Create a TDSQL for MySQL data source
Create a TDSQL for MySQL data source to enable Dataphin to read data from or write data to TDSQL for MySQL. This topic describes how to create a TDSQL for MySQL data source.
Permission requirements
Only super administrators, data source administrators, domain architects, project administrators, and custom global roles with the Create Data Source permission can create data sources.
Procedure
On the Dataphin home page, choose Management Center > Datasource Management from the top menu bar.
On the Datasource page, click +Create Data Source.
On the Create Data Source page, go to the Relational Database section and select TDSQL for MySQL.
If you have recently used TDSQL for MySQL, you can also select it from the Recently Used section. You can also enter keywords in the search box to quickly find TDSQL for MySQL.
On the Create TDSQL for MySQL Data Source page, configure the connection parameters for the data source.
Configure the basic information for the data source.
Parameter
Description
Datasource Name
Enter a name for the data source. Follow these naming conventions:
The name can contain only Chinese characters, letters, digits, underscores (_), and hyphens (-).
The name can be up to 64 characters long.
Datasource Code
After you configure the data source code, you can directly access Dataphin data source tables in Flink_SQL tasks or using the Dataphin Java Database Connectivity (JDBC) client. Use the format
datasource_code.table_nameordatasource_code.schema.table_namefor quick access. To automatically switch data sources based on the task execution environment, use the variable format${datasource_code}.tableor${datasource_code}.schema.table. For more information, see Develop Flink_SQL tasks.ImportantThe data source code cannot be modified after it is configured.
You can preview data on the object details page in the asset directory and asset checklist only after the data source code is configured.
In Flink SQL, only MySQL, Hologres, MaxCompute, Oracle, StarRocks, Hive, SelectDB, and GaussDB data warehouse service (DWS) data sources are currently supported.
Data Source Description
A brief description of the TDSQL for MySQL data source. The description cannot exceed 128 characters.
Data Source Configuration
Choose whether to distinguish between production and development data sources:
If your business data source distinguishes between production and development data sources, select Production + Development Data Source.
If your business data source does not distinguish between them, select Production Data Source.
Tag
You can categorize data sources with tags. For more information about how to create tags, see Manage data source tags.
Configure the connection parameters between the data source and Dataphin.
If you set Data Source Configuration to Production + Development Data Source, configure the connection information for both. If you set it to Production Data Source, configure the connection information for the production data source only.
NoteTypically, the production and development data sources should be different to ensure environment isolation. This prevents the development data source from impacting the production data source. However, Dataphin also supports using the same data source for both environments if you configure them with identical parameter values.
For Configuration Method, select JDBC URL or Host. The default is JDBC URL.
JDBC URL configuration
Parameter
Description
JDBC URL
The format of the JDBC URL is
jdbc:mysql://host:port/dbname.NoteThe default port for TDSQL for MySQL data sources is 3306.
Username, Password
The Username and Password for the database.
Type
Supports Directly Connectable Database, Alibaba Cloud Database, and Self-managed Database on ECS (VPC). Select and configure the type based on your database and business needs.
Directly Connectable Database: Connect to the database directly through the default or a registered scheduling cluster. This is suitable for the following scenarios: ① databases on the public network, and ② databases in the same network environment as the registered scheduling cluster. To add an IP address to a whitelist, add the public egress IP address of the Dataphin default scheduling cluster: 47.102.192.174.
Alibaba Cloud Database: A database purchased on Alibaba Cloud. Supports access through a VPC Proxy or Direct Connection.
VPC Proxy: If you use an Alibaba Cloud database in a virtual private cloud (VPC), add 100.104.0.0/16 to the IP address whitelist for the connection.
Region: The region where the database is located. Only databases in the same region as the Dataphin instance are supported. For example, if your Dataphin instance is in the China (Shanghai) region, you can only select the China (Shanghai) region.
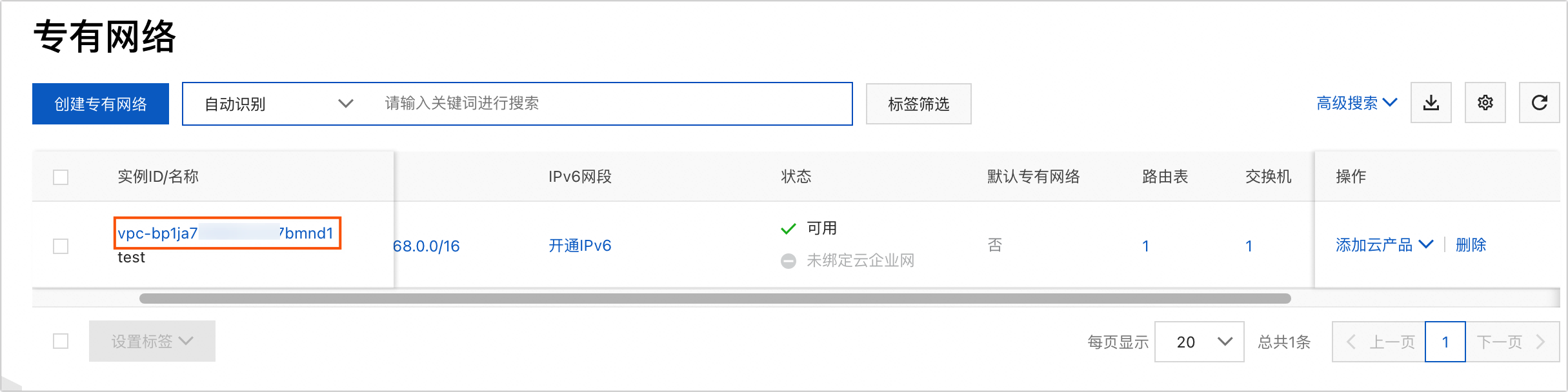
VPC ID: Enter the ID of the VPC where the database is located. You can log on to the VPC console to find it. See the following figure:
VPC instance ID: Enter the VPC instance ID of the database, which is
VpcCloudInstanceId. You can get it by calling the DescribeDrdsInstance API. For more information, see DescribeDrdsInstance.
