
操作手册
【试用教程】简单日志数据分析
dide
手动配置
120
教程简介
通过本教程,您将使用一份样例日志数据,学习如何通过大数据开发治理平台DataWorks进行数据分析挖掘,提取有效用户画像数据并进行可视化展示,了解通过DataWorks进行数据开发治理的通用流程。
本教程会为您提供样例数据和公共的MySQL数据库(阿里云数据库RDS MySQL)、云存储(阿里云对象存储OSS),作为样例数据存入数据库和云存储的示例,您需要将数据同步至阿里云的大数据计算引擎MaxCompute后进行数据加工和分析,数据处理思路如图所示。
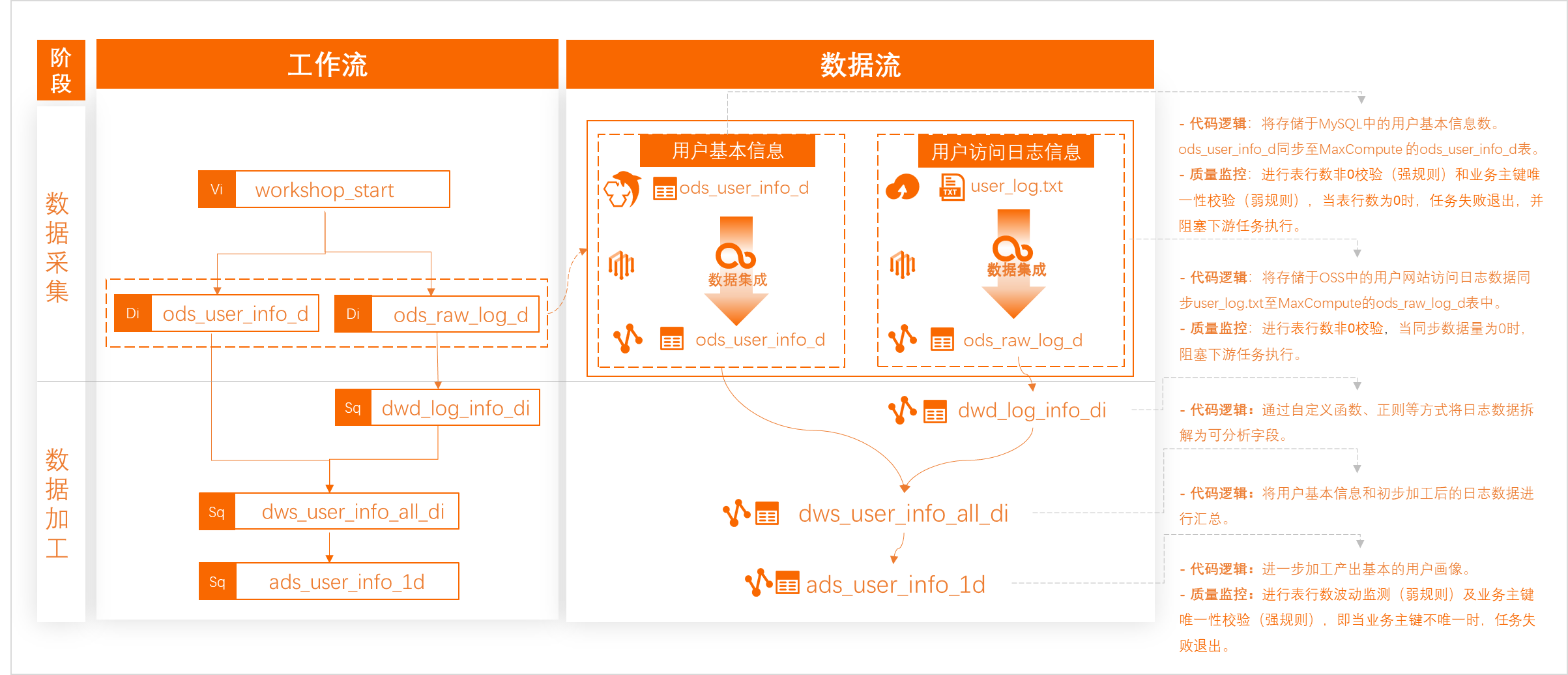
我能学到什么
熟悉通过DataWorks进行数据采集的操作流程。
熟悉通过DataWorks、MaxCompute进行数据加工的主要流程。
体验DataWorks的数据监控和简单分析能力。
操作难度 | 中 |
所需时间 | 120分钟 |
使用的阿里云产品 |
|
所需费用 |
|
准备环境和资源
5
开始教程前,请按以下步骤准备环境和资源:
访问阿里云免费试用。单击页面右上方的登录/注册按钮,并根据页面提示完成账号登录(已有阿里云账号)、账号注册(尚无阿里云账号)或实名认证(根据试用产品要求完成个人实名认证或企业实名认证)。
成功登录后,在产品类别下选择大数据计算>数据开发与服务,单击大数据开发治理平台 DataWorks产品的立即试用。
在弹出的购买试用DataWorks产品的面板上选择开通地域为华东2(上海),勾选服务协议后单击立即试用。
购买合适规格的独享数据集成资源组。详情请参见:新增和使用独享数据集成资源组。
本教程还需使用MaxCompute产品,您也可以在免费试用中申请免费额度的MaxCompute资源包进行本教程的操作,申请操作请参见申请免费试用MaxCompute。
准备数据开发环境
10
创建DataWorks工作空间。
登录DataWorks控制台,单击左侧导航栏的工作空间列表,选择工作空间地域为华东2(上海)后,单击创建工作空间。在创建工作空间面板,配置工作空间信息后单击提交。其中核心配置参数如表所示,其他参数可自定义配置或保持默认值即可。
参数
描述
工作空间名称
可自定义工作空间名称。由于工作空间名称需要全局唯一,如果后续操作时提示名称已存在,可更换名称。
本案例设置工作空间名称为doc_test。
生产、开发环境隔离
本教程选择:是。即将开发和生产隔离。
【扩展知识】
DataWorks的工作空间分为简单模式和标准模式:
简单模式:指一个DataWorks工作空间对应一个引擎项目,无法设置开发和生产环境,只能进行简单的数据开发,无法对数据开发流程以及表权限进行强控制。
标准模式:指一个DataWorks工作空间对应两个引擎项目,可以设置开发和生产两种环境,提升代码开发规范,并能够对表权限进行严格控制,禁止随意操作生产环境的表,保证生产表的数据安全。
详情请参见必读:简单模式和标准模式的区别。
绑定MaxCompute数据源。
MaxCompute为计费产品,您可以绑定已有的MaxCompute,或新绑定一个MaxCompute数据源。您也可以在免费试用中申请免费额度的MaxCompute资源包进行本教程的操作,申请操作请参见使用内置公开数据集快速体验MaxCompute。
如果您此前已在上海地域开通了MaxCompute服务,可直接绑定您已有的MaxCompute数据源,绑定操作请参见创建MaxCompute数据源。
如果您此前没有开通过MaxCompute服务,可参见下文绑定一个新的MaxCompute数据源,绑定后即会为您自动开通MaxCompute服务并创建好对应的项目。
