Section | Description |
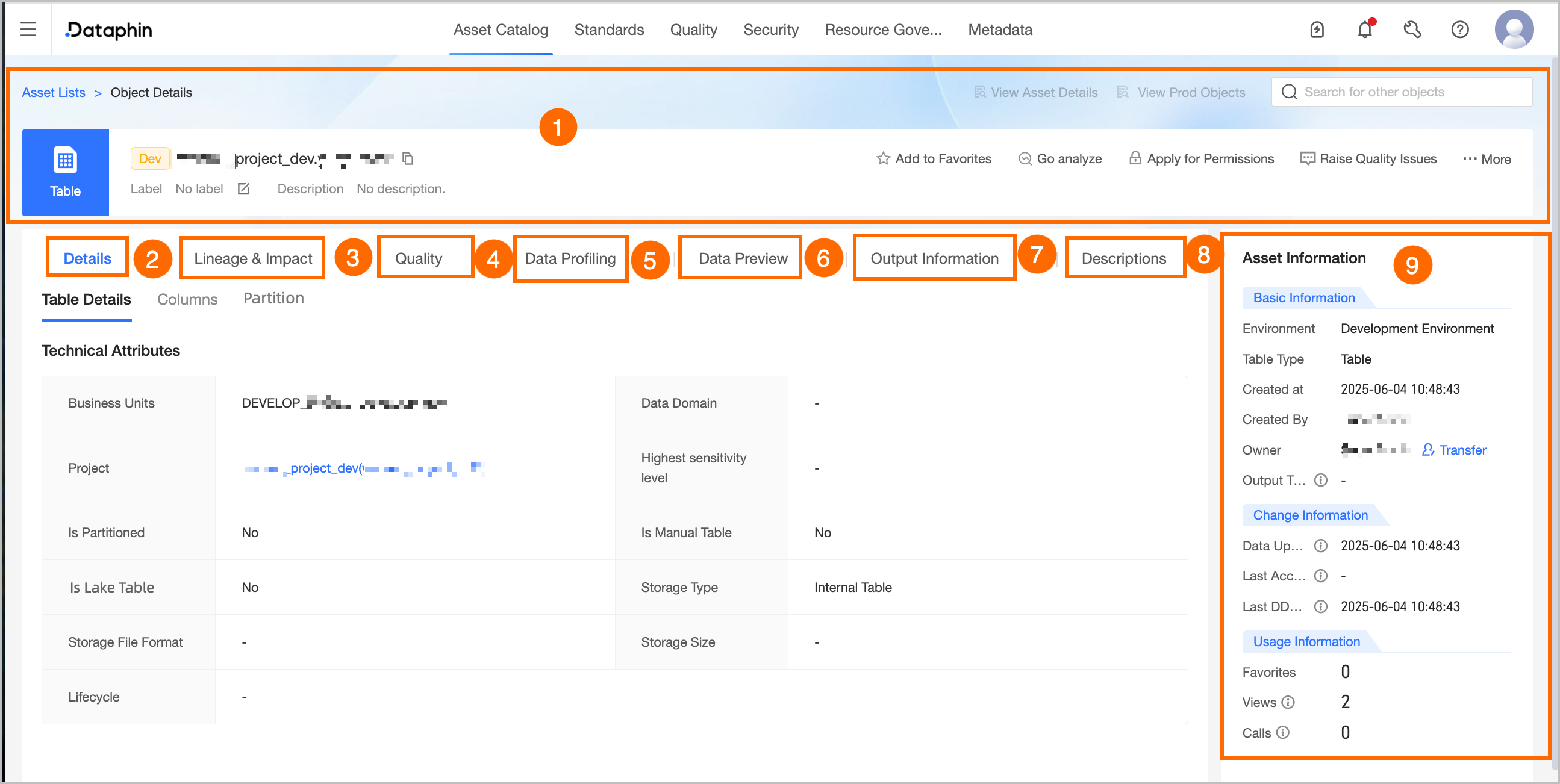
① Overview | This section displays key information about the table, such as its type, environment, name, tags, and description. You can also perform the following actions: Search for other assets: Quickly search for and switch to the details page of other assets. View Asset Details: If the current object is listed in the Asset Marketplace, you can quickly navigate to the marketplace details page to view its listing information. View Production/Development Object: Switch between object details in the production and development environments. Tags: Displays the tag values configured for the current asset. To modify tags, click Edit. Each tag value can be up to 128 characters long. Each asset can have up to 20 tag values. Super administrators can modify tags for all types of table assets. Table owners can modify tags for the tables they own. Project administrators can modify asset tags for physical tables in the projects they manage.
