
本文为您介绍算法组件的相关问题。
Designer算法支持哪些MaxCompute数据类型的字段
目前仅支持Boolean、Bigint、Double、String、Datetime五种数据类型。
使用组件时提示Compute Resource Not Exists, Type: MaxCompute
如果您的工作空间没有关联MaxCompute资源,在使用依赖MaxCompute资源的组件时,会提示“Compute Resource Not Exists, Type: MaxCompute”。为解决此问题,您需要将MaxCompute资源关联至工作空间,详情请参见管理工作空间-计算资源配置。
Beta组件使用说明
Designer中的Beta组件(如文本近似相似对、多热编码训练组件)为部分特殊用户定制,并不适用于一般用户。如有需求,建议您使用其他功能相似的组件替代,或提交工单咨询。
x13_auto_arima组件运行报错
报错内容
row number should be (1, 1200].解决方案
x13_auto_arima的数据每组不能超过1200条,如果没有分组,总数据不能超过1200条。
Doc2Vec组件运行报错CallExecutorToParseTaskFail
Doc2Vec组件的数据规模(Doc个数+Word个数)× Vec长度必须小于2410000×10000,用户规模必须小于42432500×7712293×300。如果超出了该范围,则会导致内存申请失败。
您可以先缩小数据规模再计算,且输入的数据需要进行分词。
如何将运行画布节点输出的临时表数据进行持久化存储?
PAI-Studio/Designer中提供了写数据表组件,您可以将写数据表组件连接在需要持久化存储临时表数据节点的下游,实现临时表数据持久化存储。
运行组件报错:提示没有MaxCompute操作权限
在工作空间中,请检查是否已为执行操作的RAM用户添加MaxCompute开发角色,具体操作,详情请参见管理成员。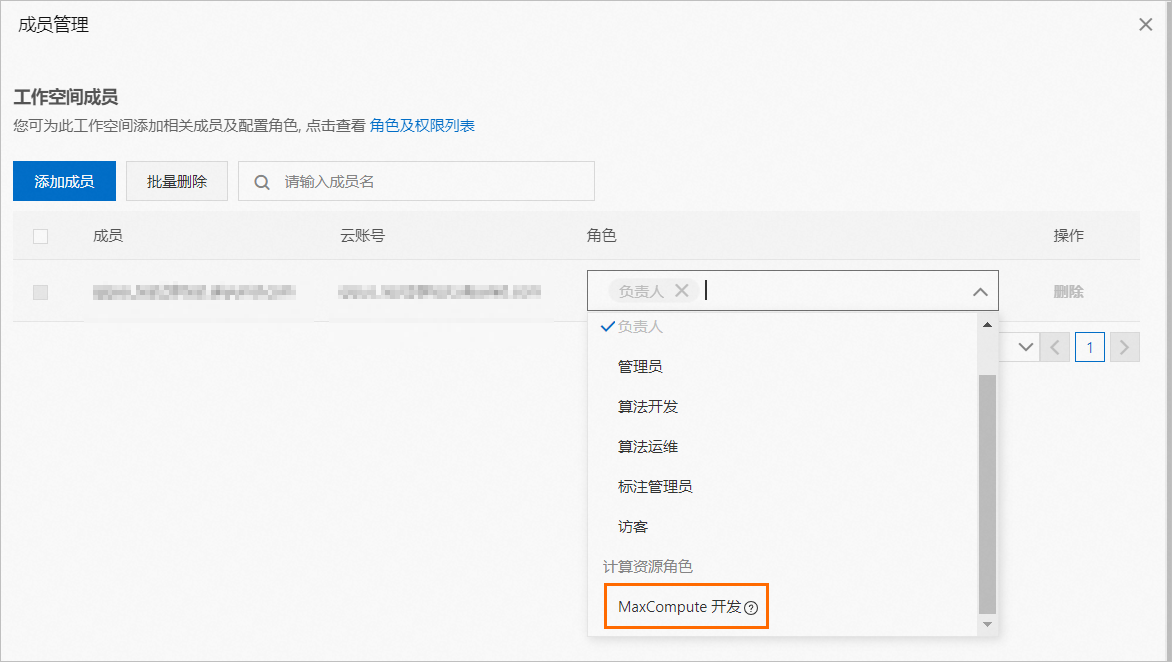
使用组件列选择器找不到预期的数据列
在列选择器中选择字段时,如果找不到预期的数据列,可以先确认上游节点是否运行成功,并生成当前节点所需要的输入数据表。具体操作可以在当前节点的上游节点,右键组件在菜单中选择执行到此处。
运行工作流失败,报错打印您没有在MaxCompute项目中,如何解决?
