Configure the Data Lake Formation Output Component
The Data Lake Formation output component writes data to a Data Lake Formation data source. When you sync data from other data sources to a Data Lake Formation data source, you must configure the Data Lake Formation output component after you configure the source data. This topic describes how to configure the Data Lake Formation output component.
Prerequisites
You have created a Data Lake Formation data source. For more information, see Create a Data Lake Formation Data Source.
The account used to configure the Data Lake Formation output component must have write-through permission on the data source. If the account does not have this permission, request it. For more information, see Request, Renew, or Release Data Source Permissions.
Procedure
In the top menu bar on the Dataphin homepage, choose Develop > Data Integration.
In the top menu bar on the Integration page, select a Project. In Dev-Prod mode, also select an environment.
In the left navigation pane, click Offline Integration. In the Offline Integration list, click the offline pipeline that you want to develop to open its configuration page.
In the upper-right corner of the page, click Component Library to open the Component Library panel.
In the navigation pane on the left of the Component Library panel, click Output. In the list of output components on the right, find the Data Lake Formation component and drag it onto the canvas.
Click and drag the
 icon of the upstream component to connect it to the Data Lake Formation output component.
icon of the upstream component to connect it to the Data Lake Formation output component.Click the
 icon in the Data Lake Formation output component card to open the Data Lake Formation Output Configuration dialog box.
icon in the Data Lake Formation output component card to open the Data Lake Formation Output Configuration dialog box.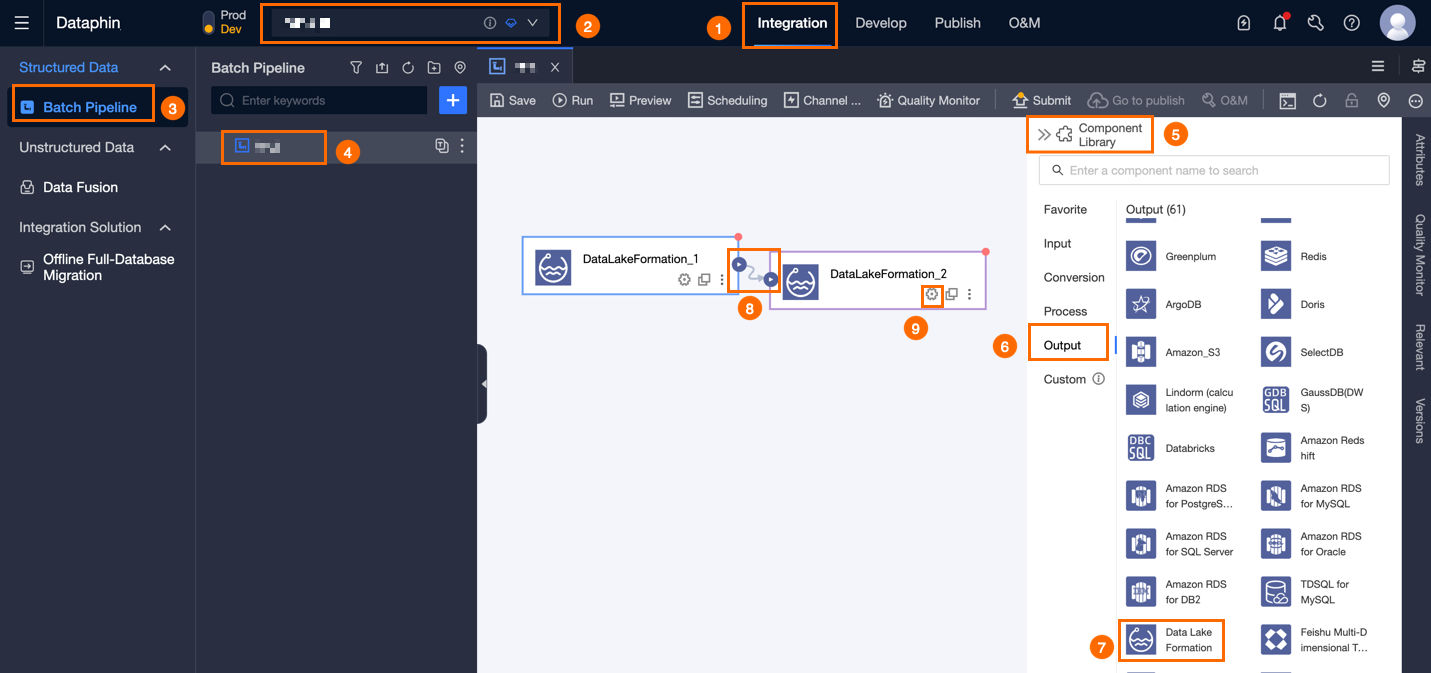
In the Data Lake Formation Output Configuration dialog box, configure the following parameters.
Parameter
Description
Basic Settings
Step Name
The name of the Data Lake Formation output component. Dataphin generates a step name automatically. You can change it based on your business scenario. Naming rules:
Use only Chinese characters, letters, underscores (_), and digits.
Keep the name no longer than 64 characters.
Datasource
The drop-down list shows all Data Lake Formation data sources. It includes data sources for which you have write-through permission and those for which you do not. Click the
 icon to copy the current data source name.
icon to copy the current data source name.If you do not have write-through permission on a data source, click Request next to the data source to request permission. For more information, see Request Data Source Permission.
If you do not have a Data Lake Formation data source, click the
 icon to create one. For more information, see Create a Data Lake Formation Data Source.
icon to create one. For more information, see Create a Data Lake Formation Data Source.
