The hot and cold data separation feature in ApsaraDB for HBase Performance-enhanced Edition stores hot and cold data on different media to improve query efficiency for hot data and reduce your overall storage costs.
Background
In many big data scenarios, some data in a table is accessed less frequently over time, becoming archival. This historical data, such as order history or monitoring metrics, can be very large. Reducing its storage cost can lead to significant savings. To meet this need, ApsaraDB for HBase Performance-enhanced Edition provides the hot and cold data separation feature. It offers a new cold storage medium that costs only one-third as much as an ultra disk.
ApsaraDB for HBase Performance-enhanced Edition implements hot and cold data separation within a single table. The system automatically archives cold data to cold storage based on a time boundary that you define. Data access is transparent to your applications, just like accessing a regular table. During queries, you can use hints or specify a TimeRange, and the system automatically determines whether to retrieve data from hot storage, cold storage, or both.
How it works
Once you configure a time boundary for a table, ApsaraDB for HBase Performance-enhanced Edition uses the data's write timestamp (in milliseconds) and this boundary to determine whether the data is hot or cold. Data is initially stored in hot storage and gradually migrates to cold storage as it ages. You can change the time boundary at any time, allowing data to move from hot to cold storage or from cold back to hot storage.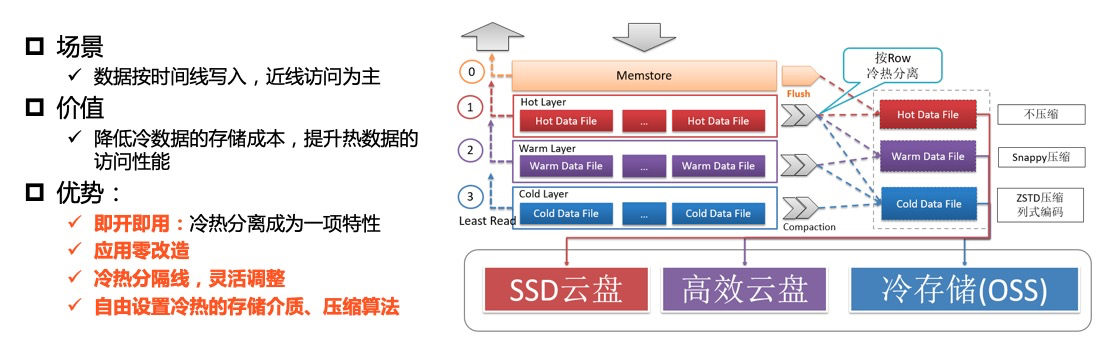
Usage notes
See the usage notes in Use cold storage.
How to use this feature
To use the cold storage feature, your ApsaraDB for HBase Performance-enhanced Edition cluster must be version 2.1.8 or later. You do not need to modify client dependencies for data read and write operations. You only need to modify the table schema using one of the following methods:
Use Java API: Requires AliHBase-Connector 1.0.7/2.0.7 or later. For instructions on how to install the Java SDK and configure parameters, see Use the Java API to access an ApsaraDB for HBase Performance-enhanced Edition cluster.
Use HBase Shell: Requires alihbase-2.0.7-bin.tar.gz or later. For instructions on how to download and configure the shell, see Use HBase Shell to access an ApsaraDB for HBase Performance-enhanced Edition cluster.
Enable the cold storage feature
To use the cold storage feature for your cluster, see Use cold storage.
Set the time boundary
You can adjust the COLD_BOUNDARY at any time to define the boundary between hot and cold data. The unit for COLD_BOUNDARY is seconds. For example, COLD_BOUNDARY => '86400' means that data written more than 86,400 seconds (one day) ago is automatically archived to cold storage.
When you use hot and cold data separation, you do not need to set the COLD attribute on a column family. If a column family already has this attribute set, remove it. For more information, see Use cold storage.
