Learn how to submit and view Flink jobs on E-MapReduce.
Background
The Flink service in a Dataflow cluster is deployed in YARN mode. You can log on to the Dataflow cluster over SSH to submit Flink jobs from the command line.
A Dataflow cluster deployed in YARN mode supports submitting Flink jobs in session mode, per-job cluster mode, and application mode.
|
Mode |
Description |
Pros and Cons |
|
General process |
The following figure shows the general process of submitting and viewing a Flink job. For example, if an exception in a job causes a TaskManager to shut down, all other jobs running on that TaskManager will fail. In addition, because a cluster has only one JobManager, the load on the JobManager increases as the number of jobs increases. |
Based on these characteristics, this pattern is suitable for deploying jobs with a short startup time and a relatively short runtime. |
|
Per-Job Clustermode |
When usingPer-Job Clustermode,,each time aFlinkjob,YARNis submitted, YARN starts a newFlinkcluster,, and then runs the job。When the job finishes running or is canceled,,theFlinkcluster is also released。 |
Based on the above characteristics,, this mode is usually suitable for long-running jobs。 |
|
Applicationmode |
When usingApplicationmode,,each time you submit aFlink Application(Flink Application (anApplicationApplication contains one or more jobs),YARN, YARN will start aApplicationnewFlinkFlink cluster。When theApplicationApplication finishes running or is canceled,theApplicationApplication'sFlinkFlink cluster will also be released。 This mode differs from thePer-JobPer-Job mode in that,Applicationthe Application's correspondingJARJAR file's If the submittedJARJAR file contains multiple jobs,, then all these jobs will run in theApplicationApplication's cluster。 |
|
Prerequisites
A Dataflow cluster has been created in Flink mode. For more information, see Create a cluster.
Submit and view Flink jobs
This topic uses the Flink TopSpeedWindowing example. This example is a long-running streaming job.
You can choose from the following three modes to submit and view jobs:
Session mode
-
Connect to the master node of the cluster over SSH. For more information, see Log on to the master node of a cluster.
-
Run the following command to start a YARN session.
yarn-session.sh --detachedAfter the command runs successfully, the system returns an application ID. For example,
application_1750137174986_0001. This ID is referred to as<application_XXXX_YY>in the following sections.
-
Run the following command to submit the job.
flink run --detached /opt/apps/FLINK/flink-current/examples/streaming/TopSpeedWindowing.jarAfter the job is submitted, the system returns a message similar to the following one.
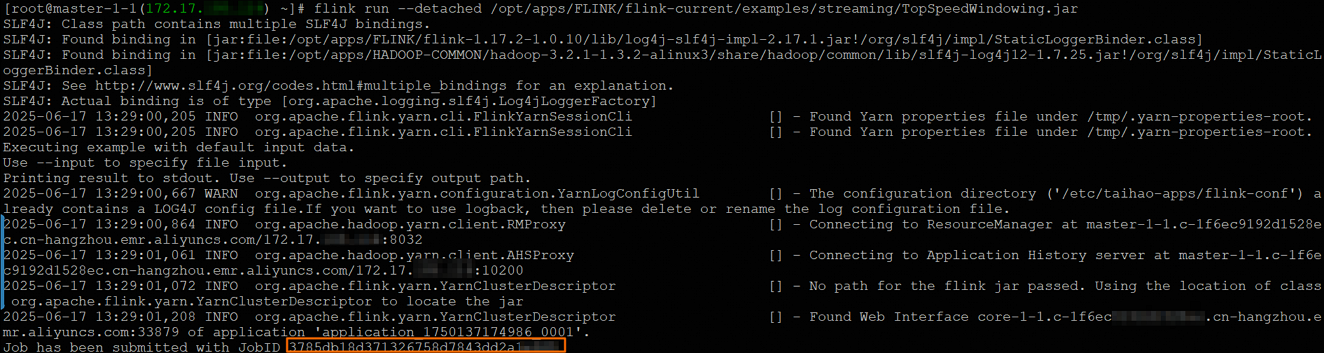
In the message,
3785db18d371326758d7843dd2a1****is the job ID. This ID is referred to as<jobId>in the following sections. -
Run the following command to view the job status.
flink list -t yarn-session -Dyarn.application.id=<application_XXXX_YY>A message similar to the following one is returned.
