Service Mesh is the core of Ant Group's next-generation technology architecture and a key part of cloud-native application development for the Double 11 Shopping Festival. This topic describes how Ant Group supports the large-scale migration of applications from the existing microservice system to the Service Mesh architecture and ensures a smooth transition at scale.
Why use Service Mesh?
Before using Service Mesh
As the core technology stack for service administration in Ant Group's microservice system, SOFAStack provides middleware with capabilities such as service discovery and traffic control. Examples include the following:
Cloud Engine application containers
SOFABoot programming framework (open source)
SOFARPC (open source)
After years of refinement in demanding finance scenarios, SOFAStack has become highly reliable and scalable. Through open source collaboration, it has also developed a healthy community ecosystem that supports replacing and integrating other open source components. The middleware libraries are already decoupled from business logic, which simplifies development iteration.
However, because the runtime and the application are in the same process, business teams must upgrade their middleware versions when base libraries are upgraded.
After using Service Mesh
The Ant Group team introduced Service Mesh to refine and optimize the service administration capabilities that were originally provided as libraries. These capabilities are offloaded to a Sidecar Proxy process that runs independently alongside the business process. These Sidecar Proxies form a large-scale service network that provides a consistent, high-quality user experience for business applications. This approach allows service administration capabilities to be iterated on independently without affecting business applications.
Challenges of using Service Mesh
Service Mesh offers powerful features, but it also presents many real-world challenges, such as:
Data plane technology selection and proprietary protocol support.
Integrating the control plane with Ant Group's existing internal systems.
Building a supporting monitoring and Operations and Maintenance (O&M) system.
Optimizing request latency and resource utilization when two hops are added to the call chain.
What is an Operator?
If Kubernetes is an "operating system", then an Operator is a specialized application on Kubernetes. It is deployed in Kubernetes and uses the Kubernetes extended resource interface to provide services to end users.
This topic shares practical experience with Operators from the perspective of O&M and risk governance for MOSN, the Sidecar Proxy.
Sidecar O&M
Injection
Creation injection
For applications that are containerized and running in Kubernetes, the simplest way to integrate with Service Mesh is to inject a new MOSN container into the pod. This injection occurs during the application deployment phase by intercepting the pod creation request with a Mutating Webhook and modifying the original Pod Spec. This approach is also used by other Service Mesh solutions, such as Istio. The following is an example:
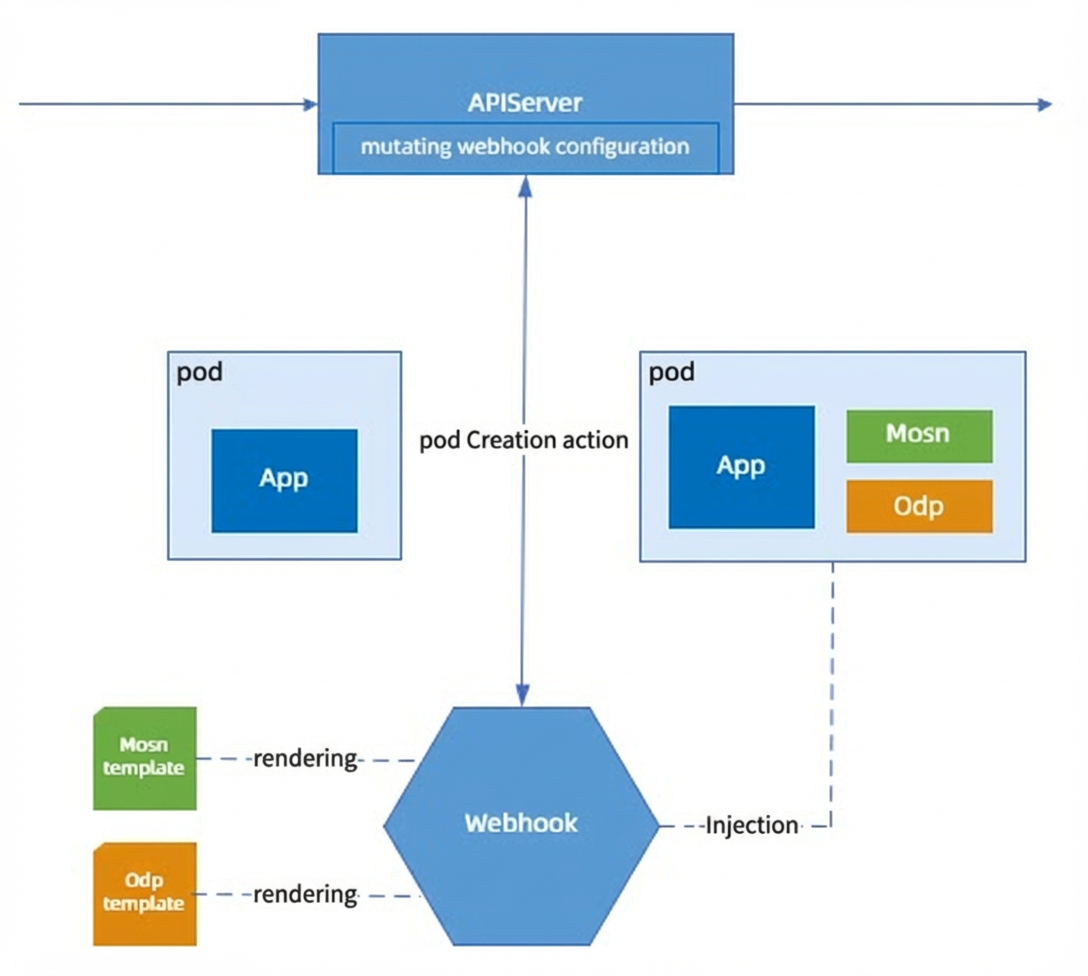
Initial configuration
