DataHub is fully compatible with the Kafka protocol. You can use a native Kafka client to read data from and write data to DataHub.
Introduction
Kafka to DataHub mapping
Topic type
Kafka and DataHub topics use different scale-out methods. To align with the scale-out method of Kafka, when you create a DataHub topic, set the scale-out method to Extension Mode. Topics in Extension Mode do not support split or merge operations. Instead, you can add shards. You cannot reduce the number of shards.
Topic naming
A Kafka topic is mapped to a DataHub project and topic, which are separated by a period (.). For example, `test_project.test_topic` maps to the `test_project` project and the `test_topic` topic in DataHub. If a name contains multiple periods, the first period separates the project from the topic. All subsequent periods (.) and hyphens (-) are replaced with underscores (_).
Partition
Each active shard in DataHub corresponds to a partition in Kafka. For example, if a topic has five active shards, you can treat them as five Kafka partitions. When you write data, you can specify a partition from 0 to 4. If you do not specify a partition, the Kafka client selects one for you.
Tuple topic
When you write Kafka data to a Tuple topic, the topic schema must contain one or two columns of the STRING data type. Otherwise, the write operation fails. If the schema has one column, only the value is written, and the key is discarded. If the schema has two columns, the first and second columns correspond to the key and value, respectively. Writing binary data to a Tuple topic can result in garbled text. We recommend that you write binary data to a BLOB topic instead.
BLOB Topic
When you write Kafka data to a BLOB topic, the value of the Kafka data is written to the BLOB. If the key of the Kafka data is not NULL, the key is written to a DataHub attribute. The key for this attribute is `__kafka_key__` and its value is the key from the Kafka data.
Header
A Kafka header corresponds to a DataHub attribute. However, if the value of a Kafka header is NULL, the header is ignored. Do not use `__kafka_key__` as a header key.
Consumer group
In DataHub, a consumer group corresponds to a subscription ID. A subscription ID can be used to subscribe to only one topic at a time. In contrast, a Kafka group can subscribe to multiple topics simultaneously. To better support the subscription method of Kafka, DataHub provides a group feature. You can create a group within a project and attach the topics to which you want to subscribe. This allows a group to subscribe to multiple topics within the same project. A DataHub group is an encapsulation of multiple DataHub subscriptions on the server-side. If you attach a topic to a group, the group automatically creates a subscription. You can view this subscription on the subscription list page of the topic. If you delete this subscription, the group can no longer subscribe to the topic, and all previous checkpoints are lost.
Currently, a single group can subscribe to a maximum of 50 topics. To subscribe to more topics, you can open a ticket.
Kafka configuration parameters
C=Consumer, P=Producer, S=Streams
Parameter |
C/P/S |
Optional values |
Required |
Description |
bootstrap.servers |
* |
See the Kafka domain name list. |
Yes |
|
security.protocol |
* |
SASL_SSL |
Yes |
To ensure data security, writing data from Kafka to DataHub uses SSL encryption by default. |
sasl.mechanism |
* |
PLAIN |
Yes |
AccessKey authentication method. Only PLAIN is supported. |
compression.type |
P |
LZ4 |
No |
Specifies whether to enable compression for transport. Currently, only LZ4 is supported. |
group.id |
C |
project.topic:subId or project.group |
Yes |
If you use the `project.topic:subId` format, the topic must be the same as the subscribed topic. Otherwise, data cannot be read. We recommend using the `project.group` format. |
partition.assignment.strategy |
C |
org.apache.kafka.clients.consumer.RangeAssignor |
No |
The default value in Kafka is RangeAssignor. DataHub currently supports only RangeAssignor. Do not change this configuration. |
session.timeout.ms |
C/S |
[60000, 180000] |
No |
The default value in Kafka is 10000. However, because the minimum value required by DataHub is 60000, the default value is changed to 60000. |
heartbeat.interval.ms |
C/S |
Recommended: 2/3 of session.timeout.ms |
No |
The default value in Kafka is 3000. However, because `session.timeout.ms` is changed to 60000 by default, we recommend that you explicitly set this parameter to 40000. Otherwise, heartbeat requests are sent too frequently. |
application.id |
S |
project.topic:subId or project.group |
Yes |
If you use the `project.topic:subId` format, the topic must be the same as the subscribed topic. Otherwise, data cannot be read. We recommend using the `project.group` format. |
The parameters listed in the preceding table are important when you use a Kafka client to write data to DataHub. The behavior of client-side parameters, such as retries and batch.size, is not affected. Server-side parameters do not affect the behavior on the server-side. For example, regardless of the value specified for acks, DataHub returns a response only after the data is successfully written.
