Restart a cluster or individual nodes to apply configuration changes or resolve exceptions. Each restart method has different prerequisites and risk levels.
Pre-restart checks
Complete these checks before restarting.
High disk usage slows restart. Reduce disk usage below the cluster.routing.allocation.disk.watermark.low threshold before restarting. Do not perform scale-out, restarts, password changes, or other configuration changes until the cluster returns to green status.
-
Check the cluster health status
Connect to the cluster through Kibana and runGET _cluster/health. Verify thatstatusisgreen.Exception: Forced restart is available only when status is
yelloworred. -
Ensure data redundancy
RunGET _cat/indices?vto check therep(replica count) for all critical indices.-
Replica count must be at least
1. Indices without replicas are inaccessible during restart. -
For multi-zone instances, replica count must be less than the zone count.
-
-
Check and handle closed indices
RunGET _cat/indices?vto check for indices withstatus=close.-
Closed indices block shard allocation and restart.
-
To open closed indices, run
POST /<index_name>/_open.
-
-
Assess cluster load
On the Cluster Monitoring page, verify sufficient capacity for shard migration:-
Node CPU Utilization: below 80%
-
Node Heap Memory Usage: around 50%
-
NodeLoad_1m: below the CPU core count
-
Procedure
After the health checks pass, restart the cluster:
-
Log on to the Alibaba Cloud Elasticsearch console. In the left navigation pane, click Elasticsearch Clusters.
-
In the top navigation bar, select the region. Click the target instance ID, then click Restart in the upper-right corner of the Basic Information page.

-
In the Restart dialog box, configure the following parameters:
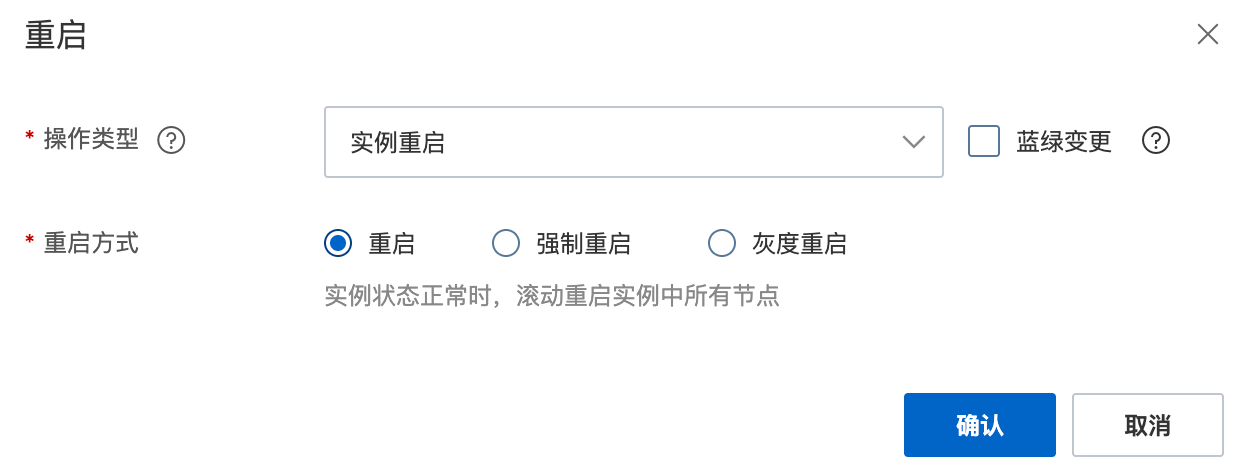
-
Object
-
Cluster: Restarts all nodes in the cluster. Suitable for cluster-level changes.
-
Node Restart: Restarts one or more specified nodes. Suitable for resolving issues with individual nodes.
-
Node Role (For basic control v2 architecture only): Restarts nodes of a specific role that you select, such as data nodes or Kibana nodes.
-
-
Blue-green Update and Restart Mode
Select a restart method based on your scenario, cluster status, and risk tolerance:
Restart method
Required Cluster Status
Mechanism and scenario
Impact
Limitations
Blue-green Update
Normal (green)
Provisions new nodes, migrates data from old nodes, then removes old nodes.
Use when a node has persistent high CPU and availability is more important than speed.
ImportantA blue-green update cannot be used with a forced restart.
Node IPs change. Performance may briefly fluctuate.
Not supported for 1 vCPU 2 GB cluster specs
Restart (Standard)
Normal (green)
Planned maintenance and regular cluster configuration.
Node IPs remain unchanged. Takes longer. Service stays available with replicas but may briefly fluctuate.
Phased Restart
Normal (green)
Verifies restart effects in batches to reduce production risk.
Select nodes for the first batch. After the cluster stabilizes, manually trigger the remaining nodes.
Node IPs remain unchanged. Minimizes production impact.
Available for cloud-native control architecture (v3) clusters only
Forced Restart
Abnormal (yellow/red)
Use when the cluster is yellow or red. Other restart methods are disabled in this state.
Node IPs remain unchanged.
Higher concurrency speeds up restart but increases risk:
-
100% concurrency restarts all nodes simultaneously, causing service interruption and potential loss of unpersisted cached data.
-
Use high concurrency only for urgent recovery.
Concurrency: Percentage of nodes restarted simultaneously. Default is 10%, minimum 1 node.
Displayed only in forced restart mode.
-
-
-
(Optional) For forced restart, select Restart Cluster Forcibly.
-
Click OK.
The cluster status changes to Initializing. Status returns to Normal after completion.
Post-restart verification
Verify cluster health and monitor shard recovery after the restart:
-
Check cluster health:
GET _cluster/health -
Monitor nodes and shard recovery:
GET _cat/nodes GET _cat/recovery -
Wait for all shards to be allocated before resuming operations.