After you install the DataWorks Open Data package, you can use Open Data to obtain metadata. This helps you prepare data for subsequent data governance and O&M. This topic describes the main use cases for Open Data and provides the required commands.
DataWorks has released a new Open Data that allows you to browse and manage metadata using a visual user interface. We recommend using the official version of this feature. For more information, see Use Open Data.
Prerequisites
Open Data package is installed. For more information, see Install or uninstall Open Data package (The invitation-only version is about to be deprecated).
Usage
This topic uses an ODPS SQL node in DataWorks as an example to describe the commands to obtain different types of metadata using Open Data. Before running the commands, go to the code editor of an ODPS SQL node. Follow these steps:
- Go to the DataStudio page.
- Log on to the DataWorks console.
- In the left-side navigation pane, click Workspaces.
- On the Workspaces page, find the desired workspace and click Data Analytics in the Actions column.
Go to the code editor of an ODPS SQL node.
Find Data Studio under the MaxCompute computing engine. Right-click Data Studio and choose Create > ODPS SQL to create an ODPS SQL node.
You can use Open Data to obtain various types of metadata:
Viewing created databases (MaxCompute projects)
The raw_v_meta_database view in Open Data of DataWorks is used to query created databases. The command is as follows.
SELECT * FROM u_meta_hangzhou.raw_v_meta_database_<version>('<business_date>');The following table describes the parameters.
Version information: The version of Open Data that is used. The format is similar to v1_1. You can run the DESCRIBE PACKAGE command to query the actual version. For more information, see View tables or views provided by Open Data.
Business date: The business date for which to view metadata, in yyyymmdd format. If you do not specify a business date, metadata for all dates is displayed.
The following code provides an example:
-- Query the list of databases created on January 9, 2021.
SELECT * FROM u_meta_hangzhou.raw_v_meta_database_v1_1('20210109');Sample query result:  For more information about the fields in the query result, see Database (MaxCompute project) metadata details: raw_v_meta_database.
For more information about the fields in the query result, see Database (MaxCompute project) metadata details: raw_v_meta_database.
Viewing tables in a project
The raw_v_meta_table view of Open Data in DataWorks is used to query information about tables in a project. The command is as follows.
SELECT *
FROM u_meta_hangzhou.raw_v_meta_table_<version>('<business_date>')
WHERE catalog_name = 'your_catalog_name'
AND database_name = 'your_database_name'
AND table_name = 'your_table_name'
;The following table describes the parameters.
Version information: The version of Open Data that is used. The format is similar to v1_1. You can run the DESCRIBE PACKAGE command to query the actual version. For more information, see View tables or views provided by Open Data.
Business date: The business date for which to view metadata, in yyyymmdd format. If you do not specify a business date, metadata for all dates is displayed.
your_catalog_name: The catalog for the metadata of the specified computing engine. Set this parameter to odps.
your_database_name: The name of the project to query. Replace this with the actual project name.
your_table_name: The name of the table to query. Replace this with the actual table name.
The following code provides an example:
-- Query the ods_user_info_d table in the MaxCompute project named isv2 on January 9, 2021.
SELECT *
FROM u_meta_hangzhou.raw_v_meta_table_v1_1('20210109')
WHERE catalog_name = 'odps'
AND database_name = 'isv2'
AND table_name = 'ods_user_info_d'
;Sample query result: 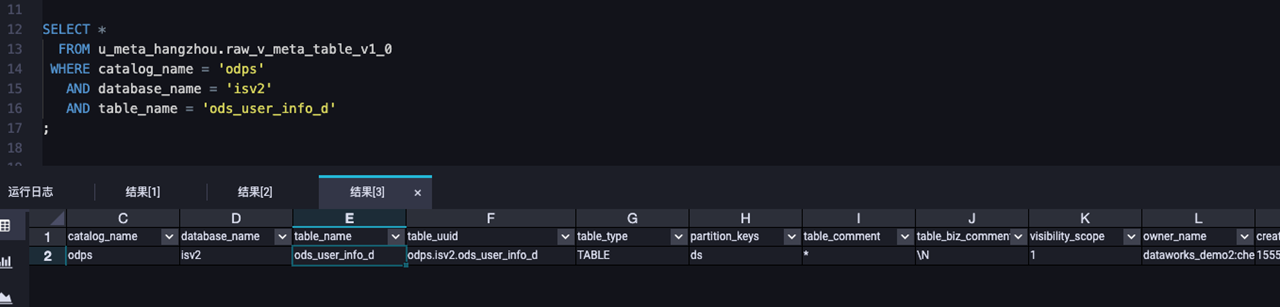 For more information about the fields in the query result, see Table metadata details: raw_v_meta_table.