在工作空间创建成功界面的大数据优质数据源类型推荐区域,单击MaxCompute数据源后的立即绑定。根据界面指引配置数据源绑定信息。其中核心配置参数如表所示,其他参数可保持默认值即可。
DataWorks支持通过如下两种方式创建数据源。
方式一:通过已有MaxCompute项目创建数据源方式二:通过新建MaxCompute项目创建数据源若您已有MaxCompute项目,则可将已有MaxCompute项目添加为当前工作空间的数据源。
通过该方式新建数据源,需拥有MaxCompute的odps:ListProjects权限,以及目标MaxCompute项目的Super_Administrator权限。
创建数据源配置如下。
配置基础信息。
参数
说明
数据源名称
定义数据源在DataWorks的名称,名称必须唯一。
地域
MaxCompute项目所在地域。
说明若选择的MaxCompute项目与当前工作空间不在同一地域,则将MaxCompute项目添加为数据源后,该数据源不支持绑定为工作空间的计算引擎,即不支持在数据开发(DataStudio)、运维中心使用,仅用于数据集成模块进行数据同步。
MaxCompute项目名称
选择需将指定地域下哪一个MaxCompute项目添加为当前工作空间的数据源。
说明如果未保有MaxCompute项目,请根据提示信息创建项目。创建方法详情请参见方式二:通过新建MaxCompute项目创建数据源。
默认访问身份
定义在当前工作空间下,用什么身份访问该数据源。
开发环境:当前仅支持使用执行者身份访问。
生产环境:支持使用阿里云主账号、阿里云RAM用户(即子账号)、阿里云RAM角色访问。
说明生产环境下默认访问身份选择相关知识的详细介绍,请参见创建MaxCompute数据源。
说明如对其他参数配置信息存有疑惑,详细介绍请参见创建MaxCompute数据源。
测试资源组连通性。
您需根据数据源后续的用途,在连接配置区域对应资源组类型后,测试所需资源组的连通性。若资源组与数据源无法连通,则相应数据源任务将无法正常执行。
说明数据源创建成功后平台会进行访问身份授权,即将访问身份账号添加至MaxCompute项目中,并为该身份映射MaxCompute对应的权限。在授权完成前,连通性测试可能会产生连通无权限报错,该场景下,保存数据源后,您需稍作等待。
单击完成创建。
若您没有可用MaxCompute项目,则可新建MaxCompute项目并将其添加为当前工作空间的数据源。
通过该方式新建数据源,需拥有MaxCompute的odps:CreateProject权限。若使用RAM用户或角色创建数据源,数据源创建完成后,该RAM用户或角色将被MaxCompute项目添加为Super_Administrator。
说明通过该方式新建数据源,会默认将工作空间内存量和新增用户均加入至MaxCompute开发项目。同时,用户所拥有的角色会映射相应预设MaxCompute角色。详情请参见附录:空间级预设角色与MaxCompute引擎权限的映射关系。
创建数据源配置如下。
配置基础信息。
参数
说明
数据源名称
定义数据源在DataWorks的名称,名称必须唯一。
项目名称
创建的MaxCompute项目命称。建议按如下规范命名:
生产环境:project_name
开发环境:project_name_dev
默认Quota
定义MaxCompute项目使用的计算资源池。关于Quota相关说明详情请参见配额。
单SQL消费限制
用于设置单个SQL语句的消费阈值,预防单个SQL语句产生高额费用。
默认访问身份
定义在当前工作空间下,用什么身份访问该数据源。
开发环境:当前仅支持使用执行者身份访问。
生产环境:支持使用阿里云主账号、阿里云RAM用户(即子账号)、阿里云RAM角色访问。
