本文通过示例为您介绍如何基于EMR Serverless StarRocks构建分钟级准实时分析。
前提条件
- 已创建DataFlow集群或自定义集群,具体操作请参见创建集群。
- 已创建EMR Serverless StarRocks实例,具体操作请参见创建实例。
- 已创建RDS MySQL,具体操作请参见创建RDS MySQL实例。
- 已创建EMR Studio集群,并开通了8443、8000和8081端口,具体操作请参见创建EMR Studio集群和添加安全组规则。
说明 本文示例中DataFlow集群为EMR-3.40.0版本、MySQL为5.7版本。
使用限制
- DataFlow集群、StarRocks集群和RDS MySQL实例需要在同一个VPC下,并且在同一个可用区下。
- DataFlow集群和StarRocks集群均须开启公网访问。
- RDS MySQL为5.7及以上版本。
场景介绍
该场景与数仓场景:即席查询构建数仓的逻辑基本一致,都是直接在StarRocks中进行数仓分层建模,区别在于分钟级准实时场景将即席查询场景中的视图部分物化成了表,因此具有更高的计算效率,可以支撑更高的QPS查询。
方案架构
分钟级准实时场景的基本架构如下图所示。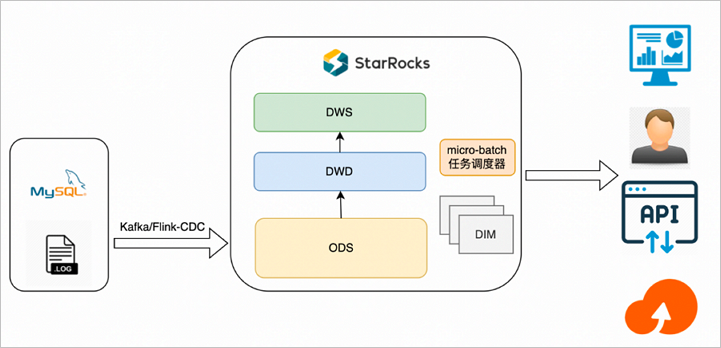
整体数据流如下:
- Flink清洗导入Kafka的日志或者通过Flink-CDC-StarRocks工具读取MySQL Binlog导入StarRocks,根据需要选用明细、聚合、更新、主键各种模型,只物理落地ODS层。
- 利用第三方任务调度器(例如Airflow)将各层数据表按血缘关系进行任务编排,再按具体的分钟间隔作为一个微批粒度进行任务调度,依次构建ODS之上的各层数据表。
方案特点
该方案主要特点是:计算逻辑在StarRocks侧,适用于高频查询场景,各层数据表按具体的分钟间隔时间作为微批粒度的数据同步。
- 将操作层(ODS层)的数据经过简单的清理、关联,然后存储到明细数据,暂不做过多的二次加工汇总,明细数据直接写入StarRocks。
- DWD或DWS层为实际的物理表,可以通过DataWorks或Airflow等调度工具调度周期性写入数据。
- StarRocks通过表的形式直接对接上层应用,实现应用实时查询。
- 前端实时请求实际的物理表,数据的实时性依赖DataWorks或Airflow调度周期配置,例如5分钟调度、10分钟调度等。
方案优势
- 查询性能强,上层应用只查询最后汇总的数据,相比View,查询的数据量更大,性能会更强。
- 数据重刷快,当某一个环节或者数据有错误时,重新运行DataWorks或Airflow调度任务即可。因为所有的逻辑都是固化好的,无需复杂的订正链路操作。
- 业务逻辑调整快,当需要新增或者调整各层业务,可以基于SQL所见即所得开发对应的业务场景,业务上线周期缩短。
方案缺点
因为引入了更多的加工和调度,所以时效性低于即席查询场景。
适用场景
数据来源于数据库和埋点系统,对QPS和实时性均有要求,适合80%实时数仓场景使用,能满足大部分业务场景需求。
操作流程
示例操作如下:
步骤一:创建MySQL源数据表
- 创建测试的数据库和账号,具体操作请参见创建数据库和账号。创建完数据库和账号后,需要授权测试账号的读写权限。说明 本文示例中创建的数据库名称为flink_cdc,账号为emr_test。
- 使用创建的测试账号连接MySQL实例,具体操作请参见通过DMS登录RDS MySQL。
- 执行以下命令,创建数据库和数据表。
CREATE DATABASE IF NOT EXISTS flink_cdc; CREATE TABLE flink_cdc.orders ( order_id INT NOT NULL AUTO_INCREMENT, order_revenue FLOAT NOT NULL, order_region VARCHAR(40) NOT NULL, customer_id INT NOT NULL, PRIMARY KEY ( order_id ) ); CREATE TABLE flink_cdc.customers ( customer_id INT NOT NULL, customer_age INT NOT NULL, customer_name VARCHAR(40) NOT NULL, PRIMARY KEY ( customer_id ) );
步骤二:创建StarRocks表
- 连接EMR Serverless StarRocks实例,详情请参见连接StarRocks实例(客户端方式)。
- 执行以下命令,创建数据库。
CREATE DATABASE IF NOT EXISTS `flink_cdc`; - 执行以下命令,创建ODS表。
CREATE TABLE IF NOT EXISTS `flink_cdc`.`customers` ( `timestamp` DateTime NOT NULL COMMENT "", `customer_id` INT NOT NULL COMMENT "", `customer_age` FLOAT NOT NULL COMMENT "", `customer_name` STRING NOT NULL COMMENT "" ) ENGINE=olap PRIMARY KEY(`timestamp`, `customer_id`) COMMENT "" DISTRIBUTED BY HASH(`customer_id`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" ); CREATE TABLE IF NOT EXISTS `flink_cdc`.`orders` ( `timestamp` DateTime NOT NULL COMMENT "", `order_id` INT NOT NULL COMMENT "", `order_revenue` FLOAT NOT NULL COMMENT "", `order_region` STRING NOT NULL COMMENT "", `customer_id` INT NOT NULL COMMENT "" ) ENGINE=olap PRIMARY KEY(`timestamp`, `order_id`) COMMENT "" DISTRIBUTED BY HASH(`order_id`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" ); - 执行以下命令,创建DWD表。