在工作空间详情页面的工作空间成员区域,为RAM用户添加MaxCompute开发角色,详情请参见管理成员。
算法组件运行失败,如何定位问题?
在Designer画布中,右键单击运行失败的组件,在快捷菜单,单击查看日志。
在日志页面,查找并单击Logview链接。
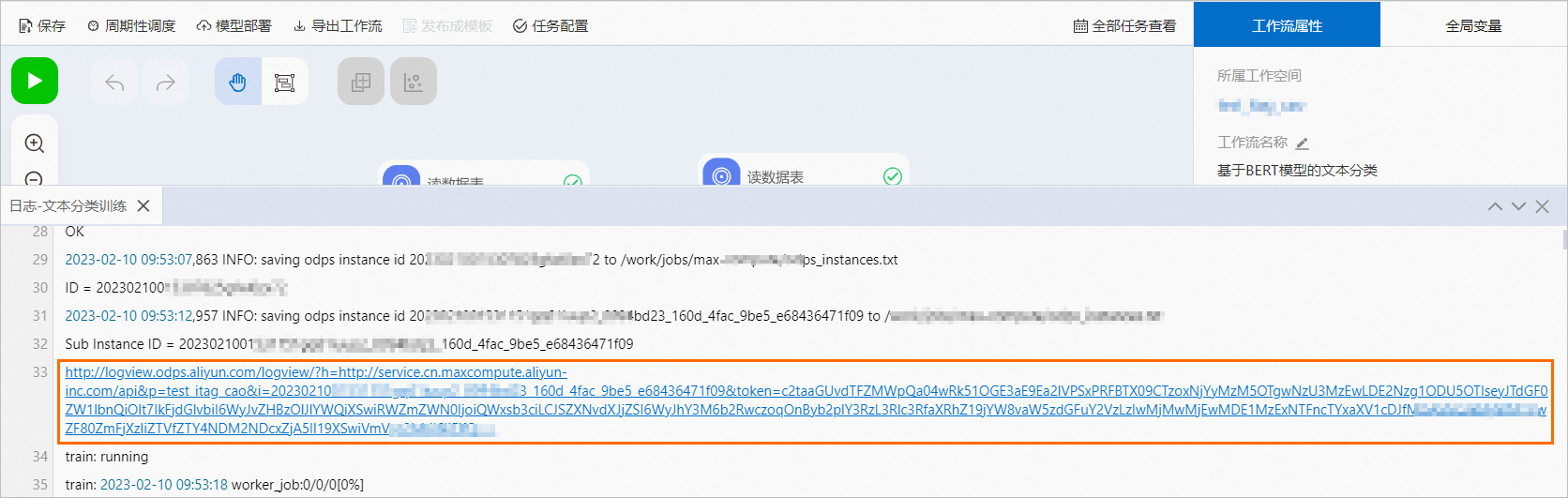
在Job Details页签,单击StdErr列下的
 。
。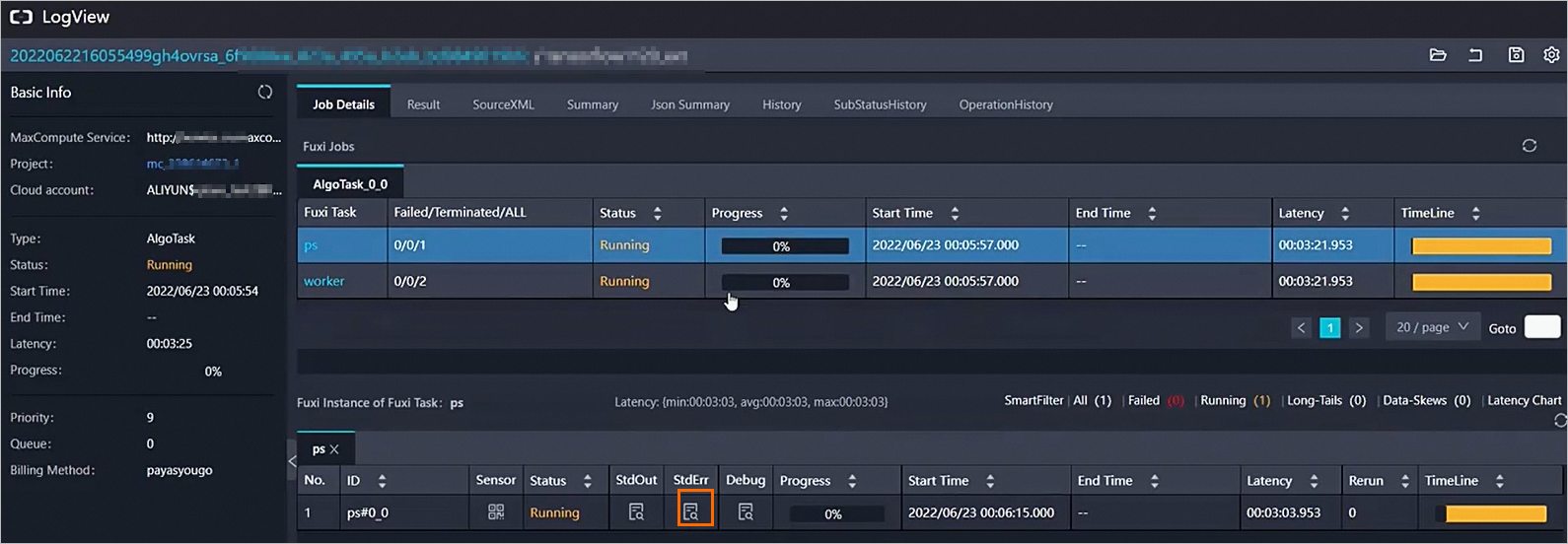
在StdErr对话框,查看运行过程中具体报错的日志信息。
Designer有什么方案可以直接使用在阿里云上自建的hive表数据
目前没有读取hive表的组件,建议先使用DataWorks-数据集成将数据同步到MaxCompute,然后在Designer中调用MaxCompute表。
PyAlink脚本组件和Python脚本组件的区别
1.PyAlink脚本组件底层使用的是Alink镜像,可以直接调用Alink的SDK,支持执行在不同的计算资源,如MaxCompute、DLC、Flink全托管。
2.Python脚本组件底层是完全基于DLC的,但提供了更灵活的使用方式,如除了自定义脚本外,还支持自定义镜像、自定义第三方依赖包。
算法代码已经写好怎么用PAI-Desiger使用
Designer提供了Python脚本组件,支持您将自己写好的代码粘贴到该组件的Python代码编辑器中运行。具体操作,请参见Python脚本。
自定义Python组件如何安装第三方库
自定义Python组件参数配置文档点击查看。脚本设置参数中支持第三方依赖库的设置,可以在配置框中按照requirements格式配置,注意下“==”是不是有空格。 更多详情参考文档。
Python组件上无法连接MaxCompute
不要在mc_execution中获取endpoint。建议参考pyodps的文档。
Designer中建立好模型可以直接在MaxCompute中调用来读取新上传的数据吗
在Designer中连接一个预测组件,将训练好的模型和待预测的MaxCompute表作为输入,配置完成后,运行即可进行离线批量预测。
注意有些算法有配套的预测组件,例如EasyRec训练和EasyRec预测,其他的算法就使用通用的预测组件即可,通用预测组件查看文档。


Designer组件列选择控件里找不到预期的字段
在列选择器中选择字段时,如果找不到预期的数据列,可以先确认上游节点是否运行成功,并生成了当前节点所需要的输入数据表。具体操作可以在当前节点的上游节点,右键组件在菜单中选择执行到此处。
