Data skew causes some workers to process significantly more data than others, slowing down or stalling distributed jobs. Learn how to identify data skew in MaxCompute and apply solutions for common scenarios involving JOIN, GROUP BY, COUNT(DISTINCT), ROW_NUMBER(), and dynamic partitions.
MapReduce
MapReduce is a distributed computing framework that breaks large problems into smaller subproblems, solves them independently, and merges the results. It abstracts the complexities of a distributed cluster — data storage, inter-node communication, and data transfer — so you can write parallel programs without managing low-level infrastructure. Understanding MapReduce is essential to diagnosing data skew.
The following diagram illustrates the MapReduce workflow: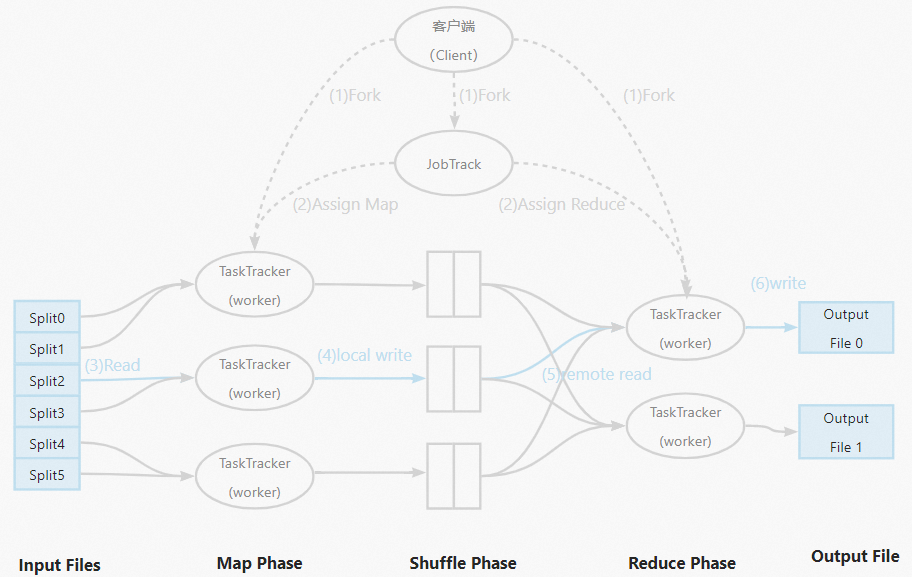
Data skew
Data skew typically occurs at the Reducer stage. While Mappers partition input files fairly evenly, the resulting data may be distributed unevenly across workers. Some workers finish quickly while others receive a disproportionate share and take much longer. Most real-world data is skewed, often following the 80/20 rule — for example, 20% of forum users may contribute 80% of posts, or 20% of users may account for 80% of site traffic. At Big Data scale, this imbalance can severely degrade performance, often causing a job to appear stuck at 99% progress.
Identify data skew
In MaxCompute, you can use Logview to identify data skew. The procedure is as follows:
-
In Fuxi Jobs, sort job stages by Latency in descending order and select the job stage with the longest runtime.
-
In the Fuxi instance list for the selected stage, sort the instances by Latency in descending order. Select the instance with a runtime significantly longer than the average, which is typically the first one in the list. Then, check its StdOut log.
-
Use the StdOut log to view the job execution graph.
-
Use the key information from the job execution graph to locate the SQL snippet causing the data skew.
The following example demonstrates this procedure.
-
Find the Logview URL in the task's operational logs. For more information, see Logview entry points.
