In an ACS cluster with GPU devices, you can schedule multiple GPU pods to the same GPU-HPN node. The pods can then exchange data between GPUs by using technologies such as NVLink. To ensure communication efficiency and fairness between GPU devices, ACS adheres to the partition constraints of different node models when scheduling devices. This topic describes the GPU partition scheduling mechanism in ACS and provides use case examples.
Prerequisites
This feature is supported only for pods of the gpu-hpn compute class and their corresponding node types.
Background
On a node, GPU devices interconnect through one or more communication channels. ACS allows pods with different GPU requirements to run on the same GPU-HPN node. To ensure efficient and fair GPU communication and prevent interference between pods, ACS schedules pods based on the GPU device topology. ACS creates partitions based on the number of GPUs requested by each pod to find the optimal allocation.
The following figure shows a node with eight GPUs. The GPUs are arranged in two groups of four. Within each group, the GPUs are directly interconnected. The two groups are connected through PCIe.
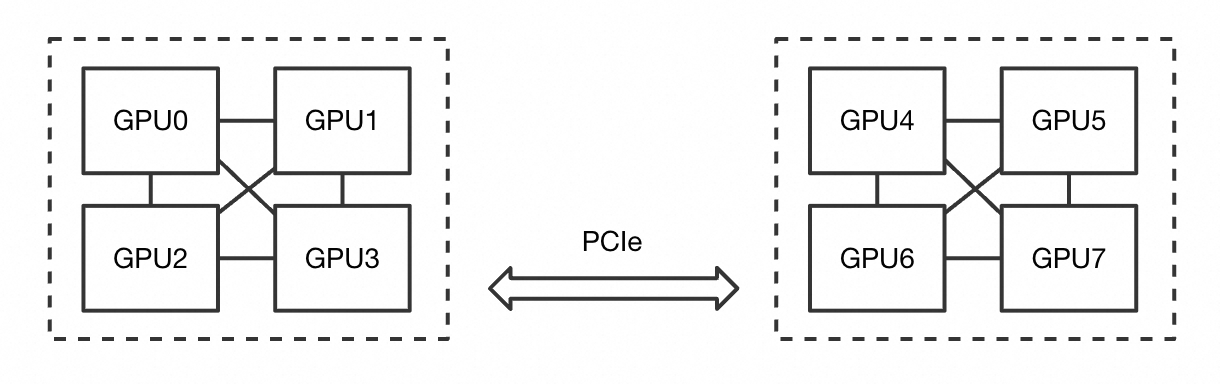
The following table describes how ACS creates partitions for pods with different GPU requests.
|
GPUs requested |
Allocation results |
|
8 |
[0,1,2,3,4,5,6,7] |
|
4 |
[0,1,2,3], [4,5,6,7] |
|
2 |
[0,1], [2,3], [4,5], [6,7] |
|
1 |
[0], [1], [2], [3], [4], [5], [6], [7] |
Continuously creating and deleting pods on a node can cause partition fragmentation on the GPU devices. This can prevent new pods from scheduling, leaving them in the Pending state. You can review the scheduling results of existing pods and, based on your business priorities, evict some pods to meet the resource demands of the pending pods.
GPU-HPN node partitions
The partition configurations and GPU model vary across different GPU-HPN node types in ACS.
gpu.p16en-16XL
This node type contains 16 GPUs of the P16EN model. The following table shows the possible allocation results for pods with different GPU requests.
|
GPUs requested |
Allocation results |
|
16 |
[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15] |
|
8 |
[0,1,2,3,4,5,6,7], [8,9,10,11,12,13,14,15] |
|
4 |
[0,1,2,3], [4,5,6,7], [8,9,10,11], [12,13,14,15] |
|
2 |
[0,3], [1,2], [4,7], [5,6], [8,11], [9,10], [12,15], [13,14] |
|
1 |
[0], [1], [2], [3], [4], [5], [6], [7], [8], [9], [10], [11], [12], [13], [14], [15] |
Pod scheduling results
Device allocation result
For a GPU-HPN pod, you can check its device allocation result in the pod annotation.
apiVersion: v1
kind: Pod
metadata:
annotations:
alibabacloud.com/device-allocation: '{"gpus": {"minor": [0,1,2,3]}}'Scheduling failure due to partition fragmentation
When a pod cannot be scheduled, it enters the Pending state. Running the kubectl describe pod command displays a message similar to 0/5 nodes are available: xxx. The message Insufficient Partitioned GPU Devices indicates a scheduling failure due to resource fragmentation on the node. The following is an example.
kubectl describe pod pod-demoExample output (other content is omitted):
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 26m default-scheduler 0/5 nodes are available: 2 Node(s) Insufficient Partitioned GPU Devices, 1 Node(s) xxx, 2 Node(s) xxx.FAQ
Avoiding partition fragmentation
-
Use different node labels to manage resources based on the GPU requirements of your pods. For example, you can assign pods that require 8 GPUs and pods that require 1 GPU to different nodes.
-
If pods are in the Pending state due to fragmentation, you can use descheduling to evict lower-priority pods. This frees up resources for the pending pods.
-
If your cluster is small or you cannot use labels to manage nodes, and your applications require various GPU specifications, consider using GPU pod capacity reservation to satisfy your application's resource requirements.
Selecting pods for eviction
-
Identify the resource requirements of the pending pod, for example, 8 GPUs.
-
Check the pod annotations on the target node and find the device allocation result in the
alibabacloud.com/device-allocationannotation. -
Based on the allocation result, determine which pods to evict. For example, a pod that requests 8 GPUs of the P16EN model requires an unallocated block of device IDs, such as [0,1,2,3,4,5,6,7] or [8,9,10,11,12,13,14,15].
-
Evict the pods by using a command such as
evictordelete.
Partitions and custom schedulers
After a custom scheduler assigns a pod to a node, ACS handles device allocation for that pod. During the device allocation phase, ACS attempts to place devices as compactly as possible to avoid fragmentation.
The custom scheduler only needs to consider the total GPU capacity of a node. We recommend that you use a bin-packing scheduling policy for GPU resources, such as MostAllocated. This can effectively reduce partition fragmentation.
Topology awareness in schedulers
|
Scheduler type |
Conditions |
Description |
|
ACS default scheduler |
All of the following conditions are met:
Any of the following conditions is met:
For more information, see kube-scheduler. |
The scheduler is aware of the partition allocation status on the current node and excludes nodes that do not meet partition requirements. The pod scheduling failure event includes the |
|
ACK default scheduler |
All of the following conditions are met:
For more information, see kube-scheduler. |
|
|
Other scheduler types, conditions, or configurations not listed above |
The scheduler is unaware of the partition topology. The GPU-HPN node attempts to allocate devices in a consolidated manner. If the partition requirements are not met, the pod remains in the Pending state on the node until its requirements are satisfied. The event message includes |
|