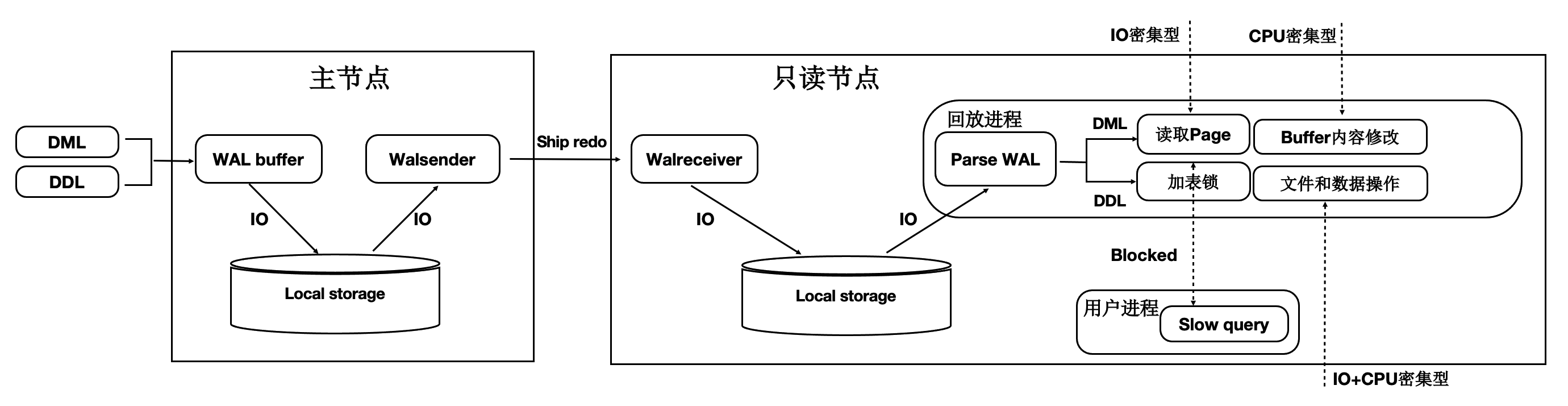
流程如下:
主节点写入WAL日志到本地文件系统中。
WAL Sender进程读取,并发送。
只读节点的WAL Receiver进程接收写入到本地文件系统中。
回放进程读取WAL日志,读取对应的Page到BufferPool中,并在内存中回放。
主节点刷脏页到Shared Storage。
从上述流程可以看到,整个链路是很长的,只读节点延迟高,影响用户业务读写分离负载均衡。
优化1:只复制Meta
因为底层是Shared-Storage,只读节点可直接从Shared-Storage上读取所需要的WAL数据。因此主节点只把WAL日志的元数据(去掉Payload)复制到只读节点,这样网络传输量小,减少关键路径上的IO。如下图所示:
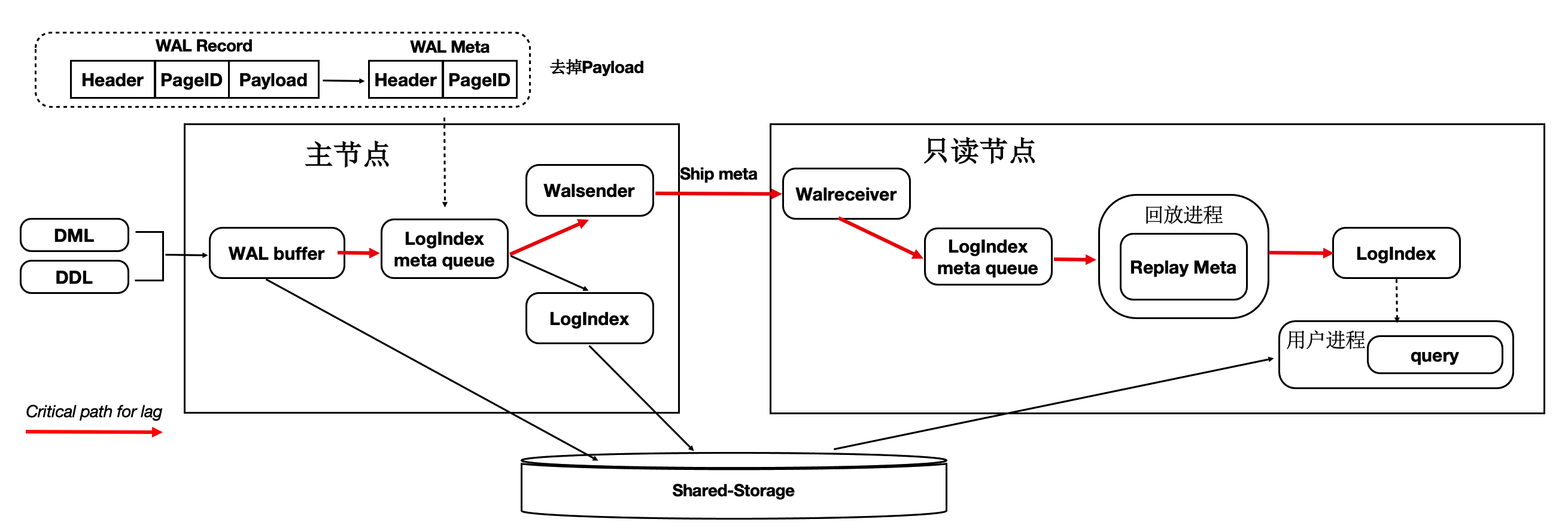
优化流程如下:
WAL Record是由:Header,PageID,Payload组成。
由于只读节点可以直接读取Shared-Storage上的WAL文件,因此主节点只把WAL日志的元数据发送(复制)到只读节点,包括:Header,PageID。
在只读节点上,通过WAL的元数据直接读取Shared-Storage上完整的WAL文件。
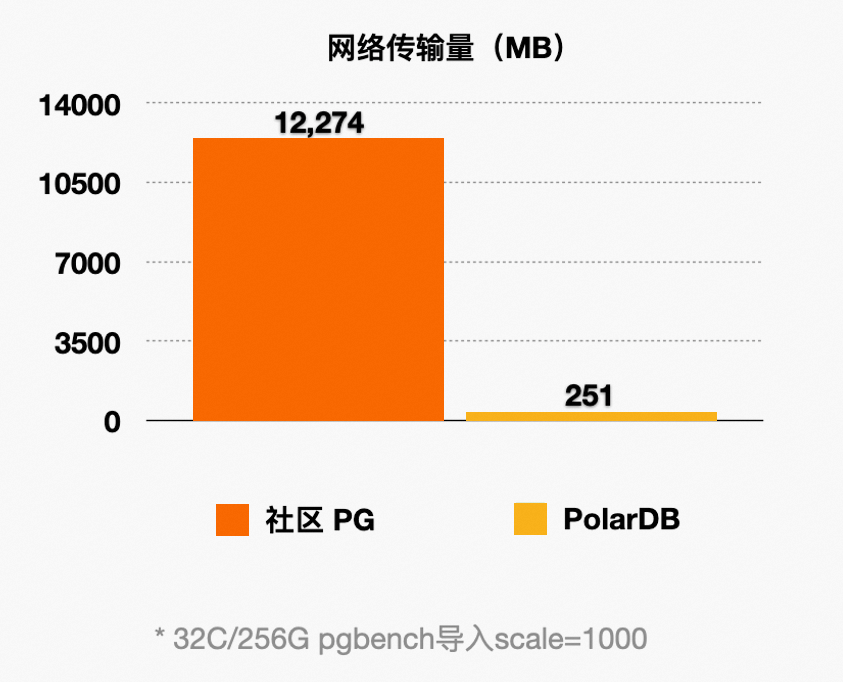
通过上述优化,能显著减少主节点和只读节点间的网络传输量。从下图可以看到网络传输量减少了 98%。
优化2:页面回放优化
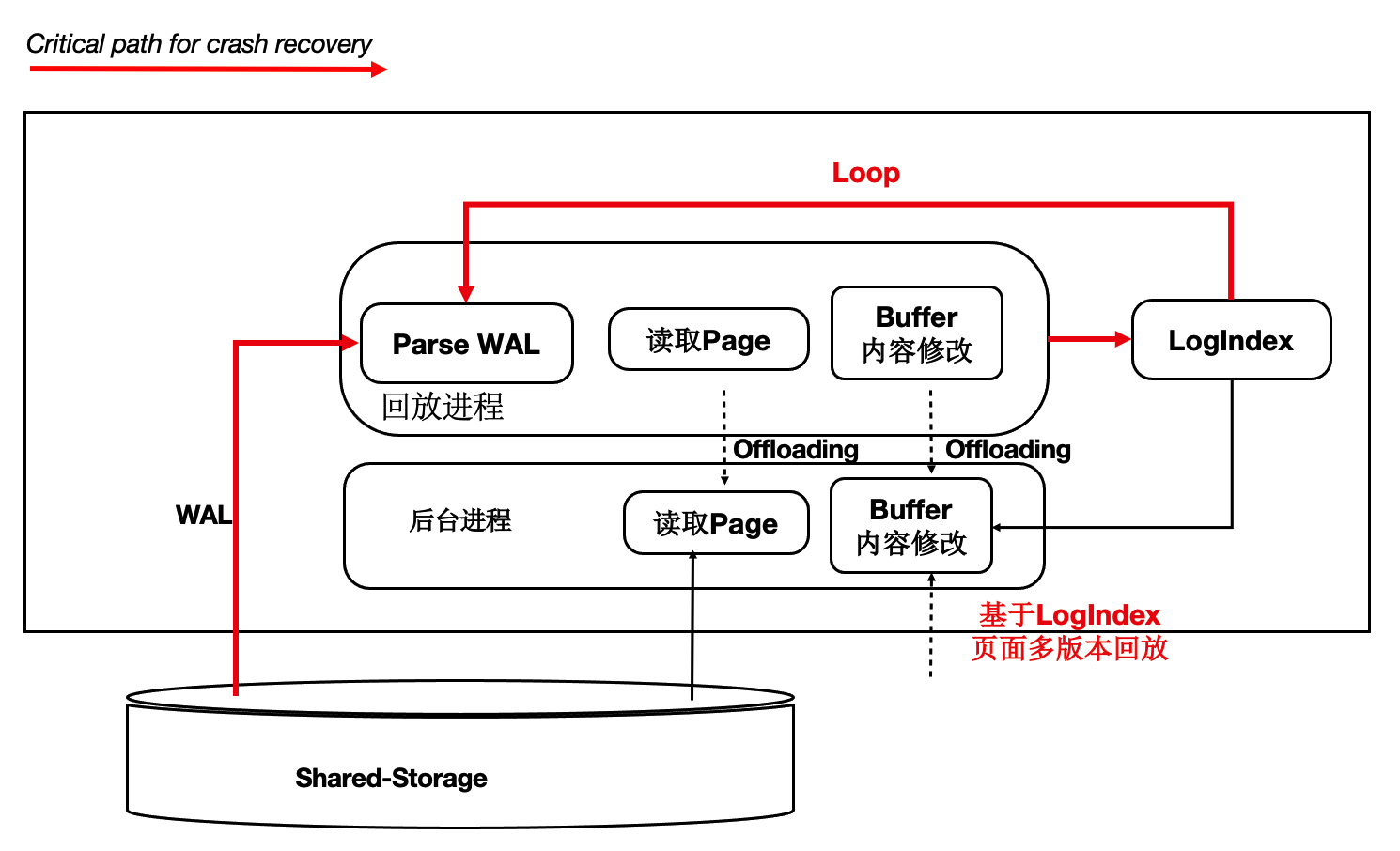
