本文主要通过图例介绍常见的压测场景内的逻辑结构关系,并说明数据在压测中是如何分配的。
基本概念
压测API:指由用户行为触发的一条端上请求,是压测中的必需元素。
串联链路:指一组压测API的有序集合(类似于事务),具有业务含义。
关联数据文件:压测API使用了来自数据文件的参数,从而关联了相应的数据文件。如果使用了多个文件参数分别来自于不同数据文件则表示关联了多个数据文件。
数据配置节点:如果串联链路中任意API需要使用文件参数,或将文件参数进行二次定义(如MD5编码等)再使用的,需要通过数据配置节点预先设置/定义后,方可在API中使用
数据导出指令:用于导出某个串联链路中的数据(导出Cookie为典型应用),供其他串联链路使用,实现导出数据的全局共享。
检查点(断言):一般用于标记业务成功与否,从而验证压测请求的响应是否符合预期。
数据轮询一次:使用文件参数时,数据文件只轮询一次,以保证请求信息不重复。
出参:在创建串联链路时,将前置接口的部分返回信息作为参数。
常见的压测场景结构和数据分配规则
具体请参考下图:
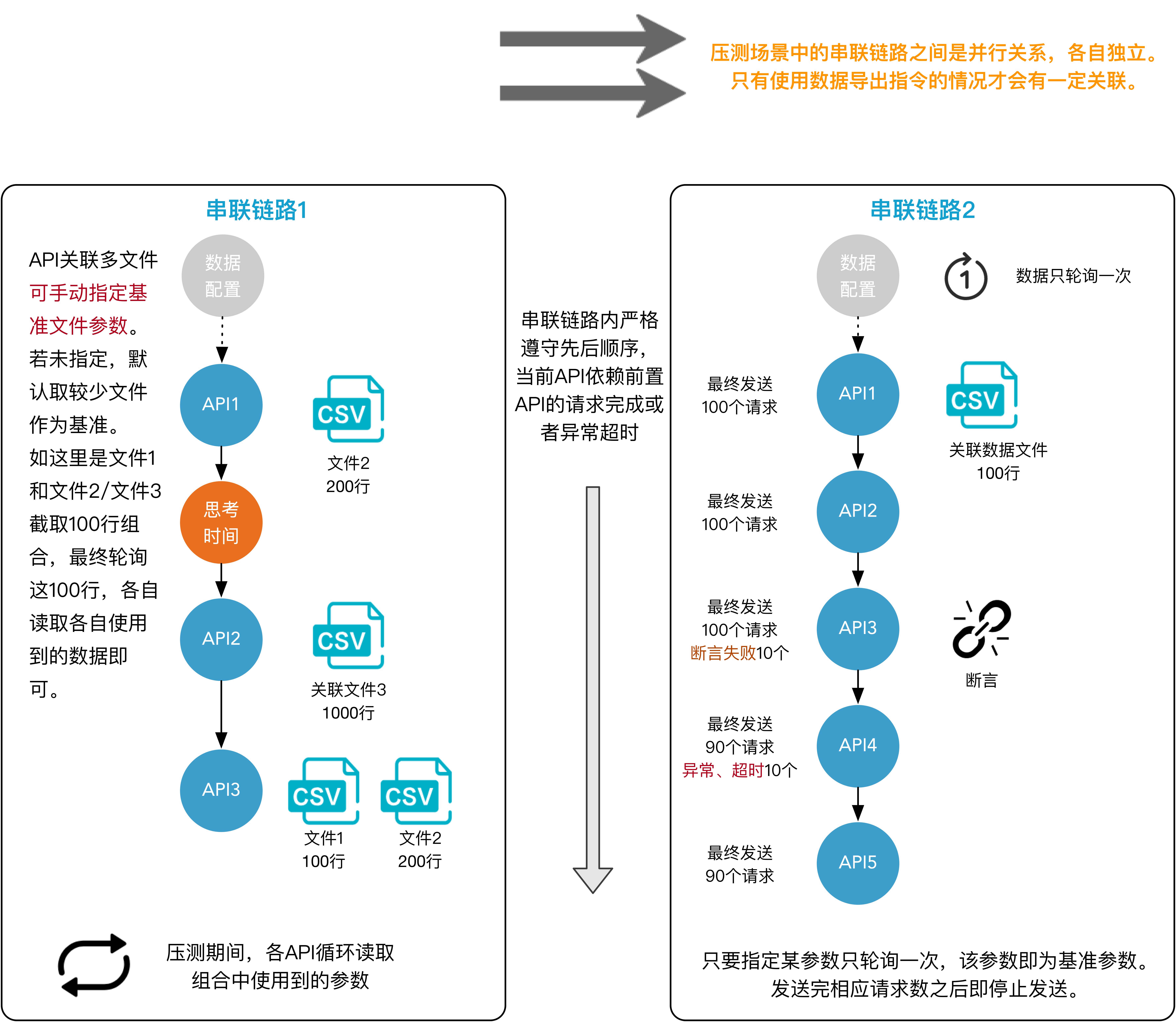
图例说明如下:
- 串联链路1和串联链路2是并行关系。