说明生产环境下默认访问身份选择相关知识的详细介绍,请参见创建MaxCompute数据源。
说明如对其他参数配置信息存有疑惑,详细介绍请参见创建MaxCompute数据源。
测试资源组连通性。
您需根据数据源后续的用途,在连接配置区域对应资源组类型后,测试所需资源组的连通性。若资源组与数据源无法连通,则相应数据源任务将无法正常执行。
说明数据源创建成功后平台会进行访问身份授权,即将访问身份账号添加至MaxCompute项目中,并为该身份映射MaxCompute对应的权限。在授权完成前,连通性测试可能会产生连通无权限报错,该场景下,保存数据源后,您需稍作等待。
单击完成创建。
采集数据:新建数据源
25
新建HttpFile数据源。
登录DataWorks控制台,单击左侧导航栏的工作空间列表,找到上述步骤创建的工作空间后,单击操作列的管理,进入管理中心。
进入管理中心页面后,单击左侧导航栏的数据源,进入数据源页面。在数据源页面,单击新增数据源,选择HttpFile,在创建HttpFile数据源对话框配置各项参数。其中核心配置参数如下表所示,其他参数可自定义配置或保持默认值即可。
参数
描述
数据源名称
输入数据源名称,本案例中设置数据名称为user_behavior_analysis_httpfile。
数据源描述
输入DataWorks案例体验专用数据源,在离线同步配置时读取该数据源即可访问平台提供的测试数据,该数据源只支持数据集成场景去读取,其他模块不支持使用。
适用环境
勾选开发环境和生产环境。
说明您需要同步创建开发环境及生产环境的数据源,否则任务生产执行会报错。
URL域名
输入
https://dataworks-workshop-2024.oss-cn-shanghai.aliyuncs.com。资源组连通性
在连接配置区域的独享数据集成资源组后,单击连通状态列的测试连通性,界面提示可连通后说明资源组与数据源的网络是连通的。
单击完成创建,完成HttpFile数据源的添加。
新建MySQL数据源(本教程即是阿里云RDS MySQL)。
操作步骤与新建OSS数据源类似,数据源的核心配置参数如表所示。其中核心配置参数如表所示,其他参数可自定义配置或保持默认值即可。
参数
描述
数据源类型
选择连接串模式。
数据源名称
输入user_behavior_analysis_mysql。
数据源描述
输入DataWorks案例体验专用数据源,在离线同步配置时读取该数据源即可访问平台提供的测试数据,该数据源只支持数据集成场景去读取,其他模块不支持使用。
适用环境
勾选开发和生产。
JDBC URL
输入jdbc:mysql://rm-bp1z69dodhh85z9qa.mysql.rds.aliyuncs.com:3306/workshop。
用户名
输入workshop。
密码
输入workshop#2017。
说明本密码仅为本教程的公共数据源示例密码,请勿在后续您的实际业务中使用。
资源组连通性
在连接配置区域的独享数据集成资源组后,单击连通状态列的测试连通性,界面提示可连通后说明资源组与数据源的网络是连通的。
采集数据:配置业务流程
30
登录DataWorks控制台,单击左侧导航栏的工作空间列表,找到上述步骤创建的工作空间后,选择操作列的快速进入,单击数据开发,进入数据开发页面。
进入数据开发页面后,单击左侧导航栏的数据源,进入数据源页面。在数据源页面,找到上述步骤中创建的数据源后进行绑定操作。绑定后,才能基于数据源的连接信息读取该数据源的数据,进行后续操作。
说明当数据源信息发生变更时,若当前界面数据更新不及时,请刷新当前页面更新缓存数据。
单击左侧导航栏的数据开发,进入数据开发页面。双击页面左侧业务流程下的Workflow,打开默认的Workflow业务流程面板。