------------------ Running/Restarting Jobs ------------------- 16.06.2025 18:20:55 : 3785db18d371326758d7843dd2a1**** : CarTopSpeedWindowingExample (RUNNING)You can also view the job status on the web UI. For more information, see View the job status on the web UI.
-
Run the following command to stop the job.
flink cancel -t yarn-session -Dyarn.application.id=<application_XXXX_YY> <jobId>
Per-job cluster mode
-
Connect to the master node of the cluster over SSH. For more information, see Log on to the master node of a cluster.
-
Run the following command to submit the job.
flink run -t yarn-per-job --detached /opt/apps/FLINK/flink-current/examples/streaming/TopSpeedWindowing.jarAfter the job is submitted, the system returns a message similar to the following one.

In the message,
application_1750125819948_****is the application ID, which is referred to as<application_XXXX_YY>in the following sections.f5f980ac631192b02548235f1bbe****is the job ID, which is referred to as<jobId>in the following sections. -
Run the following command to view the job status.
flink list -t yarn-per-job -Dyarn.application.id=<application_XXXX_YY>You can also view the job status on the web UI. For more information, see View the job status on the web UI.
-
Run the following command to stop the job.
flink cancel -t yarn-per-job -Dyarn.application.id=<application_XXXX_YY> <jobId>
Application mode
-
Connect to the master node of the cluster over SSH. For more information, see Log on to the master node of a cluster.
-
Run the following command to submit the job.
flink run-application -t yarn-application /opt/apps/FLINK/flink-current/examples/streaming/TopSpeedWindowing.jarAfter the job is submitted, the system returns a message similar to the following one.

In the message,
application_1750125819948_0004is the YARN application ID of the submitted Flink job. This ID is referred to as<application_XXXX_YY>in the following sections. -
Run the following command to view the job status.
flink list -t yarn-application -Dyarn.application.id=<application_XXXX_YY>A message similar to the following one is returned. In the message,
4db32b5339e6d64de2a1096c4762****is the<jobId>of the job.------------------ Running/Restarting Jobs ------------------- 16.06.2025 18:20:55 : 4db32b5339e6d64de2a1096c4762**** : CarTopSpeedWindowingExample (RUNNING)You can also view the job status on the web UI. For more information, see View the job status on the web UI.
-
Run the following command to stop the job.
flink cancel -t yarn-application -Dyarn.application.id=<application_XXXX_YY> <jobId>
Specify job configurations
Flink provides three ways to specify job configurations:
-
Specify configuration values in your job code. For more information, see Flink Configuration.
-
When you submit a job with the
flink runcommand, use the -D flag to specify configuration values. For example,flink run-application -t yarn-application -D state.backend=rocksdb.... -
Specify configuration values in the
/etc/taihao-apps/flink-conf/flink-conf.yamlfile.
If you do not specify configurations by using these methods, Flink uses the default values. For more information about configuration parameters, see the official Apache Flink website.
Check job status on the web UI
-
Access the web UI.
-
Log on to the E-MapReduce console.
-
In the navigation pane on the left, select EMR on ECS.
-
In the top navigation bar, select a region and a resource group as needed.
-
On the EMR on ECS page, click the Cluster ID of the target cluster.
-
Click the Access Links and Ports tab.
-
On the Access Links and Ports page, click the link in the YARN UI row.
For more information, see Access the web UIs of open-source components.
-
-
Click an application ID.