- 串联链路类似于一个事务,串联链路内的所有压测API,严格遵循先后顺序。当前API的请求发起依赖前置API的请求处理完成或者超时异常。说明 后面的API最终发送的请求次数会少于前面API的,因为压测停止的时候总有一些请求还在串联链路的中间环节(API)上没有全部完成。
- 串联链路内,所有API使用到的文件参数,需要配置数据配置节点后才能使用,请参见添加数据配置节点。
- 串联链路1中API 1使用了文件2的一个参数(源文件200行),API 2使用了文件3的一个参数(源文件1000行的),API 3使用了文件2的一个参数(源文件200行)及文件1的一个参数(源文件100行),未指定基准文件时,会根据最少的文件1(即100行)参数组合。截取文件2、文件3的前100行进行组装并重复循环。
- 若某参数勾选了数据轮询一次,即指定该参数为基准。组装后的行数为它的源文件行数。使用完组合构造数据构造的请求数之后,将不再压测该API,当前串联链路也将整体停止压测。
- 设置了检查点(断言)的情况下,如果当前请求断言失败,那么后置的API或者指令将不再执行(仅针对本次顺序执行过程),断言成功的没有影响。
依赖登录的压测场景结构
下图中串联链路1的API 1是登录业务相关接口,其典型配置如下:
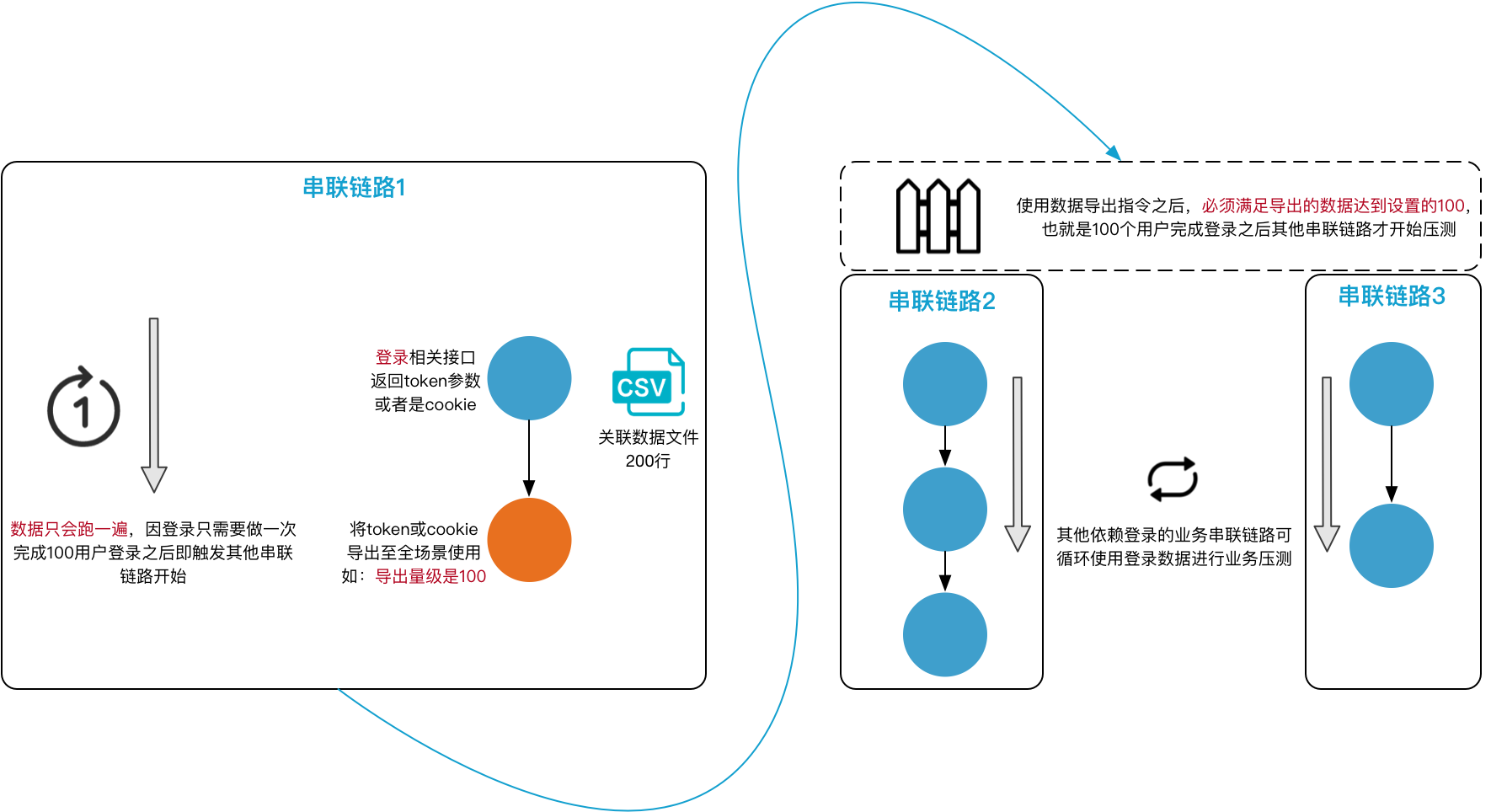
图例说明如下:
- 数据导出指令一般应用于登录之后需要并行压测多个不同业务串联链路的情况,支持标准的Cookie导出或者是业务自定义的出参导出,目前支持最多导出5个参数,每个参数的量级均为设置值。
- 串联链路1使用了数据导出指令,数据导出完成后其它串联链路才能开始压测,所以与其他串联链路不是并行的关系。说明 只有使用了数据导出指令,才会出现串联链路之间不是全都并行的情况。
- 为保证用户登录信息不重复,需在压测API对应的数据配置中为某参数设置数据轮询一次。本示例中串联链路1中的参数设置了数据只轮询一次。
- 一批用户登录完成后,将用户登录信息共享给场景内其它业务的串联链路使用,需设置数据导出的导出量级。达到该量级才会触发场景内剩余串联链路进行压测。
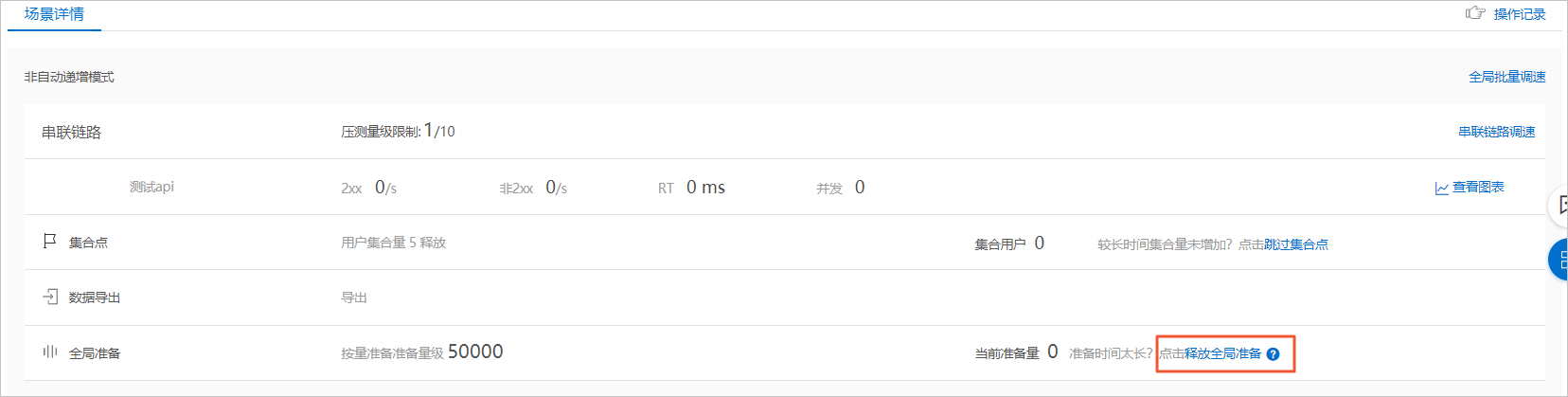
- 准备量级需要小于等于登录接口的文件行数。例如上述示例中关联数据文件为200行,导出量级设置为100。说明 若出现量级不满(如部分施压机压测过程中异常掉线)的情况,为不影响继续压测,请单击压测中的页面下方的释放全局准备,即可继续执行其它串联链路的压测。
反馈
- 本页导读 (1)
文档反馈