CREATE TABLE IF NOT EXISTS `flink_cdc`.`dwd_order_customer_valid`( `timestamp` DateTime NOT NULL COMMENT "", `order_id` INT NOT NULL COMMENT "", `order_revenue` FLOAT NOT NULL COMMENT "", `order_region` STRING NOT NULL COMMENT "", `customer_id` INT NOT NULL COMMENT "", `customer_age` FLOAT NOT NULL COMMENT "", `customer_name` STRING NOT NULL COMMENT "" ) ENGINE=olap PRIMARY KEY(`timestamp`, `order_id`) COMMENT "" DISTRIBUTED BY HASH(`order_id`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" ); - 执行以下命令,创建DWS表。
CREATE TABLE IF NOT EXISTS `flink_cdc`.`dws_agg_by_region` ( `timestamp` DateTime NOT NULL COMMENT "", `order_region` STRING NOT NULL COMMENT "", `order_cnt` INT NOT NULL COMMENT "", `order_total_revenue` INT NOT NULL COMMENT "" ) ENGINE=olap PRIMARY KEY(`timestamp`, `order_region`) COMMENT "" DISTRIBUTED BY HASH(`order_region`) BUCKETS 1 PROPERTIES ( "replication_num" = "1" );
步骤三:同步RDS中的源数据到StarRocks的ODS表
- 下载Flink CDC connector和Flink StarRocks Connector,并上传至DataFlow集群的/opt/apps/FLINK/flink-current/lib目录下。
- 拷贝DataFlow集群的/opt/apps/FLINK/flink-current/opt/connectors/kafka目录下的JAR包至/opt/apps/FLINK/flink-current/lib目录下。
- 使用SSH方式登录DataFlow集群,具体操作请参见登录集群。
- 执行以下命令,启动集群。重要 本文示例仅供测试,如果是生产级别的Flink作业请使用YARN或Kubernetes方式提交,详情请参见Apache Hadoop YARN和Native Kubernetes。
/opt/apps/FLINK/flink-current/bin/start-cluster.sh - 编写Flink SQL作业,并保存为demo.sql。执行以下命令,编辑demo.sql文件。
vim demo.sql文件内容如下所示。CREATE DATABASE IF NOT EXISTS `default_catalog`.`flink_cdc`; -- create source tables CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`orders_src`( `order_id` INT NOT NULL, `order_revenue` FLOAT NOT NULL, `order_region` STRING NOT NULL, `customer_id` INT NOT NULL, PRIMARY KEY(`order_id`) NOT ENFORCED ) with ( 'connector' = 'mysql-cdc', 'hostname' = 'rm-2ze5h9qnki343****.mysql.rds.aliyuncs.com', 'port' = '3306', 'username' = 'emr_test', 'password' = '@EMR!010beijing', 'database-name' = 'flink_cdc', 'table-name' = 'orders' ); CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`customers_src` ( `customer_id` INT NOT NULL, `customer_age` FLOAT NOT NULL, `customer_name` STRING NOT NULL, PRIMARY