Use the TDSQL for PostgreSQL output component to write data to a TDSQL for PostgreSQL data source. After you configure the source component, configure this output component as the destination.
Prerequisites
-
You have created a TDSQL for PostgreSQL data source. For more information, see .
-
You have the sync write permission for the data source. If you do not have this permission, apply for it. For more information, see Apply for, renew, and revoke data source permissions.
Procedure
-
In the top navigation bar of the Dataphin homepage, choose Develop > Data Integration.
-
In the top navigation bar of the integration page, select a project. If you are using Dev-Prod mode, you must also select an environment.
-
In the left-side navigation pane, click batch integration. In the batch integration list, click the desired batch pipeline to open its configuration page.
-
In the upper-right corner of the page, click Component Library to open the Component Library panel.
-
In the left-side navigation pane of the Component Library panel, select Output. In the output component list on the right, find TDSQL for PostgreSQL and drag it onto the canvas.
-
Click and drag the
 icon on the source component to connect it to the TDSQL for PostgreSQL output component.
icon on the source component to connect it to the TDSQL for PostgreSQL output component. -
Click the
 icon on the TDSQL for PostgreSQL output component to open the TDSQL for PostgreSQL Output Configuration dialog box.
icon on the TDSQL for PostgreSQL output component to open the TDSQL for PostgreSQL Output Configuration dialog box.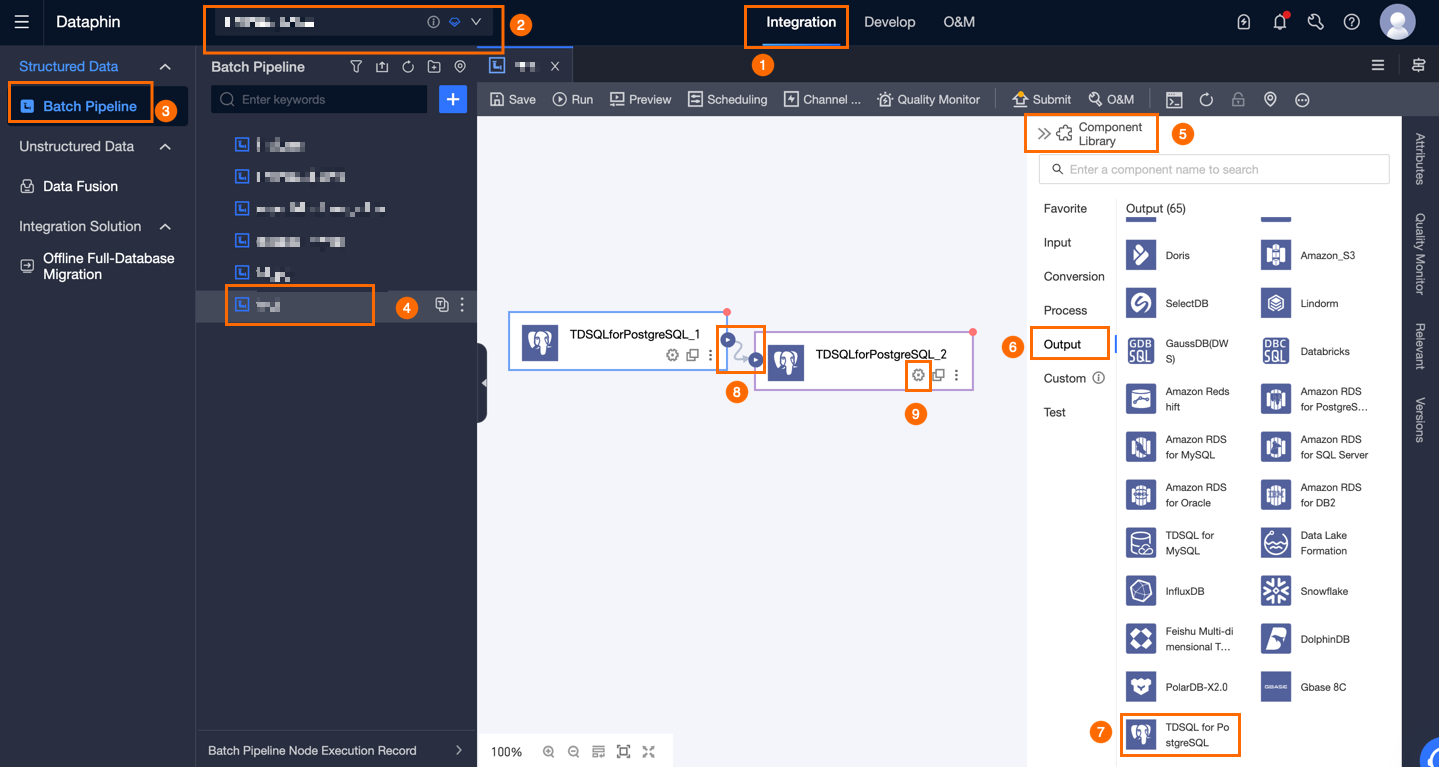
-
In the TDSQL for PostgreSQL Output Configuration dialog box, configure the following parameters.
Parameter
Description
Basic settings
Step Name
The name of the output component. Dataphin generates a default name, which you can customize. The name must follow these rules:
-
Can contain only Chinese characters, letters, underscores (_), and numbers.
-
Must be no more than 64 characters long.