Shell
// Create a table with hot and cold data separation.
hbase(main):002:0> create 'chsTable', {NAME=>'f', COLD_BOUNDARY=>'86400'}
// Disable hot and cold data separation.
hbase(main):004:0> alter 'chsTable', {NAME=>'f', COLD_BOUNDARY=>""}
// Enable hot and cold data separation for an existing table, or modify the time boundary. The unit is seconds.
hbase(main):005:0> alter 'chsTable', {NAME=>'f', COLD_BOUNDARY=>'86400'}Java API
// Create a table with hot and cold data separation.
Admin admin = connection.getAdmin();
TableName tableName = TableName.valueOf("chsTable");
HTableDescriptor descriptor = new HTableDescriptor(tableName);
HColumnDescriptor cf = new HColumnDescriptor("f");
// Set COLD_BOUNDARY to define the time boundary in seconds. This example archives data older than one day as cold data.
cf.setValue(AliHBaseConstants.COLD_BOUNDARY, "86400");
descriptor.addFamily(cf);
admin.createTable(descriptor);
// Disable hot and cold data separation.
// Note: A major compaction is required to move data from cold storage back to hot storage.
HTableDescriptor descriptor = admin
.getTableDescriptor(tableName);
HColumnDescriptor cf = descriptor.getFamily("f".getBytes());
// Disable hot and cold data separation.
cf.setValue(AliHBaseConstants.COLD_BOUNDARY, null);
admin.modifyTable(tableName, descriptor);
// Enable hot and cold data separation for an existing table, or modify the time boundary.
HTableDescriptor descriptor = admin
.getTableDescriptor(tableName);
HColumnDescriptor cf = descriptor.getFamily("f".getBytes());
// Set COLD_BOUNDARY to define the time boundary in seconds. This example archives data older than one day as cold data.
cf.setValue(AliHBaseConstants.COLD_BOUNDARY, "86400");
admin.modifyTable(tableName, descriptor);Write data
Writing data to a table with hot and cold data separation is identical to writing to a standard table. You can write data using the Java API or a multi-language API. The write timestamp is the current time. Data is first stored in hot storage (ultra disk). As time passes, if a row's write time exceeds the value set in COLD_BOUNDARY, the row is archived to cold storage during a major compaction. This process is completely transparent to you.
Query data
Because hot and cold data reside in the same table, you query only a single table. If you know that the data you need is in hot storage (written more recently than the COLD_BOUNDARY value), you can set the HOT_ONLY hint on a Get or Scan operation to query only the hot data. Alternatively, you can set a TimeRange to limit the query's time scope. The system uses the TimeRange to determine whether to query hot storage, cold storage, or both. Querying cold data has higher latency than querying hot data, and cold storage has lower query throughput.
Query examples
Get
Shell
// A query without the HotOnly hint may scan cold data. hbase(main):013:0> get 'chsTable', 'row1' // A query with the HotOnly hint scans only hot storage. If row1 is in cold storage, no result is returned. hbase(main):015:0> get 'chsTable', 'row1', {HOT_ONLY=>true} // A query with a TimeRange. The system compares the TimeRange with the COLD_BOUNDARY to determine which storage area to query. Note: The TimeRange unit is milliseconds for the timestamp. hbase(main):016:0> get 'chsTable', 'row1', {TIMERANGE => [0, 1568203111265]}Java
Table table = connection.getTable("chsTable"); // A query without the HotOnly hint may scan cold data. Get get = new Get("row1".getBytes()); System.out.println("result: " + table.get(get)); // A query with the HotOnly hint scans only hot storage. If row1 is in cold storage, no result is returned. get = new Get("row1".getBytes()); get.setAttribute(AliHBaseConstants.HOT_ONLY, Bytes.toBytes(true)); // A query with a TimeRange. The system compares the TimeRange with the COLD_BOUNDARY to determine which storage area to query. Note: The TimeRange unit is milliseconds for the timestamp. get = new Get("row1".getBytes()); get.setTimeRange(0, 1568203111265)
Scan
If a scan does not include the HOT_ONLY hint or if its TimeRange covers the cold data period, the operation accesses both hot and cold data in parallel and merges the results.
