
本文介绍了类目预测功能是什么,以及类目预测的基本原理和使用方法,来帮助用户快速的理解和使用该功能。
效果展示
什么是类目预测
类目预测功能通过计算用户查询内容与物品类目的相关度进行排序。相关度越高的类目,其对应物品会获得更高的排序得分,从而在搜索结果中优先展示。
示例:
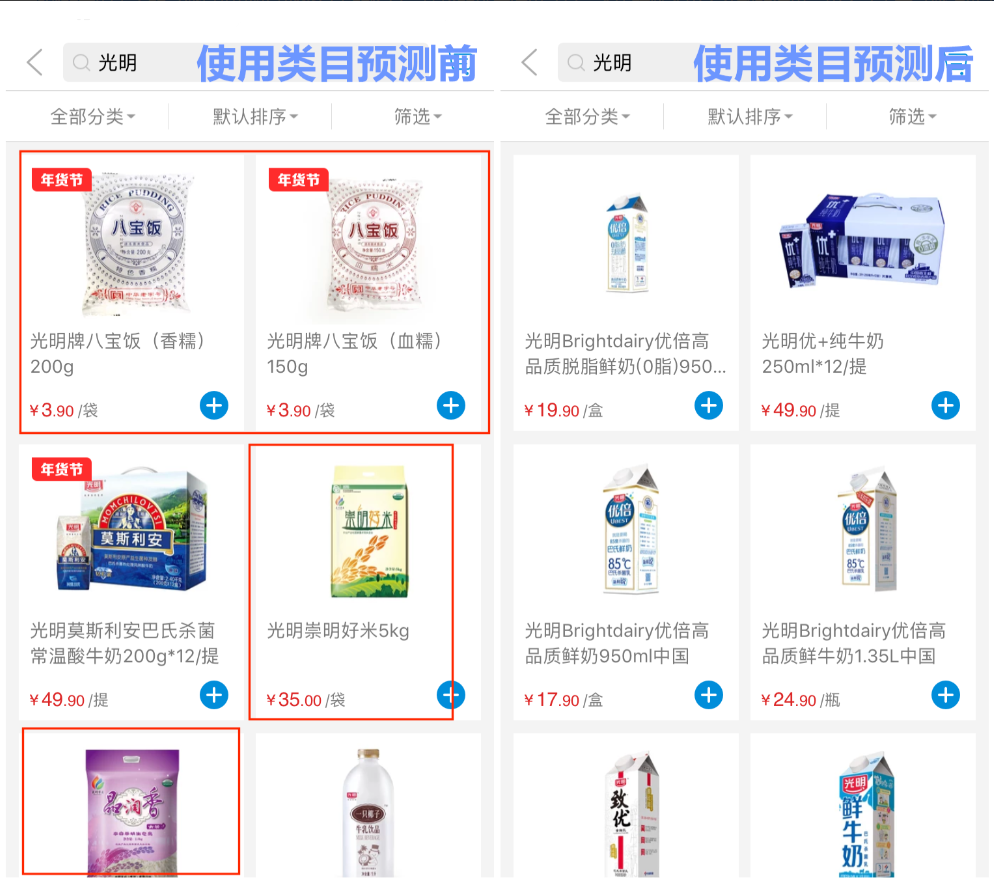
举个例子,用户输入“光明”,查询到一批物品,这批物品中有一部分的类目是“牛奶”,另一部分的类目是“大米”。根据搜索历史行为数据,搜索“光明”的人里面,点击“牛奶”类目物品的用户数量显著高于点击“大米”类目物品的用户数量。则类目预测模型就会给出这样的预测结果:“牛奶”类目与“光明”的相关度要比“大米”类目与“光明”的相关度高,所以在计算每个物品的排序分时,“牛奶”类目物品的得分比“大米”类目物品得分高,因此“牛奶”类目物品会排在更前面,从而提高了搜索的业务价值。
类目预测基本原理
类目预测的目标是预测搜索的query与类目的相关度,它需要用到历史query数据、点击行为数据、类目下的物品信息数据。具体来说是把之前搜过的query收集起来,结合搜索后的点击行为数据,与类目下的物品信息联系起来,刻画query与类目之间的数据规律。
训练模型需要有数据源,创建类目预测模型时先要与某个应用关联起来,关联应用之后,需要确定训练模型所需的三类数据:
历史上在该应用搜索过的所有query,需要在搜索请求中添加raw_query参数。
类目数据和物品数据,这部分数据由用户在准备模型训练时从应用中指定字段,至少需要指定应用中的类目ID字段、物品标题字段。
应用的点击行为数据,行为上报的数据越全面、质量越高,意味着模型的特征越丰富,效果越好。
OpenSearch类目预测功能支持带行为数据的模型训练和不带行为数据的模型训练。
带行为数据的模型训练,适用于已经上传行为数据,在开始训练前会自动做入口条件检查,确保数据量、数据质量、数据完整度都能达到要求,模型训练有如下步骤:
使用历史query和类目信息,抽样生成样本数据,使用行为数据进行样本数据打标签。
对行为数据进行指标统计、特征计算等操作,生成点击行为类特征。
结合query和类目下的物品标题,对query和标题分词后,计算query文本与物品标题文本的语义类特征。
如果上传了成交类行为数据,会对成交行为数据进行指标统计、特征计算,生成成交类特征,使得成交表现较好的物品排在更前面。