KEY(`customer_id`) NOT ENFORCED ) with ( 'connector' = 'mysql-cdc', 'hostname' = 'rm-2ze5h9qnki343****.mysql.rds.aliyuncs.com', 'port' = '3306', 'username' = 'emr_test', 'password' = '@EMR!010beijing', 'database-name' = 'flink_cdc', 'table-name' = 'customers' ); CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`orders_sink` ( `timestamp` TIMESTAMP NOT NULL, `order_id` INT NOT NULL, `order_revenue` FLOAT NOT NULL, `order_region` STRING NOT NULL, `customer_id` INT NOT NULL, PRIMARY KEY(`timestamp`,`order_id`) NOT ENFORCED ) with ( 'connector' = 'starrocks', 'database-name' = 'flink_cdc', 'table-name' = 'orders', 'username' = 'admin', 'password' = '', 'jdbc-url' = 'jdbc:mysql://fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com:9030', 'load-url' = 'fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com:8030', 'sink.properties.format' = 'json', 'sink.properties.strip_outer_array' = 'true', 'sink.buffer-flush.interval-ms' = '15000' ); CREATE TABLE IF NOT EXISTS `default_catalog`.`flink_cdc`.`customers_sink` ( `timestamp` TIMESTAMP NOT NULL, `customer_id` INT NOT NULL, `customer_age` FLOAT NOT NULL, `customer_name` STRING NOT NULL, PRIMARY KEY(`timestamp`,`customer_id`) NOT ENFORCED ) with ( 'connector' = 'starrocks', 'database-name' = 'flink_cdc', 'table-name' = 'customers', 'username' = 'admin', 'password' = '', 'jdbc-url' = 'jdbc:mysql://fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com:9030', 'load-url' = 'fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com:8030', 'sink.properties.format' = 'json', 'sink.properties.strip_outer_array' = 'true', 'sink.buffer-flush.interval-ms' = '15000' ); BEGIN STATEMENT SET; INSERT INTO `default_catalog`.`flink_cdc`.`orders_sink` SELECT LOCALTIMESTAMP, order_id, order_revenue, order_region, customer_id FROM `default_catalog`.`flink_cdc`.`orders_src`; INSERT INTO `default_catalog`.`flink_cdc`.`customers_sink` SELECT LOCALTIMESTAMP, customer_id, customer_age, customer_name FROM `default_catalog`.`flink_cdc`.`customers_src`; END;涉及参数如下所示:- 创建数据表orders_src和customers_src。
参数 描述 connector 固定值为mysql-cdc。 hostname RDS的内网地址。 您可以在RDS的数据库连接页面,单击内网地址进行复制。例如,rm-2ze5h9qnki343****.mysql.rds.aliyuncs.com。
port 固定值为3306。 username 步骤一:创建MySQL源数据表中创建的账号名。本示例为emr_test。 password 步骤一:创建MySQL源数据表中创建的账号的密码。 database-name 步骤一:创建MySQL源数据表中创建的数据库名。本示例为flink_cdc。 table-name 步骤一:创建MySQL源数据表中创建的数据表。 - orders_src:本示例为orders。
- customers_src:本示例为customers。
- 创建数据表orders_sink和customers_sink。