Favorite: Click to add or remove the asset from your favorites. After an asset is added to your favorites, you can find the 30 most recently favorited assets on the Asset List > My History page for quick access. You can view all your favorited assets in the Personal Data Center. For more information, see View and manage my favorite assets. Analyze: Click to open the Notebook page, where a corresponding Notebook task is automatically created. For more information, see Create a Notebook. Apply for Permissions: Click to open the permission application page for the current table. For more information, see Apply for, renew, and release table permissions. Report Quality Issue: Use this feature to report data quality issues you encounter (such as unstable data output or inaccurate data content) to the quality owner. This helps the relevant owner resolve issues promptly and improve the asset's availability and health. For configuration details, see Add and manage an issue list. To use the Report Quality Issue feature, you must activate the data quality module. You can then view the processing status and results of reported issues in the issue list of the data quality module. Generate SELECT Statement: Click to generate a SELECT statement for the current table. You can choose whether to add escape characters. You can copy the query statement and run it on the ad hoc query or analysis page. 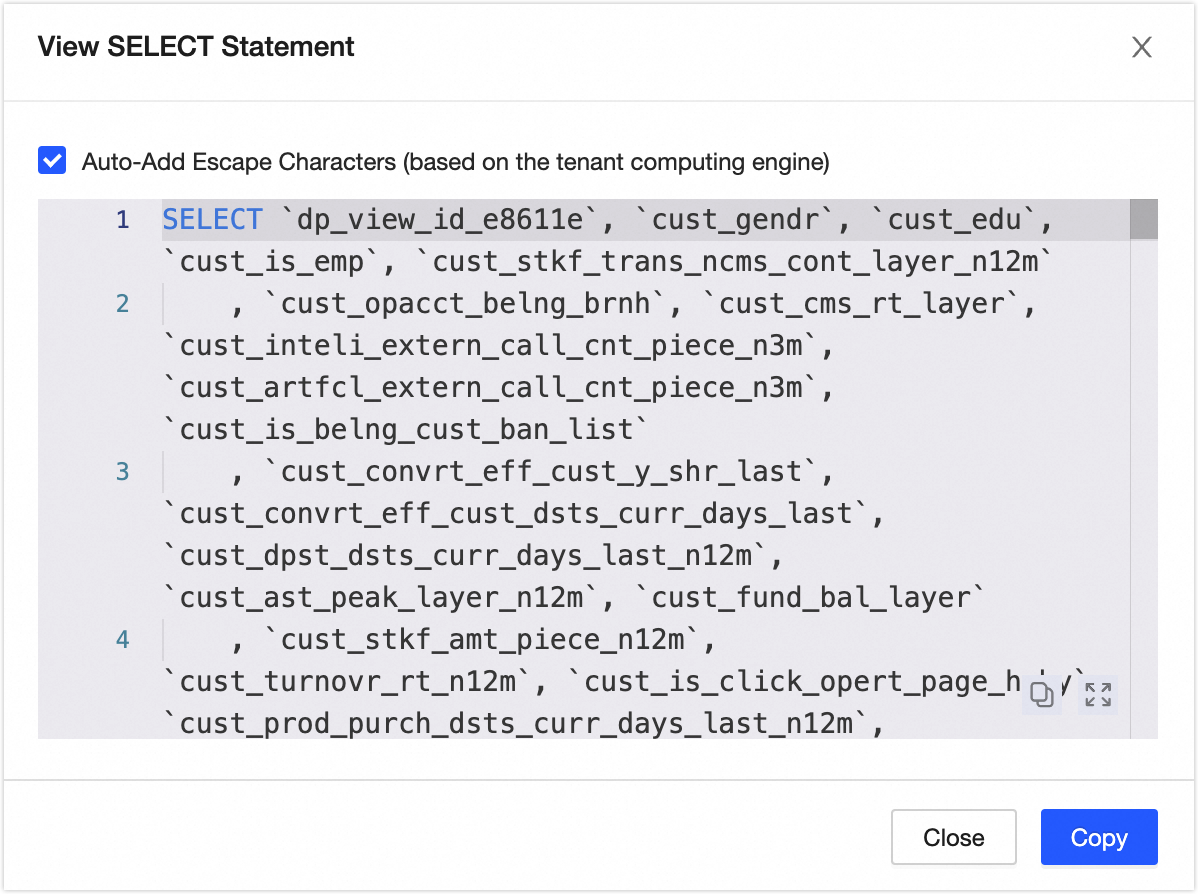
