DataWorks allows you to easily build an offline data warehouse and analytics system based on MaxCompute. You can use the visual interface in DataWorks to configure task workflows, schedule and run tasks periodically, and manage metadata to ensure efficient and stable data production and management. This topic describes the basic process, billing details, environment preparation, and permission management for developing MaxCompute tasks in DataWorks.
Prerequisites
DataWorks is activated. For more information, see Activate DataWorks.
MaxCompute is activated. For more information, see Activate MaxCompute.
A DataWorks workspace is created. For more information, see Create a workspace.
Usage notes
The following table describes key topics for developing tasks.
Category | Description |
When you develop MaxCompute tasks in DataWorks, fees are incurred for both DataWorks and other related services. | |
Before you develop MaxCompute tasks in DataWorks, you must purchase the required DataWorks edition and resource groups for your business needs and associate the MaxCompute data source. | |
DataWorks provides product-level and module-level permission management, and supports visual permission requests and approvals for MaxCompute data sources. | |
Data Integration in DataWorks allows you to read data from and write data to MaxCompute. It supports various data synchronization scenarios, including batch synchronization, real-time synchronization, and full and incremental synchronization. | |
DataWorks provides the Data Modeling service to structure and manage large amounts of complex, disorganized data. It also provides the DataStudio feature to develop scheduling tasks. DataStudio works with Operation Center to monitor and maintain these tasks. | |
DataWorks provides metadata management and data governance capabilities for MaxCompute. | |
DataAnalysis in DataWorks provides data analysis and service sharing capabilities for MaxCompute. | |
DataWorks provides open capabilities that let you quickly integrate various application systems. This facilitates development process control, data governance, and O&M, and helps you quickly respond to business status changes from integrated systems. |
Billing
DataWorks DataStudio and Operation Center let you periodically schedule MaxCompute data synchronization and data processing tasks. Using these features incurs fees for DataWorks and other related services, as described in the following sections.
1. DataWorks charges
These charges appear on your DataWorks bill. For more information about DataWorks billing, see Billable items of DataWorks.
Charge | Description |
DataWorks edition fee | Before you can develop tasks, you must activate DataWorks. If you activate DataWorks Standard Edition, Professional Edition, or Enterprise Edition, you must pay the fee for the selected edition. |
Scheduling resource fee | After you develop a task, it requires scheduling resources to run on a schedule. You can use a serverless resource group (recommended) or an old-version exclusive resource group and pay the corresponding fees. Note A serverless resource group can be used for both task scheduling and data synchronization. |
Synchronization resource fee | When you run data synchronization tasks, you need data synchronization resources in addition to scheduling resources. You can use a serverless resource group (recommended) or an old-version exclusive resource group for data integration and pay the corresponding fees. |
No scheduling fees are charged for tasks that are run using the Run or Run with Parameters feature on the DataStudio page.
No scheduling fees are charged for tasks that fail to run or are run as dry runs.
For information about how DataWorks dispatches scheduling tasks to help you better understand the billing details, see How DataWorks dispatches scheduling tasks.
2. Non-DataWorks-related fees
These charges do not appear on your DataWorks bill. You may incur the following charges when you develop and run tasks.
The fees for other services are determined by the billing rules of those services. For more information, see the billing documentation for each service. For example, for information about MaxCompute billing, see Billable items of MaxCompute.
Fee | Description |
Database fees | Database fees may be incurred when you read data from or write data to upstream and downstream databases during data synchronization. |
Computing and storage fees | When you run a task on a compute engine, computing and storage fees may be incurred for the compute engine. For example, if you run a MaxCompute SQL task to create a table and write data to it, computing and storage fees may be incurred for MaxCompute. |
Network service fees | Network service fees may be incurred when you establish network connections between DataWorks and other related services. For example, using services such as Express Connect, Internet Shared Bandwidth, or Elastic IP Address (EIP) to establish network connections incurs fees from the corresponding services. |
Environment preparation
1. Resource preparation
DataWorks provides Standard, Professional, and Enterprise feature-rich editions, and also provides tenant-specific serverless resource groups. Select an edition and a resource group type that meets your business needs.
Category | Description | Related documentation |
Edition selection | DataWorks Basic Edition can meet the basic requirements for data migration to the cloud, data development, scheduled production, and simple data governance in MaxCompute development. If you require professional data governance and data security solutions, you can select Standard, Professional, or Enterprise Edition. | |
Resource group selection |
|
2. Development environment preparation
You must create a MaxCompute project as a data source of a DataWorks workspace and associate it with DataStudio before you can start development. You can also manage workspace members to collaborate on development.