For more information about the fields in the query result, see Table metadata details: raw_v_meta_table.
Querying table statistics
The rpt_v_meta_ind_table_core and rpt_v_meta_ind_table_extra views in Open Data can be used to query table statistics, such as tenant ID and table lifecycle. The command is as follows.
SELECT c.tenant_id, c.table_uuid, c.dim_life_cycle, c.is_partition_table, c.entity_type, c.categories, c.last_access_time, c.partition_count, c.favorite_count, e.output_task_count
FROM u_meta_hangzhou.rpt_v_meta_ind_table_core_<version>('<business_date>') c
LEFT OUTER JOIN u_meta_hangzhou.rpt_v_meta_ind_table_extra_<version>('<business_date>') e
ON c.table_uuid = e.table_uuid AND c.tenant_id = e.tenant_id
WHERE c.catalog_name = 'your_catalog_name'
AND c.database_name = 'your_database_name'
AND c.table_name = 'your_table_name'
;The following table describes the parameters.
Version information: The version of Open Data that is used. The format is similar to v1_1. You can run the DESCRIBE PACKAGE command to query the actual version. For more information, see View tables or views provided by Open Data.
Business date: The business date for which to view metadata, in yyyymmdd format. If you do not specify a business date, metadata for all dates is displayed.
your_catalog_name: The catalog for the metadata of the specified computing engine. Set this parameter to odps.
your_database_name: The name of the project to query. Replace this with the actual project name.
your_table_name: The name of the table to query. Replace this with the actual table name.
The following code provides an example:
-- Query the statistical information of the ods_user_info_d table in the MaxCompute project named isv2 on January 9, 2021.
SELECT c.tenant_id, c.table_uuid, c.dim_life_cycle, c.is_partition_table, c.entity_type, c.categories, c.last_access_time, c.partition_count, c.favorite_count, e.output_task_count
FROM u_meta_hangzhou.rpt_v_meta_ind_table_core_v1_1('20210109') c
LEFT OUTER JOIN u_meta_hangzhou.rpt_v_meta_ind_table_extra_v1_1('20210109') e
ON c.table_uuid = e.table_uuid AND c.tenant_id = e.tenant_id
WHERE c.catalog_name = 'odps'
AND c.database_name = 'isv2'
AND c.table_name = 'ods_user_info_d'
;Sample query result: 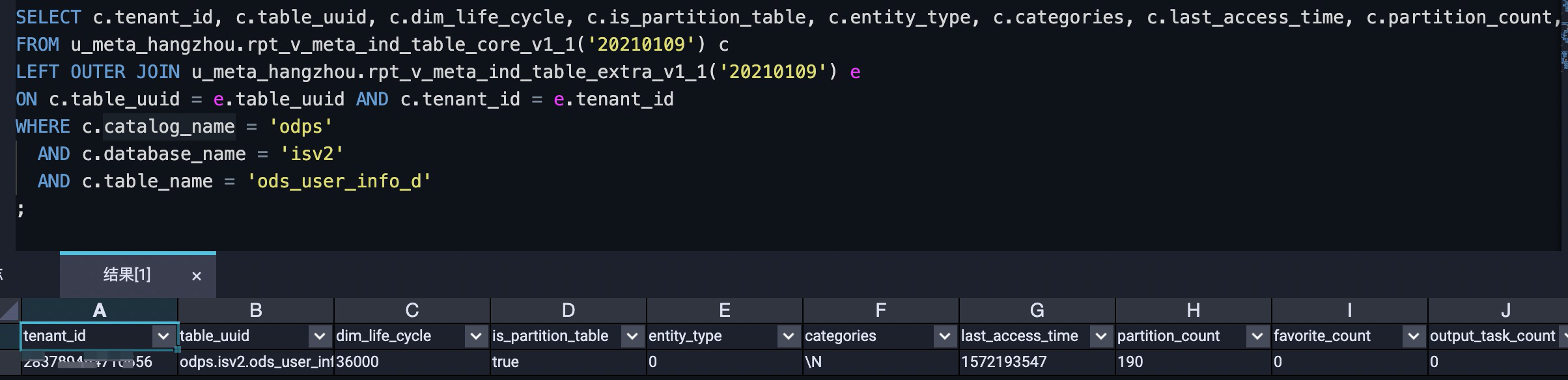 For more information about the fields in the query result, see Core table metrics: rpt_v_meta_ind_table_core and Additional table metrics: rpt_v_meta_ind_table_extra.
For more information about the fields in the query result, see Core table metrics: rpt_v_meta_ind_table_core and Additional table metrics: rpt_v_meta_ind_table_extra.
Viewing node details for an output table