本教程使用默认的Workflow业务流程进行数据采集和开发,后续您在实际使用的时候,可根据实际业务情况,为不同业务规划并创建不同业务流程。
新建两个目标表,用于后续同步OSS日志数据(表ods_raw_log_d)和MySQL日志数据(表ods_user_info_d)。
右键单击Workflow后,单击新建表>MaxCompute>表,根据界面提示输入表名ods_raw_log_d完成表创建。
在表格配置页面的基本属性中,自定义配置中文名。
单击顶部的DDL,复制建表语句后单击生成表结构,确认覆盖。
--创建OSS日志对应目标表 CREATE TABLE IF NOT EXISTS ods_raw_log_d ( col STRING ) PARTITIONED BY ( dt STRING );分别单击顶部提交到开发环境、提交到生产环境,将新建的表提交的开发和生产环境中。
重复上述建表操作,新建并提交一个表名为ods_user_info_d的表。
--创建MySQL对应目标表 CREATE TABLE IF NOT EXISTS ods_user_info_d ( uid STRING COMMENT '用户ID', gender STRING COMMENT '性别', age_range STRING COMMENT '年龄段', zodiac STRING COMMENT '星座' ) PARTITIONED BY ( dt STRING );
新建并配置虚拟节点。
新建虚拟节点。右键单击Workflow后,单击新建节点>通用>虚拟节点,根据界面提示新增虚拟节点。虚拟节点的名称为workshop_start。此虚拟节点后续作为整个教程的数据处理流程的一级管控节点。
配置虚拟节点。单击虚拟节点页面右侧的调度配置,核心配置参数如表所示,其他参数可保持默认值,完成后单击顶部保存按钮保存节点配置。
参数
描述
时间属性下的重跑属性
选择运行成功或失败后皆可重跑。
调度依赖下的依赖的上游节点
单击添加按钮后面的使用工作空间根节点。
新建两个离线同步节点。
右键单击Workflow后,单击新建节点>数据集成>离线同步,根据界面提示新增离线同步节点。本教程需要新增两个离线同步节点,节点名称配置为ods_user_info_d、ods_raw_log_d。
双击页面左侧业务流程下的Workflow,打开Workflow业务流程面板后,通过拖拽连线,将workshop_start节点设置为两个离线同步节点的上游节点,如图所示。
【扩展知识】:若您进入业务流程面板后,未找到已创建的3个节点,您可以单击面板上方的居中显示图标
 进行调整。
进行调整。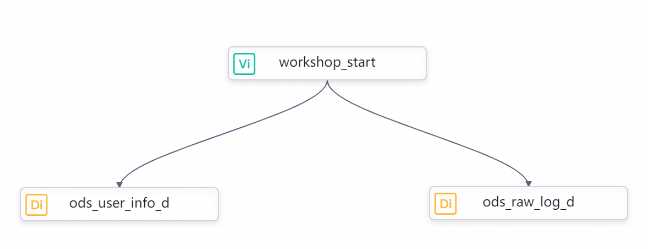
配置HttpFile离线同步节点。
双击HttpFile离线同步节点ods_user_info_d,进入节点编辑页面。
根据界面提示配置离线同步节点。
界面核心参数如表所示,其他参数保持默认即可。
参数
描述
配置同步网络链接
数据来源:选择HttpFile,数据源名称选择user_behavior_analysis_httpfile。
我的资源组:选择已创建的独享数据集成资源组。
数据去向:选择MaxCompute,数据源名称选择odps_first。
配置好后单击下一步,根据界面提示完成网络连通测试。
配置任务
数据来源:
文本类型:选择text。
文件路径:/user_log.txt。
列分隔符:输入列分隔符为|。
压缩格式:包括None、Gzip、Bzip2和Zip四种类型,此处选None。
是否跳过表头:选择No。
数据去向:
表:选择数据源中的ods_raw_log_d表。
调度配置
