Avoid spilling to disk
When memory is insufficient during query execution, AnalyticDB for PostgreSQL temporarily writes intermediate results to disk — a process called disk spill. Because disk access is significantly slower than memory access, disk spill degrades query performance and should be eliminated.
How to detect disk spill
Run EXPLAIN ANALYZE on a slow query and check the Workfile field in the output:
-
Positive integer — the operator has spilled to disk.
-
0 — no spill occurred.
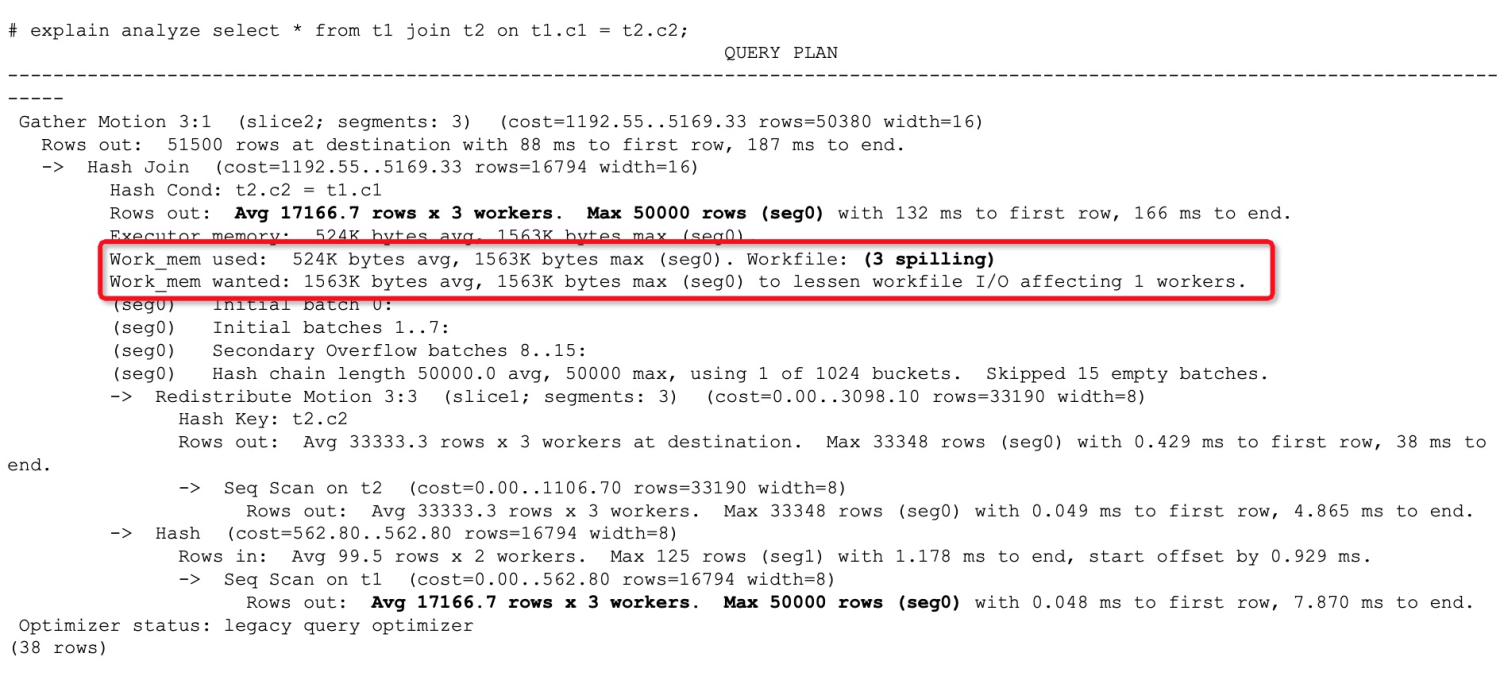