View DDL Statement: Click to view the DDL statement corresponding to the current data table in your tenant's compute engine. You can also select a Data Source Type and click Generate DDL Statement. The system generates a DDL statement to create a table with the same structure in the specified data source type. If you select Automatically Add Escape Characters, the generated DDL statement includes the appropriate escape characters for the selected source type. This helps prevent issues caused by misinterpreting system keywords. 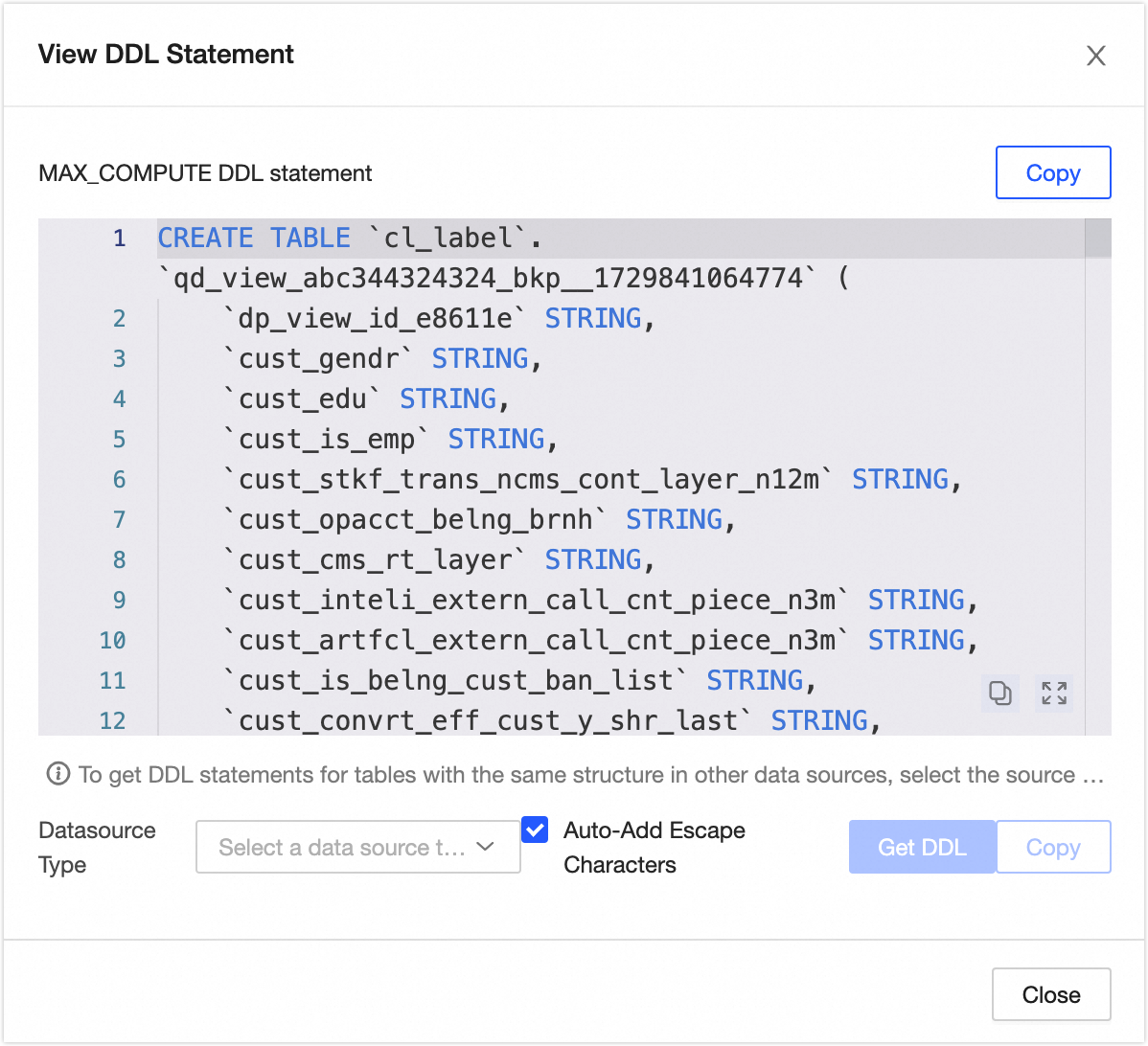
Edit Table: Click to open the Data Development > Table Management page, where you can edit the table's DDL information. For more information, see Create and edit an offline physical table. Export Fields: Export field information from the table to a CSV file. This helps developers or business users quickly analyze and use the data. View Transfer Records: View the 100 most recent owner transfer records for the current data table. View Permission List: View permission information for the data table. Refresh Metadata: If a data table was not created in Dataphin, or if a newly created table does not appear in search results due to metadata ingestion delays, you can click Refresh Metadata. This action fetches the latest metadata and syncs it into the Dataphin system.
Note Tables from the analysis platform do not support the Analyze, Apply for Permissions, Report Quality Issue, Edit Table, View Transfer Records, or View Permission List actions. |
② Details | Displays table, field, and partition information. Table Details: Displays the properties of the table, including its business segment, subject domain, project, highest confidentiality level (requires the Data Security module), and whether it is a partitioned table, a manually created table on the analysis platform, a lakehouse table, its lakehouse format, table storage mode, storage type, storage format, storage size, lifecycle, and location. Project: The project to which the table belongs. You can click the project name to go to the project's asset details page. Highest Confidentiality Level: The highest sensitivity level among the table's fields. This helps you quickly understand the data's sensitivity. The data classification levels range from L1 (Public) to L4 (Top Secret), with support for custom levels. Table Storage Mode: If the data table is a lakehouse table in Hudi format, this information can be collected from the table's compute source. Storage Type: The storage type of the table, which can be an internal table or an external table. Storage Size: The actual storage size of the table, updated on a T+1 basis. Lifecycle: The retention period of the table, in days. Location: For external tables from MaxCompute compute sources, this field shows the storage path, for example: hdfs://node01.exp5:8020/user/hive/warehouse.