时间属性下的重跑属性:选择运行成功或失败后皆可重跑。
配置MySQL离线同步节点。
操作方法与HttpFile离线同步节点一样,界面核心参数如表所示。
参数
描述
配置同步网络链接
数据来源:选择MySQL,数据源名称选择user_behavior_analysis_mysql。
我的资源组:选择已创建的独享数据集成资源组。
数据去向:选择MaxCompute(ODPS),数据源名称选择odps_first。
配置好后单击下一步,根据界面提示完成网络连通测试。
配置任务
数据来源:
表:选择ods_user_info_d。
数据去向:
表:选择数据源中的ods_user_info_d表。
调度配置
时间属性下的重跑属性:选择运行成功或失败后皆可重跑。
运行并提交业务流程。
双击页面左侧业务流程下的Workflow,打开Workflow业务流程面板后,单击顶部运行按钮,运行业务流程,首次运行时需关注自定义参数bizdate的取值,需设置为运行教程当天的前一天日期。本教程设置为20230322。
当界面上所有节点显示绿色图标,则表示业务流程运行成功,您可通过临时查询功能查看数据是否正确同步至MaxCompute。您可以单击左侧导航栏的临时查询,选择新建节点>ODPS SQL,执行查询语句查看数据同步情况。运行成功且反馈结果,表明数据成功同步至MaxCompute。
--查看是否成功写入MaxCompute,以下命令中的业务日期需替换为运行的bizdate取值 select count(*) from ods_raw_log_d where dt=20230322;--需要将时间取值替换为教程运行前一天,否则可能会无数据 select count(*) from ods_user_info_d where dt=20230322;单击左侧导航栏的数据开发,回到业务流程页面,在业务流程画布中,单击工具栏中的
 提交图标,根据界面提示,选择所有节点,输入变更描述,提交业务流程。
提交图标,根据界面提示,选择所有节点,输入变更描述,提交业务流程。
数据加工
40
上传并注册函数。本教程的数据加工过程中,会使用一个分析IP地址所属地域的函数,您需要将此函数上传注册至DataWorks,用于后续的加工分析。
上传函数为DataWorks的资源。点击下载函数包ip2region.jar。在数据开发页面打开业务流程,右键单击MaxCompute,选择新建资源>JAR。在新建资源对话框中,根据界面提示,将下载的函数包上传至DataWorks,单击新建按钮并提交新建资源。
注册函数。在数据开发页面打开业务流程,右键单击MaxCompute,选择新建函数,在新建函数对话框中,输入函数名称(示例为getregion)。在注册函数对话框中,配置各项参数,完成后保存并提交。
参数
描述
类名
输入
org.alidata.odps.udf.Ip2Region。资源列表
选择
ip2region.jar。描述
输入IP地址转换地域。
命令格式
输入
getregion(‘ip’)。参数说明
输入IP地址。
新建三张表,提交到生产和开发环境,用于存储数据加工节点的产出数据。建表操作与上述采集数据中的日志数据表的建表操作一致。
新建dwd_log_info_di表。
