
阿里云流数据处理平台数据总线DataHub是流式数据(Streaming Data)的处理平台,提供流式数据的发布 (Publish)、订阅(Subscribe)和分发功能,支持构建基于流式数据的分析和应用。
产品概述
数据总线(DataHub)是阿里云提供的一款流式数据(Streaming Data)处理平台,核心功能包括流式数据的发布(Publish)、订阅(Subscribe)与分发,支持构建基于流式数据的分析和应用。
主要能力
数据采集:DataHub服务对各种移动设备、应用软件、网站服务及传感器等多种来源产生的大量流式数据,进行持续采集、存储和处理。
实时处理:写入DataHub的流式数据(如Web访问日志、应用事件等)可通过流计算引擎(如StreamCompute)或自定义应用程序处理,以生成实时图表、报警信息、统计数据等实时的数据处理结果。
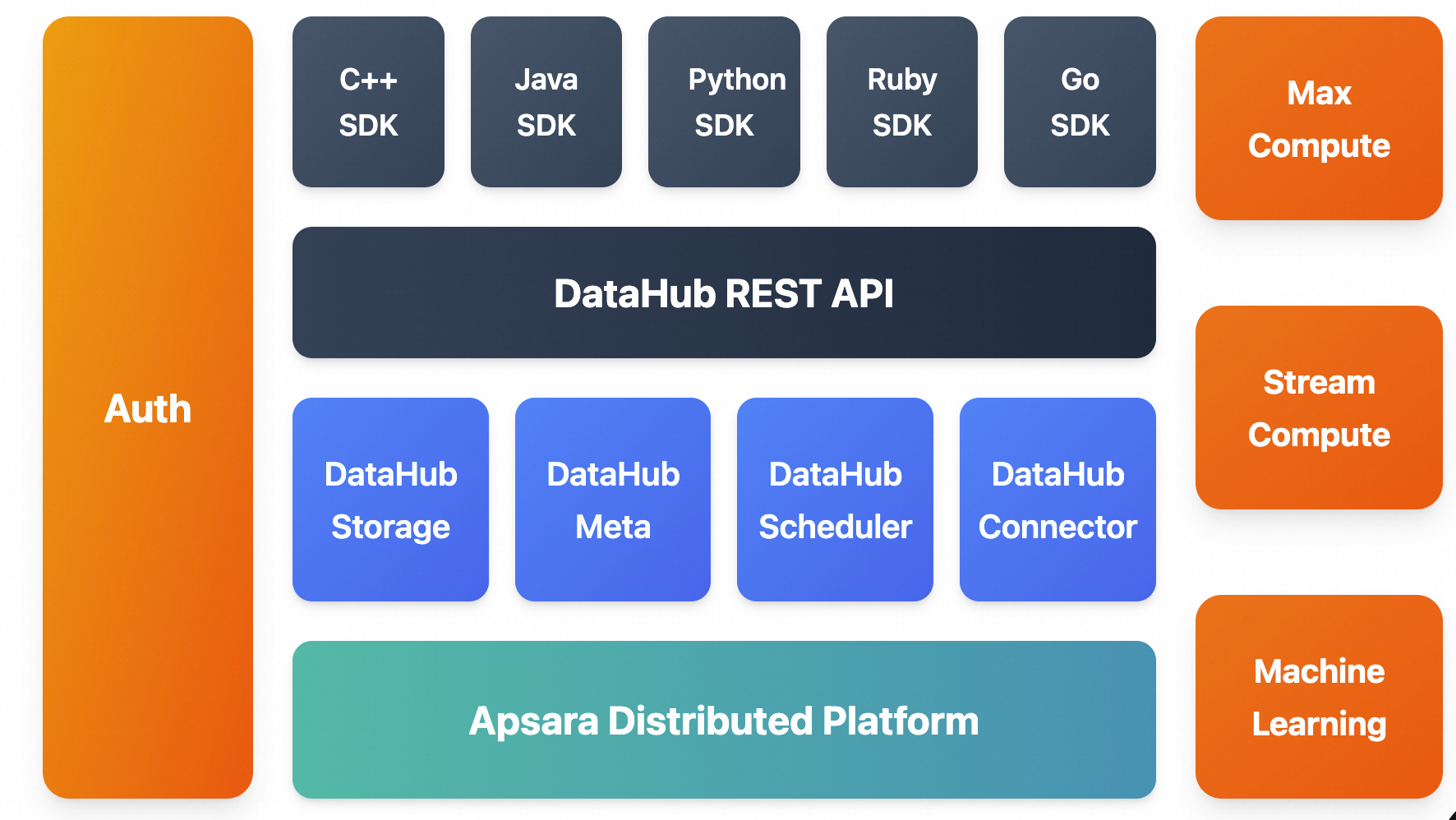
整体架构
DataHub基于阿里云自研的飞天分布式平台,具有高可用、低延迟、高可扩展、高吞吐的特点。
通过统一的REST API对外提供能力,上层应用可通过多语言SDK与之交互。
