DataWorks is a one-stop platform for big data development and governance. It provides a comprehensive suite of tools for Data Integration, Data Studio, Data modeling, Data Analysis, Data Quality, DataService Studio, Data Map, and Open Platform. This unified environment enables end-to-end data processing and helps you build an enterprise-grade data platform. This topic describes the core features of DataWorks.
Data Integration: Cross-domain aggregation
Data Integration in DataWorks is a stable, efficient, and elastically scalable data synchronization platform. It provides fast, stable data movement and synchronization across a wide range of heterogeneous data sources, even in complex network environments.
Overview
DataWorks Data Integration supports batch synchronization, real-time synchronization, and integrated full and incremental synchronization.
For batch synchronization scenarios, you can configure a scheduling cycle for the synchronization tasks.
It supports data synchronization between more than 50 heterogeneous data sources, including relational databases, data warehouses, non-relational databases, file storage, and message queues.
It provides network solutions to connect to data sources in various complex network environments. You can establish network connectivity by using Data Integration regardless of whether your data sources are on the public cloud, in an IDC, or within a VPC.
It supports security controls and O&M monitoring for secure and controllable data synchronization.
Core technologies and architecture
Engine architecture: Data Integration uses a star-shaped engine architecture. After you connect a data source to Data Integration, it can form a synchronization link with any other supported data source. For a list of supported data sources, see Supported data sources and synchronization solutions.

Resource groups for Data Integration and network connectivity: Before you synchronize data, use an appropriate network connectivity solution to connect the data source to the resource group. Currently, Data Integration tasks can run only on serverless resource groups (recommended) and exclusive resource groups for Data Integration (legacy). For details, see Network connectivity solutions.
Use cases
Data Integration is suitable for various data transmission scenarios, such as ingesting data into data lakes and data warehouses, database and table sharding, real-time data archiving, and cross-cloud data flows.
Data Studio and Operation Center: Data processing
Data Studio in DataWorks is a development platform for data processing, and Operation Center is an intelligent operations and maintenance (O&M) platform. With these two modules, you can build and operate data development workflows on DataWorks in a standardized and efficient way.
Overview
The key features of Data Studio include:
Data Studio supports multiple compute engines, such as MaxCompute, E-MapReduce, CDH, Hologres, AnalyticDB, and ClickHouse. You can develop, test, deploy, and operate tasks for these engines from a single platform.
Its scheduling capabilities are proven by the complex scheduling tasks and business dependencies within Alibaba Group.
Data Studio provides isolated development and production environments. Together with features like version control, code review, smoke testing, deployment control, and operational auditing, it helps enterprises standardize data development.
Operation Center supports features such as data timeliness assurance, task diagnostics, impact analysis, automated O&M, and mobile-based O&M.
Core technologies and architecture
Efficient and standardized development workflow
 Note
NoteDataWorks provides workspaces in standard mode to isolate development and production environments. For more information about standard mode, see Differences between workspace modes.
Visual development interface: Build task workflows using drag-and-drop, and configure data development and scheduling in a unified interface.
Task monitoring and troubleshooting

Data modeling: Intelligent data modeling
Data modeling is an intelligent data modeling product developed in-house by DataWorks. It is built on the best practices from over a decade of data warehouse modeling at Alibaba. It includes four modules: Data Warehouse Planning, Data Standard, Dimensional Modeling, and Data Metrics. This module helps enterprises enhance their modeling and reverse modeling capabilities when building data platforms and data marts, and quickly construct data assets.