You can use the raw_v_meta_table_output and raw_v_schedule_node views in the DataWorks Open Data to query the details of nodes for a table. The command is as follows.
SELECT s.*, o.schedule_instance_id, execute_time
FROM u_meta_hangzhou.raw_v_meta_table_output_<version>('<business_date>') o
LEFT OUTER JOIN u_meta_hangzhou.raw_v_schedule_node_<version>('<business_date>') s
ON o.schedule_task_id = s.node_id
WHERE o.type = 'your_table_type'
AND o.database = 'your_database_name'
AND o.table = 'your_table_name'
AND s.project_env = 'your_project_environment'
;The following table describes the parameters.
Version information: The version of Open Data that is used. The format is similar to v1_1. You can run the DESCRIBE PACKAGE command to query the actual version. For more information, see View tables or views provided by Open Data.
Business date: The business date for which to view metadata, in yyyymmdd format. If you do not specify a business date, metadata for all dates is displayed.
your_table_type: The type of the output table for which to retrieve metadata. This parameter is currently supported only for MaxCompute. Set this parameter to odps.
your_database_name: The name of the project to query. Replace this with the actual project name.
your_table_name: The name of the table to query. Replace this with the actual table name.
your_project_environment: Specifies the project environment whose metadata you want to view. Set this to DEV for the development environment or PROD for the production environment.
The following code provides an example:
-- Query the details of the production node for the odps table named ods_user_info_d in the xc_simple_e1 project on January 9, 2021.
SELECT s.*, o.schedule_instance_id, execute_time
FROM u_meta_hangzhou.raw_v_meta_table_output_v1_1('20210109') o
LEFT OUTER JOIN u_meta_hangzhou.raw_v_schedule_node_v1_1('20210109') s
ON o.schedule_task_id = s.node_id
WHERE o.type = 'odps'
AND o.database = 'xc_simple_e1'
AND o.table = 'ods_user_info_d'
AND s.project_env = 'PROD'
;Sample query result:  For more information about the fields in the query result, see Table output node metadata: raw_v_meta_table_output and Scheduling node details: raw_v_schedule_node.
For more information about the fields in the query result, see Table output node metadata: raw_v_meta_table_output and Scheduling node details: raw_v_schedule_node.
Viewing ancestor and descendant nodes
You can use the raw_v_schedule_node and raw_v_schedule_node_relation views in Open Data to query the upstream and downstream nodes of a specific node. The command is as follows.
-- Query the ancestor nodes.
