Selection of distribution keys
Choosing the right distribution key is a key design decision when building tables in AnalyticDB for PostgreSQL. A well-chosen distribution key spreads data evenly across compute nodes and keeps related data local, so queries run without moving data over the network.
How distribution keys affect query performance
AnalyticDB for PostgreSQL moves data between compute nodes based on the relationship between the distribution key and the join key in your query. Three execution patterns are possible:
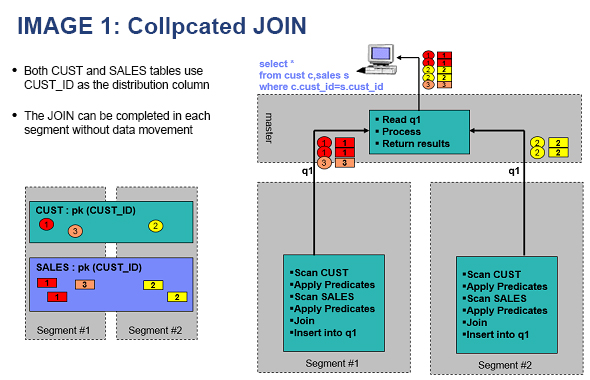
Collocated join — When the join key matches the distribution key, rows that need to be joined are already on the same compute node. No data movement is required.
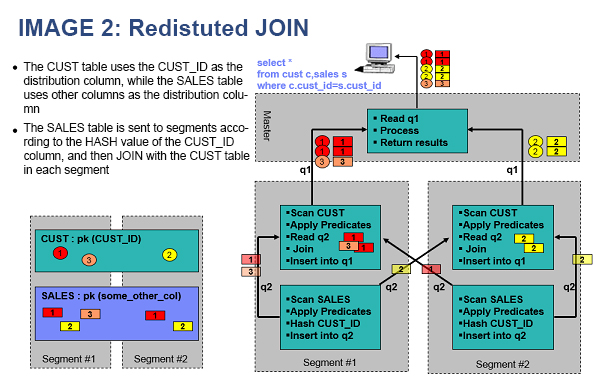
Redistributed join — When the join key differs from the distribution key, the system performs a redistribute motion: it shuffles rows across compute nodes before joining.
Broadcast join — As an alternative to redistribution, the system performs a broadcast motion: it copies one table entirely to every compute node.
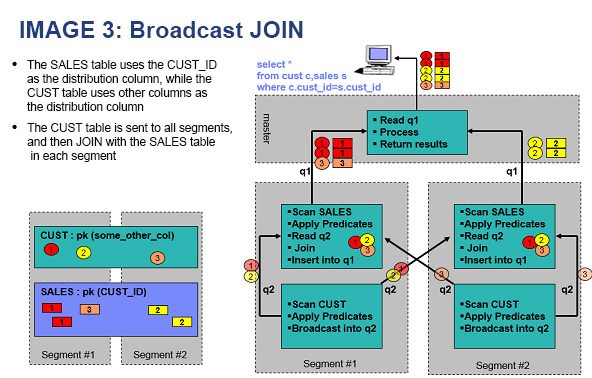
Redistributed and broadcast joins both incur higher network overhead than collocated joins. Choosing distribution keys that enable collocated joins is the primary goal.
Principles for choosing a distribution key
Even data distribution
Choose a column whose values are spread evenly across rows. If the values are skewed — for example, a Boolean column where 90% of rows are true — some compute nodes end up holding more data than others. This is called data skew. Skewed nodes become bottlenecks: they handle a disproportionate share of the query workload and slow down the entire query.
Avoid distribution columns of the Boolean, time, or date type, as these commonly produce skewed distributions.
Local join execution
Choose a column that is frequently used as a join key. When the distribution key matches the join key, AnalyticDB for PostgreSQL executes the join locally within each compute node — no data movement needed. This is the fastest join pattern.
Query predicate filtering
Choose a column that appears frequently in WHERE clause conditions. When a query filters on the distribution key, AnalyticDB for PostgreSQL identifies which compute nodes hold the relevant data and skips the rest. This reduces the number of nodes involved in query execution.
Default behavior when no distribution key is specified
If you do not specify a distribution key when creating a table:
The primary key is used as the distribution key.
If there is no primary key, the first column is used.
Multi-column distribution keys
The distribution key can span more than one column. Use a multi-column key when no single column achieves even distribution on its own.
CREATE TABLE t1 (c1 int, c2 int) DISTRIBUTED BY (c1, c2);Random distribution
Random distribution spreads rows across compute nodes without regard to column values. It does not support collocated joins or compute node filtering, so it offers the weakest query optimization. Use it only when no column or column combination achieves even distribution.
Selecting a distribution key: a decision guide
Use this sequence to select a distribution key:
Identify a single high-cardinality column that distributes data evenly. The primary key is often a good starting point.
Prefer columns used in frequent joins. A distribution key that enables collocated joins eliminates the costliest query operations.
Avoid low-cardinality types — Boolean, time, or date columns tend to concentrate data on a small number of nodes.
If one column is not enough, use two columns with
DISTRIBUTED BY (col1, col2).Fall back to random distribution only when no column combination produces even distribution.