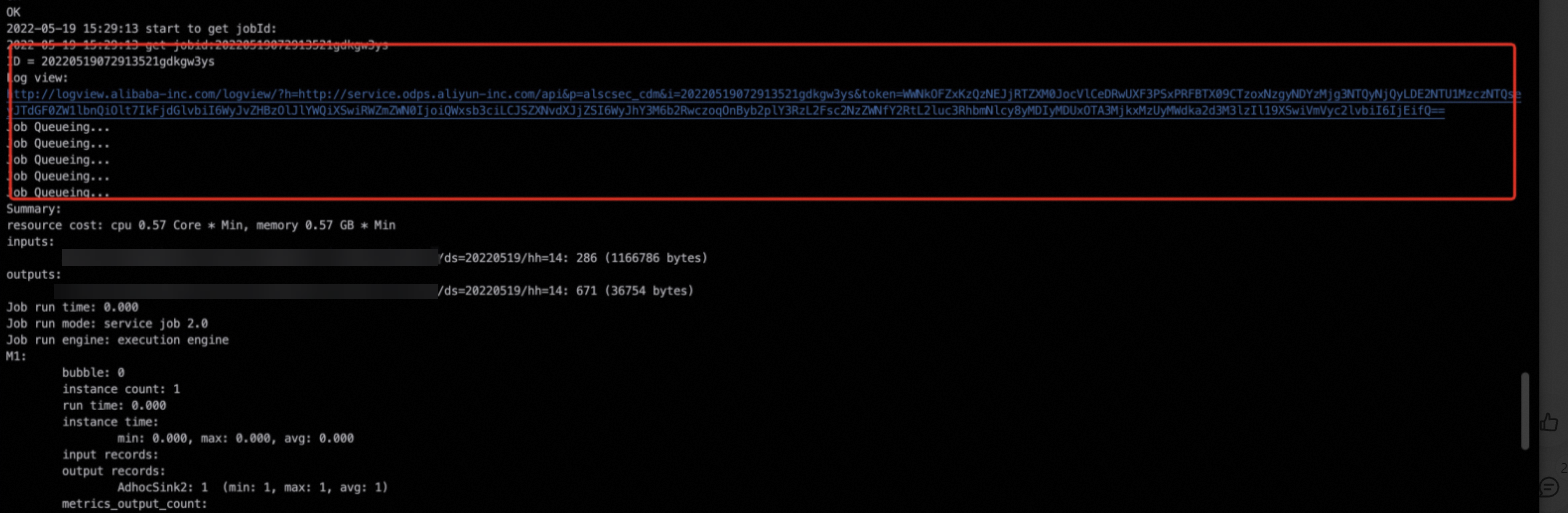
-
On the Logview page, sort Fuxi tasks by Latency in descending order and select the one with the longest runtime to quickly identify the problem.
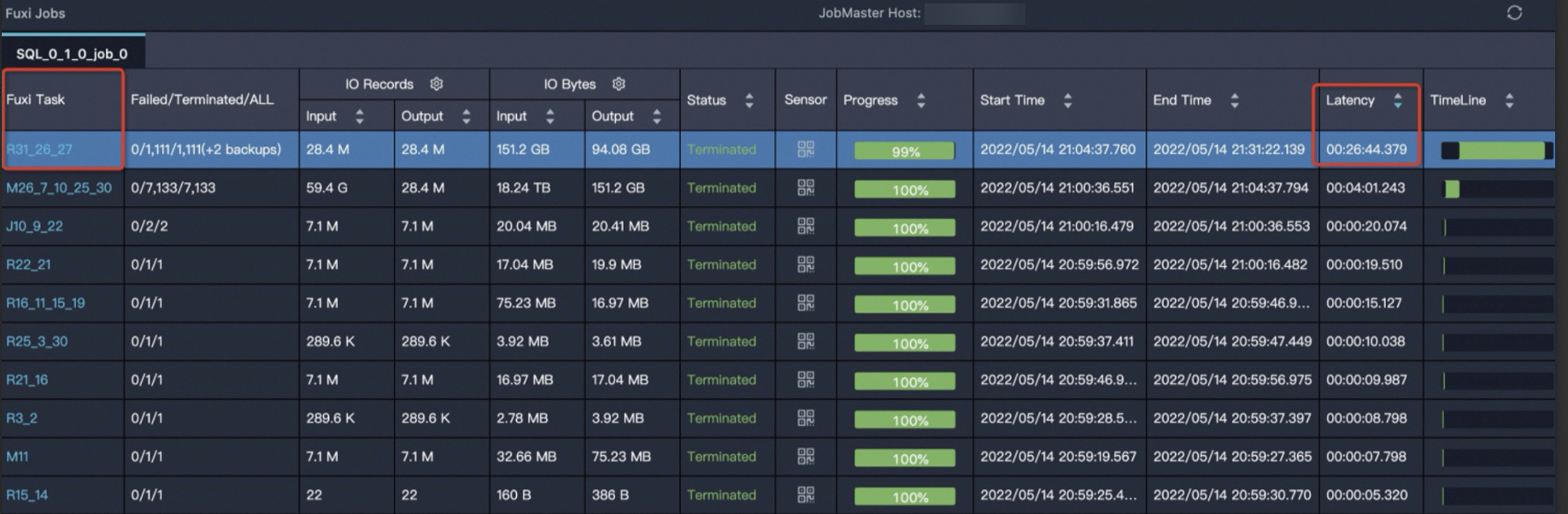
-
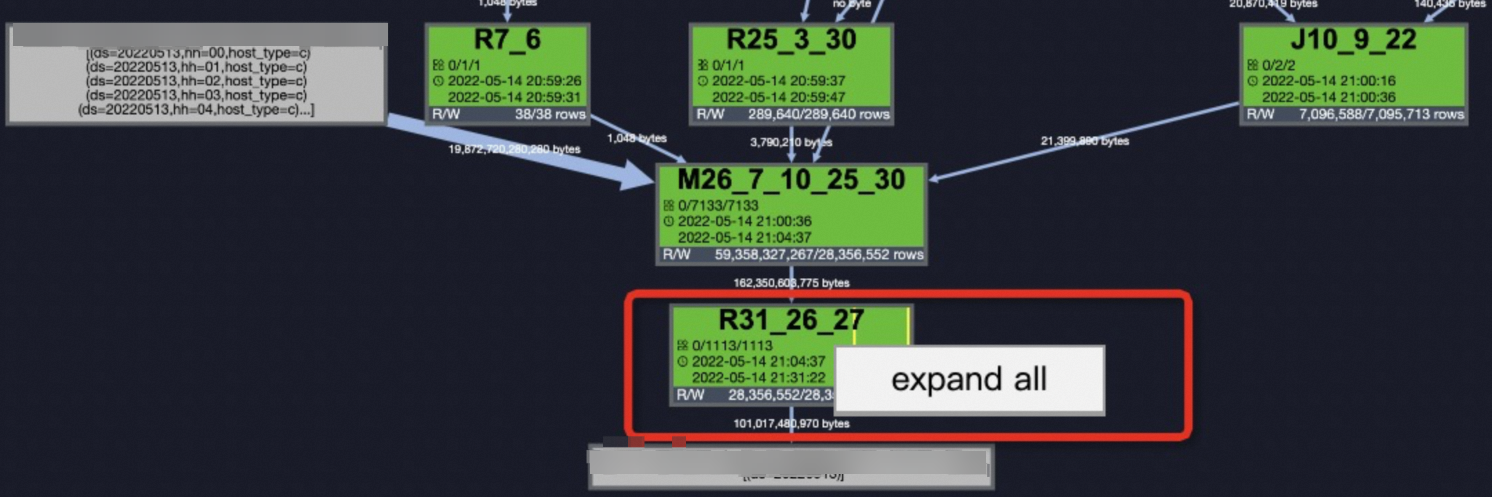
The
R31_26_27task has the longest latency. Click theR31_26_27task to go to the instance details page, as shown in the following figure.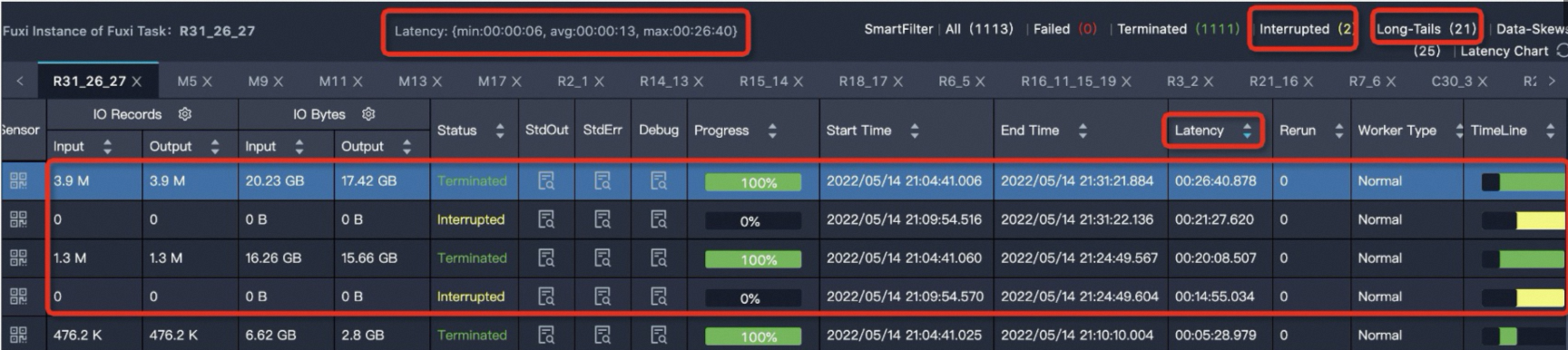
Latency: {min:00:00:06, avg:00:00:13, max:00:26:40}indicates that for all instances of the task, the minimum latency is6s, the average latency is13s, and the maximum latency is26 minutes and 40s. You can sort the instances byLatencyin descending order to view four instances with relatively long latencies. MaxCompute