Category | Description | Related documentation |
Data synchronization environment | Before you run MaxCompute synchronization tasks in DataWorks, you must add the MaxCompute project as a data source to the workspace. After you add the data source, you can use it to run synchronization tasks. | |
Data development and analysis environment | Before you run MaxCompute scheduling tasks in DataWorks, you must add the MaxCompute project as a data source to the workspace and associate it with DataStudio. Once associated, you can use the data source for data development, data analysis, and periodic task scheduling. | |
Collaborative development environment | To enable RAM users to collaborate on development in a workspace, you must add them as members to the workspace and grant them a development-related role. |
Permission management
DataWorks provides product-level and module-level permission management, and supports visual permission requests and approvals for MaxCompute data sources. The following sections describe how to manage permissions.
1. Data access and permission management
You can use a MaxCompute SQL node or an ad hoc query node to query MaxCompute table data. A workspace in basic mode does not support fine-grained permission management or isolation between the development and production environments. This topic uses a workspace in standard mode as an example.
Default permissions
After a RAM user is added to a workspace as a member, their default data access permissions are as follows:
Permission type
Description
MaxCompute development project permissions
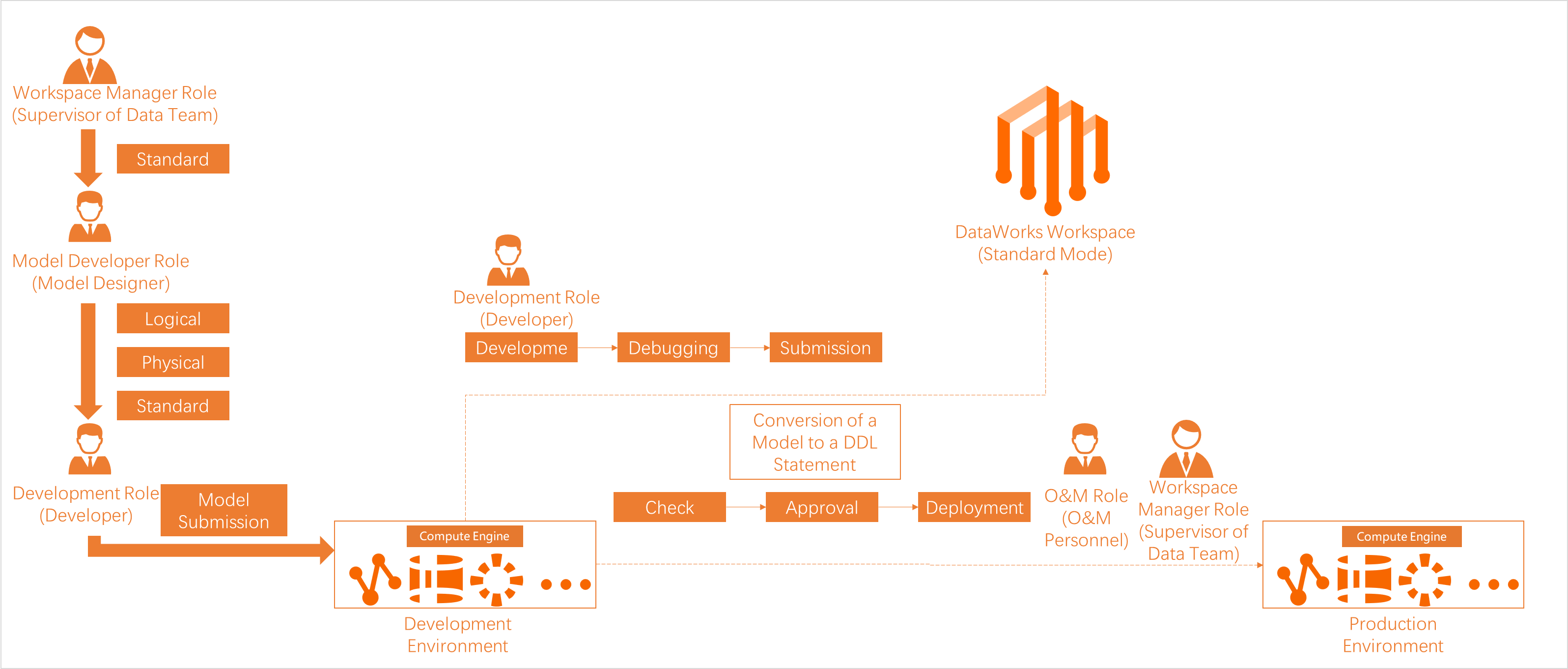
DataWorks maps predefined workspace-level roles to MaxCompute data source roles in the development environment. A RAM user with a workspace role inherits the permissions of the mapped data source role. By default, the RAM user has permissions on the development project, but not on the production project.