Overview
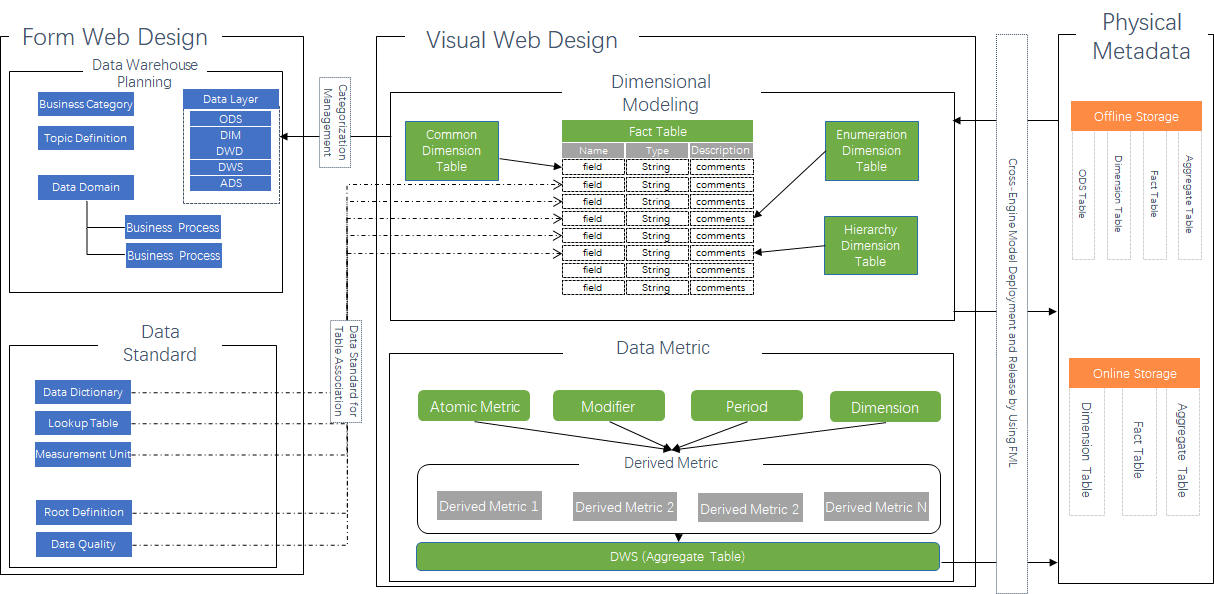
The intelligent Data modeling product includes four modules: Data Warehouse Planning, Data Standard, Dimensional Modeling, and Data Metrics.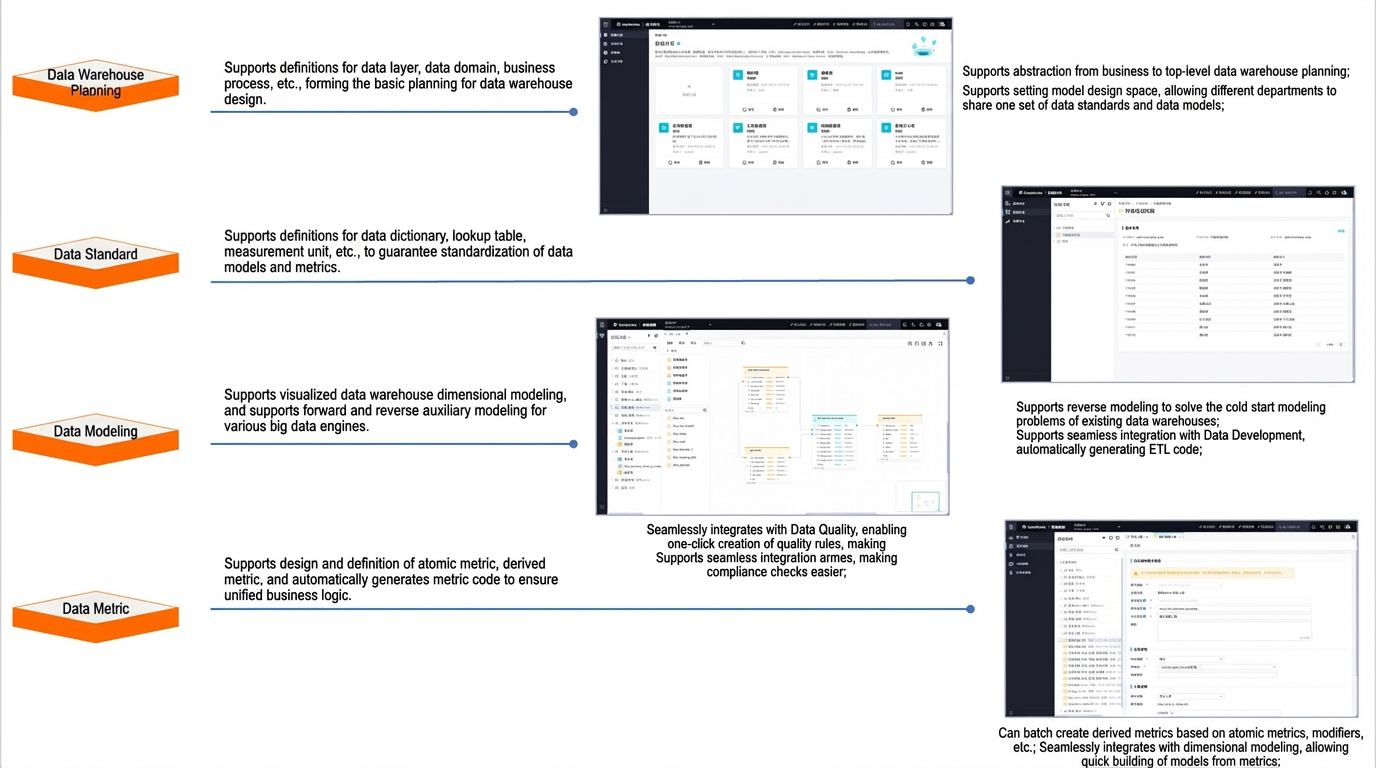
Data Warehouse Planning: Plan your data warehouse layers, data domains, and data marts. You can configure model design spaces, allowing different departments to share a unified set of data standards and data models.