在传统数据库中日志回放的过程中会读取大量的Page并逐个日志Apply,然后落盘。该流程在用户读IO的关键路径上,借助存储计算分离可以做到:如果只读节点上Page不在BufferPool中,不产生任何IO,仅仅记录LogIndex即可。
可以将回放进程中的以下IO操作offload到session进程中:
数据页IO开销。
日志apply开销。
基于LogIndex页面的多版本回放。
如下图所示,在只读节点上的回放进程中,在Apply一条WAL的meta时:
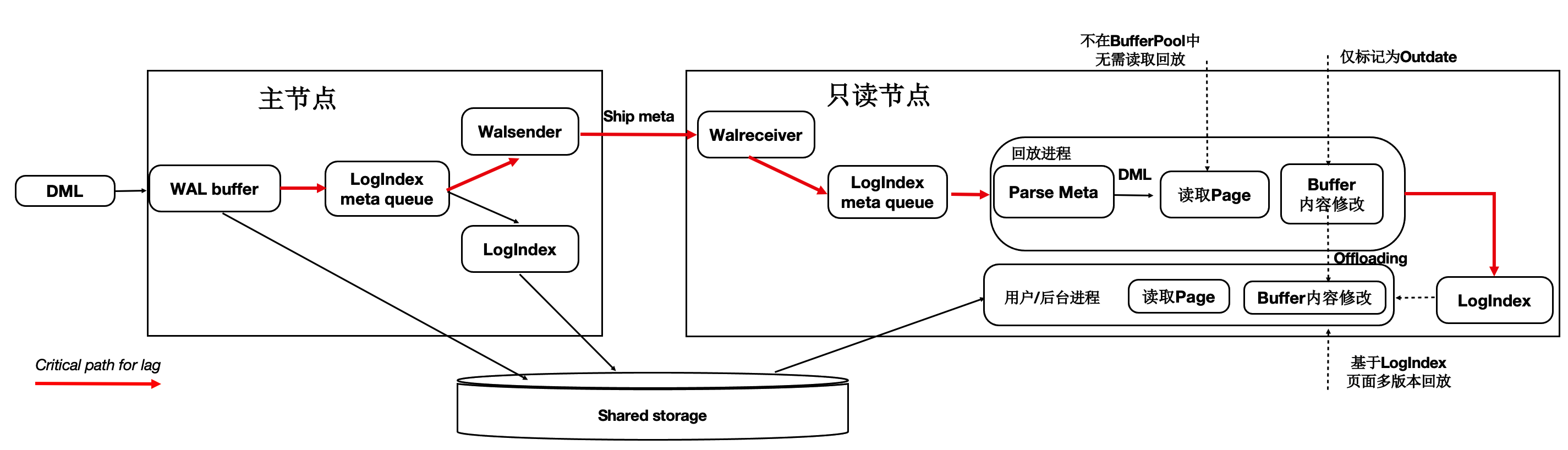
如果对应Page不在内存中,仅仅记录LogIndex。
如果对应的Page在内存中,则标记为Outdate,并记录LogIndex,回放过程完成。
用户session进程在读取Page时,读取正确的Page到BufferPool中,并通过LogIndex来回放相应的日志。
可以看到,主要的IO操作由原来的单个回放进程offload到了多个用户进程。
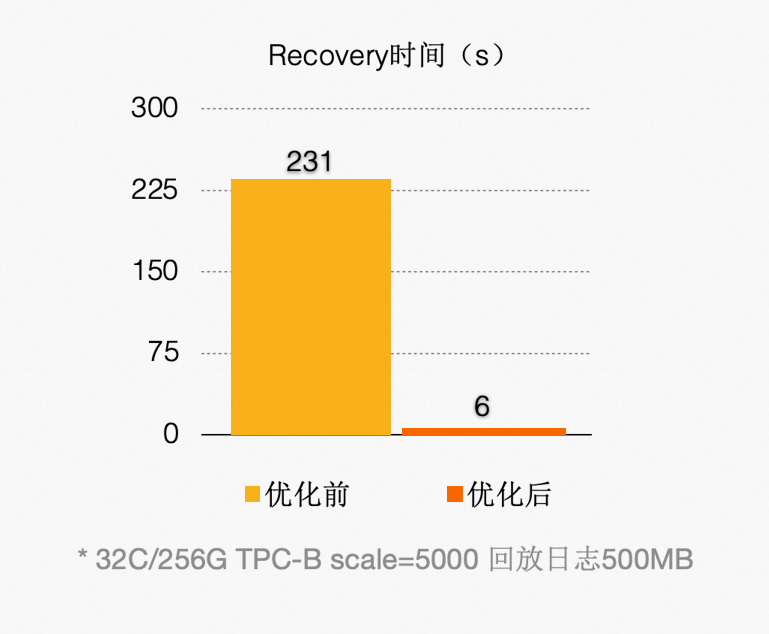
通过上述优化,能显著减少回放的延迟,比其他云原生数据库快30倍。
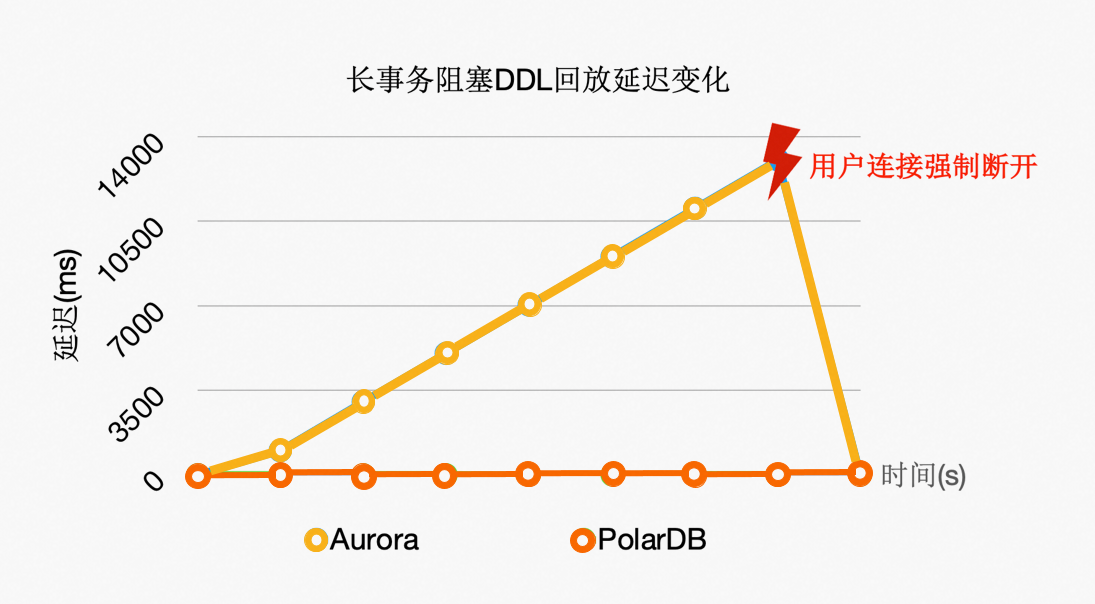
优化3:DDL锁回放优化
在主节点执行DDL时(例如,drop table),需要在所有节点上都对表上排他锁,这样能保证表文件不会在只读节点上读取时被主节点删除掉了(因为文件在Shared-Storage上只有一份)。在所有只读节点上对表上排他锁是通过WAL复制到所有的只读节点,只读节点回放DDL锁来完成。而回放进程在回放DDL锁时,对表上锁可能会阻塞很久,因此可以通过把DDL锁offload到其他进程上来优化回放进程的关键路径。
