
hive表存储格式区别
在dataphin中的使用中,若对接Hadoop系列引擎,肯定会遇到建表场景,本文将介绍建表存储格式的选型问题
在dataphin系统设置的研发平台的表管理设置可以设置默认建表的表格式,一般情况下默认成orc,或者引擎默认设置(截图以emr为例,其他Hadoop系列会有一些独特的专属格式,比如星环tdh,这里不做例举)
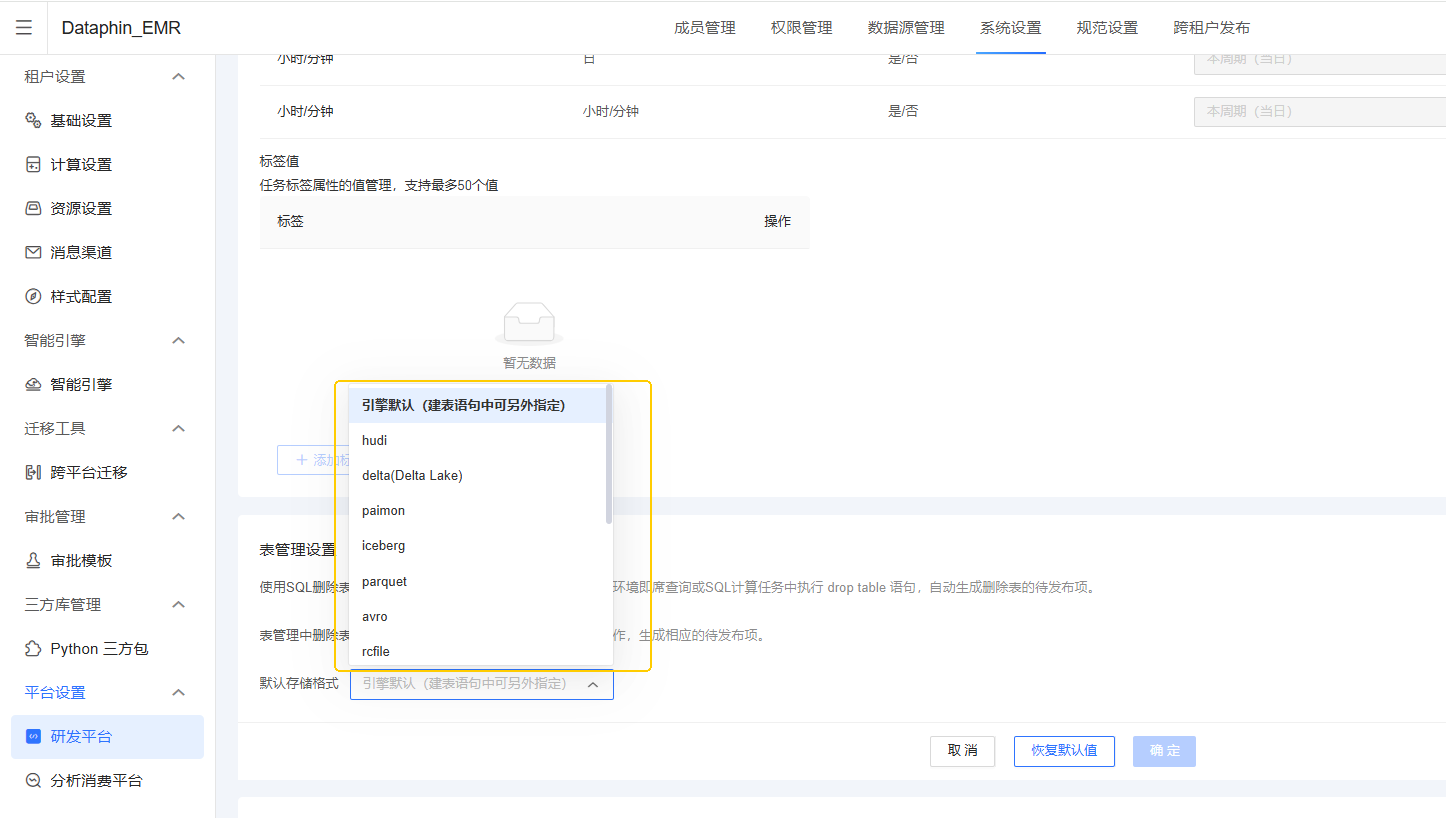
这个设置会导致通过表管理建表的时候默认是落在对应的格式选项上,当然,您可以不通过表管理方式建表,用建表语句通过计算任务手动执行建表也是可以的,只是在这个列表内的存储格式,dataphin算支持的比较好,而其中支持度最好的目前是orc
以下按照时间线介绍这些格式
存储格式 | Hive 原生支持情况 | 类型 | 优点 | 缺点 | 使用场景 | 主要缺陷 |
TextFile | 原生默认(0.1+) | 行式文本 | 可读性强;兼容所有系统; | 存储效率低;不支持压缩分片;数据含 | ODS 贴源层;小数据测试;调试 | 无结构元数据,特殊字符污染严重 |
SequenceFile | 原生(0.1+) | 行式二进制 | 可压缩、可分片;Hadoop 原生高效 | 不可读;仅限 Hadoop 生态;写入需 | Hadoop 内部临时表 | 社区淘汰,不支持复杂类型 |
RCFile | 原生(0.6+) | 混合列存 | 列式查询 I/O 少;支持压缩 | 写入慢;重建整行成本高;无统计信息 | 历史遗留宽表(2015年前) | 已废弃,Hive 3.0+ 不推荐 |
ORC | 原生(0.11+) | 列式二进制 | 高压缩比;谓词下推;向量化执行;支持 ACID | 写入 CPU 开销大;生态略逊于 Parquet | Hive 数仓核心层(DWD/DWS) | 小文件问题;内存消耗高 |
Parquet | 原生(0.13+) | 列式二进制 | 跨平台(Spark/Presto/Flink);嵌套模型支持好 | 不支持 Hive ACID;Hive 中性能略逊 ORC | 多引擎数据湖;云数仓 | Schema 演化有限 |
Avro | 原生(0.9+) | 行式二进制 | Schema 演化灵活;适合流数据 | 行式存储,分析性能差;Hive 中使用少 | Kafka 流落盘;Schema 频繁变更场景 | 不适合 OLAP 查询 |
CSV | 通过 | 行式文本 | 通用性强;Excel 可读 | 无标准(引号/转义混乱);含换行符必错行 | 与外部系统交换(非生产) | Hive 无原生 CSV SerDe,可靠性差 |
JSON | 需 | 行式文本 | 自描述;嵌套结构 | 解析开销大;无压缩;一行一 JSON | 日志半结构化数据接入 | 性能极低,不适用于大表 |
Text | 同 TextFile | 行式文本 | 同 TextFile | 同 TextFile | 同 TextFile | 同 TextFile |