Direct Connection: Connect to the database directly through the default or a registered scheduling cluster. To add an IP address to a whitelist, add the public egress IP address of the Dataphin default scheduling cluster: 47.102.192.174.
Self-managed Database on ECS (VPC): If you use an Alibaba Cloud database in a VPC, add 100.104.0.0/16 to the IP address whitelist for the connection.
Region: The region where the database is located. Only databases in the same region as the Dataphin instance are supported. For example, if your Dataphin instance is in the China (Shanghai) region, you can only select the China (Shanghai) region.
VPC ID: Enter the ID of the VPC where the ECS instance is located. You can log on to the VPC console to find it. See the following figure:
ECS ID: Enter the ID of the ECS server where the database is deployed. You can log on to the ECS console to find it. See the following figure:

Host configuration
Host configuration
Parameter
Description
Server Address
Enter the IP address and port number of the server.
Click +Add to add multiple IP addresses and port numbers. Click the
 icon to delete extra entries. You must keep at least one entry.
icon to delete extra entries. You must keep at least one entry.dbname
Enter the database name.
Parameter configuration
Parameter
Description
Parameter
Parameter name: You can only select an existing parameter name.
Parameter value: This is required if you select a parameter name. The value can contain only letters, digits, periods (.), underscores (_), and hyphens (-). The value can be up to 256 characters long.
NoteClick +Add Parameter to add multiple parameters. Click the
icon to delete extra parameters. You can add up to 30 parameters.Username, Password
The username and password to log on to the TDSQL for MySQL instance.
NoteIf you select Host as the configuration method and then switch to the JDBC URL method, the system combines the server IP address and port number to populate the JDBC URL.
Configure advanced settings for the data source.
Parameter
Description
connectTimeout
The connection timeout period for the database, in milliseconds. The default is 900,000 ms (15 minutes).
NoteIf you specify `connectTimeout` in the JDBC URL, that value is used.
For data sources created before Dataphin V3.11, the default `connectTimeout` is
-1, which means no timeout limit.
socketTimeout
The socket timeout period for the database, in milliseconds. The default is 1,800,000 ms (30 minutes).
NoteIf you specify `socketTimeout` in the JDBC URL, that value is used.
For data sources created before Dataphin V3.11, the default `socketTimeout` is
-1, which means no timeout limit.
Connection Retries
If the database connection times out, the system automatically retries the connection up to the specified number of times. If the connection still fails after the maximum number of retries, the connection attempt fails.
NoteThe default is 1 retry. You can configure a value from 0 to 10.
The number of connection retries applies by default to offline integration tasks and global quality checks. The asset quality module must be enabled for global quality checks. You can configure task-level retry counts separately in offline integration tasks.
NoteThe following precedence rules apply to duplicate parameters:
If a parameter is defined in the JDBC URL, Advanced Settings, and Host Configuration, the value in the JDBC URL takes precedence.
If a parameter is defined in both the JDBC URL and Advanced Settings, the value in the JDBC URL takes precedence.
If a parameter is defined in both the Advanced Settings and Host Configuration, the value in the Advanced Settings takes precedence.
Select a Default Resource Group. This resource group is used to run tasks related to the data source, such as database SQL tasks, offline full database migration, and data previews.
Click Test Connection or click OK to save the configuration and create the TDSQL for MySQL data source.
When you click Test Connection, the system tests the connectivity to Dataphin. If you click OK directly, the system automatically tests the connection for all selected clusters. You can create the data source even if the connection test fails for all selected clusters.
Test Connection tests the connection for the Public Scheduling Cluster or Registered Scheduling Clusters that have been registered in Dataphin and are in normal use. The Public Scheduling Cluster is selected by default and cannot be deselected. If there are no resource groups under a Registered Scheduling Cluster, connection testing is not supported. You need to create a resource group first before testing the connection.
The selected clusters are only used to test network connectivity with the current data source and are not used for running related tasks later.
The test connection usually takes less than 2 minutes. If it times out, you can click the
 icon to view the specific reason and retry.
icon to view the specific reason and retry.Regardless of whether the test result is Connection Failed, Connection Successful, or Succeeded With Warning, the system will record the generation time of the final result.
NoteOnly the test results for the Public Scheduling Cluster include three connection statuses: Succeeded With Warning, Connection Successful, and Connection Failed. The test results for Registered Scheduling Clusters in Dataphin only include two connection statuses: Connection Successful and Connection Failed.
When the test result is Connection Failed, you can click the
icon to view the specific failure reason.When the test result is Succeeded With Warning, it means that the application cluster connection is successful but the scheduling cluster connection failed. The current data source cannot be used for data development and integration. You can click the
icon to view the log information.
ImportantIf the connection test fails, you can troubleshoot the issue. For more information, see Network connectivity solutions.
If the connection test returns a
VPC_GRANT_ACCESS_API_ERRORerror, see Solution for the VPC_GRANT_ACCESS_API_ERROR error.