同时DataHub也与MaxCompute、StreamCompute等云产品或计算引擎无缝连接,支持使用SQL进行流数据分析。
DataHub服务也提供分发流式数据到各种云产品的功能,目前支持分发到MaxCompute(原ODPS),OSS等。
产品优势
高吞吐:最高支持单Shard每日1.6亿级别的写入量。
实用性:实时收集不同来源数据并实时处理,快速响应业务。
易用性
提供包括C++、Java、Python、Go等语言的SDK包。
提供Restful API规范,支持自定义实现访问接口。
提供包括Fluentd、Logstash、Flume等常用的客户端插件。
支持强Schema的结构化数据(创建Tuple类型的Topic)和无类型的非结构化数据(创建Blob类型的Topic)。
高可用
服务可用性不低于99.9%。
数据持久性不低于99.999%。
规模自动扩展,不影响对外服务。
数据自动多重冗余备份。
动态伸缩
每个主题(Topic)的数据流吞吐能力可以动态扩展和减少,最高可达到每主题
256000 Records/s的吞吐量。高安全性
提供企业级多层次安全防护,多用户资源隔离机制。
提供多种鉴权和授权机制及白名单、主子账号功能。
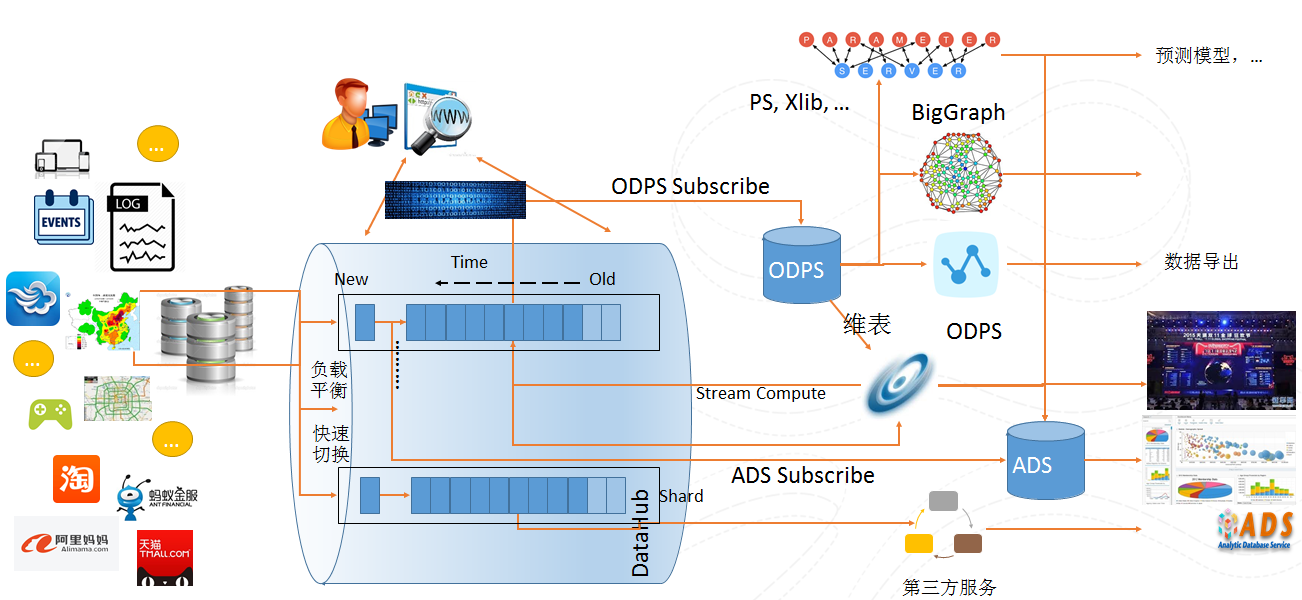
使用场景
数据总线DataHub作为流式数据处理服务,可以结合阿里云众多云产品,构建一站式的数据处理服务。
流计算StreamCompute
实时计算Flink是阿里云提供的流计算引擎,提供使用类SQL的语言来进行流式计算。数据总线DataHub和StreamCompute无缝结合,可以作为StreamCompute的数据源和输出源,具体可参考实时计算(流计算)。
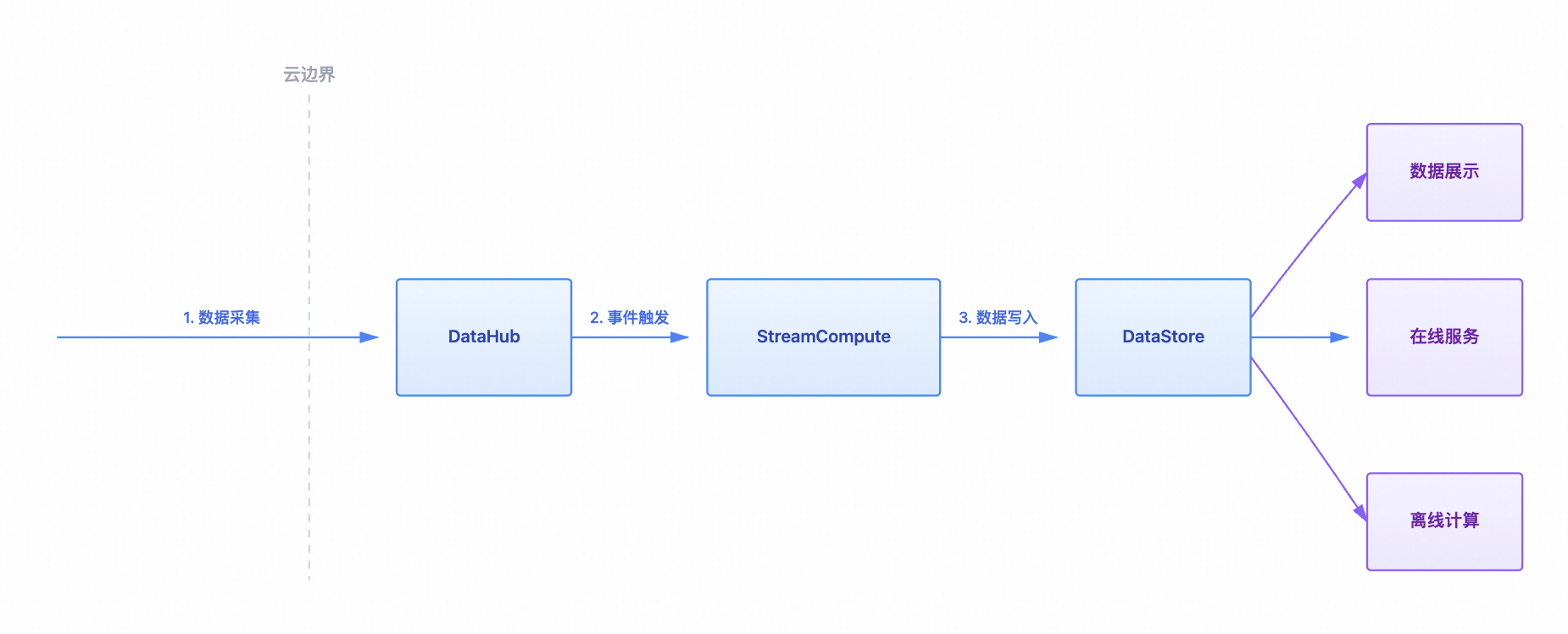
流处理应用
支持用户自定义应用订阅数据总线DataHub中的数据,并实时加工,输出处理结果。应用计算产生的结果可以进一步输出到数据总线DataHub中,并使用另外一个应用来处理上一个应用生成的流式数据,从而构建出数据处理流程的DAG。
流式数据归档
流式数据可以归档到MaxCompute(原ODPS)中。通过创建数据总线DataHub Connector,指定相关配置,即可创建将数据总线DataHub中流式数据定期归档的同步任务。