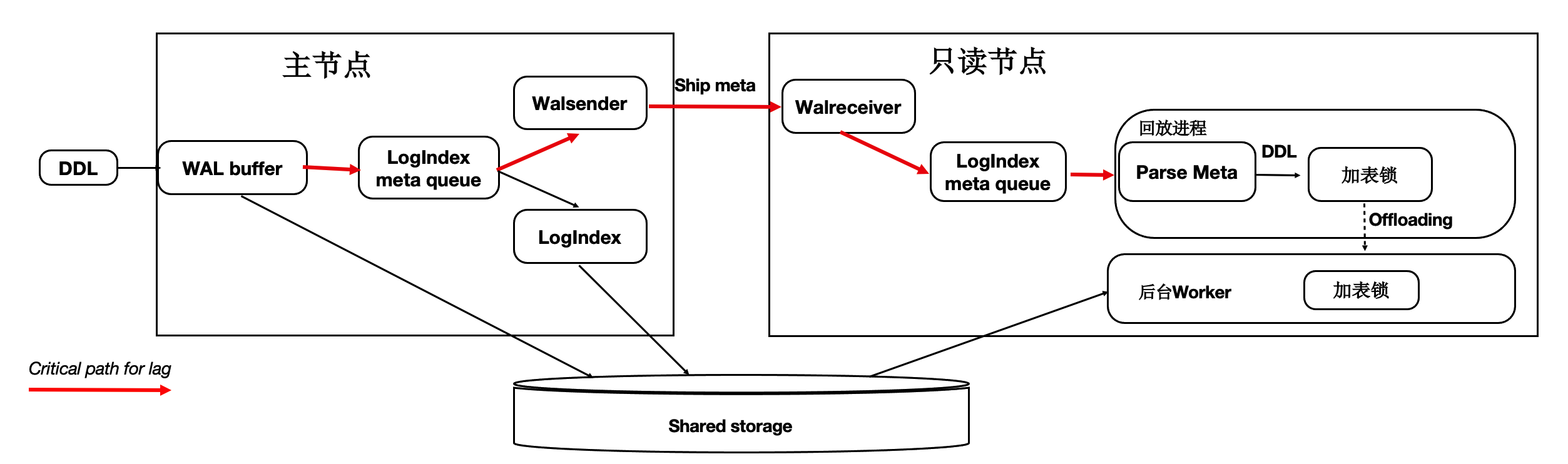
通过上述优化,能够保证回放进程一直处于平滑的状态,不会因为去等DDL而阻塞了回放的关键路径。
上述3个优化之后,极大的降低了复制延迟,能够带来如下优势:
读写分离:负载均衡,更接近Oracle RAC使用体验。
高可用:加速HA流程。
稳定性:最小化未来页的数量,可以写更少或者无需写页面快照。
Recovery优化
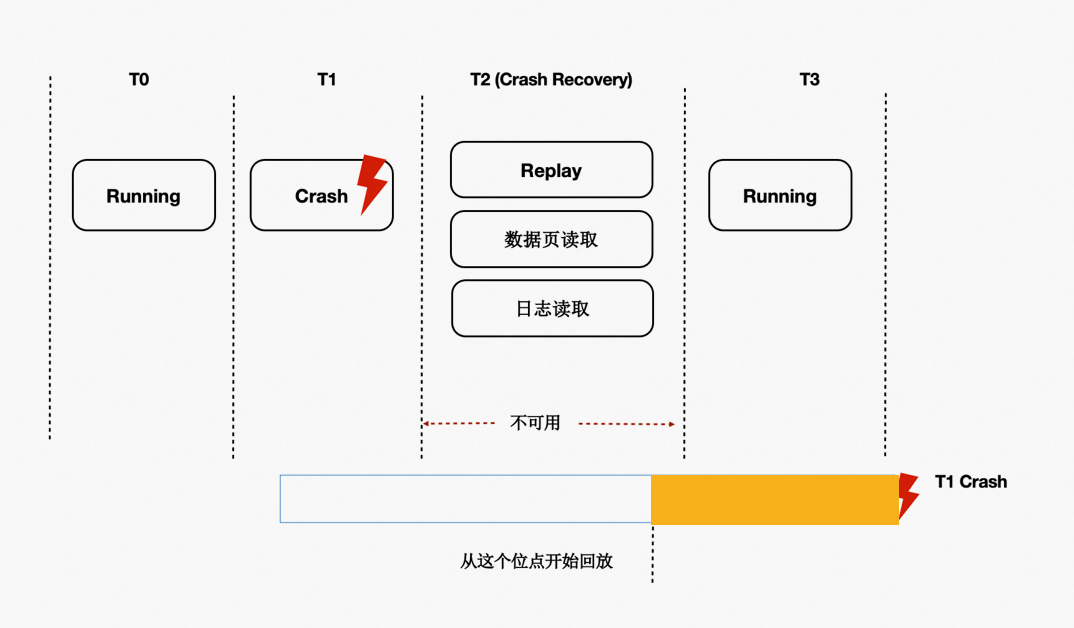
背景
数据库OOM、Crash等场景恢复时间长,本质上是日志回放慢,在共享存储Direct-IO模型下问题更加突出。
Lazy Recovery
上述内容介绍通过LogIndex在只读节点上做到了Lazy的回放,在主节点重启后的recovery过程中,本质也是在回放日志,因此,可以借助Lazy回放来加速recovery的过程:
从checkpoint点开始逐条去读WAL日志。
回放完LogIndex日志后,即认为回放完成。
recovery完成,开始提供服务。
真正的回放被offload到了重启之后进来的session进程中。
优化之后(回放500 MB日志量),如下图所示:
Persistent BufferPool
