If your documents have a fixed format and the fields to be extracted have clear and consistent contexts, you can use rule-based methods to supplement the model. This approach improves the performance of the entity extraction model, provides high accuracy, and does not require extensive annotation. If you cannot see the entry for rule configuration on the interface, contact us to enable the feature. Advanced settings also include preset fields, such as mobile phone numbers. These fields are extracted automatically without any annotation. You can configure this setting during model creation. The rules engine interface is shown below:
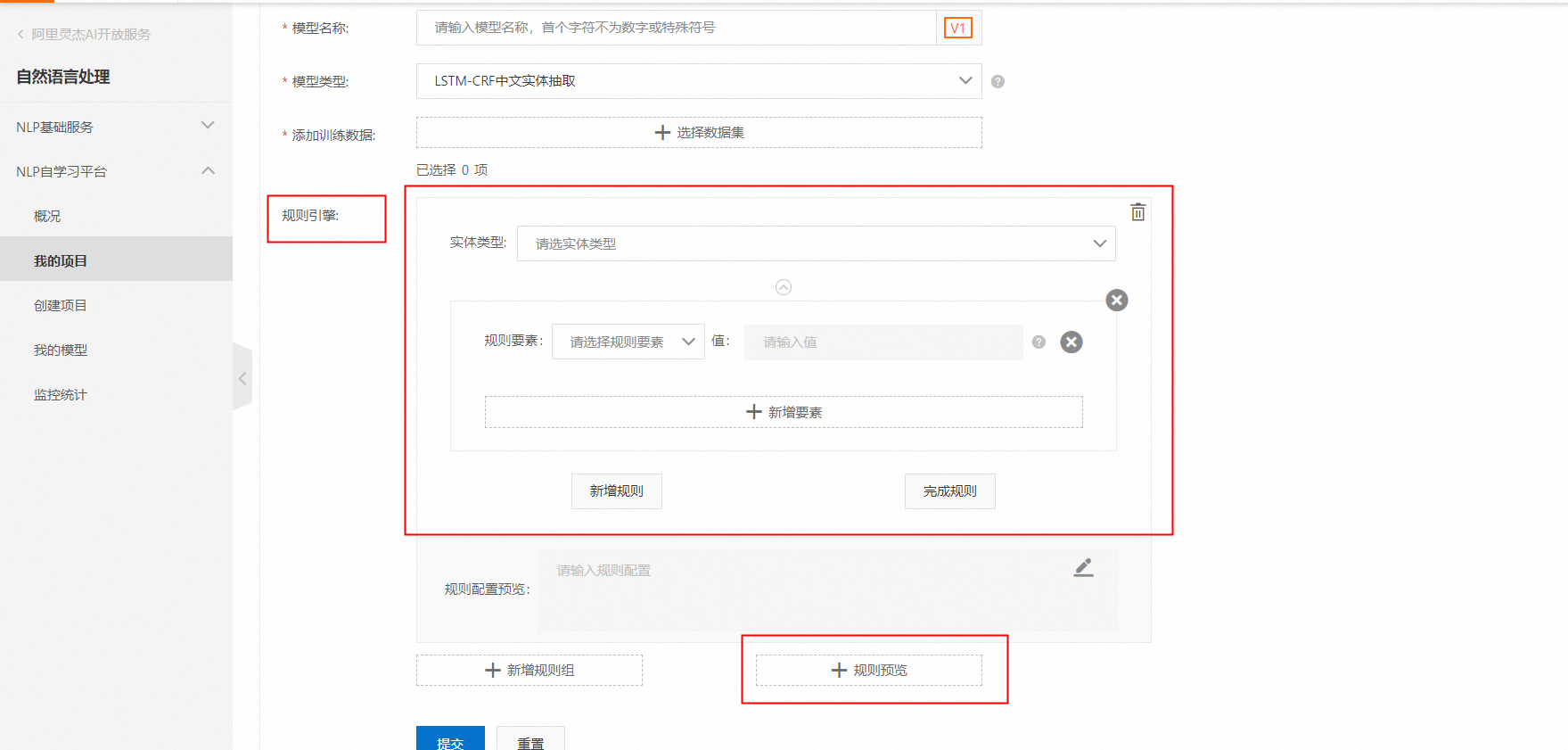
You can use the rule configuration feature to set up rules. These rules can be a combination of regular expressions, dictionaries, arbitrary characters, and entities extracted by the model. Then, you can use the rule preview feature to test your rules.
Rule configuration example
From the following legal document, extract the name, gender, and date of birth for the plaintiff and the defendant.
Plaintiff: Cheng Xiaoer, female, residing at Yuhang District, Hangzhou City, Zhejiang Province.\n\n Defendant: Wang Moumou, male, born on October 1, 2019, Han ethnicity.
You can use the rules engine to configure a regular expression that extracts these fields.
Click the following in order: Add Rule Group -> Set Entity Type to Plaintiff -> Set Rule Element to Regular Expression -> Set Value to: (?<=Plaintiff:)([^,]+)(?=,)
After you configure several rules, click Rule Preview to check them:
Advanced settings
Advanced settings also include presets for extracting common fields. This feature lets you extract these field types directly without any annotation. Currently, mobile phone number is a supported common field.
In addition to the common field presets, the advanced settings include traversal count and learning rate. The default values are usually sufficient. For more information, see the "Result optimization" chapter.