Shell
// A query without the HotOnly hint may scan cold data. hbase(main):017:0> scan 'chsTable', {STARTROW =>'row1', STOPROW=>'row9'} // A query with the HotOnly hint scans only hot storage. hbase(main):018:0> scan 'chsTable', {STARTROW =>'row1', STOPROW=>'row9', HOT_ONLY=>true} // A query with a TimeRange. The system compares the TimeRange with the COLD_BOUNDARY to determine which storage area to query. Note: The TimeRange unit is milliseconds for the timestamp. hbase(main):019:0> scan 'chsTable', {STARTROW =>'row1', STOPROW=>'row9', TIMERANGE => [0, 1568203111265]}
Java
TableName tableName = TableName.valueOf("chsTable"); Table table = connection.getTable(tableName); // A query without the HotOnly hint may scan cold data. Scan scan = new Scan(); ResultScanner scanner = table.getScanner(scan); for (Result result : scanner) { System.out.println("scan result:" + result); } // A query with the HotOnly hint scans only hot storage. scan = new Scan(); scan.setAttribute(AliHBaseConstants.HOT_ONLY, Bytes.toBytes(true)); // A query with a TimeRange. The system compares the TimeRange with the COLD_BOUNDARY to determine which storage area to query. Note: The TimeRange unit is milliseconds for the timestamp. scan = new Scan(); scan.setTimeRange(0, 1568203111265);
Cold storage in a table with hot and cold data separation is intended only for data archival and should be queried infrequently. Most queries on such tables should include the
HOT_ONLYhint or aTimeRangethat covers only hot storage. If you find that a large number of requests are querying cold data, consider whether yourCOLD_BOUNDARYsetting is appropriate.If a row is already in cold storage and you update it, the updated fields are written to hot storage. If you then query this row using the
HOT_ONLYhint (or aTimeRangecovering only hot storage), only the updated fields from hot storage are returned. To retrieve the complete row, you must query without theHOT_ONLYhint and without aTimeRange, or ensure theTimeRangecovers both the original insertion time and the update time. Therefore, we recommend avoiding updates to data that has moved to cold storage. If you frequently need to update cold data, reconsider yourCOLD_BOUNDARYsetting.
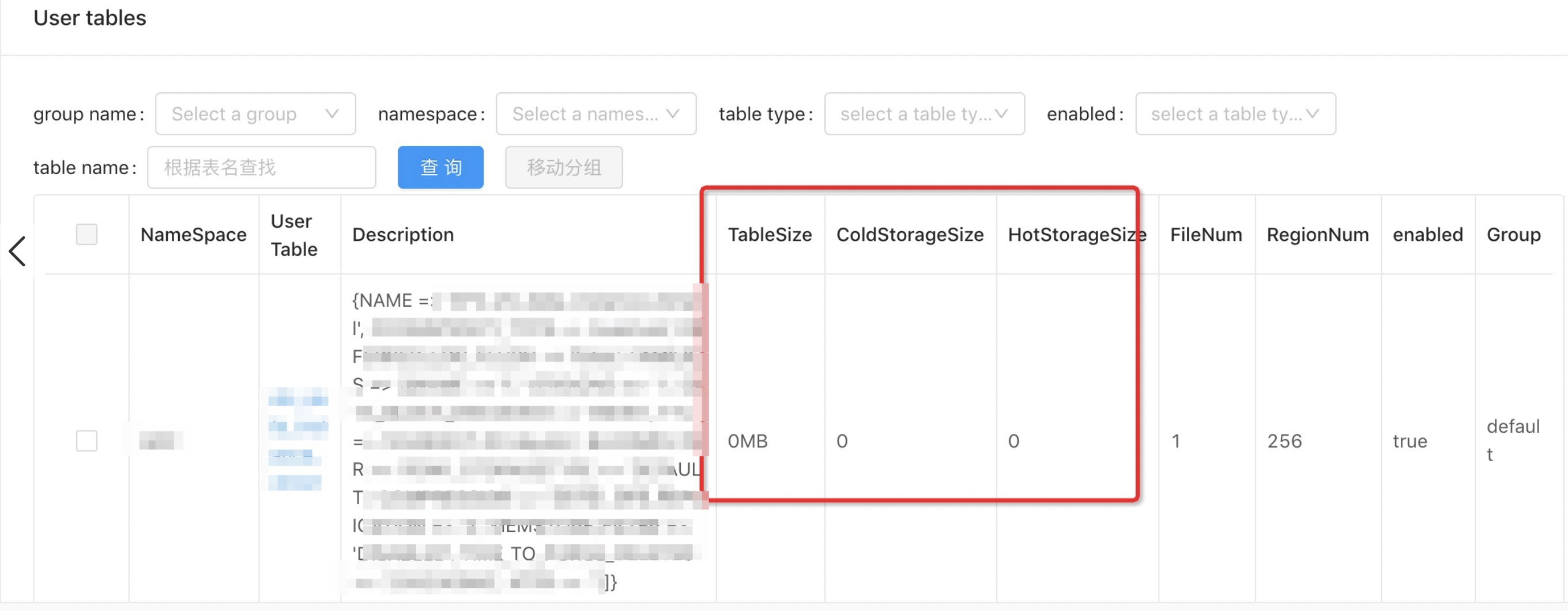
View hot and cold data size
In ClusterManager, on the User tables tab, you can view the hot and cold storage sizes for a specific table.