Kafka domain name list
Area |
Region |
Public Endpoint |
Classic Network ECS Endpoint |
VPC ECS Endpoint |
China (Hangzhou) |
cn-hangzhou |
dh-cn-hangzhou.aliyuncs.com:9092 |
dh-cn-hangzhou.aliyun-inc.com:9093 |
dh-cn-hangzhou-int-vpc.aliyuncs.com:9094 |
China (Shanghai) |
cn-shanghai |
dh-cn-shanghai.aliyuncs.com:9092 |
dh-cn-shanghai.aliyun-inc.com:9093 |
dh-cn-shanghai-int-vpc.aliyuncs.com:9094 |
China (Beijing) |
cn-beijing |
dh-cn-beijing.aliyuncs.com:9092 |
dh-cn-beijing.aliyun-inc.com:9093 |
dh-cn-beijing-int-vpc.aliyuncs.com:9094 |
China (Shenzhen) |
cn-shenzhen |
dh-cn-shenzhen.aliyuncs.com:9092 |
dh-cn-shenzhen.aliyun-inc.com:9093 |
dh-cn-shenzhen-int-vpc.aliyuncs.com:9094 |
North China 3 (Zhangjiakou) |
cn-zhangjiakou |
dh-cn-zhangjiakou.aliyuncs.com:9092 |
dh-cn-zhangjiakou.aliyun-inc.com:9093 |
dh-cn-zhangjiakou-int-vpc.aliyuncs.com:9094 |
Asia Pacific SE 1 (Singapore) |
ap-southeast-1 |
dh-ap-southeast-1.aliyuncs.com:9092 |
dh-ap-southeast-1.aliyun-inc.com:9093 |
dh-ap-southeast-1-int-vpc.aliyuncs.com:9094 |
Asia Pacific SE 3 (Kuala Lumpur) |
ap-southeast-3 |
dh-ap-southeast-3.aliyuncs.com:9092 |
dh-ap-southeast-3.aliyun-inc.com:9093 |
dh-ap-southeast-3-int-vpc.aliyuncs.com:9094 |
Asia Pacific S 1 (Mumbai) Decommissioned |
ap-south-1 |
dh-ap-south-1.aliyuncs.com:9092 |
dh-ap-south-1.aliyun-inc.com:9093 |
dh-ap-south-1-int-vpc.aliyuncs.com:9094 |
EU Central 1 (Frankfurt) |
eu-central-1 |
dh-eu-central-1.aliyuncs.com:9092 |
dh-eu-central-1.aliyun-inc.com:9093 |
dh-eu-central-1-int-vpc.aliyuncs.com:9094 |
Shanghai Finance Cloud |
cn-shanghai-finance-1 |
dh-cn-shanghai-finance-1.aliyuncs.com:9092 |
dh-cn-shanghai-finance-1.aliyun-inc.com:9093 |
dh-cn-shanghai-finance-1-int-vpc.aliyuncs.com:9094 |
China (Hong Kong) |
cn-hongkong |
dh-cn-hongkong.aliyuncs.com:9092 |
dh-cn-hongkong.aliyun-inc.com:9093 |
dh-cn-hongkong-int-vpc.aliyuncs.com:9094 |
Examples
Create a topic
Creating a page
Creating code
Note: You cannot use the Kafka API to create topics. You must use the DataHub SDK. When you create a topic, you must set the ExpandMode parameter to ONLY_EXTEND. Ensure that the Maven dependency version is 2.19.0 or later.