Data Source
Select a TDSQL for PostgreSQL data source from the drop-down list. The list shows all available data sources of this type, regardless of your sync write permission. Click the
 icon to copy the selected data source name.
icon to copy the selected data source name.-
If you do not have the sync write permission for a data source, click Apply to request it. For more information, see Apply for data source permissions.
-
If no TDSQL for PostgreSQL data source is available, click the
 Create icon to create one. For more information, see .
Create icon to create one. For more information, see .
Schema (Optional)
Select the schema where the target table is located. You can select tables from different schemas. If you do not specify a schema, the system uses the default schema configured for the data source.
Table
Select the target table. You can search by a table name keyword or enter the full name and click Exact Match. After you select a table, the system automatically checks its status. Click the
 icon to copy the name of the selected table.
icon to copy the name of the selected table.If the target table does not exist in the TDSQL for PostgreSQL data source, you can use the one-click DDL feature to quickly create it. Follow these steps:
-
Click One-Click DDL. Dataphin automatically generates a DDL statement to create the target table. By default, the target table name matches the source table name, and column types are converted from Dataphin field types.
-
Modify the SQL script as needed, and then click Create. After the table is created, Dataphin automatically uses it as the target table.
Note-
If a table with the same name exists in the development environment, Dataphin reports an error when you click New.
-
You can also manually enter a table name for integration if no matches are found.
-
Policy for missing production table
Specifies what to do when the production table does not exist. Options: Do not process or Automatically create. The default is Automatically create.
-
Do not process: If the target table does not exist, a notification appears upon submission, but you can still publish the task. You must manually create the target table in the production environment before running the task.
-
Automatically create: Click Edit DDL Statement. The DDL for the selected table is pre-filled, and you can adjust it. In the DDL statement, use the
${table_name}placeholder for the table name. Only this placeholder is supported. At runtime, it is replaced with the actual table name.If the target table does not exist, Dataphin creates it from the DDL statement. If table creation fails, the pre-publish check fails. Fix the DDL statement based on the error message and publish again. If the target table already exists, Dataphin skips creation.
NoteThis parameter is available only in projects that use the Dev-Prod mode.
Load policy
Select the write policy for the target table. Options:
-
Append data (insert into): If a primary key or constraint conflict occurs, the system reports a dirty data error.
-
Update on primary key conflict (on conflict do update set): If a primary key or constraint conflict occurs, the system updates the mapped fields of the existing record.
Synchronous write
The primary key update operation is not atomic. If your source data contains duplicate primary keys, enable synchronous write to prevent data inconsistencies. Otherwise, Dataphin uses faster parallel writes.
NoteYou can configure this parameter only when the load policy is Update on primary key conflict.
Batch write size (Optional)
The amount of data written per batch. Works together with Number of rows per batch. A write operation starts when either threshold is reached. Default: 32 MB.
Number of rows per batch (Optional)
The number of rows written per batch. Default: 2,048. Dataphin uses a batch write strategy governed by Number of rows per batch and batch write size.
-
A write operation starts when either this limit or the batch write size is reached.
-
To optimize performance, adjust the number of rows per batch based on the average size of each record. For example, if each record is about 1 KB and the batch write size is set to 16 MB, set the number of rows per batch to a value greater than 16,384 (16 MB / 1 KB), such as 20,000. With this configuration, the system triggers a write operation each time the accumulated data reaches 16 MB.
Pre-SQL script (Optional)
An SQL script to run on the database before the data import starts.
For example, to maintain continuous service availability, you could use a pre-SQL script to first create a temporary table (
Target_A) and write data to it. Then, in the post-SQL script, rename the live table (Service_B) to a backup (Temp_C), renameTarget_AtoService_B, and finally, dropTemp_C.Post-SQL script (Optional)
An SQL script to run on the database after the data import completes.
Field mapping
Input field
The input fields from the upstream component.
Output field
The output fields. You can perform the following actions:
-
Manage Fields: Click Manage Fields to select which fields to include in the output.
-
Click the
icon to move items from Selected input fields to Unselected input fields. -
Click the
icon to move the unselected input fields to the selected input fields.
-
-
Batch Add: Click Batch Add to add multiple fields at once using JSON, TEXT, or DDL format.
-
Configure in batches using the JSON format. For example:
// Example: [{ "name": "user_id", "type": "String" }, { "name": "user_name", "type": "String" }]Notenamespecifies the name of the field to import.typespecifies the data type for the imported field. For example,"name":"user_id","type":"String"imports the field nameduser_idand sets its data type toString. -
Configure in batches using the TEXT format. For example:
// Example: user_id,String user_name,String-
The row delimiter separates the information for each field. The default delimiter is a newline character (\n). Semicolons (;) and periods (.) are also supported.
-
The column delimiter separates the field name from the field type. The default delimiter is a comma (,).
-
-
Configure in batches using the DDL format. For example:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
-
-
New output field: Click + New Output Field, then enter a Field name and select a Type for the new row. Click the
icon to save.
Mapping
Map input fields to output fields manually, or use Quick Mapping, which includes Map by position and Map by name.
-
Map by name: Automatically maps input and output fields with the same name.
-
Map by position: Maps fields based on their order (position) in the list. The first input field is mapped to the first output field, the second to the second, and so on. This is useful when field names do not match but their order does.
-
-
Click Confirm to complete the property configuration of the TDSQL for PostgreSQL output component.
 icon to copy the name of the selected table.
icon to copy the name of the selected table.
 icon to save.
icon to save.