For resource allocation, we initially assigned 512 MB of memory to the Sidecar based on experience with applications that use 8 GB of memory, as follows:
App: req=8 GB, limit=8 GB
Sidecar: req=512 MB, limit=512 MB
However, this allocation plan caused some problems:
Some high-traffic applications experienced severe out-of-memory (OOM) issues in their MOSN containers.
The injected Sidecar container requested additional memory resources from the scheduler. These resources were outside the business application's quota management.
Countermeasures
To eliminate the risk of memory OOM and avoid discrepancies in business resource capacity planning, the Ant Group team developed a new "shared memory" policy. The main points of this policy are:
The Sidecar's memory request is set to 0, so it no longer requests extra resources from the scheduler.
The limit is set to 1/4 of the application's memory. This ensures the Sidecar has enough memory available during normal operation.
To achieve a true shared memory model, Ant Group modified Kubelet. This modification ensures that while the Sidecar container's Cgroups limit is set to 1/4 of the application's memory, the entire pod's limit does not increase.
New threats and solutions
However, this approach introduces new threats. Ant Group has also proposed corresponding solutions, as described below:
Threat: The Sidecar and the application "share" allocated memory resources. This causes the Sidecar to compete with the application for memory resources in abnormal scenarios, such as a memory leak.
Solution: Extend the Pod Spec (specifically, the corresponding apiserver and Kubelet chains) to set the
Linux oom_score_adjproperty for the Sidecar container. This ensures that in a memory exhaustion scenario, the OOM Killer selects the Sidecar container with higher priority. This allows the Sidecar to restart faster than the application and restore service more quickly.Threat: In CPU resource allocation, MOSN might fail to acquire CPU resources. This can lead to significant jitter in request latency.
Solution: When injecting a Sidecar, calculate the appropriate cpushare weight for each Sidecar container based on the number of containers in the pod. A tool is used to scan for and fix any pods across the system that are not configured correctly.
In-place injection
The motivation for in-place injection includes the following aspects:
Integration method: A simple integration method is to inject the Sidecar when a pod is created. In this case, the application only needs to scale-out and then scale-in. This process gradually replaces legacy pods that do not have Sidecars with new pods that do.
Existing problems: When integrating many applications at scale, the cluster needs a large resource buffer for rolling replacement of application instances. Otherwise, the replacement process becomes very difficult and time-consuming.
Ant Group's goal: Do not add more machines for the Double 11 Shopping Festival. Instead, increase machine utilization.
To solve these problems and achieve the goal, the Ant Group team proposed the concept of "in-place injection". This means injecting the Sidecar into a pod without destroying or recreating the pod.