把以上抽样生成的样本数据和这些样本数据的行为特征、语义特征、成交特征和样本的标签,综合起来作为训练数据,输入到算法中进行迭代训练。
训练完成后就得到了描述样本中query和类目相关度关系的模型,利用这个模型就可以预测query和类目的相关度。
勾选了“行为数据”的训练类目预测模型时要求query满足近14天内该query下的某类目点击数要超过1次。
不带行为数据的模型训练,适用于没有上传行为数据,或行为数据质量较差的场景,只需要指定应用中的类目ID字段和物品标题字段,就可以开始训练模型。由于没有行为数据,样本打标签没有依据,那么会使用另一类算法来训练模型,仅通过query和类目下物品标题的文本数据,进行分词后,计算query文本与物品标题文本的语义相关度,得到query与类目的相关度。
使用行为数据的模型效果要优于不使用行为数据的模型,训练模型的特征越丰富,模型对于query和类目的数据规律的刻画越全面,做出的预测越准确。
不管是带行为数据的模型还是不带行为数据的模型,训练的过程都经过了大量的实验,使用不同场景的数据,做了精心的参数调优,确保效果能符合预期。
如何使用类目预测
必要条件
进行模型训练需要数据源,训练模型之前必须先绑定某个应用。应用数据、应用的query数据、应用的行为数据,都是类目预测模型所需要的数据。
如果没有上传点击行为数据,或不想使用点击行为数据进行训练,或点击行为数据尚未满足训练条件,那么可以先不使用点击行为数据来训练模型,此时类目预测模型需要从应用中选择三个字段的数据,分别是:类目ID、物品标题、类目名称。其中类目ID和物品标题必选,类目名称可选。在模型训练完成后,会输出部分模型的预测结果供效果评估,类目名称将被用于效果评估页面以评估query与类目的相关度是否符合预期,所以建议训练的时候提供类目名称字段。
如果已上传了点击行为数据,那么除了选择上述的字段内容,在进行模型训练时,还可以选择关联行为数据的选项,只要行为数据满足训练条件,就会使用这部分数据训练模型。
操作步骤
在应用下创建类目预测模型。
应用类目预测模型:首先需要在查询分析中应用该模型,然后再在基础排序、业务排序中生效模型。
创建一个查询分析,配置上类目预测并选择1中创建的模型。
查询中生效类目预测模型:SDK调用查询接口,输入raw_query参数。
具体操作流程可参考类目预测功能使用。