MaxCompute production project permissions
Only RAM users that are granted the scheduling access identity have broad permissions on the MaxCompute project in the production environment. Other RAM users do not have permissions on the production project. To operate on production tables, go to Security Center to request permissions.
DataWorks provides a default approval process, and also allows administrators to customize approval workflows.
For more information about MaxCompute data access control, see MaxCompute data permission management.
Data access behavior
MaxCompute supports cross-project table queries. In DataStudio, you can query production data in a DataWorks workspace across projects by specifying the project name. The following table describes how to access tables across projects and the accounts used for execution.
NoteYou can view the data sources created for different environments and the execution accounts configured for them in the workspace's data source information. For more information, see Associate a MaxCompute compute engine with a workspace.
In a DataWorks workspace in standard mode, tasks in the development environment are run using the personal identity of a task executor by default. Tasks in the production environment are run by using a specific Alibaba Cloud account, which is the scheduling access identity. For more information, see Associate a MaxCompute compute engine with a workspace.
Code example
Execution in development
Execution in production
Access a development table in a development project:
select col1 from projectname_dev.tablename;The task executor's personal Alibaba Cloud account accesses the development table.
If a RAM user runs the task, the RAM user's personal account is used.
If the primary Alibaba Cloud account runs the task, that account is used.
The scheduling access identity accesses the development table.
Access a production table in a production project:
select col1 from projectname.tablename;The task executor's personal Alibaba Cloud account accesses the production table.
NoteBy default, personal accounts do not have permission to access production tables due to security controls. You must go to Security Center to request permission. DataWorks provides a default approval process and also supports custom approval workflows.
The scheduling access identity accesses the production table.
Access a table in the current environment (for example, a development table in the development environment):
select col1 from tablename;When run in the development environment, the task uses the task executor's personal Alibaba Cloud account to access the target table in the development data source.
When run in the production environment, the task uses the scheduling access identity to access the target table in the production data source.
2. Feature module permission management
Before you start data development, you can assign different workspace roles to users to grant them different operation permissions. The following permission models are available:
The RAM policy-based authorization model manages permissions on DataWorks feature modules (for example, denying access to Data Map) and console operations (for example, allowing users to delete workspaces).
The RBAC model manages permissions on workspace-level modules (for example, allowing users to access DataStudio for development) and global modules (for example, denying access to the Data Security Guard module).
Get started
DataWorks provides multiple feature modules. You can develop scheduling tasks in DataStudio and then go to Operation Center to monitor and maintain the tasks. DataWorks also provides development process control for task development and deployment to help you standardize development operations and ensure security.
1. Data Integration
The Data Integration module in DataWorks lets you read data from and write data to MaxCompute. You can synchronize data from other data sources to a MaxCompute data source, or from a MaxCompute data source to other data sources. You can also run data synchronization tasks in different scenarios, such as batch synchronization, real-time synchronization, and full and incremental synchronization, as needed. For more information, see Data Integration.
2. Data development and O&M
Module | Description | Related documentation |
Data Modeling | Using Alibaba's data middle platform methodology, it helps you define your data warehouse plan, data standards, dimensional models, and data metrics. This helps enterprises understand and use data quickly and consistently. | |
DataStudio | DataWorks encapsulates the capabilities of the MaxCompute compute engine and allows you to run MaxCompute data synchronization and data development tasks.
|
|
You can combine general-purpose nodes and compute engine nodes in DataWorks to process complex logic. Major nodes include:
| ||
After you develop a node task, you can perform the following operations as needed:
| ||
Operation Center | Operation Center is a one-stop big data O&M and monitoring platform. It allows you to view the running status of tasks in real time and provides O&M operations such as intelligent diagnosis and reruns for abnormal tasks. It also provides an intelligent baseline feature to help you solve issues such as unpredictable completion times for important tasks and the difficulty of monitoring many tasks, ensuring timely task output. | |
Data Quality | Data Quality ensures data availability throughout the entire data development lifecycle. By efficiently validating data quality rules and tightly integrating with the task scheduling process, it helps you detect quality issues as early as possible and prevent data quality problems from spreading. This provides an efficient, reliable, and trustworthy data source for your business. |
3. Data governance
After you associate a MaxCompute data source, DataWorks automatically collects its metadata. You can go to Data Map to view the metadata. You can also go to Data Governance Center to view the issues that DataWorks detected and resolve them.