The steps for in-place injection are shown in the following figure:
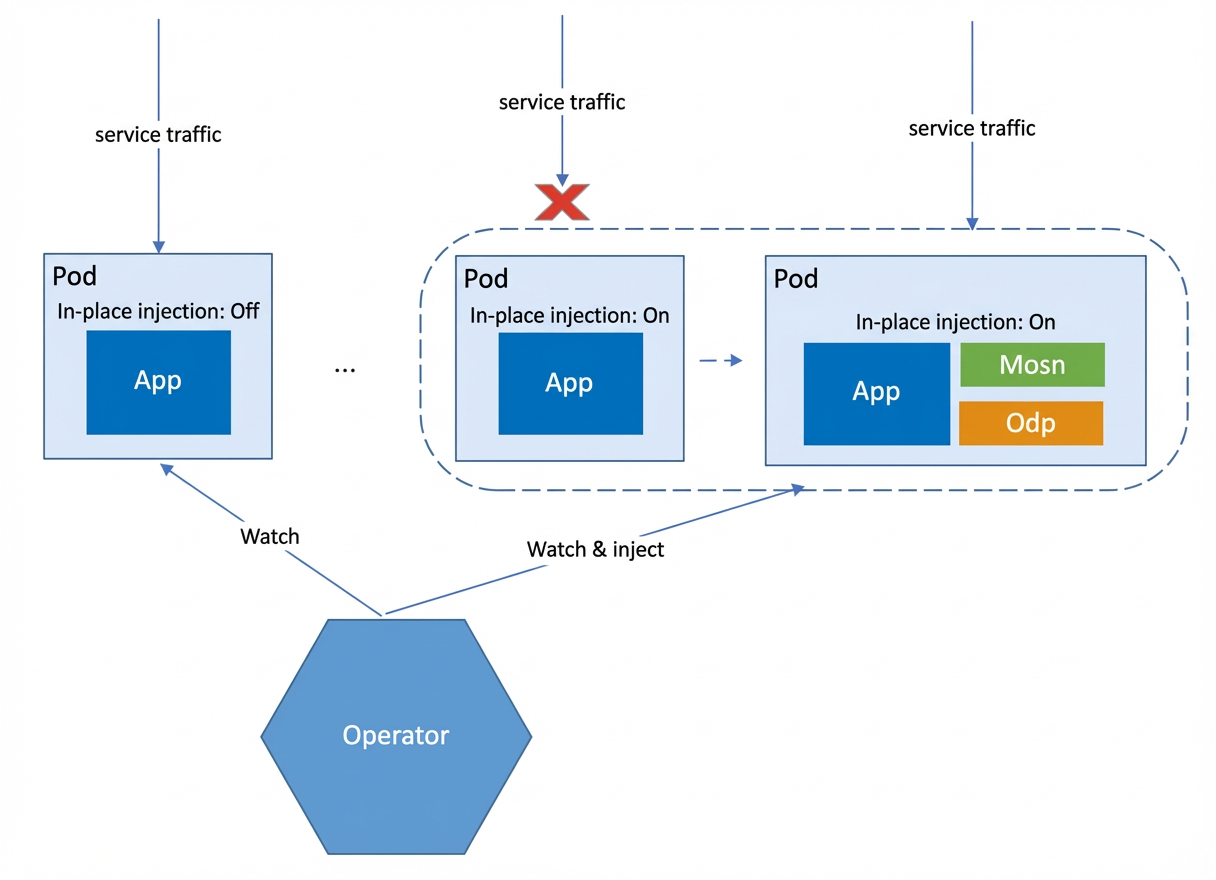
Submit a ticket in the Platform as a Service (PaaS) to select a batch of pods for in-place injection.
The PaaS calls the middleware interface to shut down service traffic and stop the application container.
The PaaS enables the in-place injection switch on the pod as an annotation.
The Operator observes that the in-place injection switch is enabled on the pod. It then renders the Sidecar template, injects it into the pod, and adjusts parameters such as CPU and Memory.
The Operator sets the desired state of the containers within the pod to running.
Kubelet restarts the containers within the pod.
The PaaS calls the middleware interface to resume service traffic.
Upgrades
After the Ant Group team offloaded capabilities such as RPC from base libraries to the Sidecar, base library upgrades were no longer tied to business applications. However, the need to iterate on these capabilities still exists. The focus has simply shifted from upgrading base libraries to upgrading the Sidecar.
Upgrade by replacement
The simplest upgrade method is replacement. This involves destroying the pod and recreating it. The new pod is automatically created with the new Sidecar version.
However, upgrading by replacement has a similar problem to injection at creation. It requires a large resource buffer. This upgrade method also has the greatest impact on business services and is the slowest.
Non-graceful upgrade
To avoid destroying and recreating pods, the Ant Group team implemented a "non-graceful upgrade" capability using the Operator. The following is an example.