上述方案优化了在recovery的重启速度,但是在重启之后,session进程通过读取WAL日志来回放想要的page。表示为在recovery之后会有短暂的响应慢的问题。优化的办法为在数据库重启时BufferPool并不销毁,如下图所示:crash和restart期间BufferPool不销毁。
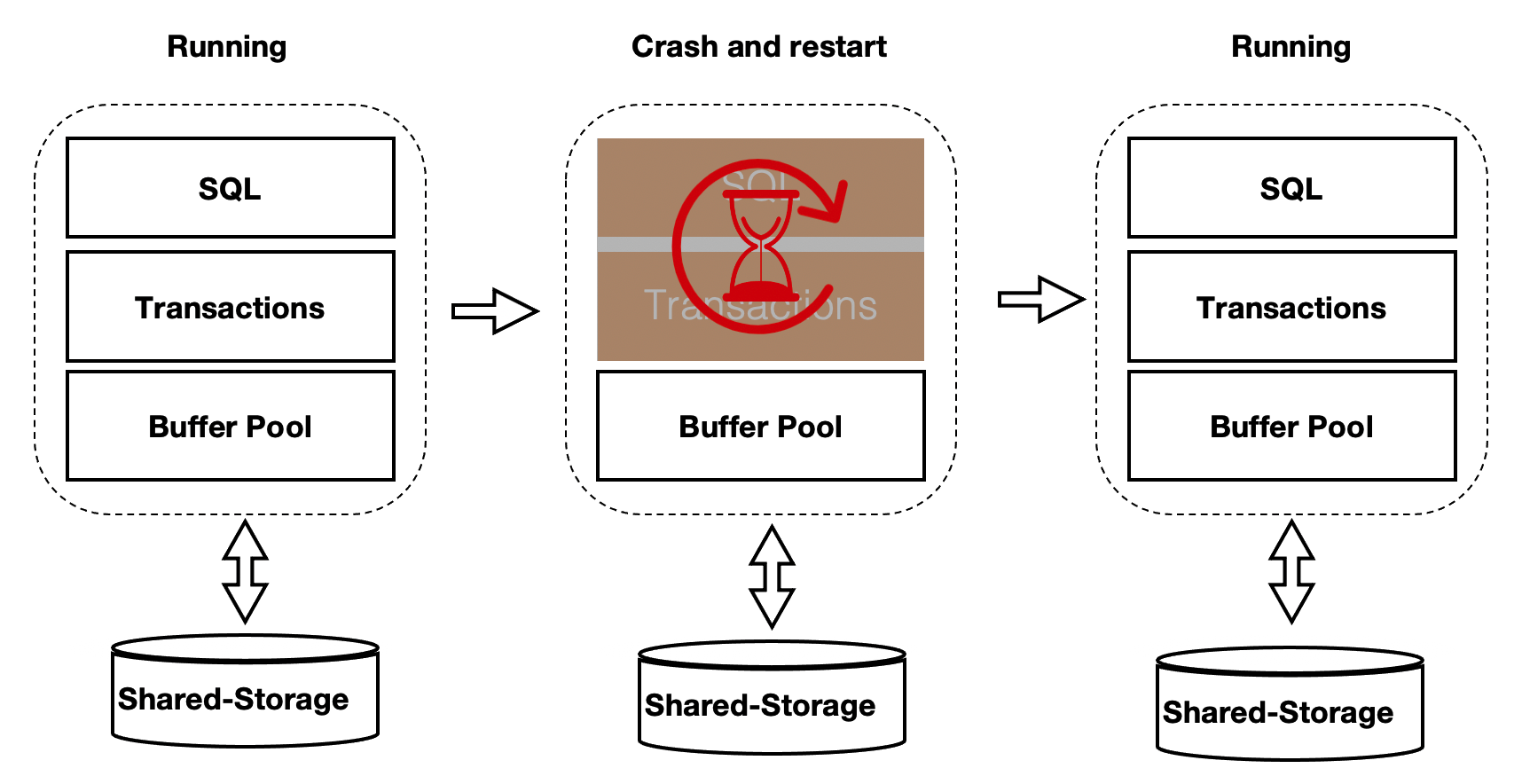
内核中的共享内存分成2部分:
全局结构,ProcArray等。
BufferPool结构;其中BufferPool通过具名共享内存来分配,在进程重启后仍然有效。而全局结构在进程重启后需要重新初始化。
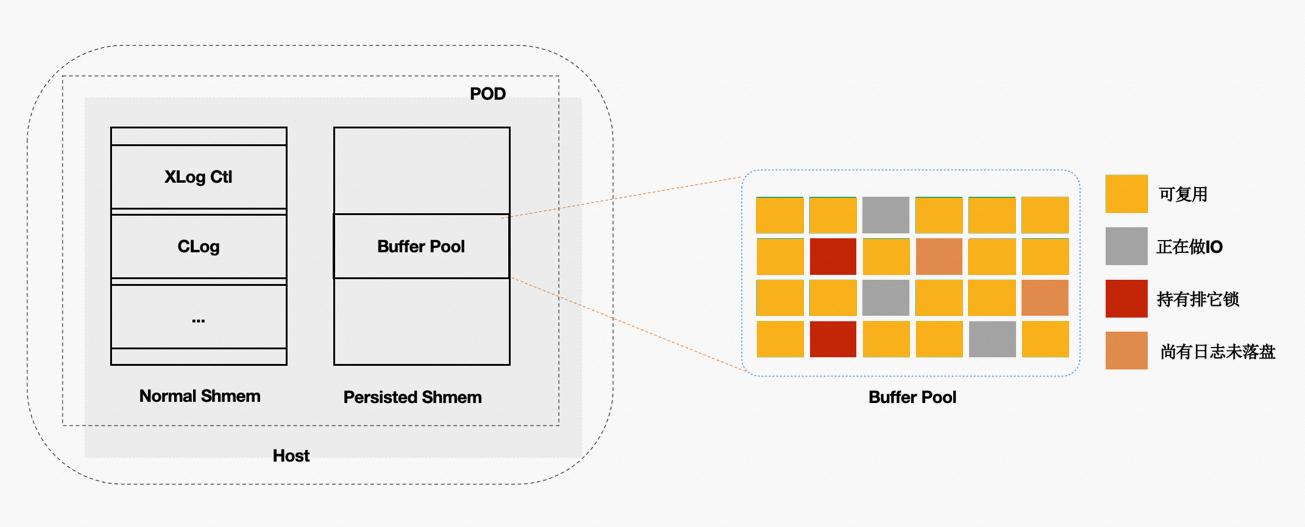
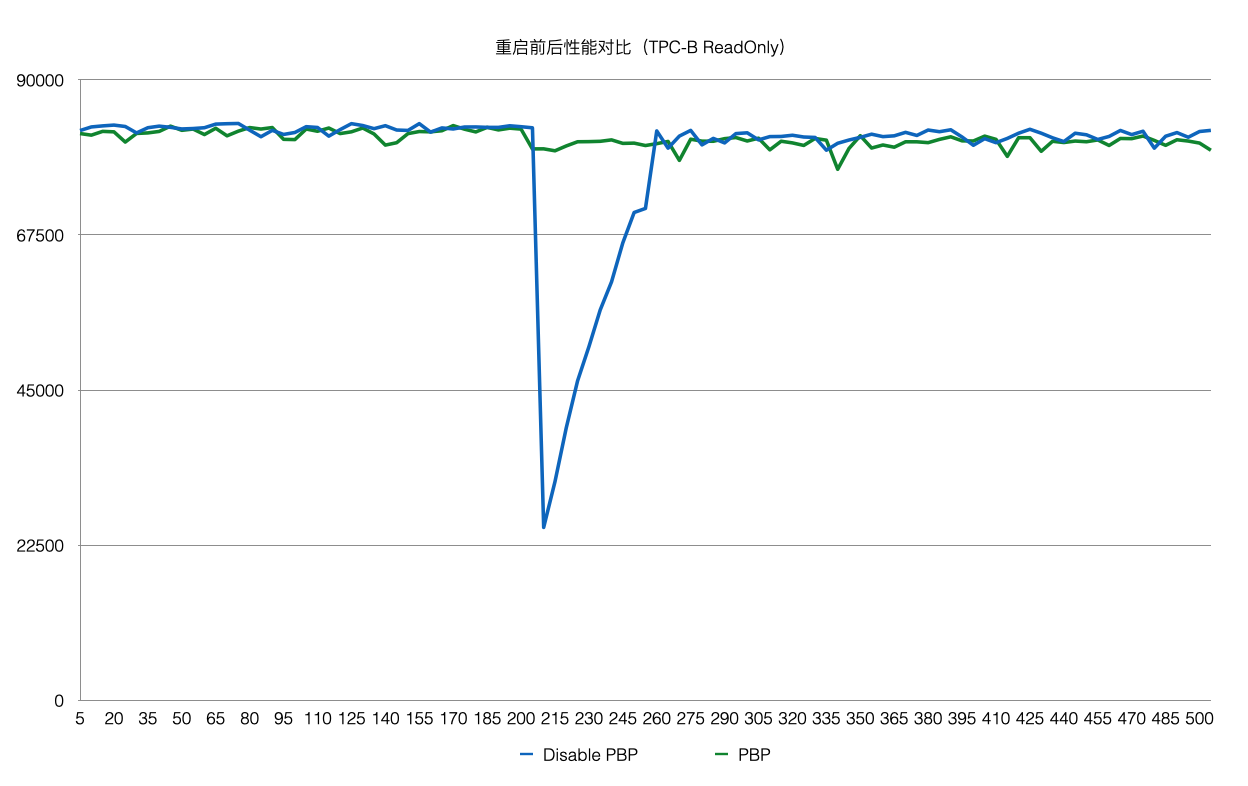
而BufferPool中并不是所有的Page都是可以复用的。例如:在重启前,某进程对Page上X锁,随后crash了,该X锁就没有进程来释放了。因此,在crash和restart之后需要把所有的BufferPool遍历一遍,剔除掉不能被复用的Page。另外,BufferPool的回收依赖kubernetes。该优化之后,使得重启前后性能平稳。
PolarDB PostgreSQL版HTAP架构详解
PolarDB PostgreSQL版读写分离后,由于底层是存储池,理论上IO吞吐是无限大的。而大查询只能在单个计算节点上执行,单个计算节点的CPU/MEM/IO是有限的,因此单个计算节点无法发挥出存储侧的大IO带宽的优势,也无法通过增加计算资源来加速大的查询。PolarDB PostgreSQL版推出了基于Shared-Storage的MPP分布式并行执行,来加速在OLTP场景下OLAP查询。