Data Standard: Define field standards, standard codes, units of measurement, and naming dictionaries. You can also automatically generate data quality rules from standard codes to simplify compliance checks.
Dimensional Modeling: Use reverse modeling to solve the cold-start problem for existing data warehouses. It supports visual dimensional modeling for data warehouses. You can import models from Excel files or use FML, an SQL-like domain-specific language (DSL), to quickly build models. It seamlessly integrates with Data Studio to automatically generate ETL code.
Data Metrics: Define and build atomic metrics and derived metrics. This feature seamlessly integrates with Dimensional Modeling, allowing you to batch-create derived metrics based on atomic metrics and different dimensions.
Core technologies and architecture
Use cases
Data modeling helps enterprises build their own modeling capabilities and mine the value of their data assets. For example:
-
Standardize management of massive data
Larger enterprises have more complex data structures. How to manage and store data in a structured and orderly manner is a challenge that every large enterprise faces.
-
Break information barriers by interconnecting business data
If the data of each business or department in an enterprise is isolated from one another, the decision-makers cannot clearly or fully understand the data. How to break data silos between departments or business domains is a big challenge for business data management.
-
Integrate data standards to achieve unified and flexible data interconnection
Inconsistent descriptions of the same data result in duplicate data, incorrect calculation results, and difficulties in business data management. How to formulate a unified data standard without changing the original system architecture and realize flexible interconnection between upstream and downstream business is one of the core focuses of standardized management.
-
Maximize data value to maximize profit
Make the most of various types of enterprise data to maximize the data value to deliver a more efficient data service for enterprises.
Data Analysis: Ad hoc analysis
With the goal of empowering everyone to be a data analyst, Data Analysis provides users other than professional data developers, such as data analysts, product managers, and operations staff, with simple and efficient tools for data retrieval and analysis to improve their daily efficiency.
Overview
Data Analysis supports features such as uploading personal data, using public datasets, searching for and bookmarking tables, running online SQL queries, sharing SQL files, downloading query results, and viewing data on large screens using spreadsheets.
Use cases
Data Analysis is suitable for users other than professional data developers, such as data analysts, product managers, and operations staff, to perform efficient, large-scale, fluid, and secure data analysis.
Scale: Leverage the power of compute engines to efficiently analyze full-scale, massive datasets.
Flow: Perform online data analysis by fetching data from databases of different business systems. Data Analysis allows you to export data to MaxCompute tables or share query results with specific members and grant them permissions. This ensures data can flow between different systems and personnel.
Security: You can integrate all operations, including SQL queries and query result downloads, with security auditing.
Data Quality: End-to-end monitoring
The end-to-end Data Quality monitoring feature in DataWorks provides more than 30 preset monitoring templates at the table and field levels, as well as custom templates. Data Quality helps you immediately detect changes in source data and identify dirty data generated during the ETL (extract, transform, load) process. It automatically blocks problematic tasks to effectively prevent dirty data from propagating downstream.
ETL is the process of extracting, transforming, and loading data from a source to a destination.
Data Quality monitors datasets and supports data tables from various engines, including MaxCompute. When batch data changes, Data Quality verifies the data and blocks the production pipeline, preventing the spread of problematic data. It also manages historical verification results, allowing you to analyze and classify data quality. For more information, see Data Quality.
Data Quality helps you address the following issues:
Frequent database changes.
Frequent business changes.
Data definition issues.
Dirty data from business systems.
Quality issues caused by system interactions.
Issues caused by data correction.
Quality issues originating within the data warehouse itself.
Data Map: Unified management and lineage
The Data Map feature in DataWorks helps you manage data in a unified way and trace data lineage. Based on data search, Data Map provides tools such as table usage instructions, data categories, data lineage, and field lineage to help data consumers and owners better manage data and collaborate on development. Data Map allows you to view detailed metadata for tables from multiple perspectives. This metadata includes basic information (such as view count, read count, project, and region), field information (such as field name, type, description, primary key, foreign key, and security level), output information, lineage, quality, and data preview. It also provides entry points for actions such as Request permissions, Bookmark, Generate API, and Data Analysis.