identifies a Fuxi Instance as a long-tail instance if its latency is more than twice the average value. This means that task instances with a latency greater than26sare identified as long-tail instances (Long-Tails). In this case, 21 instances have a latency greater than26s. The presence of Long-Tails instances does not necessarily indicate data skew. You also need to compare theavgandmaxvalues of the instance latency. For tasks where themaxvalue is much greater than theavgvalue, which indicates severe data skew, you need to optimize these tasks. -
Click the
 icon in the StdOut column to view the StdOut log, as shown in the following example.
icon in the StdOut column to view the StdOut log, as shown in the following example. -
After you identify the issue, on the Job Details tab, right-click
R31_26_27and select expand all to expand the task. For more information, see Using Logview 2.0 to View Job Runtime Information.Examine StreamLineWriter21, which is the step beforeStreamLineRead22, to locate the keys that are causing the data skew:new_uri_path_structure,cookie_x5check_userid, andcookie_userid. This process also helps you locate the SQL fragment that is causing the data skew.
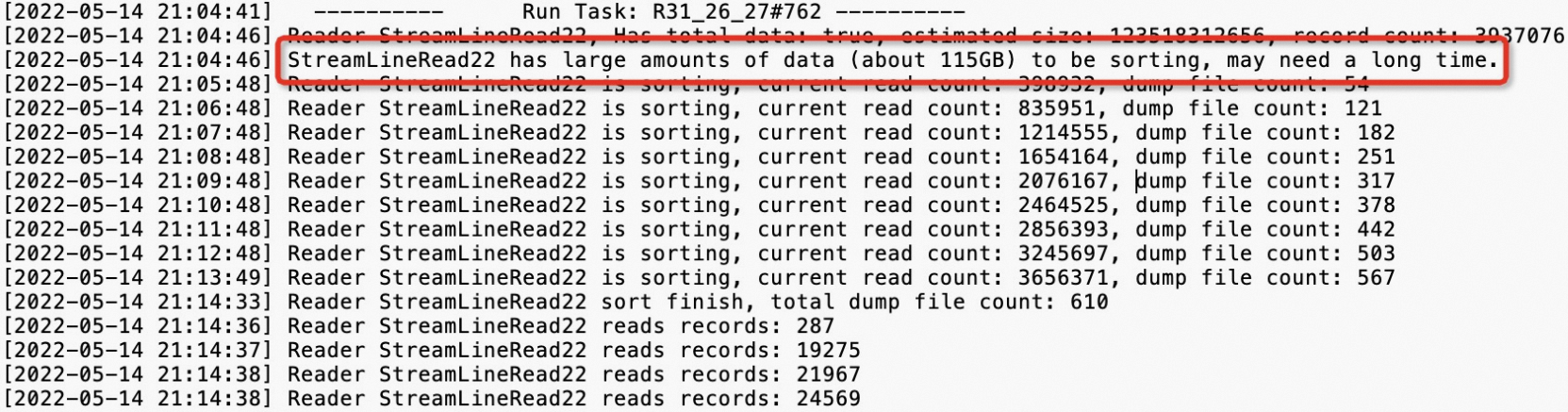
 Examine
Examine 
Troubleshooting data skew
Common operations that cause data skew include:
-
join
-
group by
-
count(distinct)
-
row_number() (TopN)
-
dynamic partition
These are ranked by frequency as follows: join > group by > count(distinct) > row_number() > dynamic partition.