Table
Select the target table for output data. Enter a keyword to search for tables, or enter the exact table name and click Exact Search. After you select a table, the system checks its status automatically. Click the
 icon to copy the selected table name.
icon to copy the selected table name.Partition
If the selected target table is a partitioned table, enter partition information, such as
state_date='20190101'. You can also use parameters to enable daily incremental writes, such asstate_date=${bizdate}.Loading Policy
Select the policy for writing data to the target table. Loading Policy options:
Append Data: Write data directly to the target table or partition.
Overwrite Data: Overwrite data in the target table or partition.
Field Mapping
Input Fields
Lists input fields from the upstream component.
Output Fields
Lists output fields. You can perform the following actions:
Field Management: Click Field Management to select output fields.
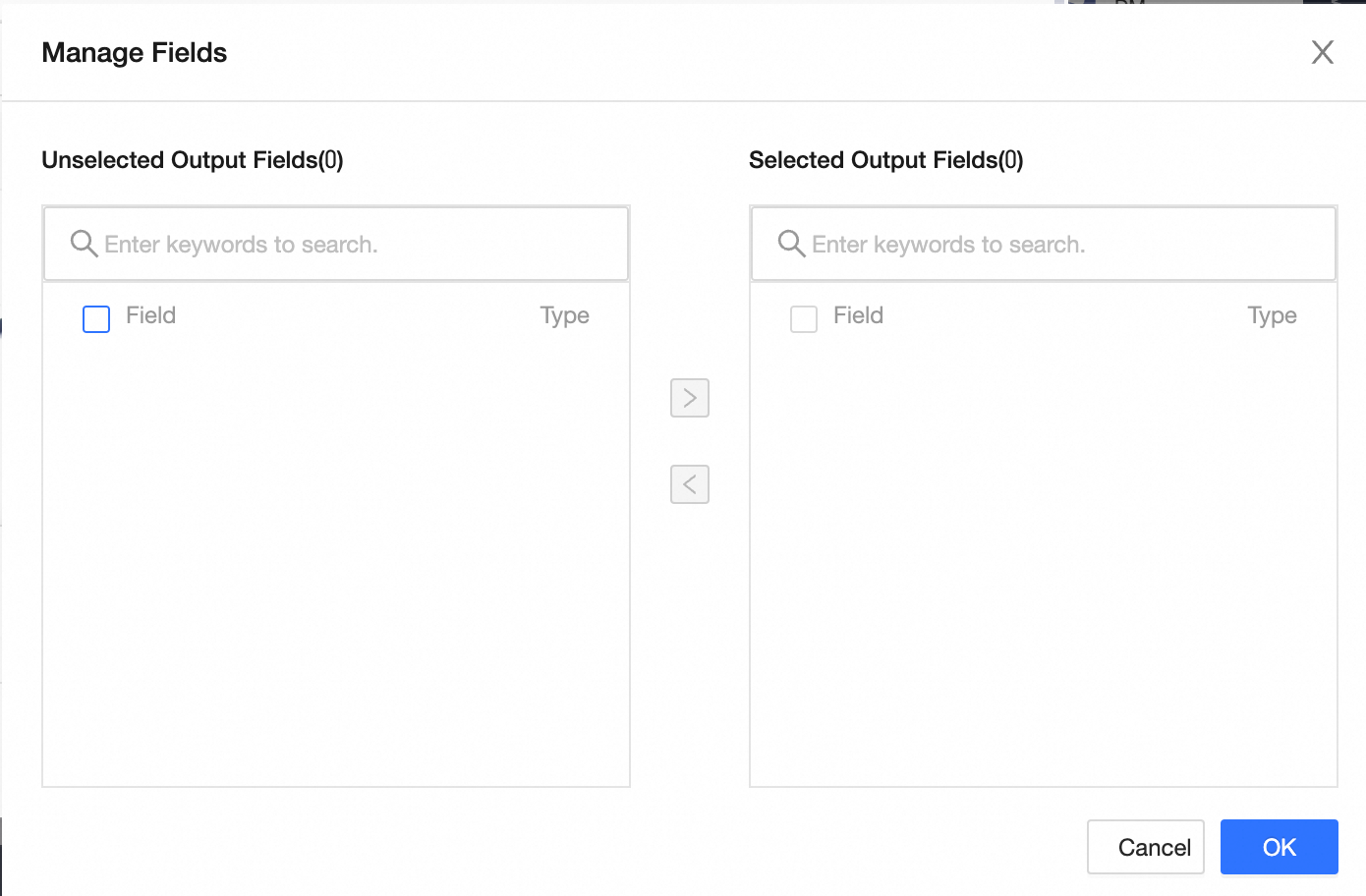
Click the
 icon to move Selected Input Fields to Unselected Input Fields.
icon to move Selected Input Fields to Unselected Input Fields.Click the
 icon to move Unselected Input Fields to Selected Input Fields.
icon to move Unselected Input Fields to Selected Input Fields.
Batch Add: Click Batch Add to configure output fields in JSON, TEXT, or DDL format.
You can configure in batch in JSON format, for example:
// Example: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]Notenamespecifies the name of the imported field, andtypespecifies the data type of the field after import. For example,"name":"user_id","type":"String"means to import the field named user_id and set its data type to String.TEXT format example:
// Example: user_id,String user_name,StringThe row delimiter separates each field. By default, it is a line feed (\n). You can also use a semicolon (;) or a period (.).
The column delimiter separates the field name and field type. By default, it is a comma (,).
DDL format example:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
Create Output Field: Click + Create Output Field. Enter a value for Column and select a value for Type. Click the
 icon to save the configuration for the current row.
icon to save the configuration for the current row.
Mapping
Manually map fields between upstream input fields and target table fields. Quick Mapping options include Row Mapping and Name Mapping.
Name Mapping: Map fields with identical names.
Row Mapping: Map fields by position when field names differ between the source and target tables. Only fields in the same row are mapped.
Click Confirm to complete the configuration of the Data Lake Formation output component.