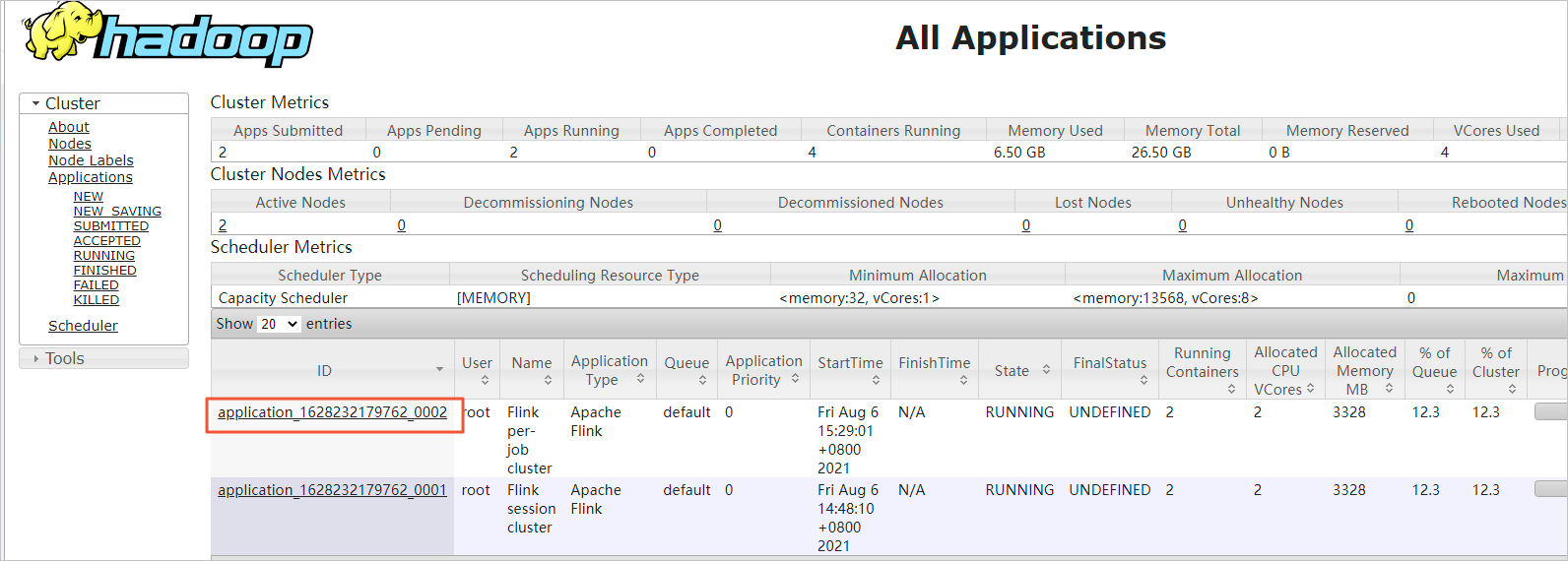
-
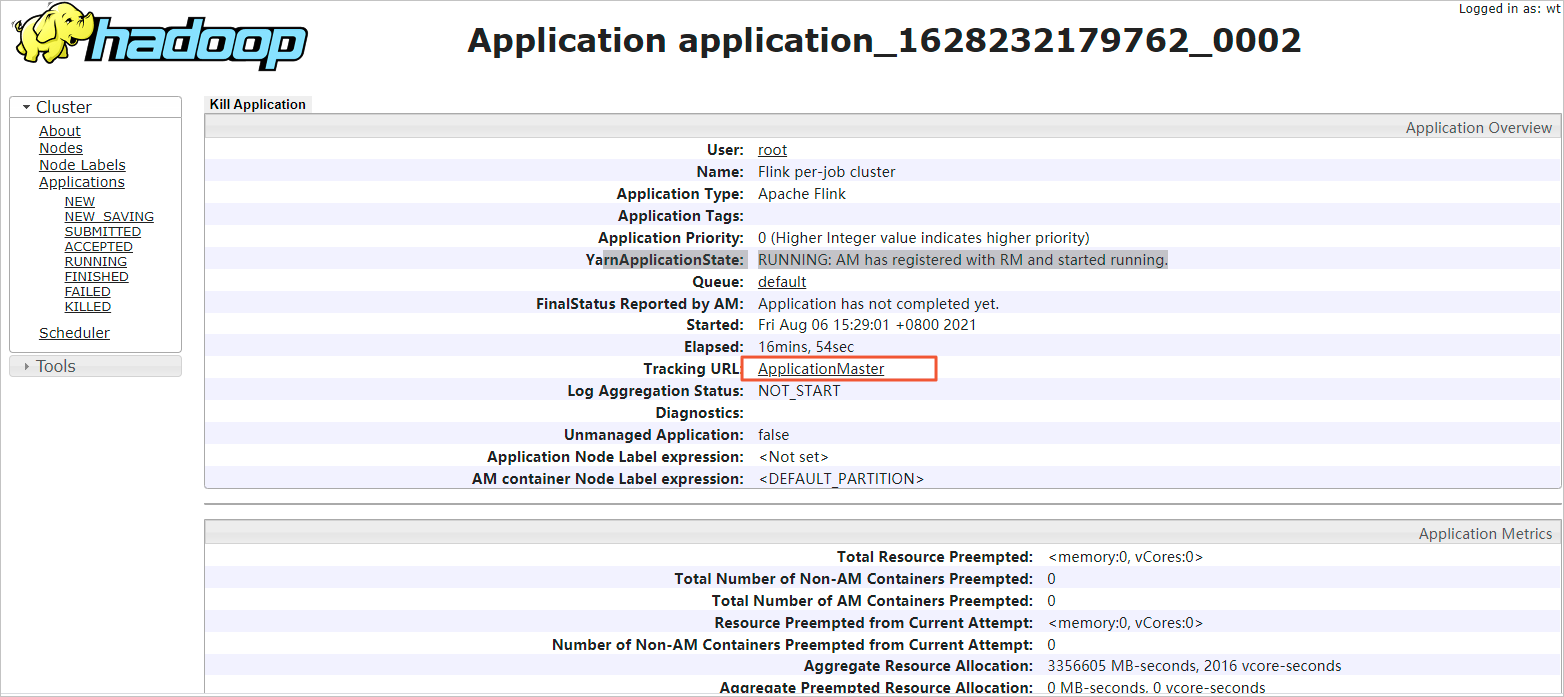
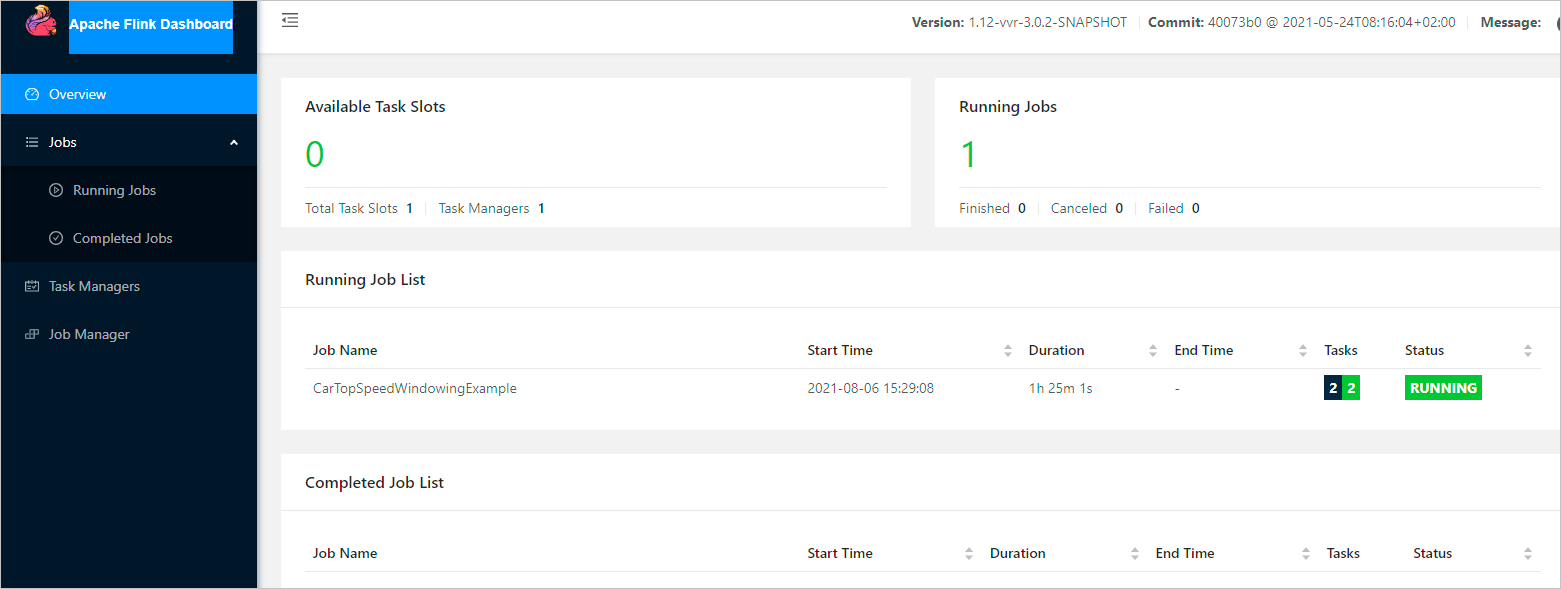
Click the link for the Tracking URL.

The Apache Flink Dashboard page opens and displays the job status.
Related documents
For more information about Flink on YARN, see Apache Hadoop YARN.