组件列选择器中的字段解析逻辑按如下顺序:
1.直接上游节点产出表,并且没有被修改过,会把产出表的字段列出。
2.上一个节点若被修改了,如果整个画布第一个节点是读数据表,会把第一个节点输入的表字段列出。
Python组件运行报错No module named imblearn
在我们使用的镜像中没有imblearn库,需要在该组件的脚本设置页签的第三方依赖库中配置imblearn。在节点执行前,会自动安装该库。详情参考文档。
随机森林最后一个节点progress显示100%但不能结束进程
模型里边有一些ID类特征,造成模型非常大,超出系统限制了,解决方法就是去掉一些离散特征,或者让树深度小一些,缩小一下模型复杂度。
随机森林报错Algo Job Failed-Algo Error-unsupported type
目前随机森林算法仅支持Boolean、Bigint、Double、String、Datetime五种数据类型(即使是保留列也需要是这五种类型)。报错是由于数据中使用了不支持的数据类型,建议提前做类型转换再参与计算。
DBSCAN组件如何输入
DBSCAN需要KV格式的输入,请先将数据转成KV格式。比如一条数据有三个feature,值分别是:0.1,0.2,0.3 。那么需要改写成:0:0.1 1:0.2 2:0.3。可以使用Designer的Table2KV组件实现数据格式之后直接输入给DBSCAN。
自然语言处理组件报错Restoring from checkpoint failed
自然语言处理组件报错Restoring from checkpoint failed.,是因为保存的checkpoint文件和新跑的代码模型结构冲突了,尝试删除保存的checkpoint文件,然后在重新运行看下。
组件报错Parse exception - invalid token
目前仅支持Boolean、Bigint、Double、String、Datetime五种数据类型。报错是由于数据中使用了不支持的数据类型,建议提前做类型转换或者过滤掉不支持的字段再进行计算。
PAI命令如何使用
1、在Designer的SQL节点中可以直接写PAI命令,详情参考文档。
2、在DataWorks-数据开发-SQL节点中使用,详情参考文档。
3、下载ODPSCMD客户端使用,详情参考文档。
Designer运行中生成大量临时表