SELECT *
FROM u_meta_hangzhou.raw_v_schedule_node_<version>('<business_date>') t
WHERE t.project_env = 'your_project_environment'
AND t.node_id IN (
SELECT parent_node_id
FROM u_meta_hangzhou.raw_v_schedule_node_relation_<version>('<business_date>') r
WHERE r.child_node_id = your_child_node_id
AND r.project_env = 'your_project_environment'
)
;
-- Query the descendant nodes.
SELECT *
FROM u_meta_hangzhou.raw_v_schedule_node_<version>('<business_date>') t
WHERE t.project_env = 'your_project_environment'
AND t.node_id IN (
SELECT child_node_id
FROM u_meta_hangzhou.raw_v_schedule_node_relation_<version>('<business_date>') r
WHERE r.child_node_id = your_child_node_id
AND r.project_env = 'your_project_environment'
)
;The following table describes the parameters.
Version information: The version of Open Data that is used. The format is similar to v1_1. You can run the DESCRIBE PACKAGE command to query the actual version. For more information, see View tables or views provided by Open Data.
Business date: The business date for which to view metadata, in yyyymmdd format. If you do not specify a business date, metadata for all dates is displayed.
your_project_environment: Specifies the project environment whose metadata you want to view. Set this to DEV for the development environment or PROD for the production environment.
your_child_node_id: The ID of the node to query.
The following code provides an example:
Query the ancestor nodes of a specific node in the production environment.
-- Query the list of ancestor nodes for node 1000550985 in the production environment on January 9, 2021. SELECT * FROM u_meta_hangzhou.raw_v_schedule_node_v1_1('20210109') t WHERE t.project_env = 'PROD' AND t.node_id IN ( SELECT parent_node_id FROM u_meta_hangzhou.raw_v_schedule_node_relation_v1_1('20210109') r WHERE r.child_node_id = 1000550985 AND r.project_env = 'PROD' ) ;Sample query result:
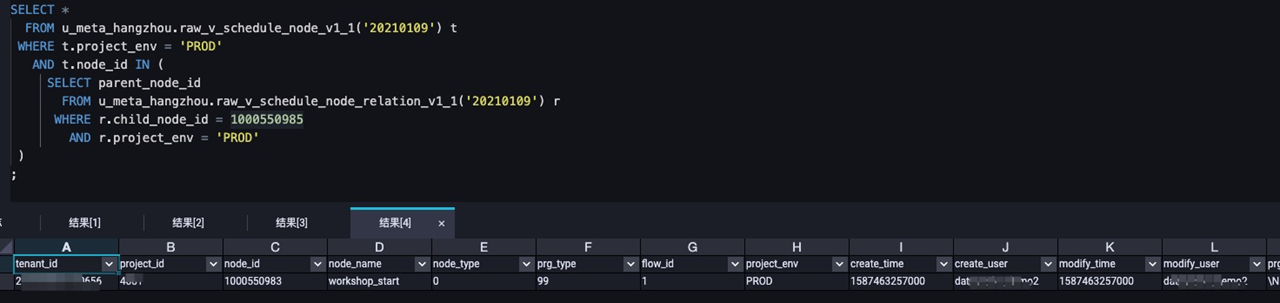
Query the descendant nodes of a specific node in the production environment.