参数 描述 connector 固定值为starrocks。 database-name 步骤一:创建MySQL源数据表中创建的数据库名。本示例为flink_cdc。 table-name 步骤一:创建MySQL源数据表中创建的数据表。 - orders_sink:本示例为orders。
- customers_sink:本示例为customers。
username StarRocks连接用户名。固定值为admin。 password 不填写。 jdbc-url 用于在StarRocks中执行查询操作。 例如,jdbc:mysql://fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com:9030。其中,fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com为EMR Serverless StarRocks实例FE节点的内网地址。说明 关于如何获取EMR Serverless StarRocks实例FE节点的内网地址,请参见查看实例列表与详情。load-url 指定FE节点的内网地址和HTTP端口,格式为 EMR Serverless StarRocks实例FE节点的内网地址:8030。例如,fe-c-9b354c83e891****-internal.starrocks.aliyuncs.com:8030。说明 关于如何获取EMR Serverless StarRocks实例FE节点的内网地址,请参见查看实例列表与详情。
- 创建数据表orders_src和customers_src。
- 执行以下命令,启动Flink任务。
/opt/apps/FLINK/flink-current/bin/sql-client.sh -f demo.sql
步骤四:通过任务调度器,编排各数据层的微批同步任务
将以下两个Job以10分钟为一次间隔,编排成定时任务。
- Job 1
-- ODS to DWD INSERT INTO dwd_order_customer_valid SELECT '{start_time}', o.order_id, o.order_revenue, o.order_region, c.customer_id, c.customer_age, c.customer_name FROM customers c JOIN orders o ON c.customer_id=o.customer_id WHERE o.timestamp >= '{start_time}' AND o.timestamp < DATE_ADD('{start_time}',INTERVAL '{interval_time}' MINUTE) AND c.timestamp >= '{start_time}' AND c.timestamp < DATE_ADD('{start_time}',INTERVAL '{interval_time}' MINUTE) - Job 2
-- DWD to DWS INSERT INTO dws_agg_by_region SELECT '{start_time}', order_region, count(*) AS order_cnt, sum(order_revenue) AS order_total_revenue FROM dwd_order_customer_valid WHERE timestamp >= '{start_time}' AND timestamp < DATE_ADD('{start_time}',INTERVAL '{interval_time}' MINUTE) GROUP BY timestamp, order_region;
本示例使用EMR Studio作为任务调度器,您也可以使用自己的任务编排方案。
 图标。
图标。
 图标,运行脚本。
图标,运行脚本。


步骤五:查看数据库和表信息
- 连接EMR Serverless StarRocks实例,详情请参见连接StarRocks实例(客户端方式)。
- 执行以下命令,查询数据库信息。
show databases;返回信息如下所示。+--------------------+ | Database | +--------------------+ | _statistics_ | | information_schema | | flink_cdc | +--------------------+ 3 rows in set (0.00 sec) - 查询数据表信息。
步骤六:验证插入后的数据
- 使用步骤一:创建MySQL源数据表中创建的测试账号连接MySQL实例,具体操作请参见通过DMS登录RDS MySQL。
- 在RDS数据库窗口执行以下命令,向表orders和customers中插入数据。
INSERT INTO flink_cdc.orders(order_id,order_revenue,order_region,customer_id) VALUES(1,10,"beijing",1); INSERT INTO flink_cdc.orders(order_id,order_revenue,order_region,customer_id) VALUES(2,10,"beijing",1); INSERT INTO flink_cdc.customers(customer_id,customer_age,customer_name) VALUES(1, 22, "emr_test"); - 连接EMR Serverless StarRocks实例,详情请参见连接StarRocks实例(客户端方式)。
- 执行以下命令,查询ODS层数据。
- 执行以下命令,查询DWD层数据。
- 执行以下命令,查询DWS层数据。