Join
Data skew in join operations occurs in several scenarios: joining a large table with a small table, joining a large table with a medium table, or encountering hot values that create a long tail.
-
Joining a large table with a small table
-
Example of data skew
In the following example,
t1is a large table, andt2andt3are small tables.SELECT t1.ip ,t1.is_anon ,t1.user_id ,t1.user_agent ,t1.referer ,t2.ssl_ciphers ,t3.shop_province_name ,t3.shop_city_name FROM <viewtable> t1 LEFT OUTER JOIN <other_viewtable> t2 ON t1.header_eagleeye_traceid = t2.eagleeye_traceid LEFT OUTER JOIN ( SELECT shop_id ,city_name AS shop_city_name ,province_name AS shop_province_name FROM <tenanttable> WHERE ds = MAX_PT('<tenanttable>') AND is_valid = 1 ) t3 ON t1.shopid = t3.shop_id -
Solution
Use the MAPJOIN hint syntax, as shown in the following example.
SELECT /*+ mapjoin(t2,t3)*/ t1.ip ,t1.is_anon ,t1.user_id ,t1.user_agent ,t1.referer ,t2.ssl_ciphers ,t3.shop_province_name ,t3.shop_city_name FROM <viewtable> t1 LEFT OUTER JOIN (<other_viewtable>) t2 ON t1.header_eagleeye_traceid = t2.eagleeye_traceid LEFT OUTER JOIN ( SELECT shop_id ,city_name AS shop_city_name ,province_name AS shop_province_name FROM <tenanttable> WHERE ds = MAX_PT('<tenanttable>') AND is_valid = 1 ) t3 ON t1.shopid = t3.shop_id-
Notes
-
When you reference a small table or a subquery, you must use its alias.
-
MapJoin supports using a subquery as the small table.
-
In a MapJoin, you can use non-equi joins or
orto connect multiple conditions. To compute a cartesian product, omit theonclause and use amapjoin on 1 = 1condition. For example:select /*+ mapjoin(a) */ a.id from shop a join table_name b on 1=1;. However, this operation can cause significant data expansion. -
In a MAPJOIN hint, separate multiple small tables with a comma (
,). For example:/*+ mapjoin(a,b,c)*/. -
In a MapJoin, MaxCompute loads the entire specified table into memory during the Map stage. Therefore, the specified table must be a small table. Because MaxCompute uses compressed storage, data can expand significantly when loaded. This expanded in-memory size cannot exceed 512 MB. You can increase this limit to a maximum of 8192 MB by setting the following parameter:
SET odps.sql.mapjoin.memory.max=2048;
-
-
Limitations on MapJoin operations
-
For a
left outer join, the left table must be the large table. -
For a
right outer join, the right table must be the large table. -
full outer joinis not supported. -
For an
inner join, either the left or the right table can be the large table. -
MapJoin supports a maximum of 128 small tables. Exceeding this limit causes a syntax error.
-
-
-
-
Joining a large table with a medium table
-
Example of data skew
In the following example,
t0is a large table, andt1is a medium table.SELECT request_datetime ,host ,URI ,eagleeye_traceid FROM <viewtable> t0 LEFT JOIN ( SELECT traceid, eleme_uid, isLogin_is FROM <servicetable> WHERE ds = '${today}' AND hh = '${hour}' ) t1 ON t0.eagleeye_traceid = t1.traceid WHERE ds = '${today}' AND hh = '${hour}' -
Solution
Use the DISTRIBUTED MAPJOIN syntax to resolve data skew, as shown in the following example.
SELECT /*+distmapjoin(t1)*/ request_datetime ,host ,URI ,eagleeye_traceid FROM <viewtable> t0 LEFT JOIN ( SELECT traceid, eleme_uid, isLogin_is FROM <servicetable> WHERE ds = '${today}' AND hh = '${hour}' ) t1 ON t0.eagleeye_traceid = t1.traceid WHERE ds = '${today}' AND hh = '${hour}'
-
-
Long tail of hot values in a join
-
Example of data skew
In the following query, the
eleme_uidcolumn has many hot values, which often causes data skew.SELECT eleme_uid, ... FROM ( SELECT eleme_uid, ... FROM <viewtable> )t1 LEFT JOIN( SELECT eleme_uid, ... FROM <customertable> ) t2 ON t1.eleme_uid = t2.eleme_uid; -
Solution
You can use one of the following four methods to resolve this issue.