-- Query the list of descendant nodes for node 1000550985 in the production environment on January 9, 2021. SELECT * FROM u_meta_hangzhou.raw_v_schedule_node_v1_1('20210109') t WHERE t.project_env = 'PROD' AND t.node_id IN ( SELECT child_node_id FROM u_meta_hangzhou.raw_v_schedule_node_relation_v1_1('20210109') r WHERE r.parent_node_id = 1000550985 AND r.project_env = 'PROD' ) ;Sample query result:

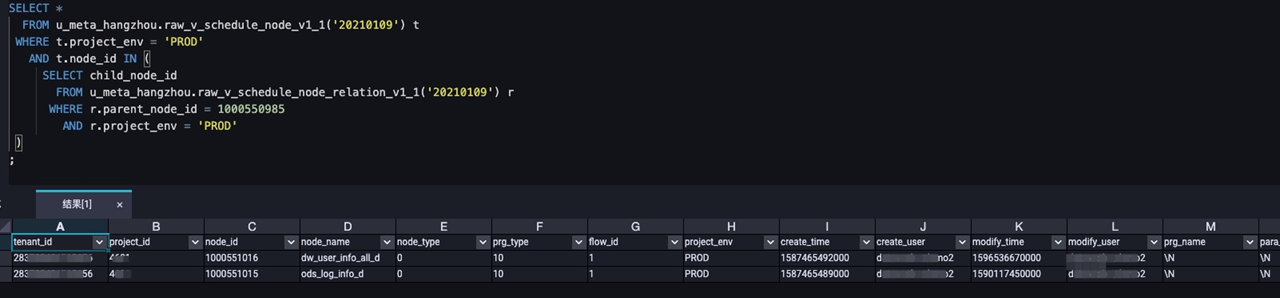
For more information about the fields in the query result, see Scheduling node details: raw_v_schedule_node and Scheduling node relationship details: raw_v_schedule_node_relation.
Viewing table and node owners
You can use the raw_v_meta_table and raw_v_tenant_user views in the DataWorks Open Data to query the owner details of a table or node. The commands are as follows.
Query the owner details of a table.
SELECT c.catalog_name, c.database_name, c.table_name, c.owner_name, u.account_name, u.nick FROM u_meta_hangzhou.raw_v_meta_table_<version>('<business_date>') c LEFT OUTER JOIN u_meta_hangzhou.raw_v_tenant_user_<version>('<business_date>') u ON c.owner_name = TOLOWER(u.yun_account) WHERE c.catalog_name = 'your_catalog_name' AND c.database_name = 'your_database_name' AND c.table_name = 'your_table_name' ;The following table describes the parameters.
Version information: The version of Open Data that is used. The format is similar to v1_1. You can run the DESCRIBE PACKAGE command to query the actual version. For more information, see View tables or views provided by Open Data.
Business date: The business date for which to view metadata, in yyyymmdd format. If you do not specify a business date, metadata for all dates is displayed.
your_catalog_name: The catalog for the metadata of the specified computing engine. Set this parameter to odps.
your_database_name: The name of the project to query. Replace this with the actual project name.
your_table_name: The name of the table to query. Replace this with the actual table name.
Query the owner details of a node.
SELECT t.project_id, t.node_id, t.node_name, t.create_user, u.account_name AS create_user_name, u.nick as create_user_nick, t.modify_user, m.account_name AS modify_user_name, m.nick as modify_user_nick FROM u_meta_hangzhou.raw_v_schedule_node_<version>('<business_date>') t LEFT OUTER JOIN u_meta_hangzhou.raw_v_tenant_user_<version>('<business_date>') u ON t.create_user = u.yun_account LEFT OUTER JOIN u_meta_hangzhou.raw_v_tenant_user_<version>('<business_date>') m ON t.modify_user = m.yun_account WHERE t.node_id = your_node_id AND t.project_env = 'your_project_environment' ;The following table describes the parameters.
Version information: The version of Open Data that is used. The format is similar to v1_1. You can run the DESCRIBE PACKAGE command to query the actual version. For more information, see View tables or views provided by Open Data.
Business date: The business date for which to view metadata, in yyyymmdd format. If you do not specify a business date, metadata for all dates is displayed.
your_project_environment: Specifies the project environment whose metadata you want to view. Set this to DEV for the development environment or PROD for the production environment.
your_node_id: The ID of the node to query.