CREATE TABLE IF NOT EXISTS dwd_log_info_di ( ip STRING COMMENT 'ip地址', uid STRING COMMENT '用户ID', time STRING COMMENT '时间yyyymmddhh:mi:ss', status STRING COMMENT '服务器返回状态码', bytes STRING COMMENT '返回给客户端的字节数', region STRING COMMENT '地域,根据ip得到', method STRING COMMENT 'http请求类型', url STRING COMMENT 'url', protocol STRING COMMENT 'http协议版本号', referer STRING COMMENT '来源url', device STRING COMMENT '终端类型 ', identity STRING COMMENT '访问类型 crawler feed user unknown' ) PARTITIONED BY ( dt STRING );新建dws_user_info_all_di表。
CREATE TABLE IF NOT EXISTS dws_user_info_all_di ( uid STRING COMMENT '用户ID', gender STRING COMMENT '性别', age_range STRING COMMENT '年龄段', zodiac STRING COMMENT '星座', region STRING COMMENT '地域,根据ip得到', device STRING COMMENT '终端类型 ', identity STRING COMMENT '访问类型 crawler feed user unknown', method STRING COMMENT 'http请求类型', url STRING COMMENT 'url', referer STRING COMMENT '来源url', time STRING COMMENT '时间yyyymmddhh:mi:ss' ) PARTITIONED BY ( dt STRING );新建ads_user_info_1d表。
CREATE TABLE IF NOT EXISTS ads_user_info_1d ( uid STRING COMMENT '用户ID', region STRING COMMENT '地域,根据ip得到', device STRING COMMENT '终端类型 ', pv BIGINT COMMENT 'pv', gender STRING COMMENT '性别', age_range STRING COMMENT '年龄段', zodiac STRING COMMENT '星座' ) PARTITIONED BY ( dt STRING );
新建三个ODPS SQL节点,用于对同步至MaxCompute的数据进行加工,进一步做日志数据的挖掘分析。
右键单击Workflow后,单击新建节点>MaxCompute>ODPS SQL,新建ODPS SQL节点,依次命名为dwd_log_info_di、dws_user_info_all_di和ads_user_info_1d。
双击Workflow后,通过连线配置如下图所示的依赖关系。
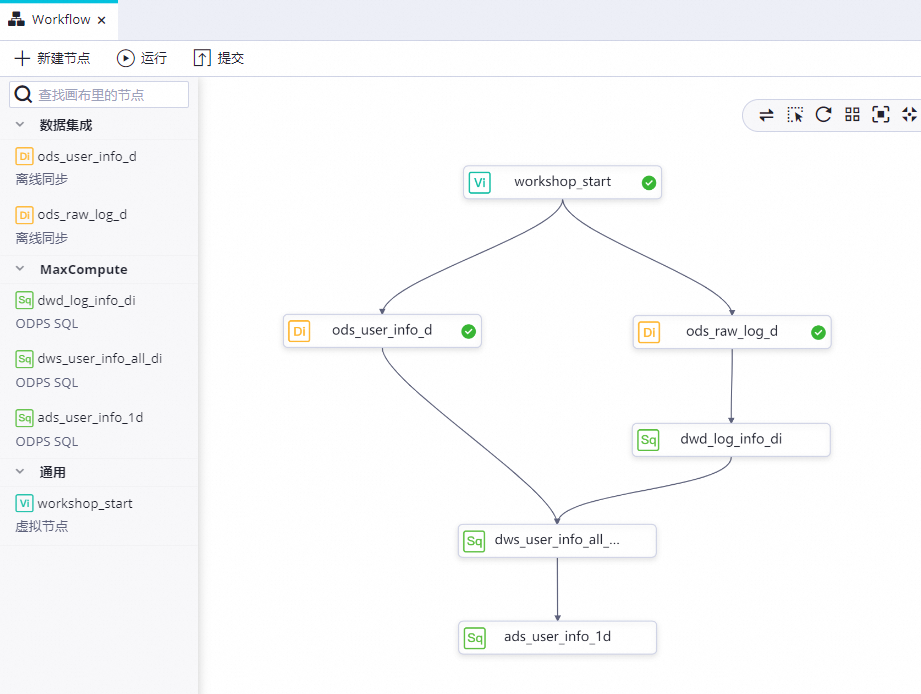
配置ODPS SQL节点:dwd_log_info_di。
双击dwd_log_info_di节点,进入节点配置页面,在节点编辑页面,编写SQL语句。