You also need to configure the AccessKey ID and AccessKey secret for your project. We recommend that you configure these credentials as environment variables in the configuration file.
datahub.endpoint=<yourEndpoint>
datahub.accessId=<yourAccessKeyId>
datahub.accessKey=<yourAccessKeySecret>An AccessKey for an Alibaba Cloud account has permissions to access all APIs. For improved security, we recommend that you use a Resource Access Management (RAM) user for API access or daily operations and maintenance (O&M).
We strongly recommend that you do not save your AccessKey ID and AccessKey secret in your project code. Doing so can lead to an AccessKey leak, which compromises the security of all resources in your account.
<dependency>
<groupId>com.aliyun.datahub</groupId>
<artifactId>aliyun-sdk-datahub</artifactId>
<version>2.19.0-public</version>
</dependency>@Value("${datahub.endpoint}")
String endpoint ;
@Value("${datahub.accessId}")
String accessId;
@Value("${datahub.accessKey}")
String accessKey;
public class CreateTopic {
public static void main(String[] args) {
DatahubClient datahubClient = DatahubClientBuilder.newBuilder()
.setDatahubConfig(
new DatahubConfig(endpoint,
new AliyunAccount(accessId, accessKey)))
.build();
int shardCount = 1;
int lifeCycle = 7;
try {
datahubClient.createTopic("test_project", "test_topic", shardCount, lifeCycle, RecordType.BLOB, "comment", ExpandMode.ONLY_EXTEND);
} catch (DatahubClientException e) {
e.printStackTrace();
}
}
}Create a group
Page Creation
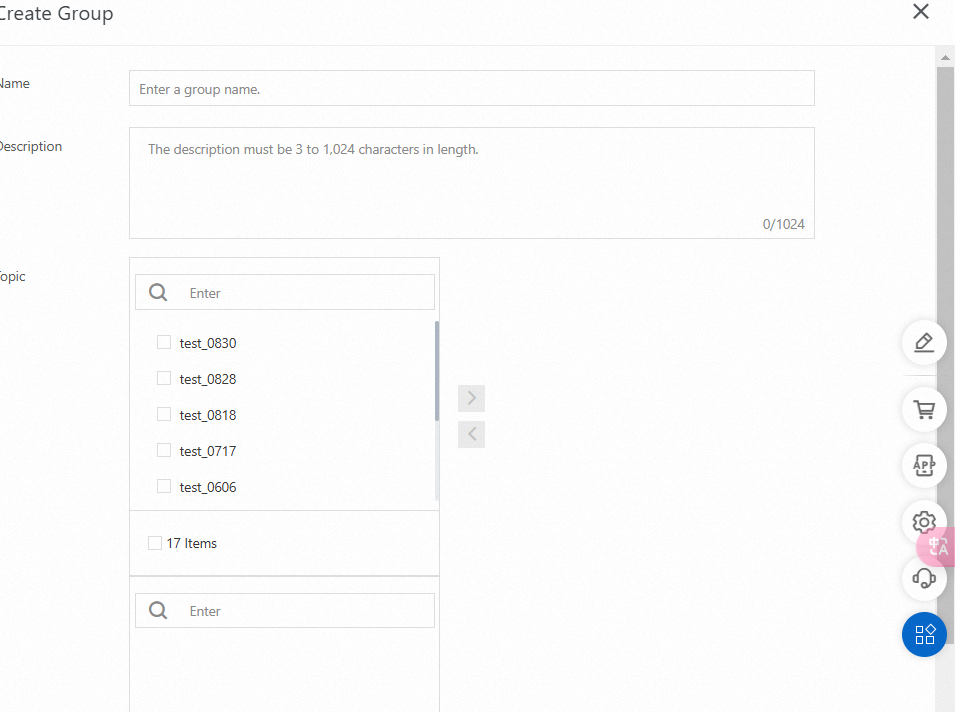
After you create the group, you can modify the list of attached topics. You can select any topic during the initial setup.