HTAP架构原理
PolarDB PostgreSQL版底层存储在不同节点上是共享的,因此不能直接像传统MPP一样去扫描表。PolarDB PostgreSQL版在原来单机执行引擎上支持了MPP分布式并行执行,同时对Shared-Storage进行了优化。 基于Shared-Storage的MPP是业界首创。原理如下:
Shuffle算子屏蔽数据分布。
ParallelScan算子屏蔽共享存储。
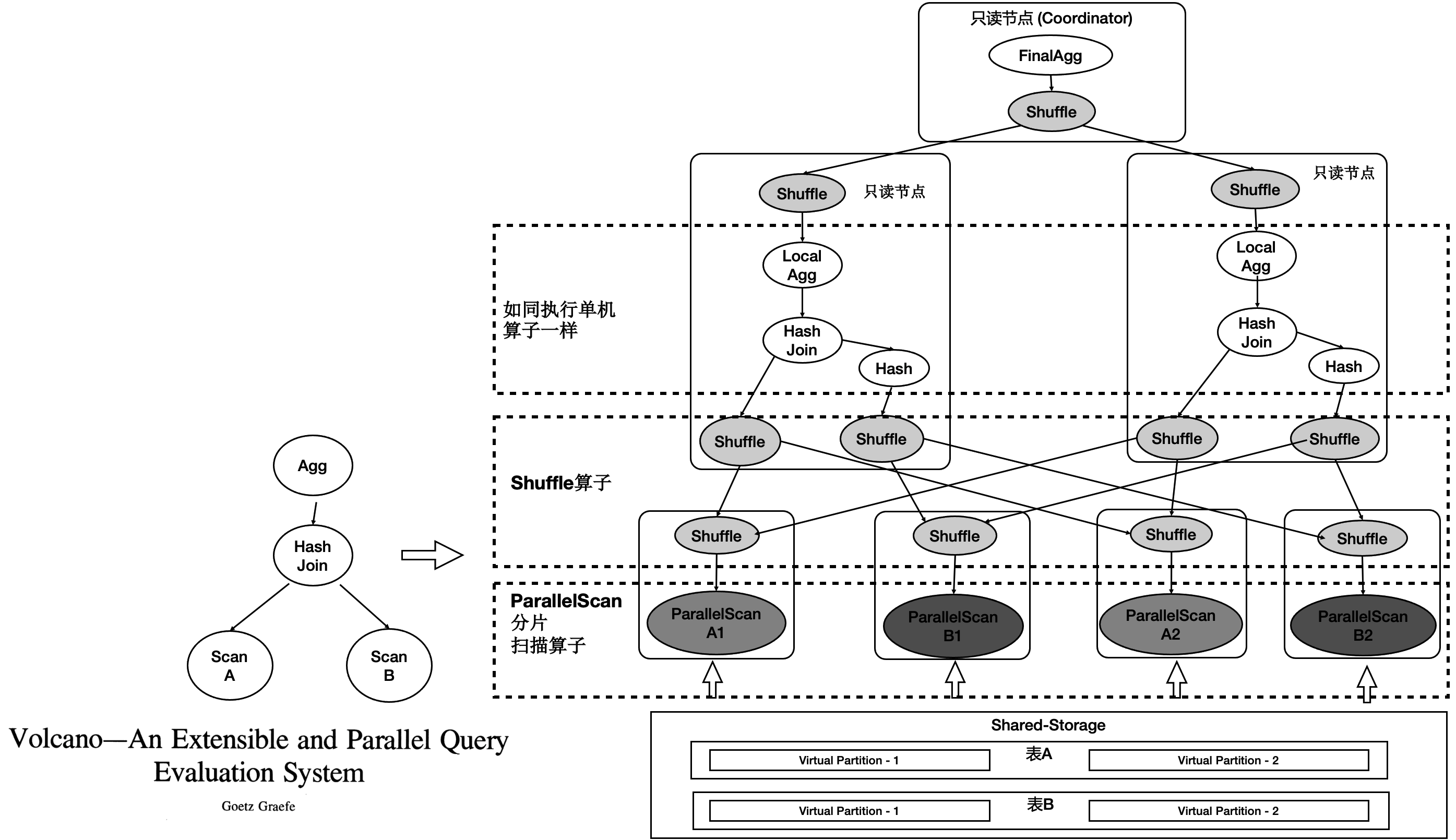
如图所示:
表A和表B做join,并做聚合。
共享存储中的表仍然是单张表,并没有做物理上的分区。
重新设计4类扫描算子,使之在扫描共享存储上的表时能够分片扫描,形成virtual partition。
分布式优化器
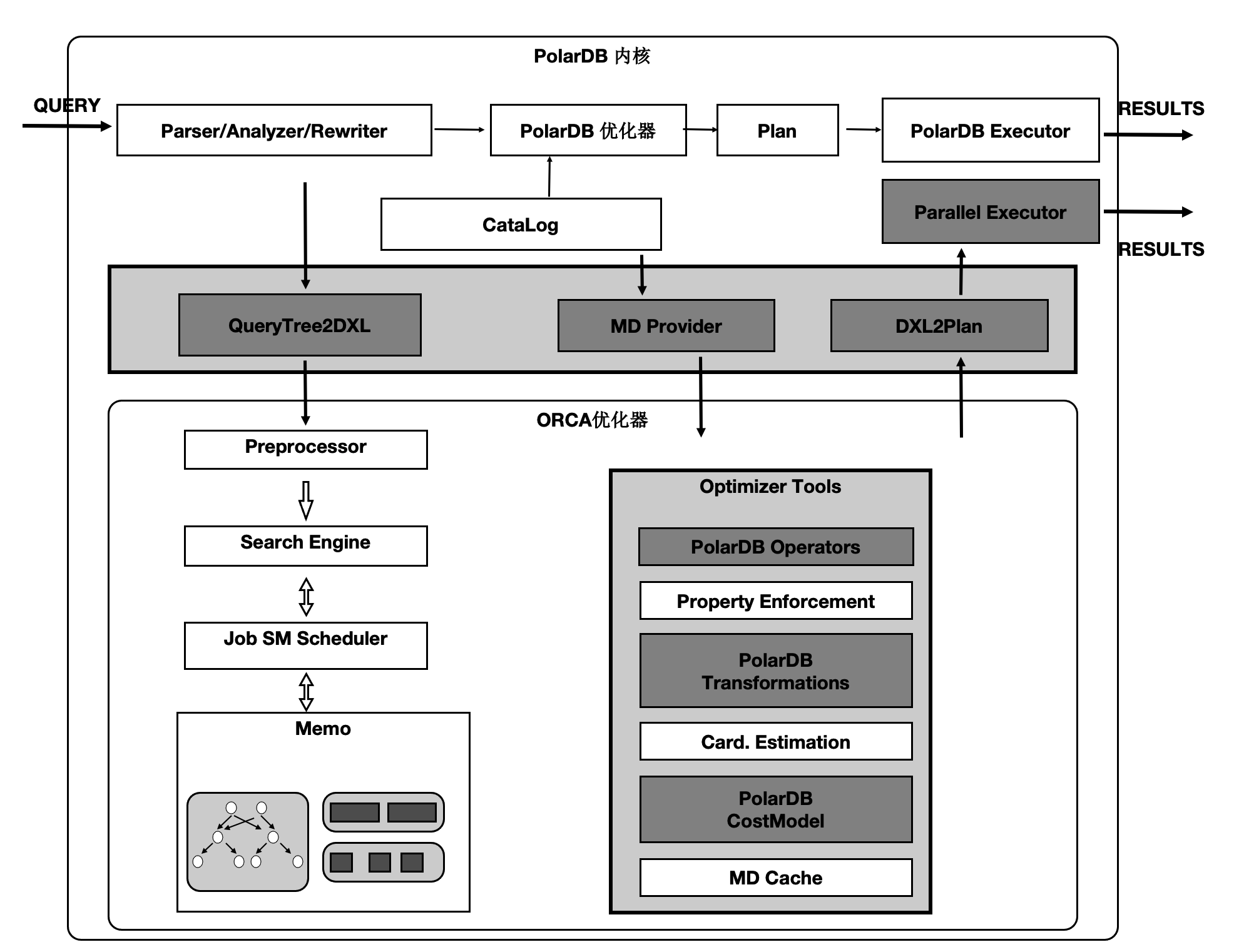
基于社区的GPORCA优化器扩展了能感知共享存储特性的Transformation Rules。使得能够探索共享存储下特有的Plan空间。例如,对于一个表在PolarDB PostgreSQL版中既可以全量的扫描,也可以分区域扫描,这个是和传统MPP的本质区别。如下图所示,上面灰色部分是PolarDB PostgreSQL版内核与GPORCA优化器的适配部分。下半部分是ORCA内核,灰色模块是在ORCA内核中对共享存储特性所做的扩展。
算子并行化
PolarDB PostgreSQL版中有4类算子需要并行化,以下介绍一个具有代表性的Seqscan的算子的并行化。
