Apache Spark是一个通用的开源的分布式处理系统,通常用于大数据工作负载。Spark既支持使用SQL,又支持编写多种语言的DataFrame代码,兼具易用性和灵活性。Spark通用化的引擎能力可以同时提供SQL、批处理、流处理、机器学习和图计算的能力。
AnalyticDB MySQL Serverless Spark是
AnalyticDB MySQL团队基于Apache Spark打造的服务化的大数据分析与计算服务,开通
AnalyticDB MySQL服务后只需简单的配置,就可以提交Spark作业,无需关心Spark集群部署。方案架构图如下所示:
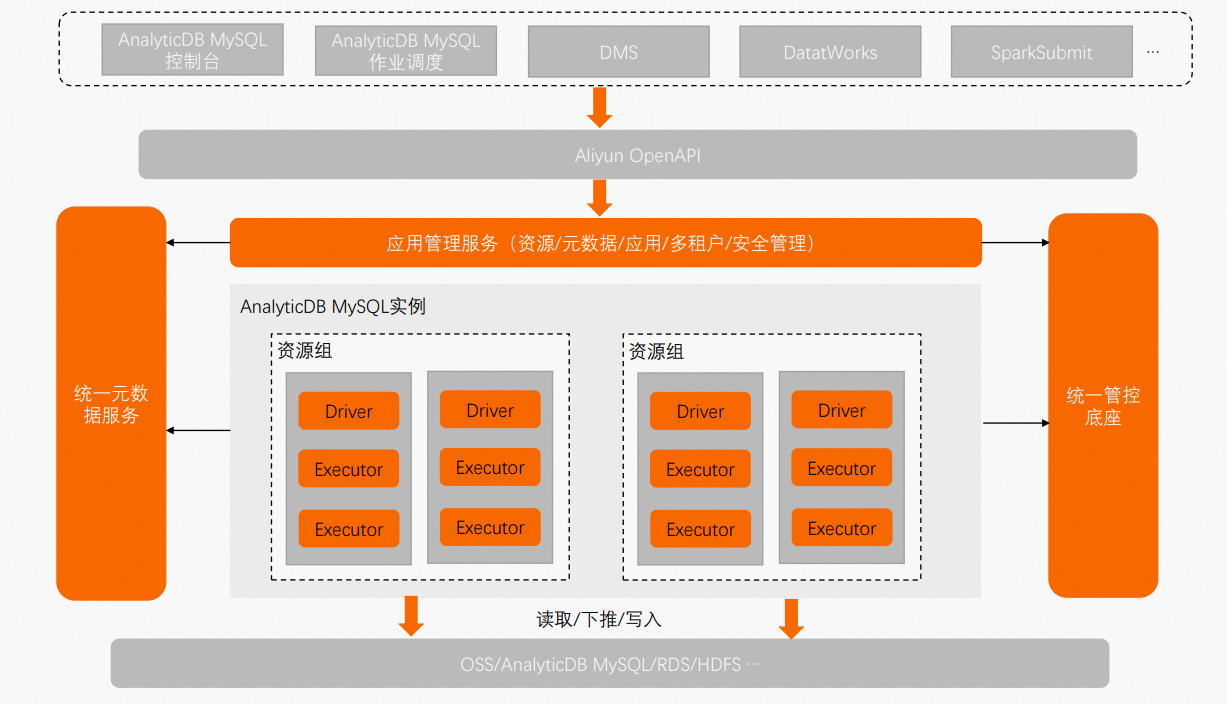
Serverless Spark将Spark、Serverless和云原生技术深度整合到一起,相对于传统开源Spark集群版方案,具有以下优势:
- 使用门槛低
- Serverless Spark屏蔽掉了底层的基础组件,提供了简单的API、脚本以及控制台使用方式,开发者了解开源Spark的使用方式就可以进行大数据业务开发。
- 0运维
- 用户只需通过 AnalyticDB MySQL Serverless Spark接口管理Spark作业,无需关心服务器配置以及Hadoop集群配置,无需处理扩缩容等运维操作。
- 作业级弹性
- Serverless Spark按照Driver和Executor粒度申请创建资源,支持秒级拉起,可以快速响应业务资源需求。
- 更低成本
- Spark作业按需使用资源,不需要长期保有预留资源,使用时再弹起资源,并按弹起的资源计费。不使用不收取费用。
- 良好的性能
- AnalyticDB MySQL团队对Spark引擎做了深度定制和优化,如针对对象存储OSS的访问,典型场景下性能可以提升至原来的3~5倍;同时Spark与 AnalyticDB MySQL数仓深度集成,典型场景下相比JDBC方式性能可以提升至原来的6倍;基于 AnalyticDB MySQL+Spark提供Zero-ETL解决方案。