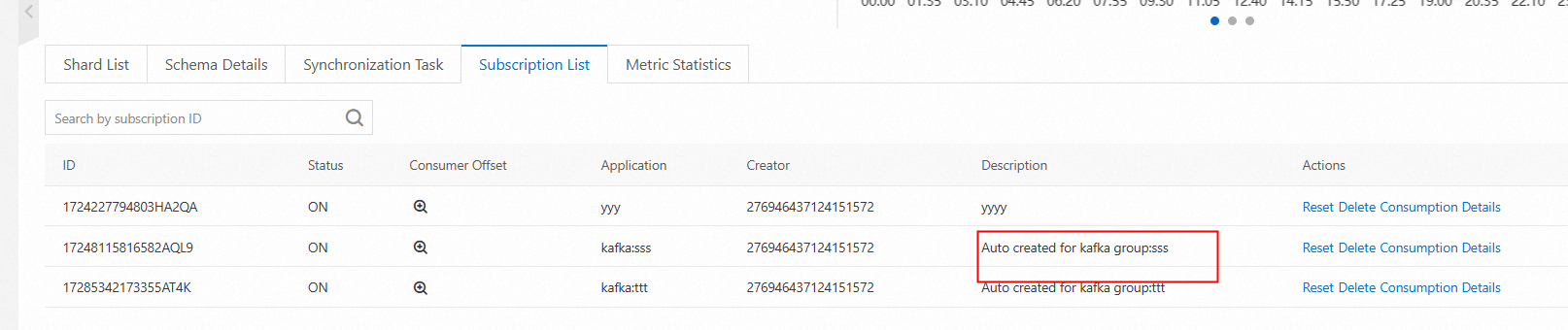
After the group is created, you can view the subscription that the group automatically created on the subscription list page of the topic.
Code Creation
Ensure that the Maven dependency version is 2.21.6-public or later.
<dependency>
<groupId>com.aliyun.datahub</groupId>
<artifactId>aliyun-sdk-datahub</artifactId>
<version>2.21.6-public</version>
</dependency>@Value("${datahub.endpoint}")
String endpoint ;
@Value("${datahub.accessId}")
String accessId;
@Value("${datahub.accessKey}")
String accessKey;
public class CreateGroup {
public static void main(String[] args) {
DatahubClient datahubClient = DatahubClientBuilder.newBuilder()
.setDatahubConfig(
new DatahubConfig(endpoint,
new AliyunAccount(accessId, accessKey)))
.build();
List<String> topicList = new ArrayList<>();
topicList.add("test_project.topic1");
topicList.add("test_project.topic2");
topicList.add("test_project.topic3");
try {
// Create a Kafka group.
datahubClient.createKafkaGroup("test_project", "test_topic", "test comment");
// Attach the topics to subscribe to the group.
datahubClient.updateTopicsForKafkaGroup("test_project", "test_topic", topicList, UpdateKafkaGroupMode.ADD);
} catch (DatahubClientException e) {
e.printStackTrace();
}
}
}Producer example
Generate the kafka_client_producer_jaas.conf file
Create a file named kafka_client_producer_jaas.conf, save it to any path, and add the following content to the file.
KafkaClient {
org.apache.kafka.common.security.plain.PlainLoginModule required
username="accessId"
password="accessKey";
};Maven dependency
The kafka-clients version must be 0.10.0.0 or later. We recommend using version 2.4.0.