临时表有生命周期到期会自动清理,默认是28天。也可以在工作空间存储配置中修改临时表生命周期设置,或者手动一键清除工作空间内所有临时表。
运行自定义Python脚本报错exit_code=255
任务输出路径和代码保存路径需要配置不同的OSS Path,否则有冲突的可能。
训练报错ODPS-1202005:Algo Job Failed-User Error-The script file is not provided
通常由于-Dscript参数未填或存储类型不支持执行的代码文件,可将代码文件放在OSS上,并将路径配置到参数中。
百分位组件为什么会涉及训练和预测
训练得到的模型就是得到百分位点,预测是指输入个数判断落到哪个百分位区间内。
Designer节点输出数据预览条数限制
1. 组件执行后完整数据存在了MaxCompute的数据表里,但预览有数量限制,建议连接SQL脚本组件查询关心的数据,SQL脚本可点此参考。
2.可以在MaxCompute或者DataWorks中查询或下载节点输出表数据(下载需要有对应权限)。节点输出表的project和table,可以通过查看log日志找到。具体操作是:鼠标点击右键,选择“查看日志”,打开日志后,找到输出表的相关信息(project,table等),如下图所示示例的,然后在DataWorks里执行SQL查询语句查看结果。

读csv文件为什么只能读100条
数据读取没有限制,但预览限制的只能看到100条,可以连接一个SQL脚本select出自己比较关心的数据进行预览,SQL脚本使用可单击SQL脚本进行了解。
如何做上采样
1、可结合分层采样StratifiedSample来完成,详情参考分层采样。
2、可利用自定义Python组件来实现,参考文档中的使用实例1。
doc2vec组件能否预测新向量
doc2vec组件不能预测新向量。建议使用PyAlink中word2vec + docvecFromWordVec的方式。详情参考文档。
如何将PAI算法流程构建的节点结果数据传递给下一个节点作为输入?
在PAI Designer(原Studio)中,根据不同的算法类型,节点结果数据可能保存在MaxCompute表或OSS路径中。下游节点可以通过连线的方式从对应的MaxCompute表和OSS路径中读取数据,以便继续进行计算。
机器学习FAILED: ODPS-1220061: Invalid parameter in HTTP request - xflow not found
如果使用PAI命令调用某个算法,请将project参数设置成固定值algo_public。