INSERT OVERWRITE TABLE dwd_log_info_di PARTITION (dt=${bdp.system.bizdate}) SELECT ip , uid , time , status , bytes , getregion(ip) AS region --使用自定义UDF通过IP得到地域。 , regexp_substr(request, '(^[^ ]+ )') AS method --通过正则把request差分为3个字段。 , regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') AS url , regexp_substr(request, '([^ ]+$)') AS protocol , regexp_extract(referer, '^[^/]+://([^/]+){1}') AS referer --通过正则清晰refer,得到更精准的URL。 , CASE WHEN TOLOWER(agent) RLIKE 'android' THEN 'android' --通过agent得到终端信息和访问形式。 WHEN TOLOWER(agent) RLIKE 'iphone' THEN 'iphone' WHEN TOLOWER(agent) RLIKE 'ipad' THEN 'ipad' WHEN TOLOWER(agent) RLIKE 'macintosh' THEN 'macintosh' WHEN TOLOWER(agent) RLIKE 'windows phone' THEN 'windows_phone' WHEN TOLOWER(agent) RLIKE 'windows' THEN 'windows_pc' ELSE 'unknown' END AS device , CASE WHEN TOLOWER(agent) RLIKE '(bot|spider|crawler|slurp)' THEN 'crawler' WHEN TOLOWER(agent) RLIKE 'feed' OR regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') RLIKE 'feed' THEN 'feed' WHEN TOLOWER(agent) NOT RLIKE '(bot|spider|crawler|feed|slurp)' AND agent RLIKE '^[Mozilla|Opera]' AND regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') NOT RLIKE 'feed' THEN 'user' ELSE 'unknown' END AS identity FROM ( SELECT SPLIT(col, '##@@')[0] AS ip , SPLIT(col, '##@@')[1] AS uid , SPLIT(col, '##@@')[2] AS time , SPLIT(col, '##@@')[3] AS request , SPLIT(col, '##@@')[4] AS status , SPLIT(col, '##@@')[5] AS bytes , SPLIT(col, '##@@')[6] AS referer , SPLIT(col, '##@@')[7] AS agent FROM ods_raw_log_d WHERE dt = ${bdp.system.bizdate} ) a;单击右侧的调度配置,核心配置参数如表所示,完成后单击保存。
参数
描述
时间属性下的重跑属性
选择运行成功或失败后皆可重跑。
配置ODPS SQL节点:dws_user_info_all_di。操作与上一步配置dwd_log_info_di节点一致。
