Collaborative consumption lets multiple consumers share a topic's shards automatically, without manual coordination. DataHub distributes shards evenly across all active consumer instances in a consumer group and reallocates them whenever a consumer joins, leaves, or a shard is split.
Collaborative consumption
How it works
Offset-based data consumption
DataHub saves consumption offsets on the server. A consumption offset identifies the position of the last processed record, consisting of the record's sequence number and the timestamp when it was written to DataHub.
When your application starts, it retrieves the saved offset from the server and resumes from the next record. Server-side offset storage is required for collaborative consumption — without it, DataHub cannot resume correctly after shards are reallocated.
In a consumer group, offset submission is handled automatically. In the config clause, set the interval at which offsets are committed. DataHub treats all records before the committed offset as processed. If your application is interrupted before committing an offset, it may reprocess some records on restart — this is expected at-least-once delivery behavior.
Collaborative consumption
Collaborative consumption automatically distributes a topic's shards across multiple consumer instances in the same consumer group. Each shard is assigned to exactly one consumer instance at a time. When a consumer instance joins or leaves, DataHub reallocates shards across the remaining active instances.
This removes the need for consumers to coordinate shard assignments among themselves — useful when consumer instances run on different machines.
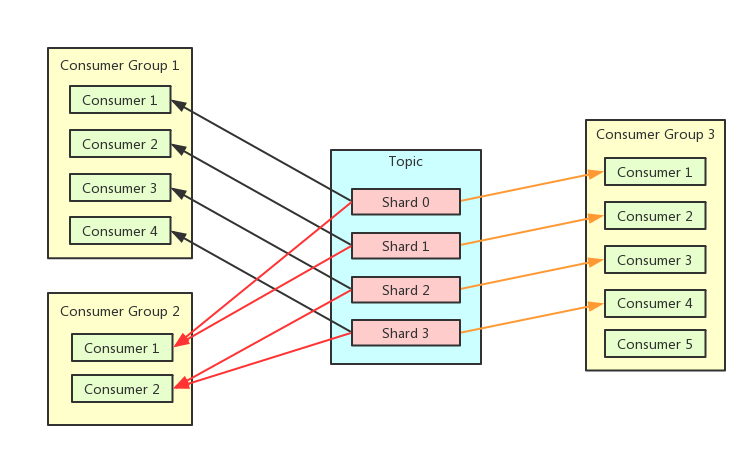
Shard allocation example
The following example shows how DataHub reallocates shards as consumer instances join, leave, or when shards are split. Three consumer instances (A, B, C) consume a topic with 10 shards.
Consumer instance A starts first. All 10 shards are allocated to it.
Consumer instances B and C start. DataHub reallocates: 4 shards to A, 3 to B, and 3 to C.
One of A's shards splits into two. After both child shards are consumed and released, DataHub reallocates: 4 shards to A, 4 to B, and 3 to C.
Consumer instance C stops. DataHub reallocates: 6 shards to A and 5 to B.
Heartbeat mechanism
Each consumer instance sends periodic heartbeats to the server. The heartbeat reports the instance's current status, the shards assigned to it, and any shards it needs to release.
If the server receives no heartbeat from a consumer instance within the configured interval, it considers that instance stopped and triggers a shard reallocation. The server returns the updated allocation plan in the heartbeat response, so there is a brief delay between when a reallocation is triggered and when the client detects it.
Prerequisites
Maven dependencies
Add the following dependencies to your Maven pom:
<dependency>
<groupId>com.aliyun.datahub</groupId>
<artifactId>aliyun-sdk-datahub</artifactId>
<version>2.18.0-public</version>
</dependency>
<dependency>
<groupId>com.aliyun.datahub</groupId>
<artifactId>datahub-client-library</artifactId>
<version>1.1.12-public</version>
</dependency>JDK
jdk: >= 1.8Sample code
For examples of reading and writing data, see Data read and write.