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.0</version>
</dependency>Sample code
public class ProducerExample {
static {
System.setProperty("java.security.auth.login.config", "src/main/resources/kafka_client_producer_jaas.conf");
}
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "dh-cn-hangzhou.aliyuncs.com:9092");
properties.put("security.protocol", "SASL_SSL");
properties.put("sasl.mechanism", "PLAIN");
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("compression.type", "lz4");
String KafkaTopicName = "test_project.test_topic";
Producer<String, String> producer = new KafkaProducer<String, String>(properties);
try {
List<Header> headers = new ArrayList<>();
RecordHeader header1 = new RecordHeader("key1", "value1".getBytes());
RecordHeader header2 = new RecordHeader("key2", "value2".getBytes());
headers.add(header1);
headers.add(header2);
ProducerRecord<String, String> record = new ProducerRecord<>(KafkaTopicName, 0, "key", "Hello DataHub!", headers);
// Send synchronously.
producer.send(record).get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} finally {
producer.close();
}
}
}Result
After the code runs, you can sample the data in DataHub to confirm that it was written correctly.
Consumer example
For instructions on generating the kafka_client_producer_jaas.conf file and identifying the required Maven dependency, see the Producer example.
A new consumer is assigned a shard in about ten seconds and can then start consuming data.
Sample code
Example: Using a Kafka group (Recommended)
package com.aliyun.datahub.kafka.demo;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class ConsumerExample2 {
static {
System.setProperty("java.security.auth.login.config", "src/main/resources/kafka_client_producer_jaas.conf");
}
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "dh-cn-hangzhou.aliyuncs.com:9092");
properties.put("security.protocol", "SASL_SSL");
properties.put("sasl.mechanism", "PLAIN");
// Set group.id to project.group.
properties.put("group.id", "test_project.test_kafka_group");
properties.put("auto.offset.reset", "earliest");
properties.put("session.timeout.ms", "60000");
properties.put("heartbeat.interval.ms", "40000");
properties.put("ssl.endpoint.identification.algorithm", "");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
List<String> topicList = new ArrayList<>();
topicList.add("test_project.test_topic1");
topicList.add("test_project.test_topic2");
topicList.add("test_project.test_topic3");
// A Kafka group can subscribe to multiple topics at the same time.
kafkaConsumer.subscribe(topicList);
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(5));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.toString());
}
}
}
}Example: Using project.topic.subid
package com.aliyun.datahub.kafka.demo;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
public class ConsumerExample {
static {
System.setProperty("java.security.auth.login.config", "src/main/resources/kafka_client_producer_jaas.conf");
}
public static void main(String[] args) {
Properties properties = new Properties();
properties.put("bootstrap.servers", "dh-cn-hangzhou.aliyuncs.com:9092");
properties.put("security.protocol", "SASL_SSL");
properties.put("sasl.mechanism", "PLAIN");
// Set group.id to project.topic.subId.
properties.put("group.id", "test_project.test_topic:1611039998153N71KM");
properties.put("auto.offset.reset", "earliest");
properties.put("session.timeout.ms", "60000");
properties.put("heartbeat.interval.ms", "40000");
properties.put("ssl.endpoint.identification.algorithm", "");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<String, String>(properties);
// The project.topic.subId method can only subscribe to a single topic.
kafkaConsumer.subscribe(Collections.singletonList("test_project.test_topic"));
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(5));
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.toString());
}
}
}
}Result
After the code runs successfully, the data is displayed in the terminal.
ConsumerRecord(topic = test_project.test_topic, partition = 0, leaderEpoch = 0, offset = 0, LogAppendTime = 1611040892661, serialized key size = 3, serialized value size = 14, headers = RecordHeaders(headers = [RecordHeader(key = key1, value = [118, 97, 108, 117, 101, 49]), RecordHeader(key = key2, value = [118, 97, 108, 117, 101, 50])], isReadOnly = false), key = key, value = Hello DataHub!)Note: The LogAppendTime is the same for all data returned in a single request because it is the maximum timestamp of all data written to DataHub in that request.