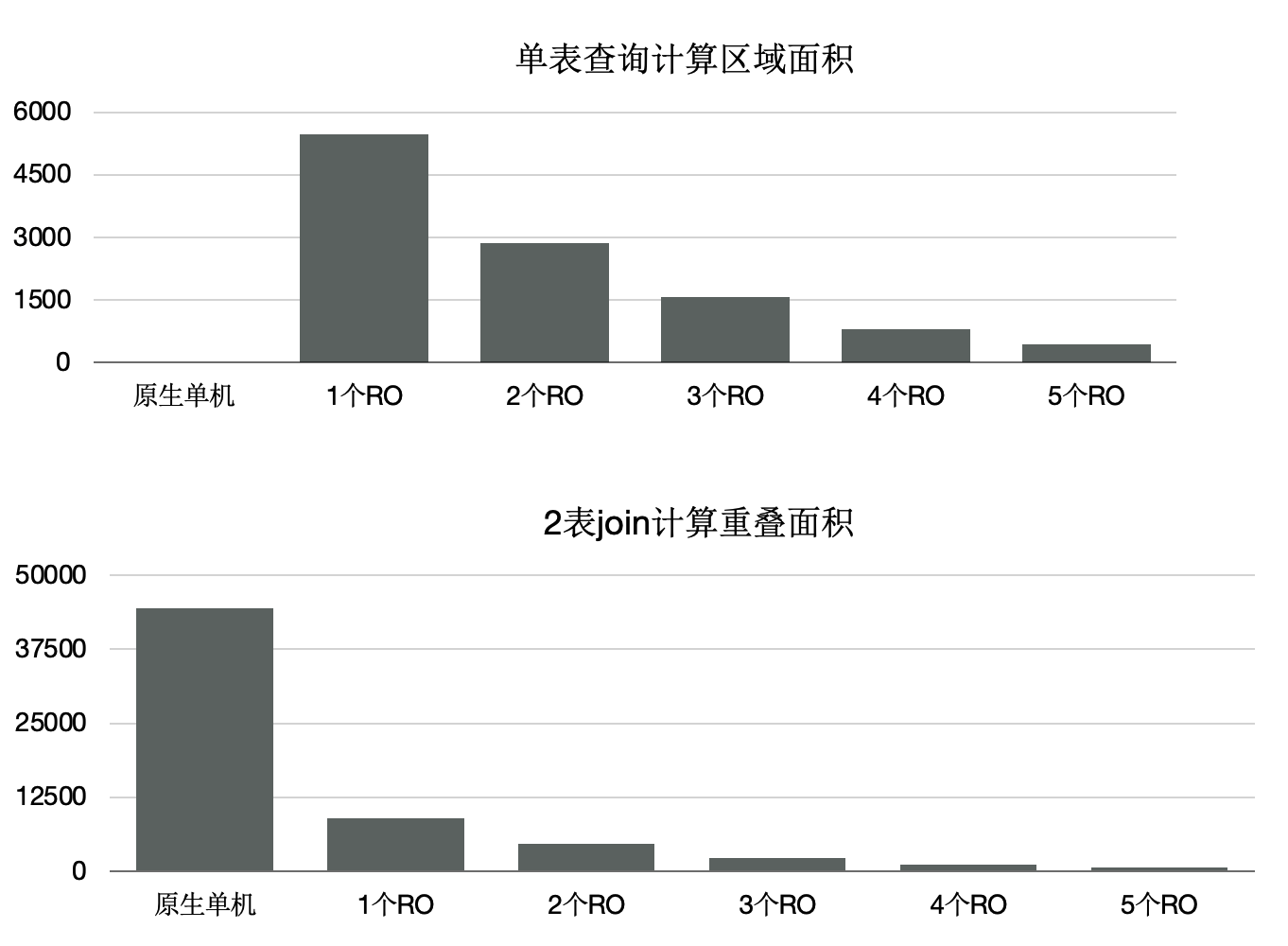
为了最大限度的利用存储的大IO带宽,在顺序扫描时,按照4 MB为单位做逻辑切分,将IO尽量打散到不同的盘上,达到所有的盘同时提供读服务的效果。这样做还有一个优势,就是每个只读节点只扫描部分表文件,则最终能缓存的表大小是所有只读节点的BufferPool总和。
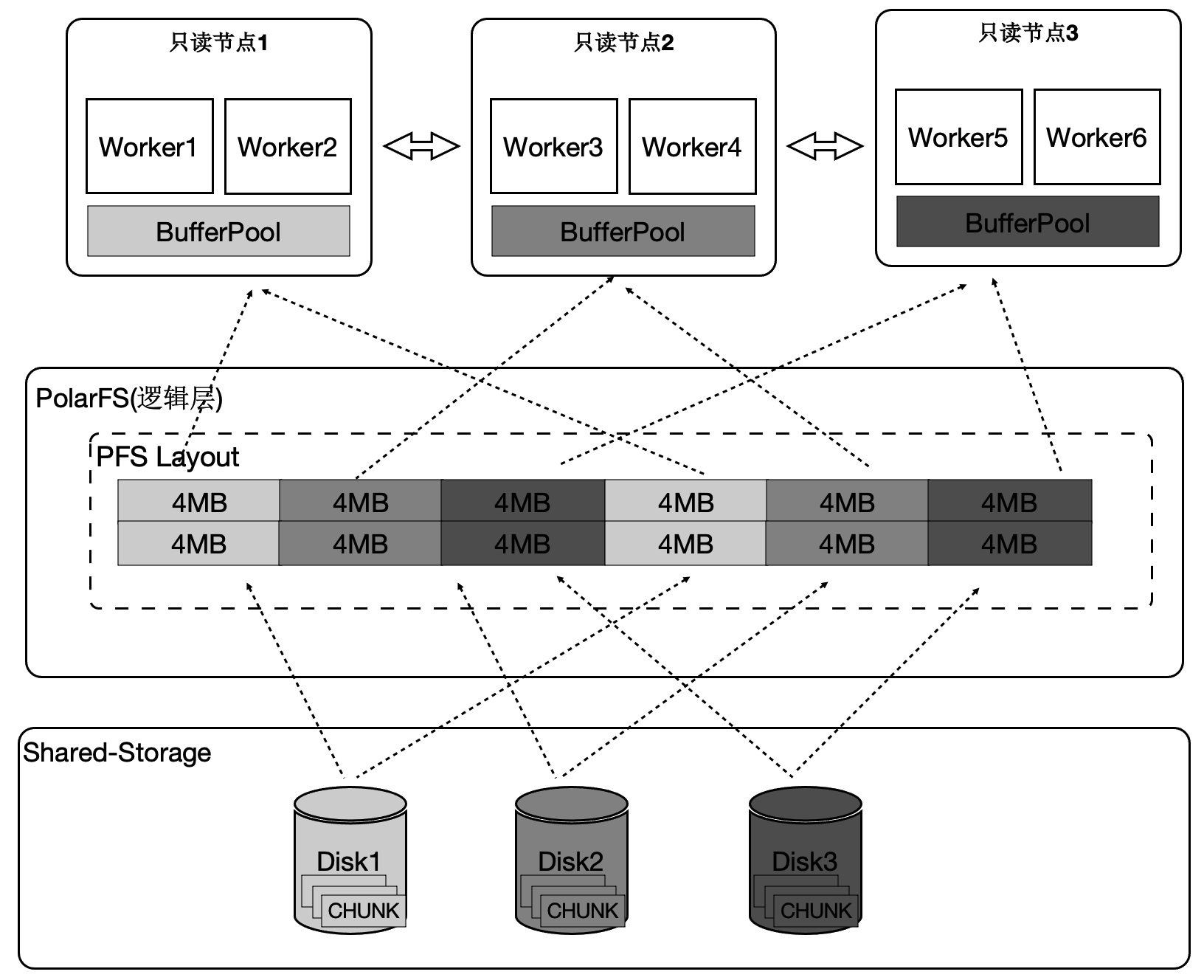
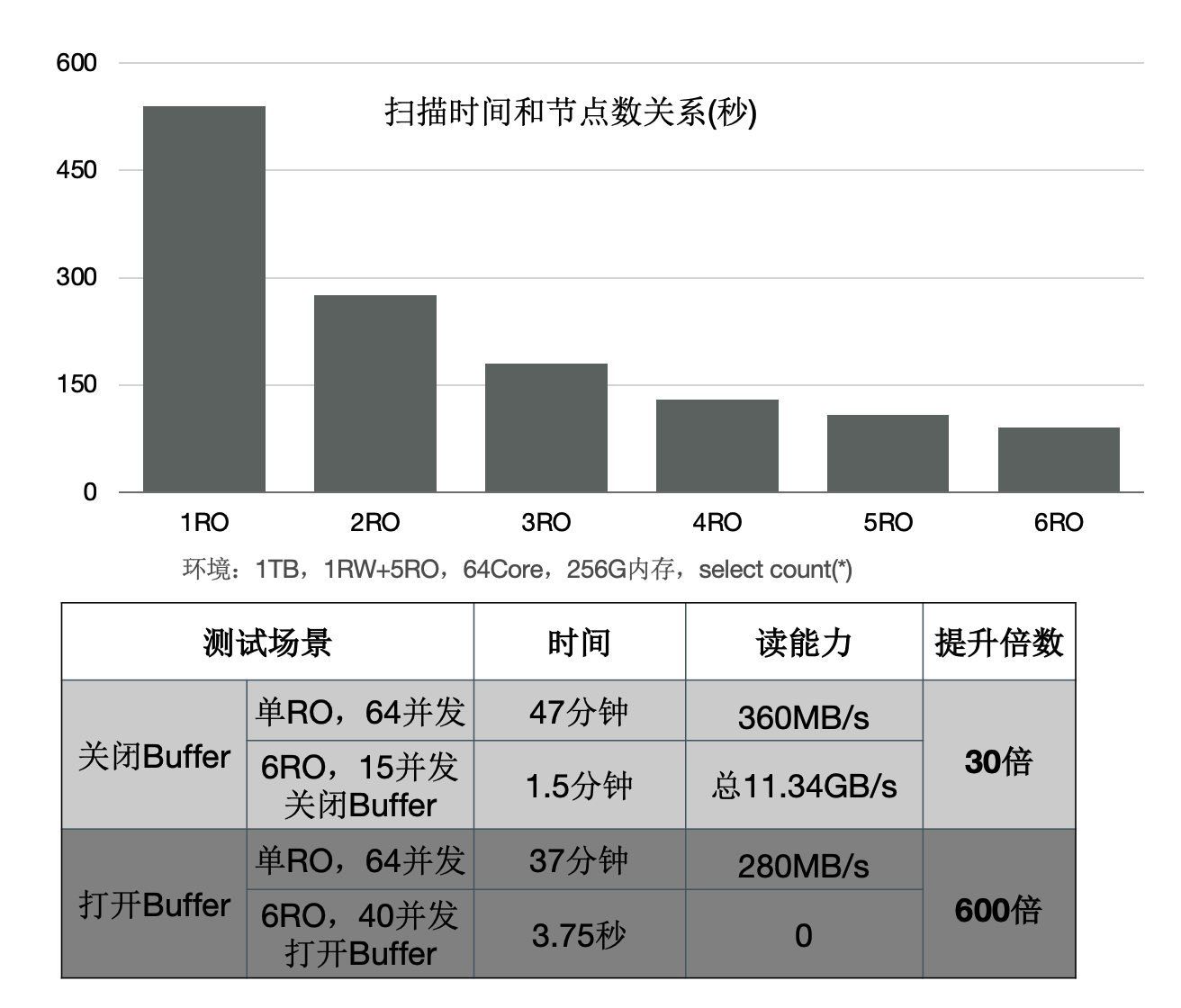
下面的图表中:
增加只读节点,扫描性能线性提升30倍。
打开Buffer时,扫描从37分钟降到3.75秒。
消除数据倾斜问题
倾斜是传统MPP固有的问题:
在PolarDB PostgreSQL版中,大对象的是通过heap表关联TOAST表,无论对哪个表切分都无法达到均衡。
另外,不同只读节点的事务、Buffer、网络、IO负载抖动。
以上两点会导致分布执行时存在长尾进程。
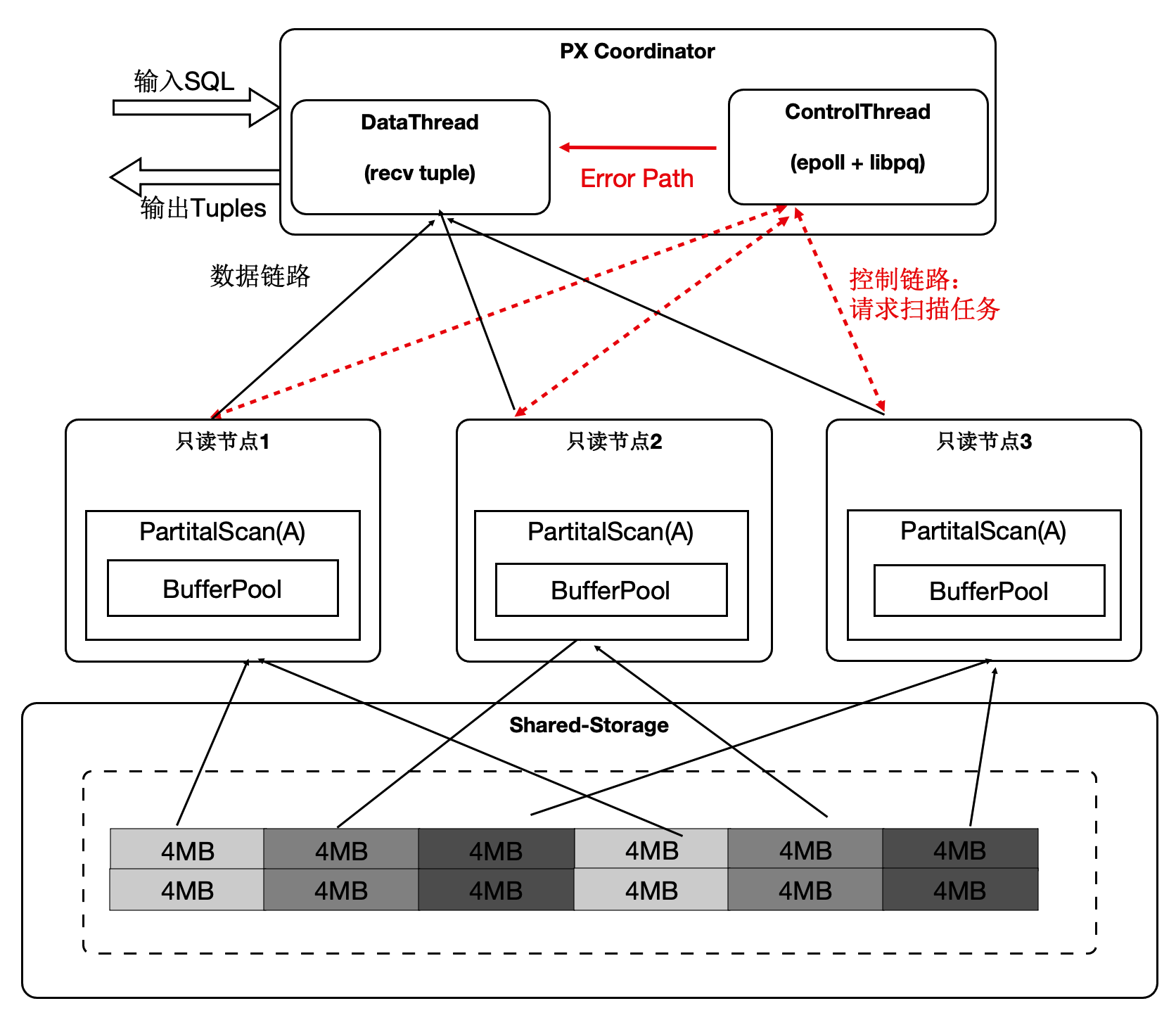
协调节点内部分成DataThread和ControlThread。
DataThread负责收集汇总元组。
ControlThread负责控制每个扫描算子的扫描进度。
扫描快的工作进程能多扫描逻辑的数据切片。
过程中需要考虑Buffer的亲和性。
尽管是动态分配,尽量维护Buffer的亲和性。另外,每个算子的上下文存储在worker的私有内存中,Coordinator不存储具体表的信息。
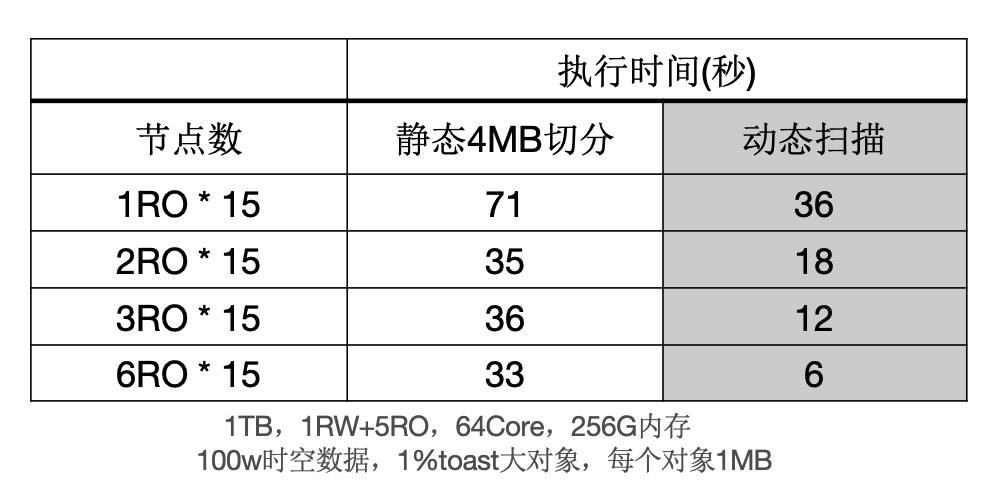