BinaryFile | 不支持 | — | — | Hive 无法直接建表读取任意二进制文件 | — | 需自定义 InputFormat |
Kudu | 通过 | 列式存储(实时) | 支持快速更新/插入;低延迟查询 | 依赖 Kudu 服务;Hive 集成弱;运维复杂 | 实时数仓(Hive + Impala 混合) | Hive 仅能读,不能写;非主流方案 |
Hudi | 需 Spark 写入 + Hive Sync | 表格式(基于 Parquet) | 支持 upsert/delete;时间旅行;增量拉取 | 依赖 Spark;Hive 仅能读快照 | CDC 数据湖;近实时分析 | Hive 无法直接写 Hudi 表 |
Delta Lake | 需 Spark 写入 + Hive Metastore Sync | 表格式(基于 Parquet) | ACID;Schema 强制;时间旅行 | 仅 Spark 原生支持;Hive 读需额外配置 | Databricks 生态;多引擎共享 | Hive 读 Delta 需 Delta Standalone Reader |
Iceberg | 需 Flink/Spark 写入 + Hive Catalog | 表格式(Parquet/Avro/ORC) | 高并发安全;隐藏分区;Schema 演化强 | 元数据管理复杂;Hive 集成需 Iceberg MR | 开放数据湖(Trino/Spark/Hive) | Hive 读写需 Iceberg MR 运行时 |
Paimon | 需 Flink 写入 + Hive Catalog | 表格式(基于 LSM) | 流批一体;Changelog 支持;高吞吐写 | 新兴项目;生态工具链不成熟 | Flink 流式数仓;实时聚合 | Hive 读 Paimon 需专用 connector |
选错存储格式建表导致的问题
错误建成text格式表
源数据库是oracle,用户集成任务把数据从oracle导入到hive的 text表上,那么如果因为oracle数据中有\N内容,导致冲突到换行符,这个时候数据再导入hive表的时候就会因为错误换行而导致脏数据无法写入,因为数据结构上换行符和数据内容在一个结构体内所以无法解耦,这个数据要做处理必须人工干预,或者有类似大语言模型的应用程序去自动化识别处理。
这个时候建议建成orc格式的表即可
(想选其他的可以自行评估,这里主要是考虑dataphin目前的其它模块的功能支持覆盖度推荐的)。
那么肯定会有新入行的同事问,既然text格式问题这么大而且无法解决,那么什么场景下目前还要这个格式建表呢?这个格式应该直接不存在才对嘛
当您数据是外部数据已经是以文本形式存储在hdfs上的时候,而且您不打算转储格式浪费存储,这个时候直接建hive表选text格式并且指定好hdfs路径建外部表,这样就减少了存储成本和etl过程,可以直接分析数据,类似文件比如fulume等其他应用程序爬回来的日志文件。