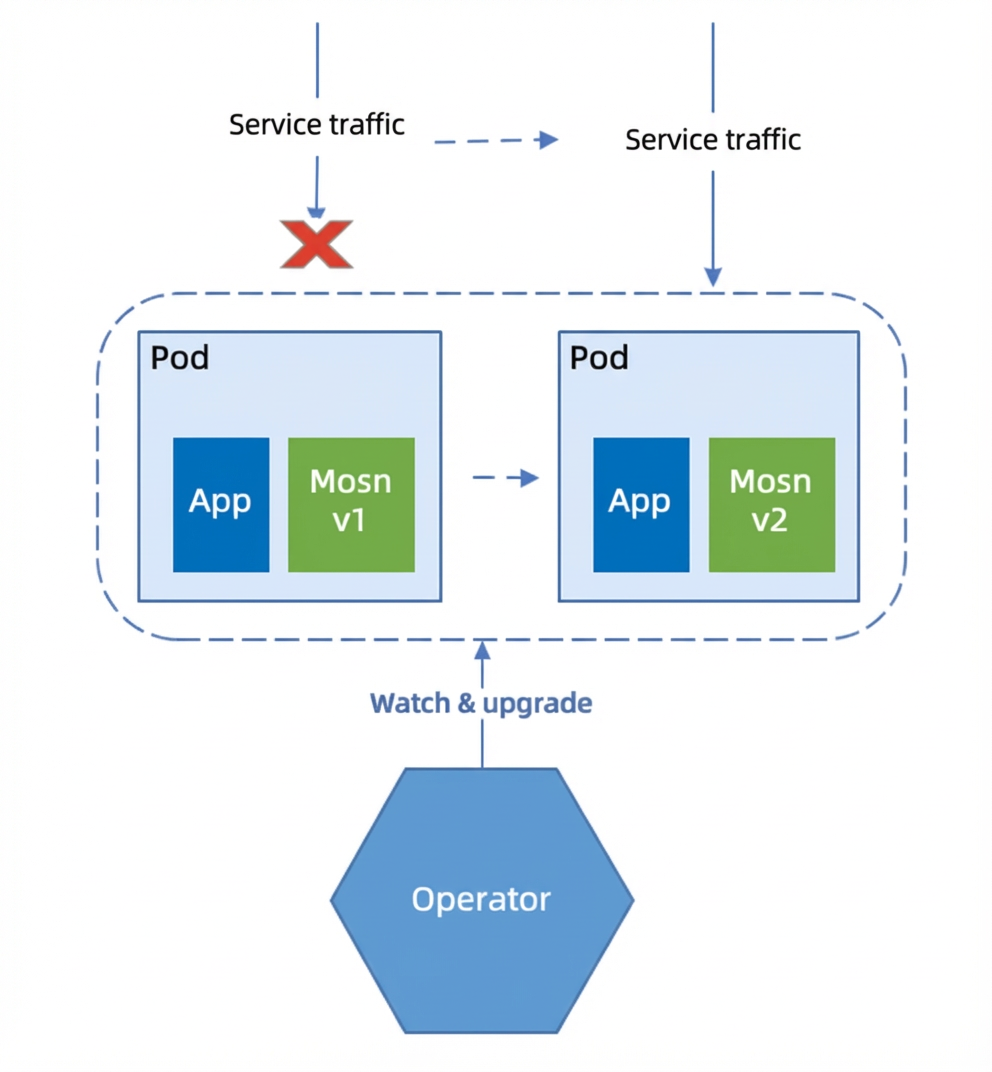
Non-graceful upgrade steps:
The PaaS shuts down traffic and stops the container.
The Operator replaces the MOSN container with the new version and restarts the container.
The PaaS resumes traffic.
In-place pod upgrades break the immutable infrastructure design of Kubernetes. To accomplish this, the Ant Group team modified the apiserver validation and admission logic to allow changes to a running Pod Spec. They also modified Kubelet's execution logic to implement container add, delete, start, and stop operations.
Graceful upgrade
To further reduce the impact of Sidecar upgrades on applications, the Ant Group team developed a "graceful upgrade" capability for the MOSN Sidecar. This allows MOSN to be upgraded without recreating the pod, shutting down traffic, or affecting the application.