下面表格中,当出现大对象时,静态切分出现数据倾斜,而动态扫描仍然能够线性提升。
SQL级别弹性扩展
利用数据共享的特点,还可以支持云原生下极致弹性的要求。将Coordinator全链路上各个模块所需要的外部依赖存在共享存储上,同时worker全链路上需要的运行时参数通过控制链路从Coordinator同步过来,使Coordinator和worker无状态化。
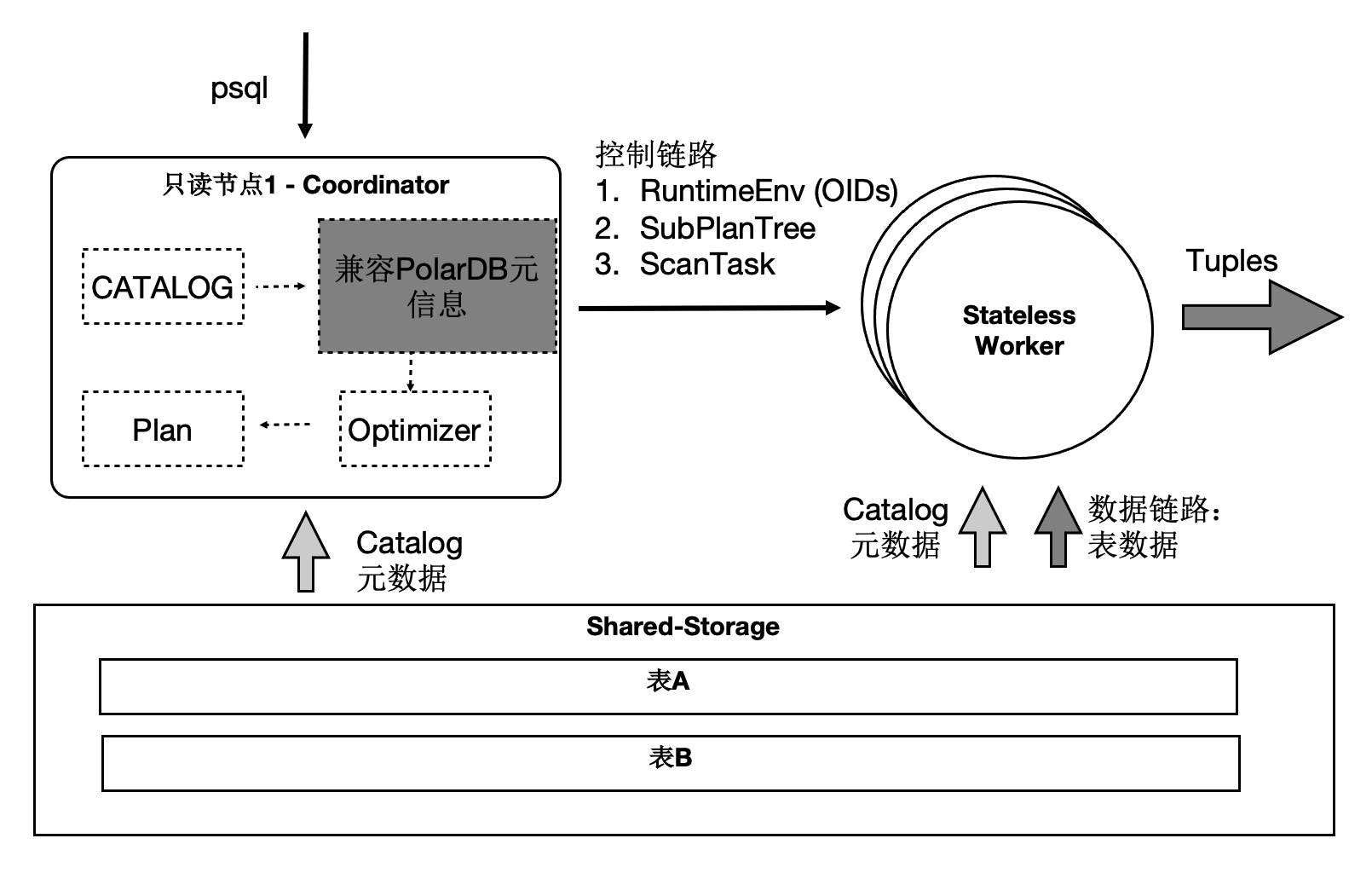
因此:
SQL连接的任意只读节点都可以成为Coordinator节点,这解决了Coordinator单点问题。
支持不同的SQL使用不同的CPU数目执行,灵活的配置不同业务SQL配置不同的CPU核心数。
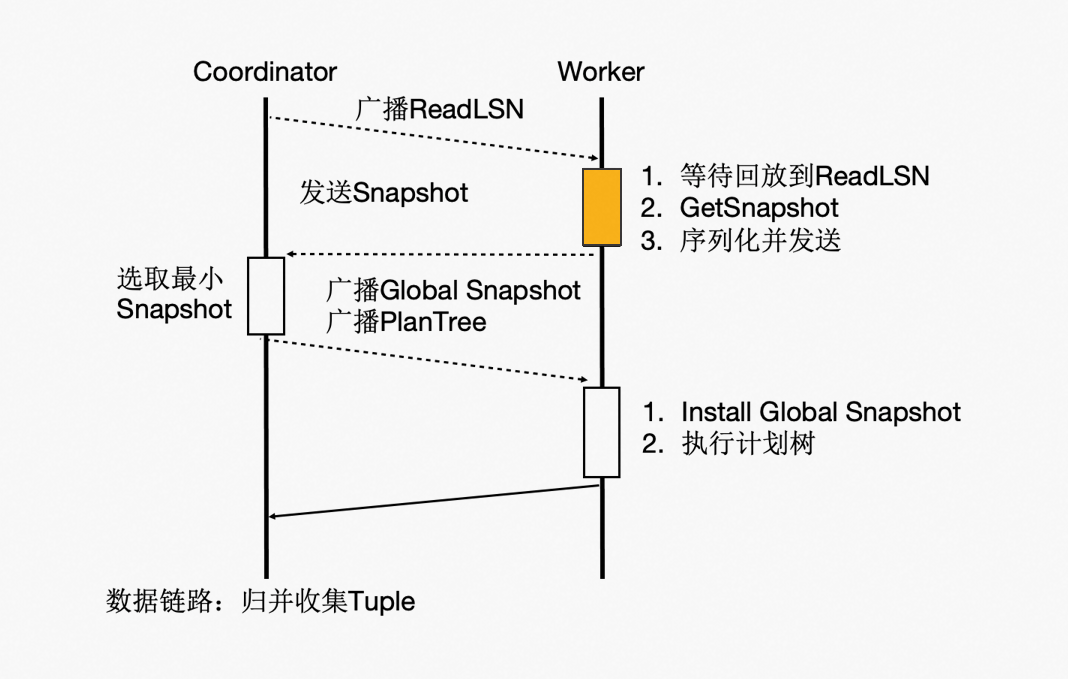
事务一致性
多个计算节点数据一致性通过等待回放和globalsnapshot机制来完成。等待回放保证所有worker能看到所需要的数据版本,而globalsnapshot保证了选出一个统一的版本。
TPC-H性能:加速比
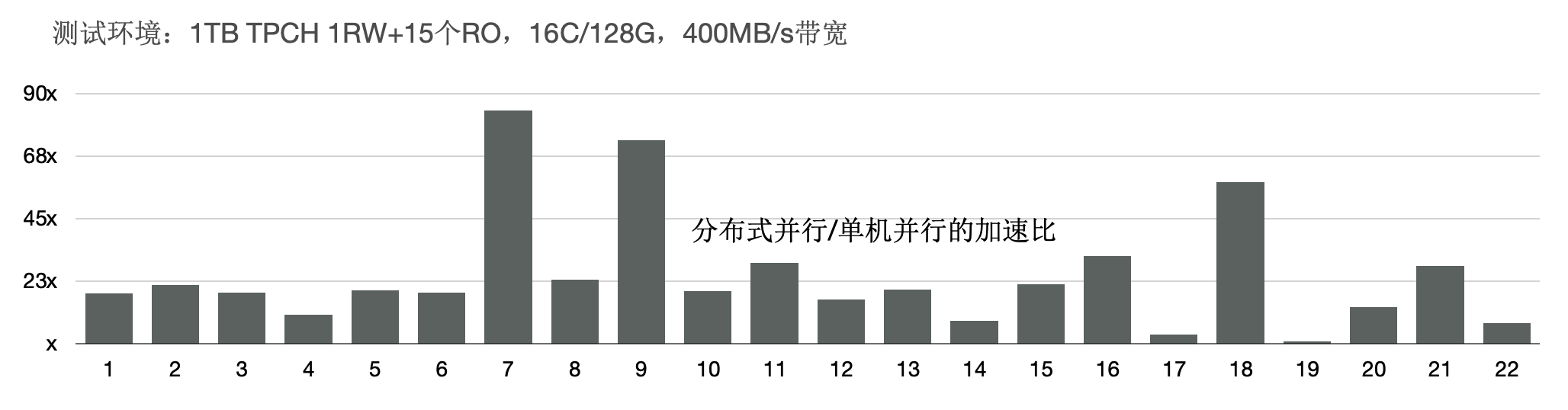
使用1 TB的TPC-H进行了测试,首先对比了PolarDB PostgreSQL版新的分布式并行和单机并行的性能,有3条SQL提速60倍,19条SQL提速10倍以上。
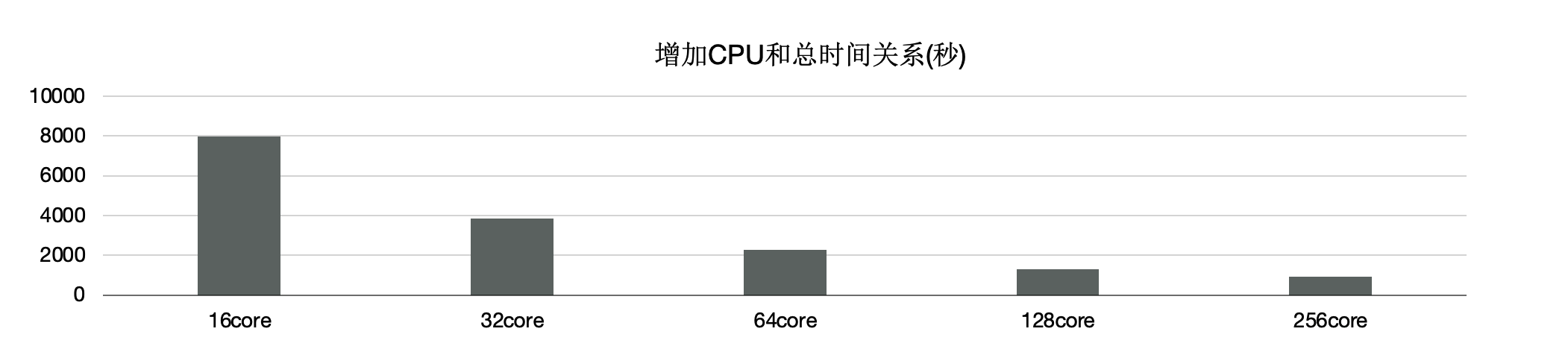
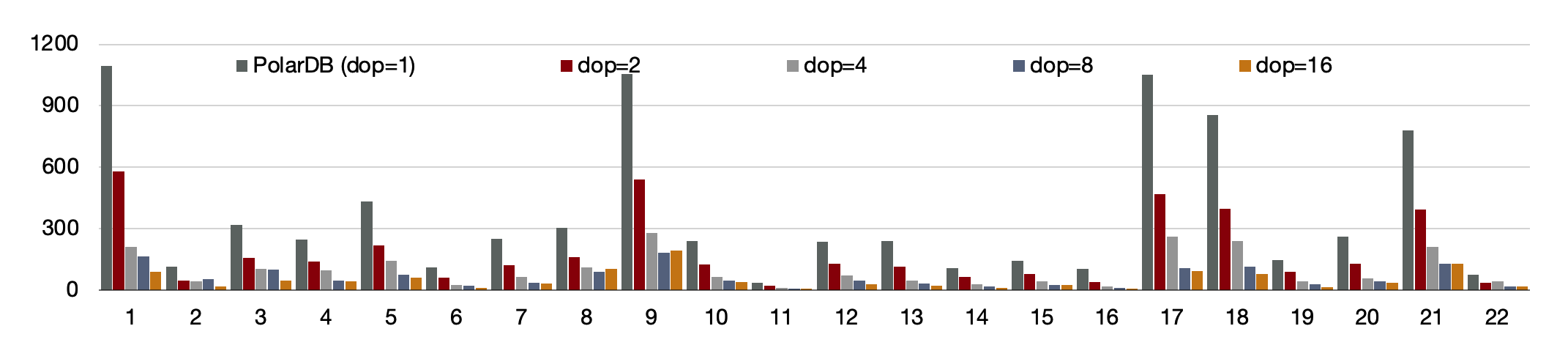
