Compaction triggered by bulk data loads has historically consumed dedicated instance resources, competing with queries and reducing instance stability. Starting with Hologres V3.1.11, you can offload compaction to serverless resources so it runs concurrently with the import without touching your instance's virtual warehouse.
How it works
When the feature is enabled, the compaction triggered by a bulk load runs on serverless resources instead of the instance's dedicated resources. This protects the performance of other operations.
Enable compaction offload
Set hg_serverless_computing_run_compaction_before_commit_bulk_load to on. The setting takes effect at the level where it is applied.
Configuration commands
Level | Command |
Session |
|
User |
|
Database |
|
Parameter reference
Attribute | Value |
Type | Boolean |
Values |
|
Scope | Session, user, or database |
Limitations
Import time: Enabling this option slightly increases data import time, but significantly improves instance stability under concurrent load.
Scope: Concurrent compaction applies only to bulk data imports. Cleanup of outdated data during compaction still uses dedicated instance resources.
Storage tier: Concurrent compaction applies only to data imported into hot storage (Standard tier). Data imported into cold storage (Infrequent Access tier) is not affected.
Example
This example uses the public dataset import feature in HoloWeb to import the TPC-H 100 GB dataset. Running the same import with and without concurrent compaction lets you compare the effect on instance resource consumption.
Disable concurrent compaction at the database level and run a data import task.
ALTER DATABASE <db_name> SET hg_serverless_computing_run_compaction_before_commit_bulk_load = off;Enable concurrent compaction at the database level and run the data import task again.
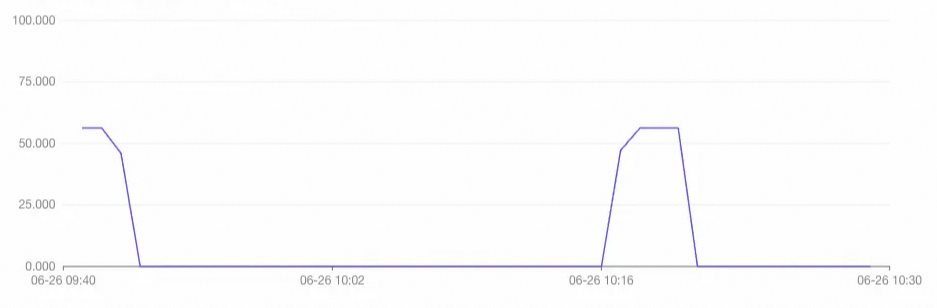
ALTER DATABASE <db_name> SET hg_serverless_computing_run_compaction_before_commit_bulk_load = on;After both imports complete, check the instance monitoring metrics. The charts below confirm that with concurrent compaction enabled, the import task uses serverless resources as expected, and the compaction task consumes no dedicated resources from the virtual warehouse.
CPU utilization of the virtual warehouse
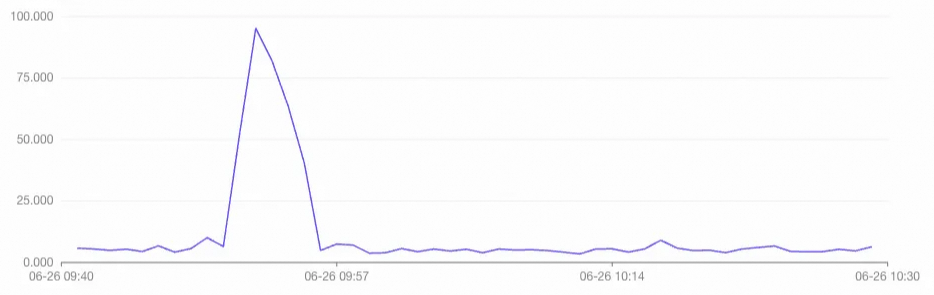
QPS of import tasks
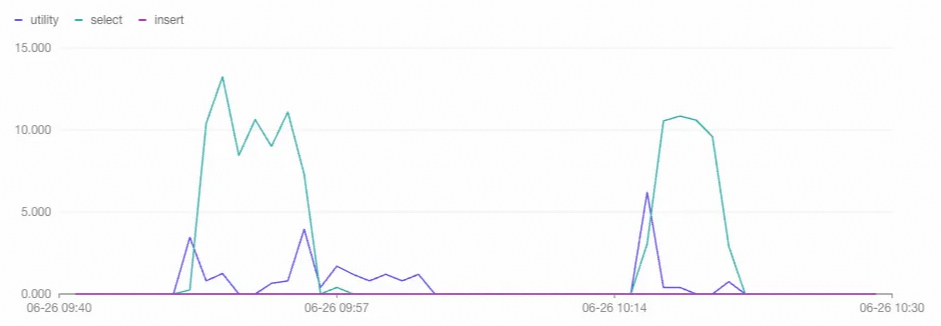
Serverless resource utilization