
PolarDB MySQL版集群自带读写分离功能。应用程序只需连接一个可读可写(自动读写分离)模式的集群地址,写请求会自动转发到主节点,读请求会自动根据各节点的负载(当前未完成的请求数)转发到主节点或只读节点。
优势
-
读一致性
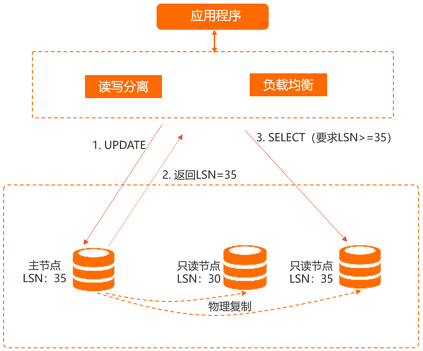
当客户端通过读写分离地址与后端建立连接后,读写分离中间件会自动与主节点和各个只读节点建立连接。在同一个连接内(同一个session内),读写分离中间件会根据各个数据库节点的数据同步程度,来选择合适的节点,在保证数据正确的基础上(写操作之后的读有正确的结果),实现读写请求的负载均衡。
-
原生支持读写分离,提升性能
如果您在云上通过自己搭建代理层实现读写分离,在数据到达数据库之前需要经历多个组件的语句解析和转发,响应延迟较大。而PolarDB读写分离直接内置在已有的高安全链路中,没有任何额外的组件产生消耗,能够有效降低延迟,提升处理速度。
-
维护方便
在传统模式下,您需要在应用程序中配置主节点和每个只读节点的连接地址,并且对业务逻辑进行拆分,才能将写请求发往主节点而将读请求发往所有节点。
PolarDB提供集群地址,应用程序连接该地址后即可对主节点和只读节点进行读写操作,读写请求会被自动转发,转发逻辑完全对使用者透明,可降低维护成本。
同时,您只需添加只读节点的个数,即可不断扩展系统的处理能力,应用程序无需做任何修改。
-
节点健康检查,提升数据库系统的可用性
读写分离模块自动对集群内的所有节点进行健康检查,当发现某个节点宕机或者延迟超过阈值后,PolarDB将不再分配读请求给该节点,读写请求在剩余的健康节点间进行分配,以此确保单个只读节点发生故障时,不会影响应用的正常访问。当节点被修复后,PolarDB会自动将该节点纳回请求分配体系内。
-
免费使用,降低资源及维护成本
免费提供读写分离功能,无需支付任何额外费用。
请求转发逻辑
可读可写模式转发逻辑如下:
-
只发往主节点:
-
所有DML操作(INSERT、UPDATE、DELETE、SELECT FOR UPDATE)。
-
所有DDL操作(建表或库、删表或库、变更表结构、权限等)。
-
在未开启事务拆分功能时,所有事务中的请求。
说明开启事务拆分功能后的路由详情请参见事务拆分。
-
用户自定义函数。
-
存储过程。
-
LOCK/UNLOCK TABLES语句。
-
使用到临时表的请求。
-
SELECT last_insert_id()。 -
所有对用户变量的查询和更改。
-
binlog dump。
-
-
发往只读节点或主节点:
说明仅当主库是否接受读选择为是时会发往主节点。
-
非事务中的读请求。
-
只读事务(START TRANSACTION READ ONLY)。
-
-
总是发往所有节点:
-
所有系统变量的更改。
-
USE命令。
-
PREPARE和DEALLOCATE PREPARE命令。
-
COM_CHANGE_USER、COM_RESET_CONNECTION、COM_QUIT、COM_SET_OPTION等命令。
-
SHOW PROCESSLIST。说明执行
SHOW PROCESSLIST命令后,PolarDB将返回所有节点的PROCESSLIST信息。 -
KILL(SQL语句中的KILL,非命令KILL)。
-
只读模式转发逻辑如下:
-
不允许执行DDL、DML操作。
-
所有读请求按照负载均衡的方式转发到各个只读节点。
-
所有读请求不会转发到主节点。即使主节点已被添加到服务节点中,也不会生效。
-
binlog dump锁定到某个RO节点。