DataService Studio: Rapid API publishing
The DataService Studio module in DataWorks is a flexible, lightweight, secure, and stable platform for building data APIs. It provides comprehensive data sharing capabilities for enterprises and helps users realize data value and share data through features like publication approval, authorization management, call metering, and resource isolation.
Overview
As a "bridge" between the data warehouse and upper-layer application systems, DataService Studio provides a unified service bus for enterprises. It helps enterprises create and manage internal and external API services, closing the "last mile" gap between data warehouses, databases, and data applications, and accelerating data flow and sharing.
DataService Studio supports both no-code and self-service SQL modes to generate data APIs from tables in various data sources. It also supports Function Compute to help process API request parameters and returned results.
DataService Studio uses a serverless architecture. You do not need to manage the runtime environment or other infrastructure. You can publish API services to an API gateway with a single click.
Core technologies and architecture
DataService Studio uses a serverless architecture. You only need to focus on the query logic of your APIs without worrying about the underlying infrastructure. DataService Studio provisions computing resources for you and supports elastic scaling, achieving zero O&M costs.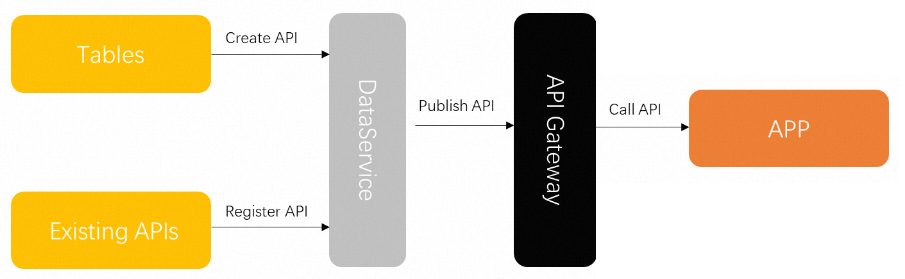
Open Platform: Open capabilities
Open Platform is the external channel through which DataWorks exposes data and capabilities. It provides OpenAPI, OpenEvent, and Extensions. These capabilities help you quickly integrate DataWorks with various application systems, perform data workflow control, data governance, and O&M efficiently, and respond to business status changes.
Overview
Open Platform provides OpenAPI, OpenEvent, and Extensions capabilities.
OpenAPI: You can use OpenAPI to deeply integrate your own applications with DataWorks. For example, you can batch create, deploy, and manage tasks to improve your big data processing efficiency and reduce manual operation costs.
For more information, see OpenAPI.
OpenEvent: You can use OpenEvent to subscribe to system events in DataWorks to obtain and respond to event changes in real time. For example, you can subscribe to table change events to implement real-time monitoring of core tables, or subscribe to task change events to build a custom real-time task monitoring dashboard.
For more information, see OpenEvent.
Extensions: Extensions are service-level plug-ins that combine OpenAPI and OpenEvent. You can use Extensions to customize process controls in DataWorks. For example, you can create a custom deployment control plug-in to block tasks that do not meet your specifications and requirements.
For more information, see Extensions.
Use cases
Open Platform provides comprehensive open capabilities for deep system integration, automated operations, process definition, and business monitoring. Users and partners can build industry-specific and scenario-based data applications and plug-ins based on DataWorks Open Platform.
Migration Assistant and cloud migration service
DataWorks Migration Assistant helps you migrate jobs from open-source scheduling engines to DataWorks. It supports cross-cloud, cross-region, and cross-account job migration, allowing you to quickly clone and deploy DataWorks jobs. Additionally, a cloud migration service is available to help you quickly migrate your data and tasks to the cloud.
Overview
The main features of Migration Assistant and the cloud migration service include:
Task migration to the cloud: Migrate jobs from open-source scheduling engines to DataWorks.
DataWorks migration: Migrate development assets within the DataWorks ecosystem.
Use cases
This feature is suitable for the following scenarios:
Task migration to the cloud: Migrate jobs from open-source scheduling engines to DataWorks.
Task backup: You can use Migration Assistant to back up task code regularly to minimize losses caused by accidental project deletion.
Rapid business replication: You can abstract common business logic and use the export and import features of Migration Assistant to quickly replicate it.
Quick creation of test environments: Use Migration Assistant to fully replicate business code. To set up a test environment, you only need to change the data input from a production database to test data.
Cross-cloud development: Import and export data between DataWorks on the public cloud and DataWorks in a private cloud to achieve collaborative development.