INSERT OVERWRITE TABLE dws_user_info_all_di PARTITION (dt='${bdp.system.bizdate}') SELECT COALESCE(a.uid, b.uid) AS uid , b.gender , b.age_range , b.zodiac , a.region , a.device , a.identity , a.method , a.url , a.referer , a.time FROM ( SELECT * FROM dwd_log_info_di WHERE dt = ${bdp.system.bizdate} ) a LEFT OUTER JOIN ( SELECT * FROM ods_user_info_d WHERE dt = ${bdp.system.bizdate} ) b ON a.uid = b.uid;配置ODPS SQL节点:ads_user_info_1d。操作与上面步骤配置dwd_log_info_di节点一致。
INSERT OVERWRITE TABLE ads_user_info_1d PARTITION (dt='${bdp.system.bizdate}') SELECT uid , MAX(region) , MAX(device) , COUNT(0) AS pv , MAX(gender) , MAX(age_range) , MAX(zodiac) FROM dws_user_info_all_di WHERE dt = ${bdp.system.bizdate} GROUP BY uid;运行并提交业务流程。
双击页面左侧业务流程下的Workflow,打开Workflow业务流程面板后,单击顶部运行按钮,运行业务流程。
当界面提示运行结束后,您可通过临时查询功能查看数据是否正确同步至MaxCompute。您可以单击左侧导航栏的临时查询,选择新建节点>ODPS SQL,执行查询语句查看数据同步情况。运行成功且反馈结果,表明数据成功同步至MaxCompute。
---查看ads_user_info_1d数据情况,ds取值与此前运行时的bizdate一致,需要将时间取值替换为教程运行前一天,否则可能会无数据。 select * from ads_user_info_1d where dt=20230322 limit 10;单击左侧导航栏的数据开发,回到业务流程页面,单击提交按钮,根据界面提示,选择所有节点,输入变更描述,提交业务流程。
发布业务流程。
单击业务流程面板右上角的发布,进入发布页面勾选所有的节点,根据界面提示发布选中项。
完成
5
观测数据周期性产出情况:完成上述操作后,后续数据即会在生产环境中周期性产出,您后续可以在数据地图中查看每日产出的数据。
本教程共产出如下5张表,您可以进入数据地图,参考下图查看对应的表详情。数据地图的使用详情请参见数据地图。
OSS用户访问日志数据表:ods_raw_log_d
MySQL用户基本信息数据表:ods_user_info_d
其他数据表:
dwd_log_info_di
dws_user_info_all_di
ads_user_info_1d

清理及后续
5
清理
完成教程后,请及时清理测试数据和试用资源。
MaxCompute资源清理:本教程使用了MaxCompute计算引擎,在体验完成本教程后,如果后续您不再使用的话,请及时将MaxCompute资源释放,否则MaxCompute会继续计费。释放操作请参见资源释放。
总结
常用知识点
问题1:如果您希望将自己的开发和生产环境隔离,您在创建工作空间的时候该如何配置?(单选题)
正确答案是创建一个工作空间并通过配置参数实现开发生产环境隔离。
问题2:进行数据同步时,数据源需要与什么保持网络连通?(单选题)
正确答案是DataWorks的数据集成资源组。DataWorks的数据同步是通过数据集成资源组来实现的,您需要保障数据源与数据集成资源组间网络连通,且不会因为受白名单限制导致访问受限。