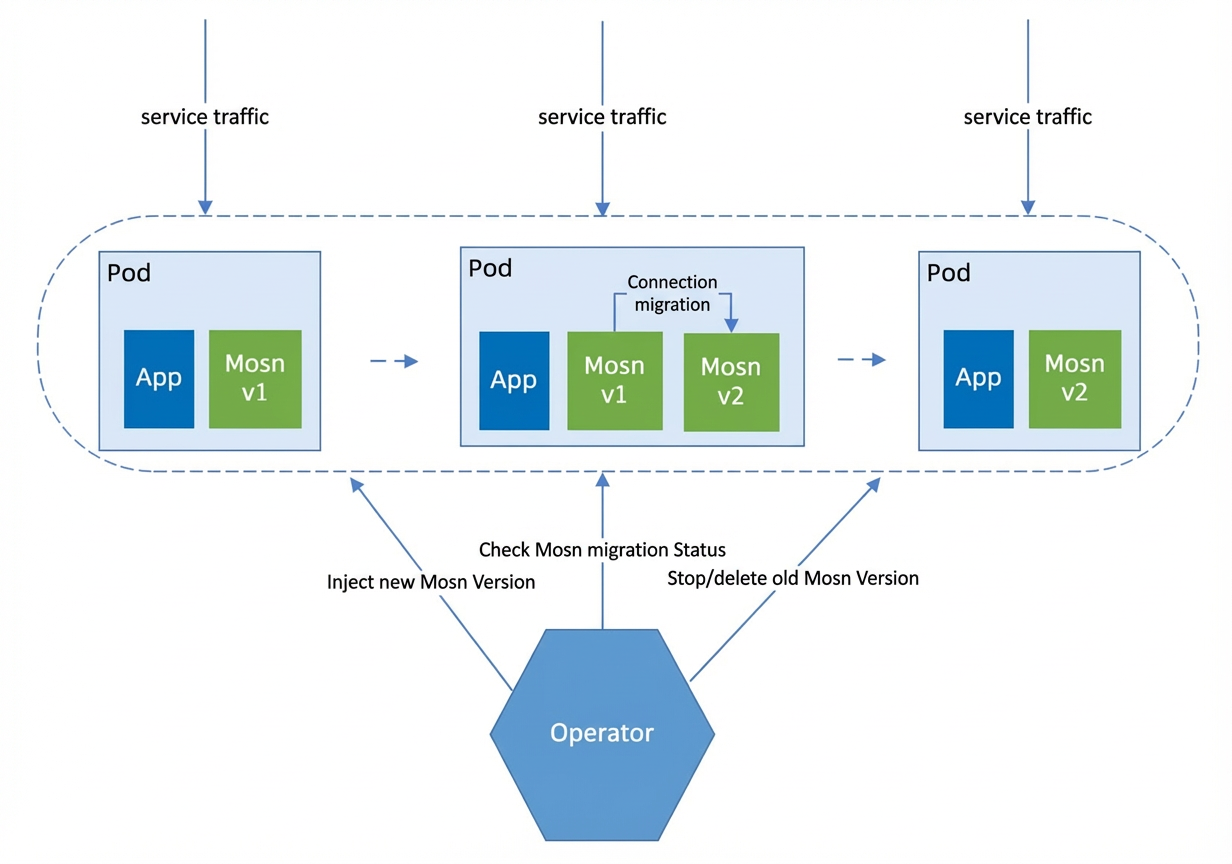
Principle of graceful upgrade: The Operator injects a new MOSN. It waits for the new MOSN to establish connections and for the metric data migration to complete. Then, it stops and removes the old MOSN. This process achieves a seamless, zero-loss upgrade that is transparent to the application.
Future work:
Increase the success rate.
Improve the Operator's state machine to enhance performance.
Rollback
To ensure that sales promotions run smoothly, the Ant Group team also provides a Sidecar rollback plan. If a critical problem is detected in Service Mesh, this plan allows applications to be quickly rolled back to a state without a Sidecar. The application can then revert to providing services with its original capabilities.
Risk Control
The analysis is based on the following:
Technical threats: All O&M operations for the Sidecar must be carefully managed. For grayscale capabilities, the Operator adds explicit switches for O&M actions such as upgrades. This ensures that each action aligns with the expectations of users and Site Reliability Engineers (SREs), preventing uncontrolled or unnoticed automatic changes.
Monitoring: In addition to basic metrics such as operation success rate, operation duration, and resource consumption, fine-grained monitoring must be continuously improved. The goal is to quickly detect problems and apply immediate remediation.
The O&M capabilities currently provided by the Operator are intricate. A single error can have a widespread impact. Therefore, increasing unit test and integration testing coverage will be an important focus for improving Service Mesh stability in the future.
Future considerations
After migrating to the Service Mesh architecture, it is very important to ensure that the Sidecar itself can iterate quickly and stably. In the future, Ant Group will focus on the following areas:
Continue to enhance the Operator's capabilities.
Use the following optimization methods for better risk governance:
Implement versioning for Sidecar templates. The Service Mesh control plane, not the user, determines which Sidecar version a specific pod of an application in a cluster should use. This allows for centralized management of all running Sidecar versions. It also binds the Sidecar binary to its container template, preventing unexpected or incompatible upgrades.
Provide richer template functions. This simplifies the complexity of writing Sidecar templates and reduces the error rate while maintaining flexibility.
Design a more complete grayscale mechanism. This allows for rapid circuit-breaking if the Operator becomes abnormal, preventing the scope of a failure from expanding.
Continuously consider how to make the entire Sidecar O&M approach more "cloud-native".