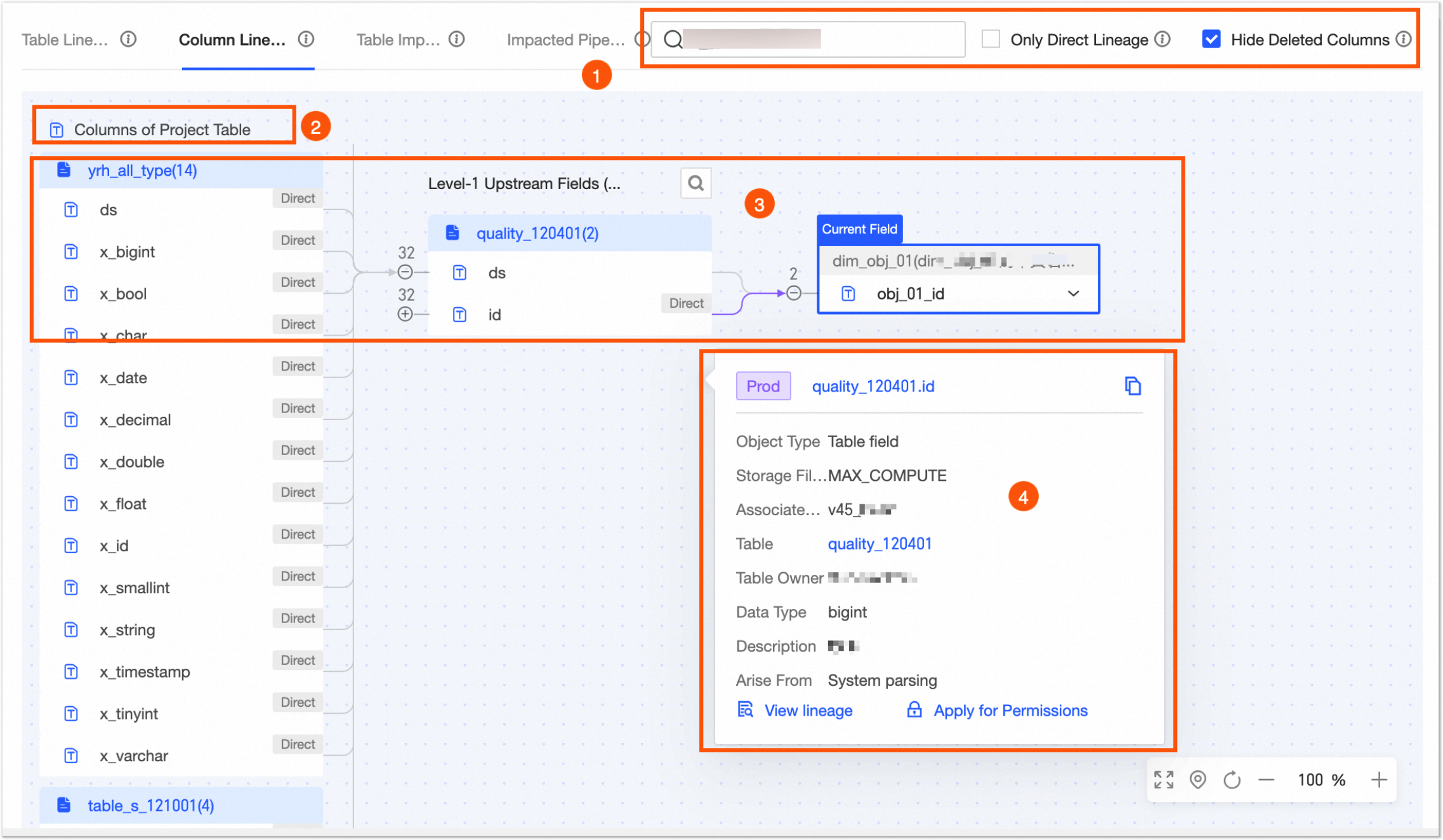
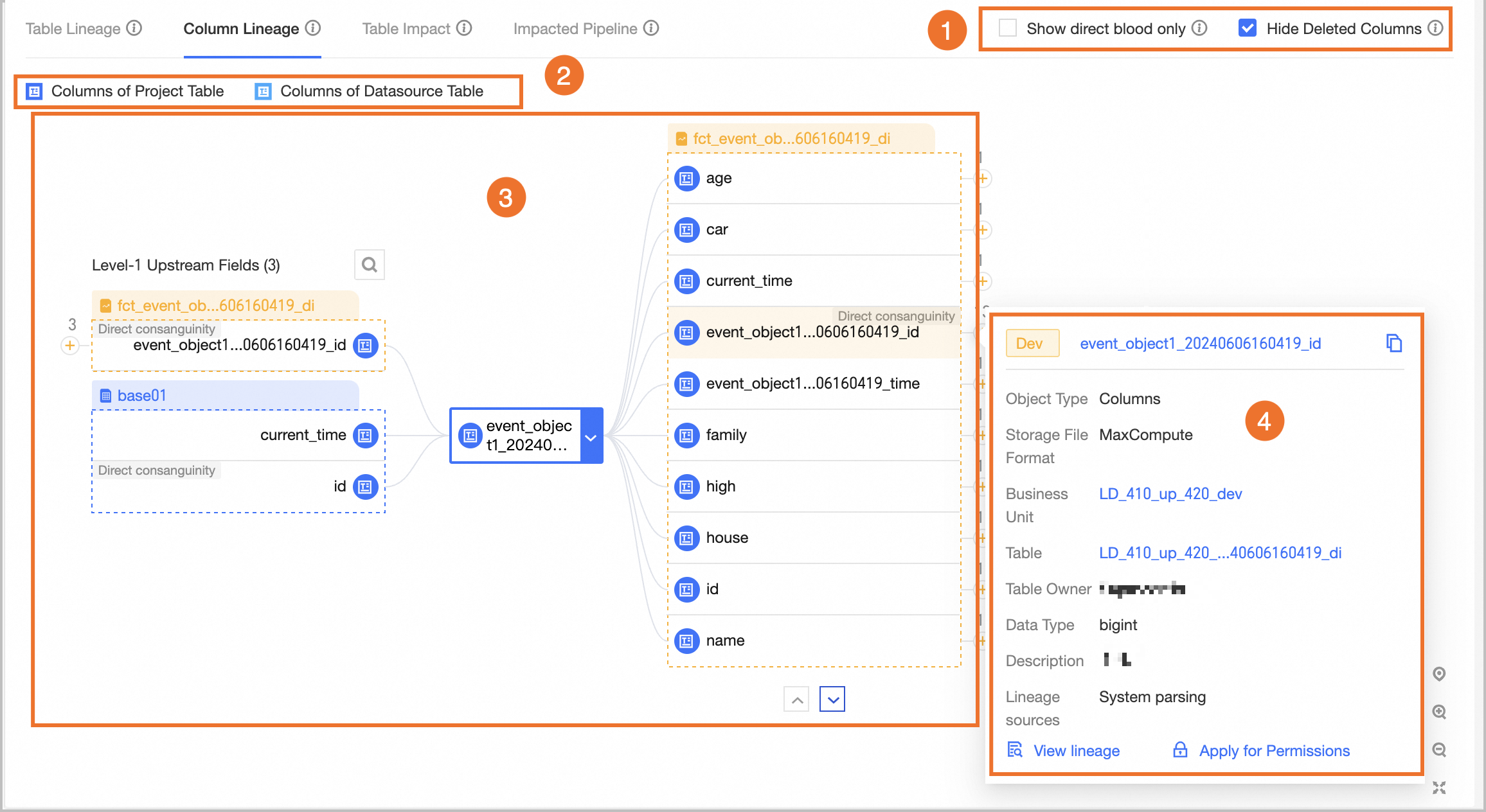
Field Information: Includes the field name, description, data type, associated standard (requires the data standards module), sample data (displayed only if the data sampling feature is enabled), data category (requires the Data Security module), data classification (requires the Data Security module), and popularity information. You can also search for, filter, and view the data lineage of fields. View Lineage: In the Actions column, click the lineage  icon to view the field-level lineage centered on the specified field. icon to view the field-level lineage centered on the specified field. Search and Filter: You can search for fields by name or description. You can also filter fields by data category and data classification if the Data Security module is activated.
Partition Information: Displays the partition information of the data table. Multi-level partitions are displayed as a combination of all partition levels, separated by forward slashes (/). For example: ds=20221001/pt1=a/pt2=b.
Note If the compute engine is MaxCompute and the table is a lakehouse table in Delta table format, the record count is not displayed. Partition record counts and storage size values are for reference only.
|
③ Lineage & Impact | |
④ Quality Overview | If you have activated the data quality feature, this section displays a validation rule overview and a list of quality monitoring rules for the current data table. Click View Report Details or View Rule Details to open the corresponding page in the data quality module.