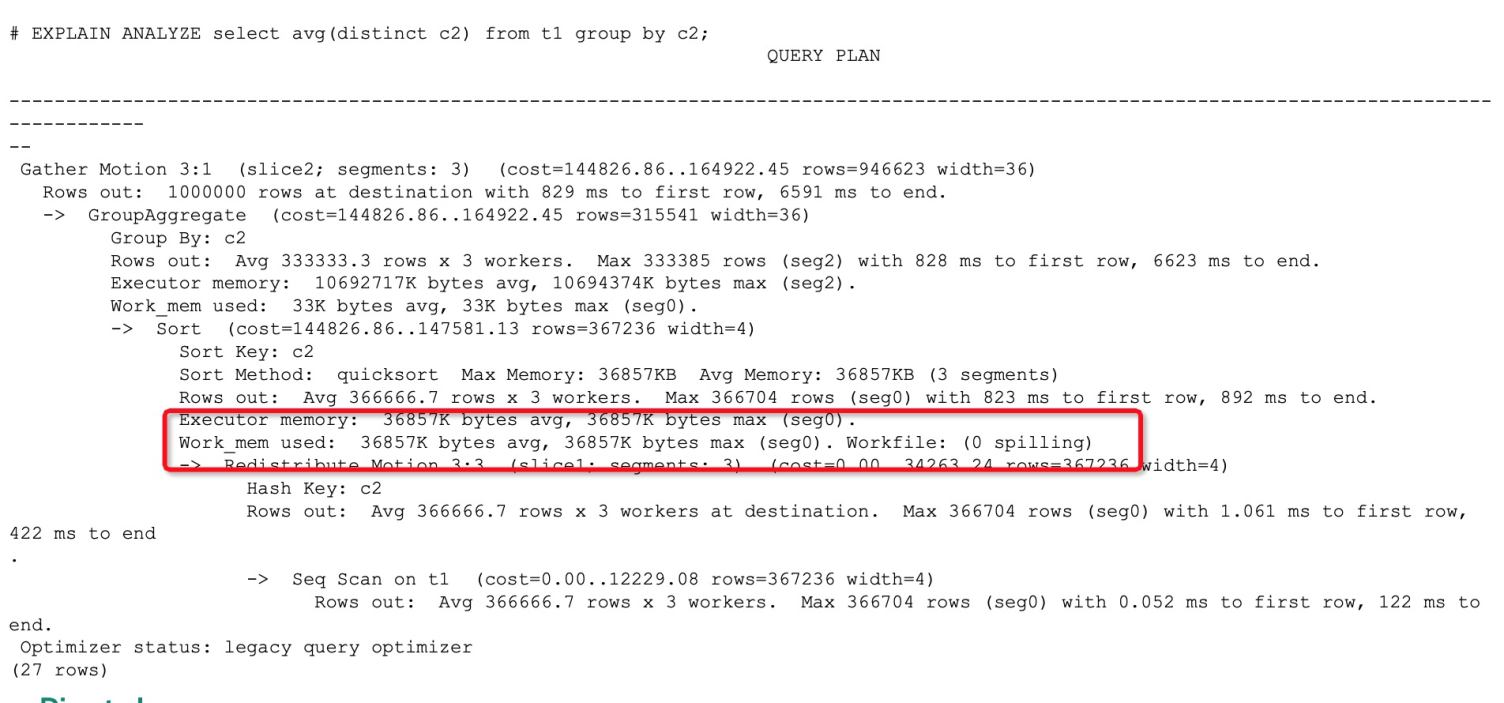
Disk spill typically occurs during SORT, JOIN, or HASH operations on large tables. Once you confirm spill is happening, identify the root cause to choose the right fix.
Root causes and fixes
Insufficient memory allocated to the query
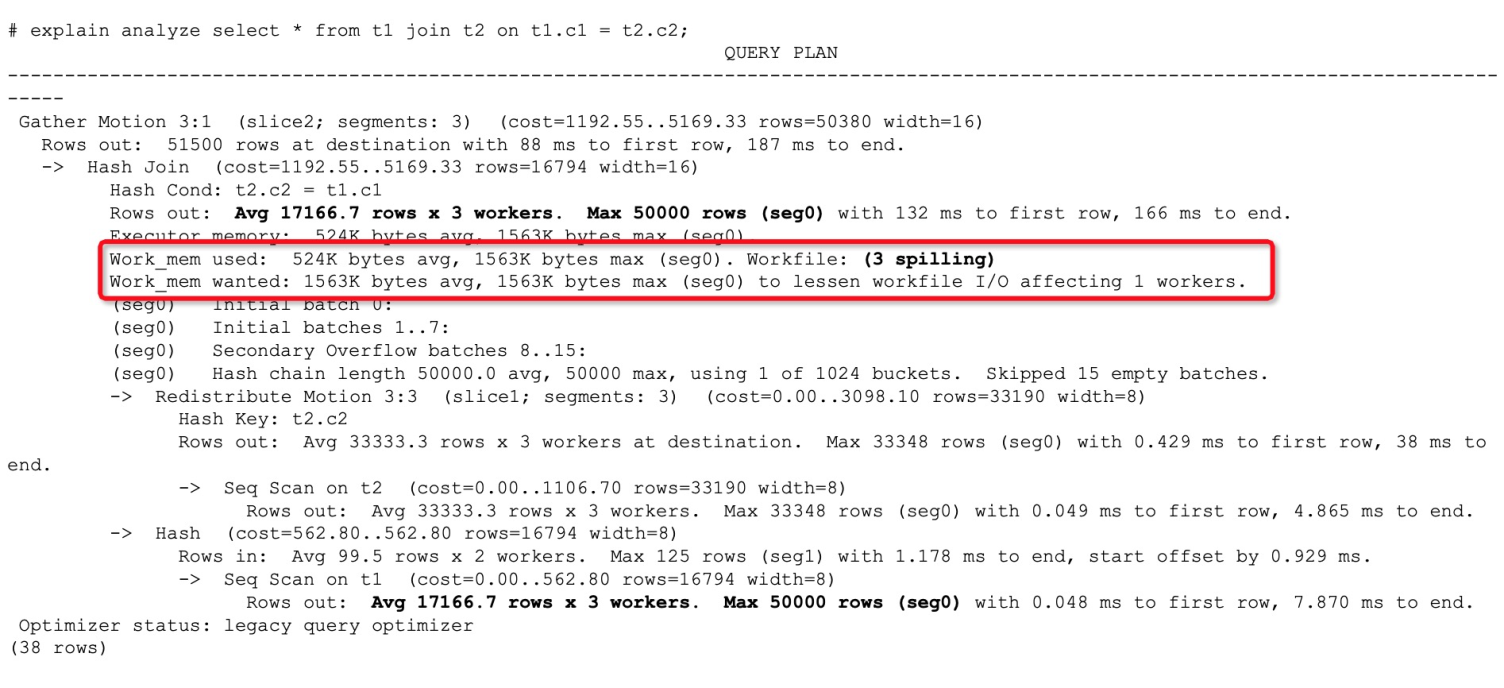
If the Workfile value is positive but the query processes a relatively small volume of data, the available memory is likely capped — either by a resource group or resource queue limit, or by a statement_mem value that is too low.