此外,使用分布式执行引擎测试,增加CPU时的性能,可以看到,从16核和128核时性能线性提升。单看22条SQL,通过增加CPU,每条SQL性能线性提升。
TPC-H性能:和传统MPP数仓对比
和传统MPP数仓对比,同样使用16个节点,PolarDB PostgreSQL版的性能是传统MPP数仓的90%。

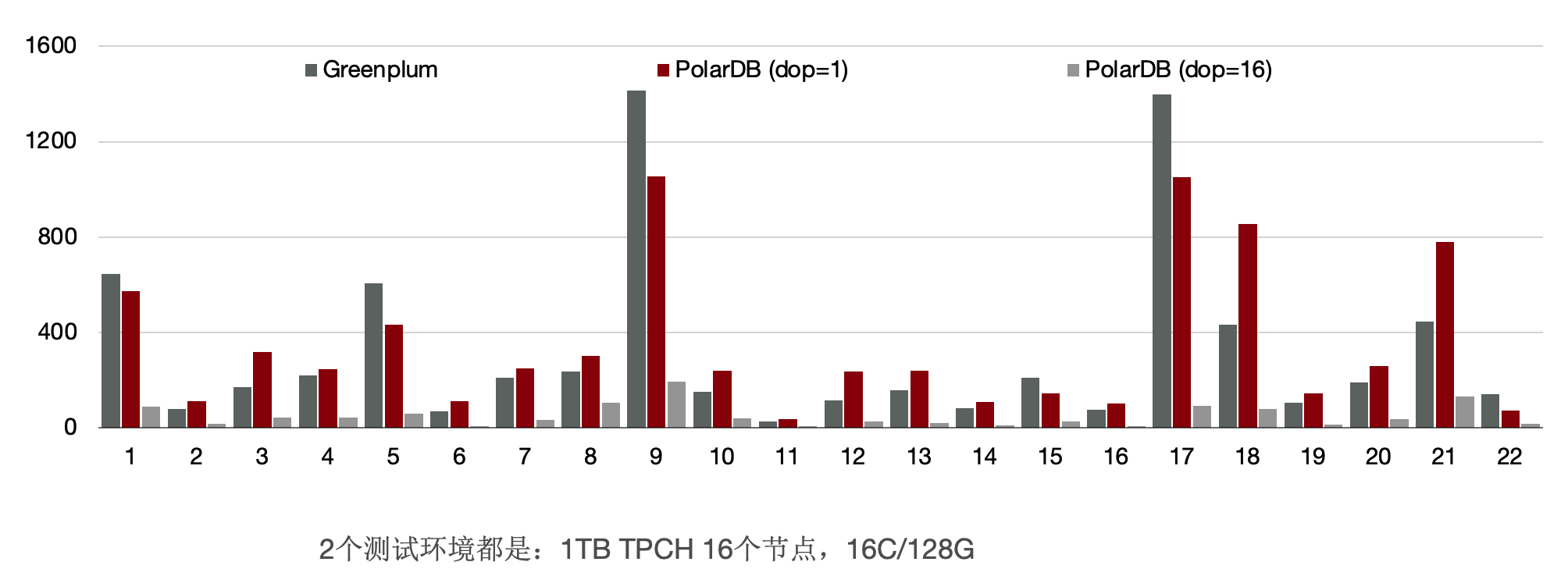
前面讲到给PolarDB PostgreSQL版的分布式引擎做到了弹性扩展,数据不需要充分重分布,当dop=8时,性能是传统MPP数仓的5.6倍。
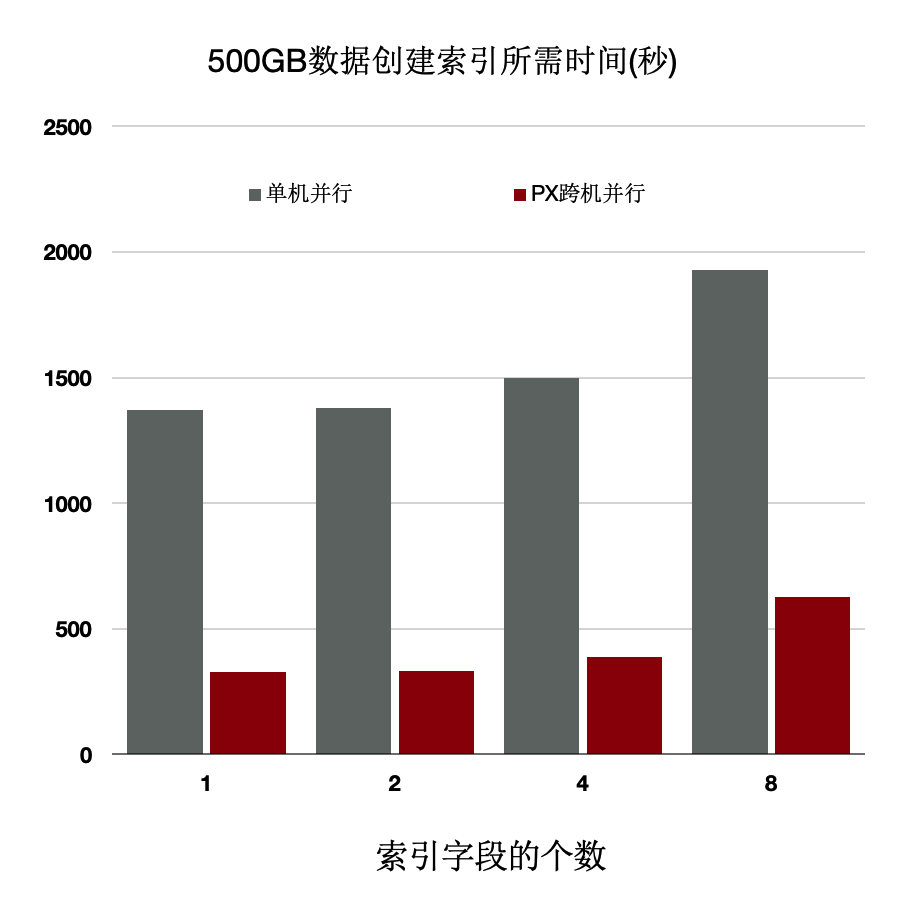
分布式执行加速索引创建
OLTP业务中会建大量的索引,经分析建索引过程中,80%是在排序和构建索引页,20%在写索引页。通过使用分布式并行来加速排序过程,同时流水化批量写入。
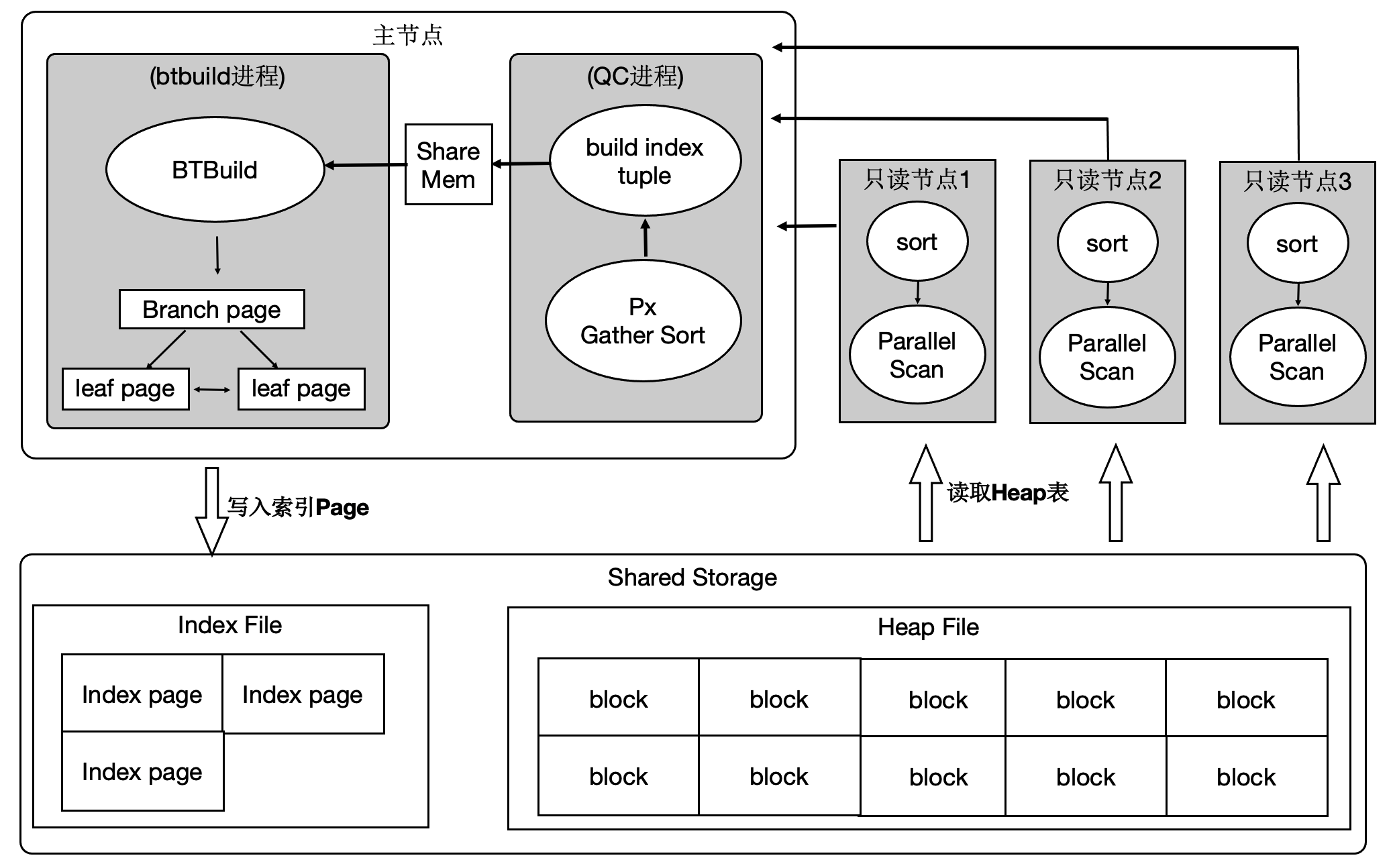
上述优化能够使得创建索引有4~5倍的提升。
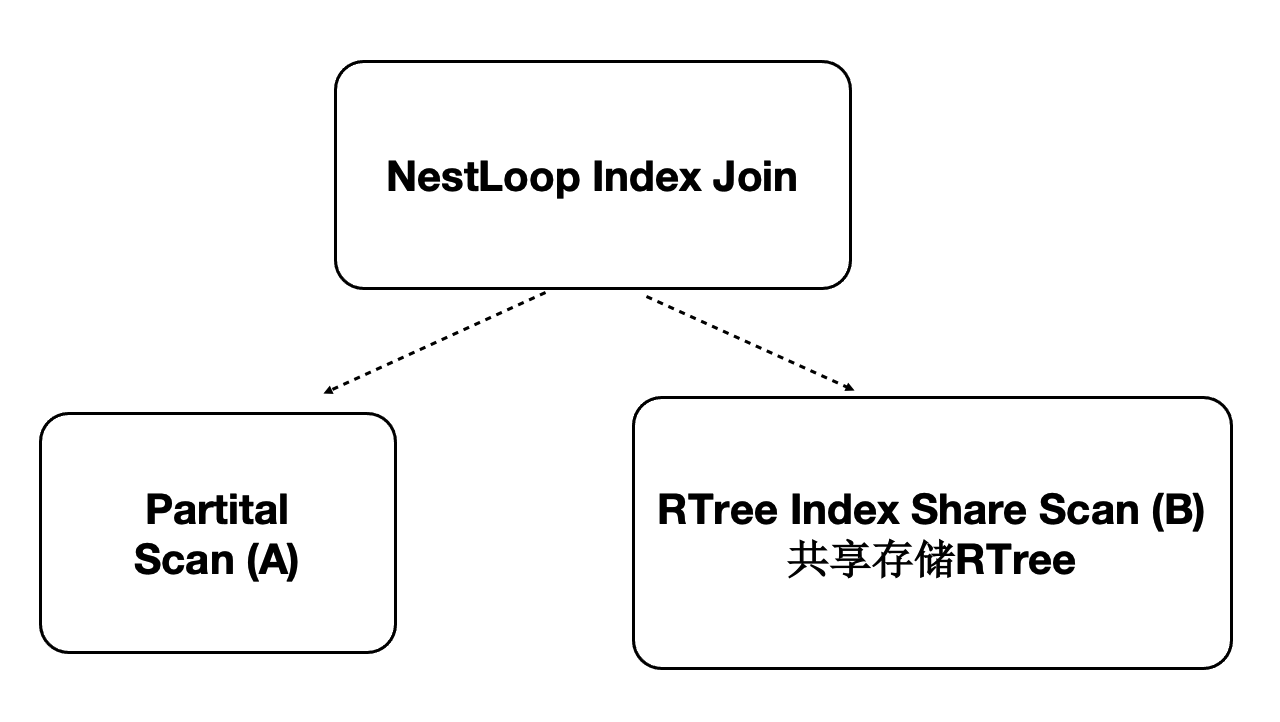
分布式并行执行加速多模:时空数据库
PolarDB PostgreSQL版是对多模数据库,支持时空数据。时空数据库是计算密集型和IO密集型,可以借助分布式执行来加速。PolarDB PostgreSQL版针对共享存储推出了扫描共享RTREE索引的功能。
数据量:40000万,500 GB。
规格:5个只读节点,每个节点规格为16核CPU、128 GB内存。
性能:
随CPU数目线性提升。
80核CPU时,提升71倍。