The following code provides an example:
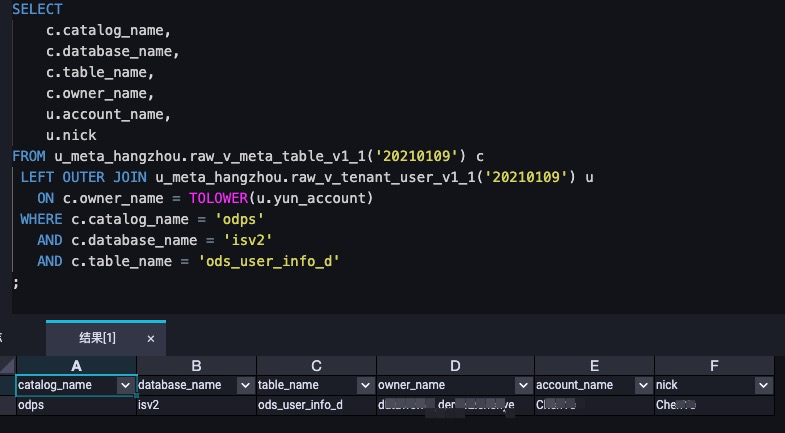
Query the owner details of a table on January 9, 2021.
SELECT c.catalog_name, c.database_name, c.table_name, c.owner_name, u.account_name, u.nick FROM u_meta_hangzhou.raw_v_meta_table_v1_1('20210109') c LEFT OUTER JOIN u_meta_hangzhou.raw_v_tenant_user_v1_1('20210109') u ON c.owner_name = TOLOWER(u.yun_account) WHERE c.catalog_name = 'odps' AND c.database_name = 'isv2' AND c.table_name = 'ods_user_info_d' ;Sample query result:
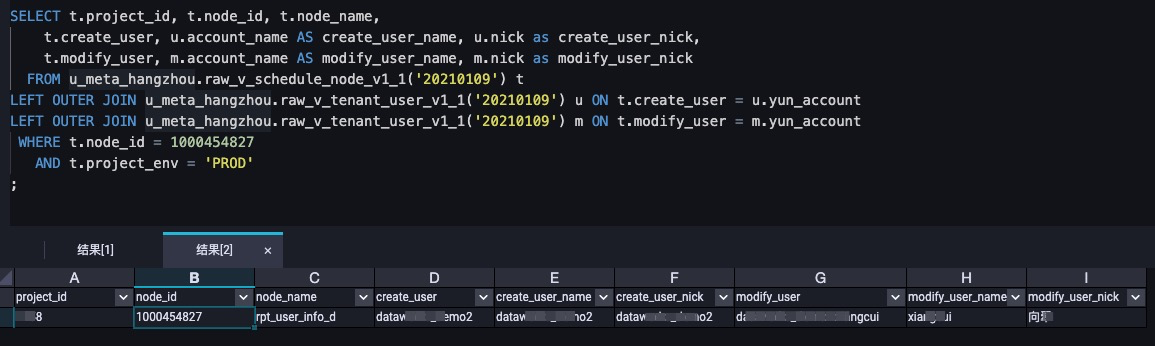
Query the owner and modifier details of a scheduled node on January 9, 2021.
SELECT t.project_id, t.node_id, t.node_name, t.create_user, u.account_name AS create_user_name, u.nick as create_user_nick, t.modify_user, m.account_name AS modify_user_name, m.nick as modify_user_nick FROM u_meta_hangzhou.raw_v_schedule_node_v1_1('20210109') t LEFT OUTER JOIN u_meta_hangzhou.raw_v_tenant_user_v1_1('20210109') u ON t.create_user = u.yun_account LEFT OUTER JOIN u_meta_hangzhou.raw_v_tenant_user_v1_1('20210109') m ON t.modify_user = m.yun_account WHERE t.node_id = 1000454827 AND t.project_env = 'PROD' ;Sample query result:
For more information about the fields in the query result, see Scheduling node details: raw_v_schedule_node and Scheduling node relationship details: raw_v_schedule_node_relation.
Next steps
The views provided by Open Data accept a date parameter in the yyyyMMdd format. You can use this parameter to partition data by date and retrieve historical data from the last 30 days. If you need to perform metric trend analysis, you can obtain data by business date and save it to your project for historical analysis.