Streams example
Maven dependency
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.4.0</version>
</dependency>Sample code
This example reads data from the `input` topic in the `test_project` project, converts the key and value strings to lowercase, and writes the results to the `output` topic.
public class StreamExample {
static {
System.setProperty("java.security.auth.login.config", "src/main/resources/kafka_client_producer_jaas.conf");
}
public static void main(final String[] args) {
final String input = "test_project.input";
final String output = "test_project.output";
final Properties properties = new Properties();
properties.put("bootstrap.servers", "dh-cn-hangzhou.aliyuncs.com:9092");
properties.put("application.id", "test_project.input:1611293595417QH0WL");
properties.put("security.protocol", "SASL_SSL");
properties.put("sasl.mechanism", "PLAIN");
properties.put("session.timeout.ms", "60000");
properties.put("heartbeat.interval.ms", "40000");
properties.put("auto.offset.reset", "earliest");
final StreamsBuilder builder = new StreamsBuilder();
TestMapper testMapper = new TestMapper();
builder.stream(input, Consumed.with(Serdes.String(), Serdes.String()))
.map(testMapper)
.to(output, Produced.with(Serdes.String(), Serdes.String()));
final KafkaStreams streams = new KafkaStreams(builder.build(), properties);
final CountDownLatch latch = new CountDownLatch(1);
Runtime.getRuntime().addShutdownHook(new Thread("streams-shutdown-hook") {
@Override
public void run() {
streams.close();
latch.countDown();
}
});
try {
streams.start();
latch.await();
} catch (final Throwable e) {
System.exit(1);
}
System.exit(0);
}
static class TestMapper implements KeyValueMapper<String, String, KeyValue<String, String>> {
@Override
public KeyValue<String, String> apply(String s, String s2) {
return new KeyValue<>(StringUtils.lowerCase(s), StringUtils.lowerCase(s2));
}
}
}Result
After you start a Streams task, it takes approximately one minute for shards to be assigned. You can then view the number of tasks in the console, which equals the number of shards in the input topic. For example, an input topic with three shards results in three tasks.
currently assigned active tasks: [0_0, 0_1, 0_2]
currently assigned standby tasks: []
revoked active tasks: []
revoked standby tasks: []After the shards are assigned, write a set of test data, such as (AAAA,BBBB), (CCCC,DDDD), and (EEEE,FFFF), to the input topic. Then, sample data from the output topic to verify that the data was written correctly.
Notes
Transactions and idempotence are not currently supported.
The Kafka client cannot automatically create DataHub topics. You must create the topic before you write data.
Currently, each Consumer can subscribe to only one topic.
The timestamp for data read by a consumer is always the LogAppendTime, which is the time the data was written to DataHub. All data returned in a single request has the same timestamp, which is the maximum timestamp of all data in the request. Therefore, the read timestamp might be later than the actual write time.
A Streams task can have only one input topic but can have multiple output topics.
Streams currently supports only stateless tasks.
Supported Kafka versions: 0.10.0 to 2.4.0.
FAQ
Q: The connection disconnects during data write operations.
Selector - [Producer clientId=producer-1] Connection with dh-cn-shenzhen.aliyuncs.com disconnected
java.io.EOFException
at org.apache.kafka.common.network.SslTransportLayer.read(SslTransportLayer.java:573)
...A: Kafka metadata requests and data write requests do not use the same connection. The initial metadata request establishes a connection. When data is written, a new connection is established with the broker that is returned in the metadata. All subsequent requests are sent over this second connection, leaving the first connection idle. The server-side closes connections that are idle for a certain period. If this error does not affect normal data writing, you can ignore it.
Q: The Kafka client failed to start
Caused by: org.apache.kafka.common.errors.SslAuthenticationException: SSL handshake failed
Caused by: javax.net.ssl.SSLHandshakeException: No subject alternative names matching IP address 100.67.134.161 foundA: You can add the following configuration: properties.put("ssl.endpoint.identification.algorithm", "");.
Q: What do I do if a DisconnectException occurs during consumption?
[INFO][Consumer clientId=client-id, groupId=consumer-project.topic:subid] Error sending fetch request (sessionId=INVALID, epoch=INITIAL) to node 1: {}.
org.apache.kafka.common.errors.DisconnectExceptionA: The Kafka client needs to maintain a persistent TCP connection with the server. This error is usually caused by network jitter, but it does not affect data consumption because the client has a retry mechanism.