To fix this, increase statement_mem for the session:
SET statement_mem TO '256MB';Excessive computation volume
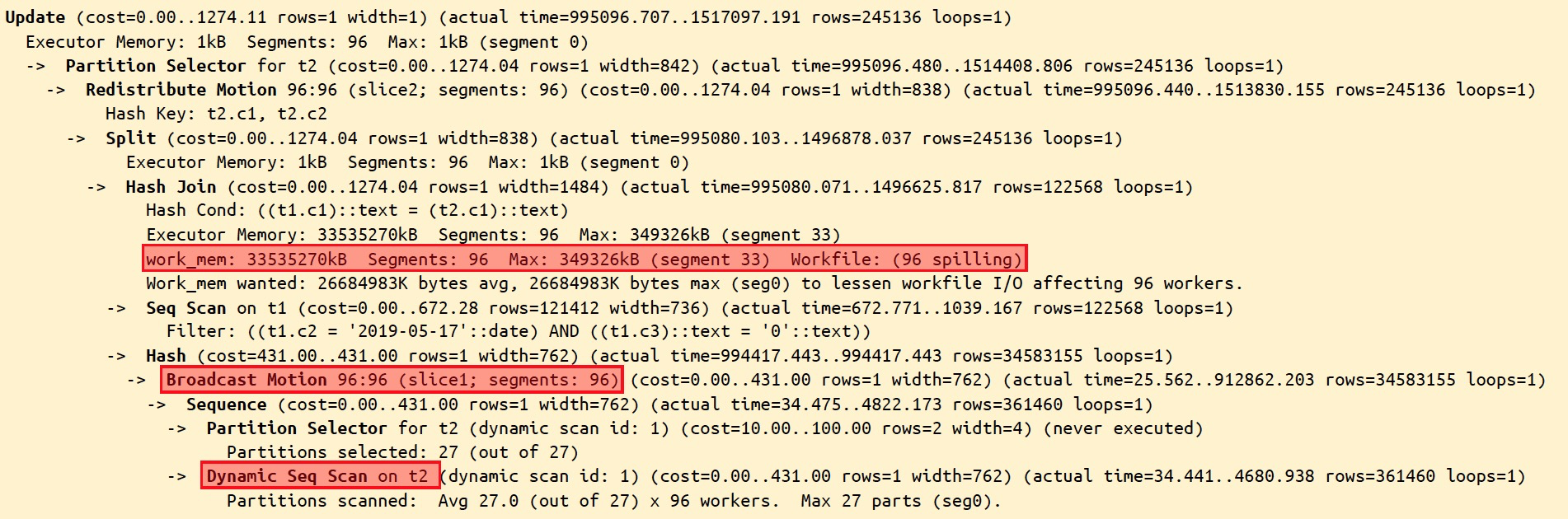
If statement_mem is already large but spill still occurs, the query requires more memory than the parameter can provide. This often happens when the query planner has a stale or inaccurate row-count estimate.
For example, if the planner evaluates a large table (such as t2) as a single-row table, it may choose to broadcast the table in a hash join — causing a disproportionately large computation volume. Running ANALYZE on the table updates statistics and gives the planner accurate estimates:
ANALYZE t2;Creating an index on the join or filter columns can also reduce the volume of data processed during execution.
Data skew
Data skew concentrates a disproportionate volume of data and computation on a single compute node, which can exhaust that node's memory and trigger spill even when other nodes are idle.
For steps to identify and resolve data skew, see Data skew elimination.
Related topics
-
Data skew elimination — identify uneven data distribution across compute nodes and rebalance it to prevent skew-induced spill and out-of-memory errors.