The HBase API-compatible secondary index feature has several limitations and is no longer maintained. We do not recommend it for new users. We recommend that you use secondary indexes through Lindorm SQL. For more information, see Secondary indexes.
Introduction
HBase natively provides a primary key index, which sorts data based on the binary order of the rowkey. You can use this rowkey index to efficiently perform full row matches, prefix matches, and range queries. However, if you need to query data based on columns other than the rowkey, you must use a filter to scan rows within a specified rowkey range. If you cannot specify a rowkey range, a full table scan is required. This process consumes significant resources and can result in high query response times (RT).
Several solutions can address the multi-dimensional query problem in HBase. For example, you can create a separate table that is indexed by the columns you want to query, and then maintain this secondary index yourself. Another way is to export data to an external system like Solr or Elasticsearch for indexing.
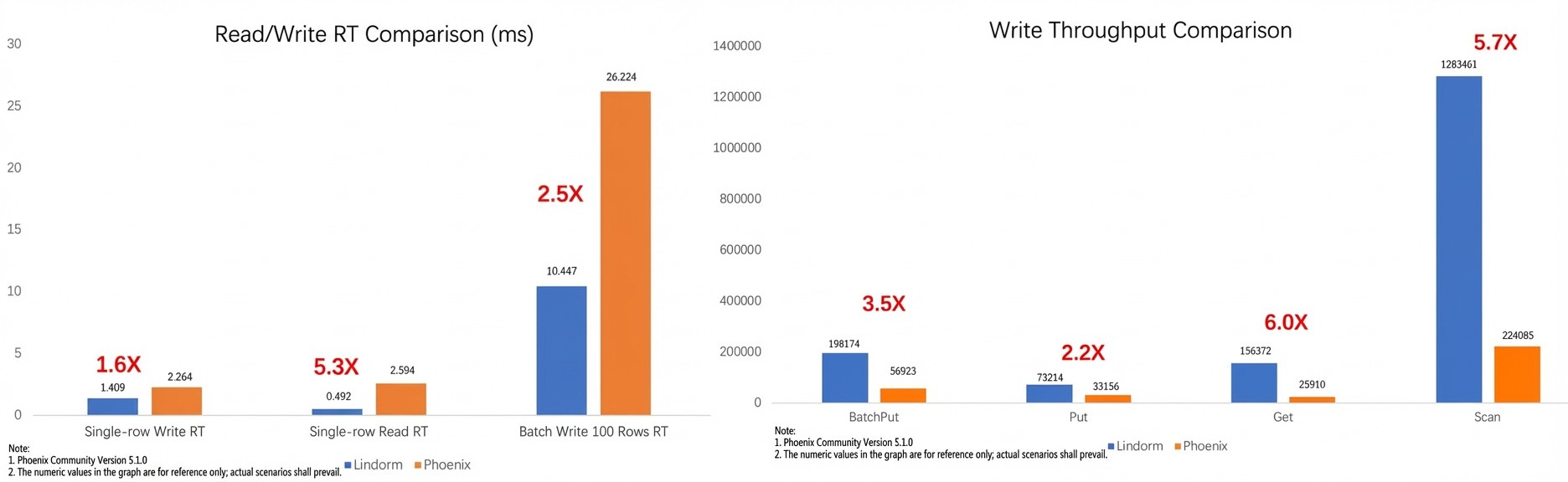
While powerful, search engines like Solr or Elasticsearch can be overkill for scenarios with a small number of columns and fixed query patterns. To address these scenarios more efficiently, ApsaraDB for HBase Performance-enhanced Edition introduces a native, global secondary index solution. This built-in feature provides high throughput and performance at a lower cost. Proven effective over many years at Alibaba for large-scale events like the Double 11 Global Shopping Festival, this indexing solution is ideal for global indexing of massive datasets. The following figure compares the indexing performance of ApsaraDB for HBase Performance-enhanced Edition with Phoenix.