
本工作流以广告CTR预测场景为例,为您介绍如何使用PAI提供的数据挖掘组件进行离线调度。
背景信息
本工作流流程如下:
-
通过历史数据,在阿里云机器学习平台上进行模型训练。
-
通过大数据开发套件对模型进行调度。
-
每天凌晨对广告投放进行CTR预测,甄选出符合标准的广告进行推送。
本工作流数据集是通过Random算法随机生成的,因此不对工作流结果进行评估,仅介绍如何构建工作流及大数据开发套件调度。
步骤一:准备数据集
本工作流训练数据集包括2016年09月19日和2016年09月20日的历史数据,针对2016年09月21日的数据进行预测,使用MaxCompute分区表。数据集的具体字段如下。
|
字段名 |
类型 |
描述 |
|
id |
STRING |
广告的唯一标识。 |
|
age |
DOUBLE |
广告投放人群的年龄。 |
|
sex |
DOUBLE |
广告投放人群的性别。1表示男性,0表示女性。 |
|
duration |
DOUBLE |
广告在界面的停留时长,单位为秒。 |
|
place |
DOUBLE |
广告投放位置,按照投放位置从上到下的顺序依次为0~4。 |
|
ctr |
DOUBLE |
广告CTR。如果广告点击量除以展现量的结果大于0.03,则该参数取值为1,反之为0。 |
|
dt |
STRING |
年月日,格式为YYYYMMDD。 |
您可以使用MaxCompute客户端执行以下命令创建分区表ad。具体操作,请参见创建表。
create table if not exists ad (id STRING,age DOUBLE,sex DOUBLE,duration DOUBLE,place DOUBLE,ctr DOUBLE ) partitioned by (dt STRING) ;
alter table ad add if not exists partition (dt='20160919') partition (dt='20160920');本工作流数据表ad的示例如下。您可以使用Tunnel命令导入分区表数据。具体操作,请参见导入数据。
|
id |
age |
sex |
duration |
place |
ctr |
dt |
|
0 |
49 |
1 |
9 |
0 |
0 |
20160919 |
|
1 |
17 |
1 |
3 |
1 |
1 |
20160919 |
|
2 |
44 |
0 |
4 |
0 |
0 |
20160919 |
|
3 |
14 |
1 |
9 |
1 |
0 |
20160919 |
|
4 |
44 |
1 |
5 |
4 |
0 |
20160919 |
|
5 |
10 |
1 |
9 |
3 |
1 |
20160919 |
|
6 |
42 |
1 |
7 |
3 |
0 |
20160919 |
|
7 |
51 |
1 |
3 |
1 |
1 |
20160919 |
|
8 |
18 |
0 |
3 |
3 |
0 |
20160919 |
|
9 |
39 |
0 |
8 |
4 |
1 |
20160919 |
|
10 |
45 |
1 |
3 |
2 |
0 |
20160919 |
|
11 |
57 |
0 |
8 |
2 |
0 |
20160919 |
|
12 |
14 |
0 |
7 |
2 |
1 |
20160919 |
步骤二:创建工作流
-
新建自定义工作流,并进入工作流,详情请参见新建自定义工作流。
-
构建工作流的流程。
-
在左侧组件列表,将源/目标下的读数据表组件向画布中拖入两个,并分别重命名为ad-1和ad-2。
-
在左侧组件列表,将数据预处理下的归一化组件向画布中拖入两个。
-
在左侧组件列表,将下的逻辑回归二分类组件拖入画布中。
-
在左侧组件列表,将机器学习下的预测组件拖入画布中。
-
在左侧组件列表,将源/目标下的写数据表组件拖入画布中,并重命名为ad_result-1。
-
将以上组件拼接为如下工作流。
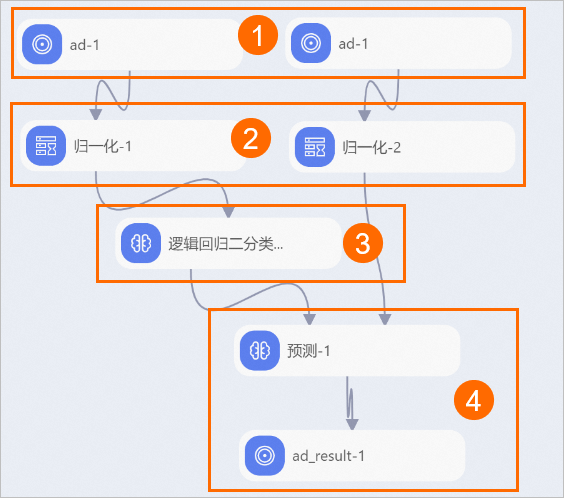
序号
描述
①
数据源导入。
②
数据预处理。
③
模型训练。
④
预测。
-
-
配置组件参数。
-
分别单击画布中的ad-2(训练数据源)和ad-1(预测数据源)组件,在右侧面板,配置工作流数据源。
页签
参数
描述
表选择
表名
输入ad。
分区
选中分区复选框。
参数
配置为 dt=@@{yyyyMMdd},确定预测数据为每天的增量数据。
字段信息
源表字段信息
配置表选择后,系统会自动同步该数据表的源表字段信息,无需手动配置。
-
分别单击画布中的归一化-1和归一化-2组件,在右侧面板字段设置页签,单击选择字段,选择DOUBLE或INT类型的字段。
-
单击画布中的逻辑回归二分类组件,在右侧面板,配置参数(仅配置如下参数,其他参数使用默认值即可)。
页签
参数
描述
字段设置
训练特征列
选择age、sex、duration及place列。
目标列
选择ctr列。
-
单击画布中的预测组件,在右侧面板,配置参数(仅配置如下参数,其他参数使用默认值即可)。
页签
参数
描述
字段设置
特征列
选择age、sex、duration及place列。
原样输出列
选择ctr列。
-
单击画布中的ad_result-1组件,在右侧面板表选择页签,配置写入表表名为ad_result。
-
-
单击画布左上方的运行按钮
 ,运行工作流。
,运行工作流。 -
工作流运行结束后,右键单击画布中的ad_result-1,在快捷菜单,单击,即可查看预测生成的结果表。
其中:
-
prediction_result:表示每个广告ID是否被点击(1表示被点击,0表示未被点击)。
-
prediction_score:表示对应被点击的概率。
-
步骤三:离线调度
-
使用DataWorks创建、配置并提交PAI任务,详情请参见创建并使用PAI Studio节点。
配置调度任务时,将具体时间配置为每日凌晨0点进行训练和推送信息,详情请参见时间属性配置。
-
在提交任务页面,单击右上方的运维,即可进入运维中心查看任务日志,详情请参见管理周期任务。
相关文档
-
您也可以通过Designer提交离线调度任务,详情请参见使用DataWorks离线调度Designer工作流。
-
关于归一化组件更详细的内容介绍,请参见归一化。
-
关于逻辑回归二分类更详细的内容介绍,请参见逻辑回归二分类。