Module | Description | Related documentation |
Data Map | Using a unified metadata foundation, it helps you manage, inventory, find, and understand data objects. | |
Security Center Data Security Guard Approval Center | Security Center is a one-stop data security governance platform that integrates data asset classification, sensitive data identification, data authorization, sensitive data masking, access auditing, and risk identification and response. | |
Data Governance Center | Data Governance Center helps you proactively and systematically perform data governance. It uses data domain rule templates, automatically identifies assets that require optimization, and provides both pre-event and post-event governance strategies. |
4. Data analysis and services
DataWorks provides data processing, analysis, and service features, supporting efficient data sharing and access through centrally managed APIs.
Module | Description | Related documentation |
DataAnalysis | Lets you run online SQL queries, gain business insights, and edit and share data. You can also save query results as chart cards to quickly build visual data reports. | |
DataService Studio | DataService Studio provides comprehensive data service and sharing capabilities, helping enterprises centrally manage API services for both internal and external use. |
5. Open Platform
DataWorks supports open capabilities to help you quickly integrate various application systems with DataWorks. This facilitates development process control, data governance, and O&M, and helps you respond to business status changes in integrated application systems.
Category | Description | Related documentation |
OpenAPI | The OpenAPI feature of Open Platform provides APIs that enable interaction between on-premises services and DataWorks services. This improves the efficiency of big data processing, reduces manual operations and O&M, and lowers data risks and costs. | |
OpenEvent | The OpenEvent feature of Open Platform provides a message subscription service. By subscribing to DataWorks event statuses, your application systems can receive real-time status changes, helping you respond to events in a timely manner and meet personalized decision-making requirements. | |
Extensions | DataWorks provides a message push subscription feature based on OpenEvent. You can register a service program as a DataWorks extension to intercept and respond to subscribed event messages. This allows you to implement message notifications and process control for specific events through the extension. |
Appendix: Relationship between DataWorks and MaxCompute
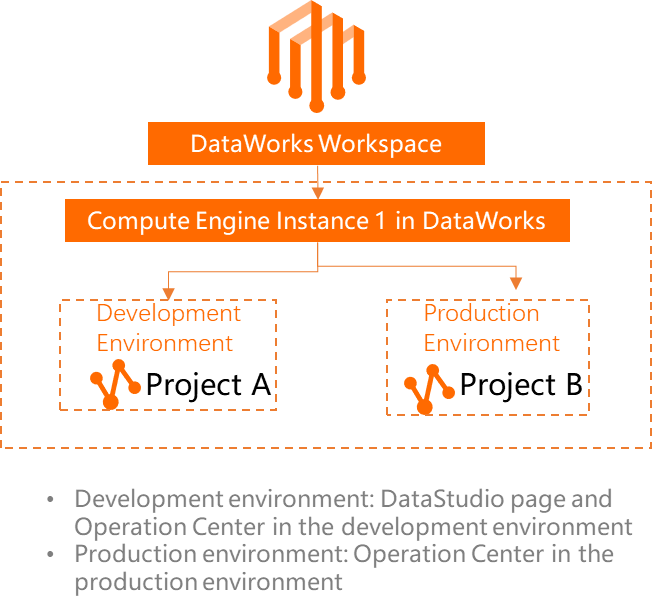
A workspace in basic mode has only one production environment and corresponds to a single MaxCompute project. This topic uses a workspace in standard mode as an example.
DataWorks provides capabilities such as task scheduling, metadata management, data governance, and data security control for MaxCompute. However, task computation and data storage still occur within MaxCompute. In a workspace in standard mode, DataWorks associates different MaxCompute projects with the development and production environments to isolate storage and resources.
For information about how to create a MaxCompute data source in a DataWorks workspace, associate it with DataStudio, and view the MaxCompute projects used in each environment, see Associate a MaxCompute compute engine with a workspace.
For more information about how DataWorks dispatches scheduling tasks, see How DataWorks dispatches scheduling tasks.