Note The Quality Overview tab is not available for tables from the analysis platform. |
⑤ Data Profiling | If you have activated the data quality feature, you can configure a data profiling task for the table to quickly understand its data profile and assess its usability and potential risks in advance. To enable automatic profiling, go to Governance > Metadata Center > Profiling and Analysis and configure the relevant settings. For more information, see Create a data profiling task. |
⑥ Data Preview | If sample data is available, it is displayed by default. Otherwise, a data preview is automatically triggered. You can also manually query the latest data. Sample Data: This is displayed when both data sampling and the data preview setting are enabled. The query returns sample data only for fields that you have column-level permissions for and that do not require masking. The sample data for each field is stored and sorted independently, so the integrity of any single row is not guaranteed. Data Preview: If you have permission to query the table's data, you can use the data preview feature. It queries only the fields for which you have SELECT permissions (including field-level and row-level permissions) and displays up to the first 50 rows. To apply for permissions, see Apply for, renew, and release table permissions.
You can search, filter, view single-row details, auto-fit column widths, and pivot rows and columns. You can also click the sort icon next to a field to apply No Sort, Ascending, or Descending order. Double-click a field value to copy it. |
⑦ Output Information | Output tasks include data-writing tasks for the object, tasks where this table is an output based on automatic data lineage parsing or custom configuration, and tasks where the node output name matches the project_name.table_name format. The output task list updates in near real time. Output details update on a T+1 basis. 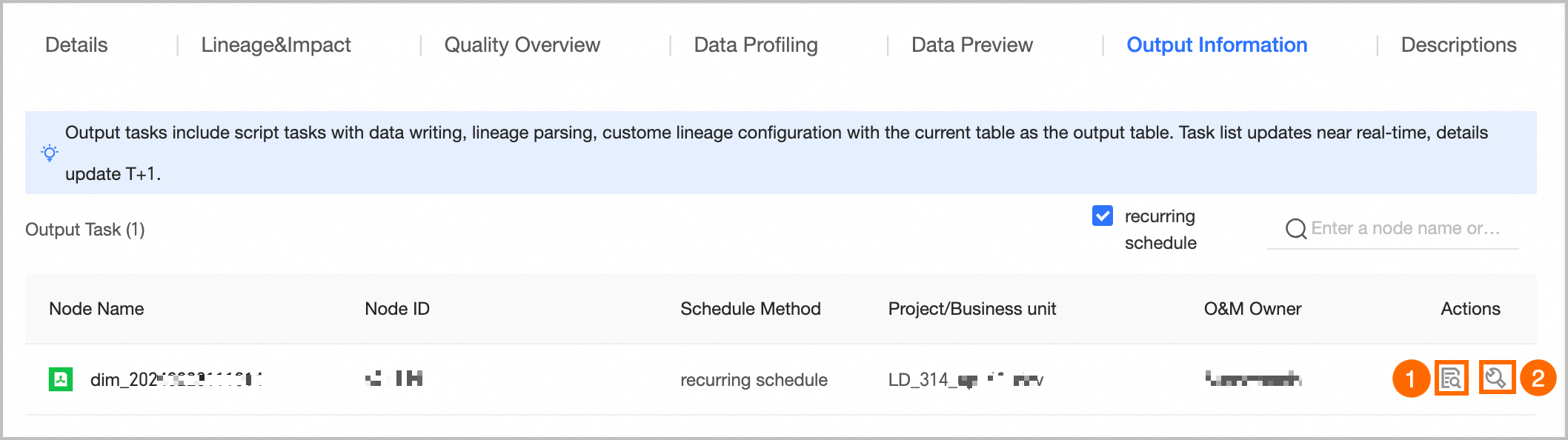
① View Output Details: You can view output details only for scheduled tasks. For more information, see Output details. ② Go to O&M: Click Go to O&M to open the task list page in the O&M Center, where the current task is automatically filtered for you to view more information.