If data has not yet moved to cold storage, it might still be in RAM. Execute the flush command to write the data to disk, and then run a major compaction. Check the storage size again after the compaction is complete.
Prioritize querying hot data
In range scan (Scan) scenarios, such as querying all orders or chat history for a user, the query may span both hot and cold storage. However, results are often displayed in paginated form from newest to oldest, with the most recent (hot) data shown first. In this scenario, a standard Scan (without HOT_ONLY) scans hot and cold data in parallel, which can decrease request performance. By enabling hot data priority, the system queries only hot data first. It queries cold data only if the number of hot data results is insufficient (for example, when a user clicks to view the next page). This reduces access to cold storage and improves response time.
To enable hot data priority, set the COLD_HOT_MERGE attribute on your Scan. This attribute instructs the system to query hot storage first. The system queries cold data only after all hot storage data has been retrieved and the client continues to call next for more results.
Shell
hbase(main):002:0> scan 'chsTable', {COLD_HOT_MERGE=>true}Java
scan = new Scan();
scan.setAttribute(AliHBaseConstants.COLD_HOT_MERGE, Bytes.toBytes(true));
scanner = table.getScanner(scan);If a row contains both hot and cold data (for example, some columns are in hot storage and others are in cold storage due to partial updates), enabling hot data priority causes the query result for that row to be returned in two parts. This means the
Resultset returned by the scanner will contain twoResultobjects for the same Rowkey.Because hot data is returned before cold data, enabling hot data priority means the overall
Resultset from the Scan is not guaranteed to be ordered by Rowkey. For example, the Rowkey of a cold data result returned later may be lexicographically smaller than the Rowkey of a hot data result returned earlier. However, the results within the hot data set and the cold data set are each ordered by Rowkey (see the demo below). In some practical use cases, you can design your Rowkey to ensure the scan results remain ordered. For example, in an order history table, you can use a Rowkey format ofUserID + OrderCreationTimeto ensure that a scan of a specific user's orders returns them sorted.
// Assume the row with rowkey "coldRow" is cold data, and the row with rowkey "hotRow" is hot data.
// Normally, because HBase rows are sorted lexicographically, the "coldRow" row is returned before the "hotRow" row.
hbase(main):001:0> scan 'chsTable'
ROW COLUMN+CELL
coldRow column=f:value, timestamp=1560578400000, value=cold_value
hotRow column=f:value, timestamp=1565848800000, value=hot_value
2 row(s)
// When COLD_HOT_MERGE is set, the scan's rowkey order is broken. Hot data is returned before cold data, so "hotRow" appears before "coldRow" in the results.
hbase(main):002:0> scan 'chsTable', {COLD_HOT_MERGE=>true}
ROW COLUMN+CELL
hotRow column=f:value, timestamp=1565848800000, value=hot_value
coldRow column=f:value, timestamp=1560578400000, value=cold_value
2 row(s)