|
⑧ Instructions | You can add instructions for a data table to provide reference information for data viewers and consumers. Click Add Instructions, enter a title and content, and then save the instructions.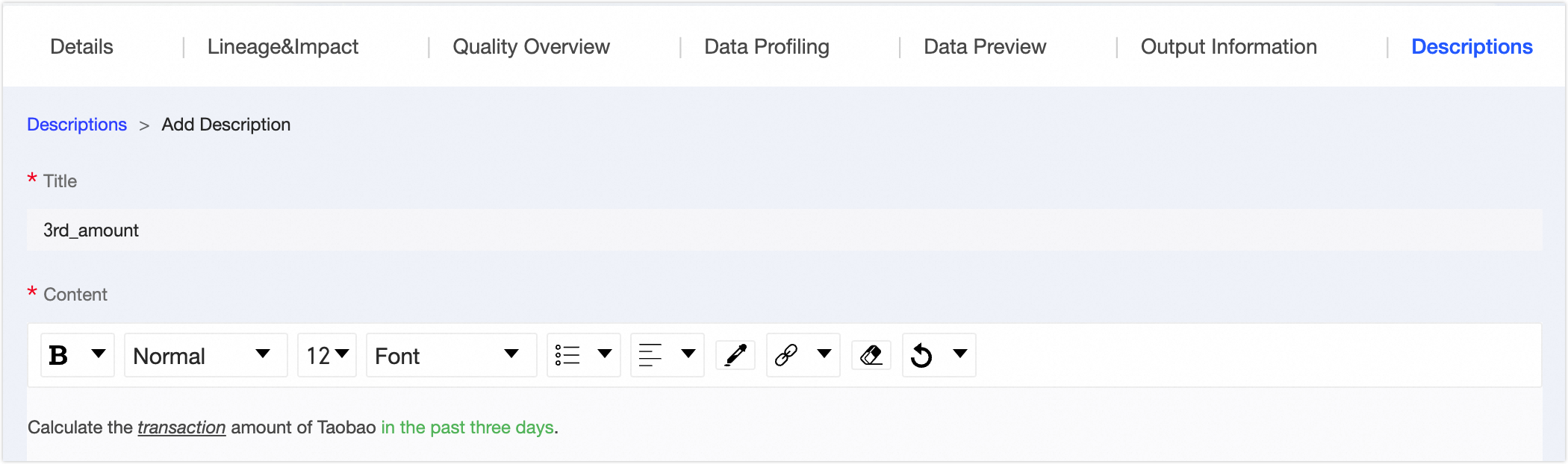 |
⑨ Asset Information | Displays detailed information about the physical table, including Basic Information, Change Information, and Usage Information. Basic Information: Includes the table's environment, type, creation time, creator, owner, and output tasks. Owner: The owner of the current table. You can transfer ownership of the table to another user. In the Transfer Owner dialog box, you can choose whether to simultaneously transfer ownership of the development and production environment tables. After you select an Assignee and click OK, the transfer takes effect immediately. Notify the new owner after the transfer. You can view transfer information on the transfer records page. For more information, see View Transfer Records.
Note Super administrators can transfer ownership of all table types. Table owners can transfer ownership of the tables they own. Project administrators can transfer ownership of physical tables in the projects they manage.
Output Tasks: You can view the output tasks for the current table. This includes data-writing tasks for the object, tasks where the table is an output based on data lineage parsing or configuration, and tasks where the node output name is project_name.table_name. Click the name of an output task to go to the O&M details page for that task.
Note You can view output details only for scheduled tasks.
Change Information: Includes Data Change, Last Accessed, and DDL Change. Data Change: Dataphin collects the time of the table's most recent content change (DML operation) from the compute engine. This information is updated in near real time. Last Accessed: Dataphin parses SQL to capture the most recent SELECT time (DQL operation). Access from external systems is not counted. Updates in real time. DDL Change: Dataphin parses SQL to capture the most recent table structure change time (DDL operation). Changes from external systems are not counted. Updates in real time.
Usage Information: Includes Favorites, Page Views, and Access Count. Favorites: The number of users who have favorited the current table. Updates in real time. Page Views: The number of page views (PV) for the current data table. The count increases by one each time the page is refreshed. Updates in real time. Access Count: Dataphin logs an access each time it parses SQL and detects a SELECT operation on the table within a Dataphin task. This value is updated on a T+1 basis and shows the total access count over the last 30 days.
|
 icon in the Actions column to open the object details page.
icon in the Actions column to open the object details page.