ID
Method
Description
Method 1
Manually split hot values
Identify the hot values. Filter records containing these values from the main table and perform a MapJoin on them. Then, perform a standard join on the remaining records with non-hot values. Finally, combine the results of both joins using
UNION ALL.Method 2
Set SkewJoin parameters
Enable SkewJoin with the command:
set odps.sql.skewjoin=true;.Method 3
SkewJoin hint
Use the hint:
/*+ skewJoin(<table_name>[(<column1_name>[,<column2_name>,...])][((<value11>,<value12>)[,(<value21>,<value22>)...])]*/. This method adds a step to find skewed keys, which can increase query runtime. If you already know the skewed keys, you can save time by setting the SkewJoin parameters directly.Method 4
Modulo join with a multiplier table
Use a multiplier table to redistribute join keys.
-
Manually split hot values
After identifying the hot values, filter the records with these values from the main table. Perform a MapJoin on these records, then perform a standard join on the remaining records. Finally, combine the results of both joins using
UNION ALL. The following code provides an example:SELECT /*+ MAPJOIN (t2) */ eleme_uid, ... FROM ( SELECT eleme_uid, ... FROM <viewtable> WHERE eleme_uid = <skewed_value> )t1 LEFT JOIN( SELECT eleme_uid, ... FROM <customertable> WHERE eleme_uid = <skewed_value> ) t2 ON t1.eleme_uid = t2.eleme_uid UNION ALL SELECT eleme_uid, ... FROM ( SELECT eleme_uid, ... FROM <viewtable> WHERE eleme_uid != <skewed_value> )t3 LEFT JOIN( SELECT eleme_uid, ... FROM <customertable> WHERE eleme_uid != <skewed_value> ) t4 ON t3.eleme_uid = t4.eleme_uid -
Set SkewJoin parameters
This is a common solution. Although you can enable the SkewJoin feature in MaxCompute by running the
set odps.sql.skewjoin=true;command, it has no effect on task execution by itself. For the feature to take effect, you must also set theodps.sql.skewinfoparameter. Theodps.sql.skewinfoparameter is used to configure specific details for join optimization. The following example shows the command syntax.SET odps.sql.skewjoin=true; SET odps.sql.skewinfo=skewed_src:(skewed_key)[("skewed_value")]; --skewed_src is the skewed table, and skewed_value is the hot value.Usage examples:
-- For a single skewed value in a single column SET odps.sql.skewinfo=src_skewjoin1:(key)[("0")]; -- For multiple skewed values in a single column SET odps.sql.skewinfo=src_skewjoin1:(key)[("0")("1")]; -
SkewJoin hint
Add the following hint to your
SELECTstatement:/*+ skewJoin(<table_name>[(<column1_name>[,<column2_name>,...])][((<value11>,<value12>)[,(<value21>,<value22>)...])]*/. In this hint,table_nameis the name of the skewed table,column_nameis the name of the skewed column, andvalueis the skewed key value. The following examples show how to use this hint.-- Method 1: Hint the table name. Note that you must hint the table's alias. SELECT /*+ skewjoin(a) */ * FROM T0 a JOIN T1 b ON a.c0 = b.c0 AND a.c1 = b.c1; -- Method 2: Hint the table name and the columns that you suspect are skewed. For example, columns c0 and c1 in table 'a' are skewed. SELECT /*+ skewjoin(a(c0, c1)) */ * FROM T0 a JOIN T1 b ON a.c0 = b.c0 AND a.c1 = b.c1 AND a.c2 = b.c2; -- Method 3: Hint the table name, columns, and provide the skewed key values. If a key is a STRING type, enclose it in quotation marks. For example, values where (a.c0=1 and a.c1="2") and (a.c0=3 and a.c1="4") are skewed. SELECT /*+ skewjoin(a(c0, c1)((1, "2"), (3, "4"))) */ * FROM T0 a JOIN T1 b ON a.c0 = b.c0 AND a.c1 = b.c1 AND a.c2 = b.c2;NoteSpecifying skewed values directly in a SkewJoin hint is more efficient than manually splitting hot values or enabling SkewJoin without providing the values.
Join types supported by the SkewJoin hint:
-
For an inner join, you can hint either table in the join.
-
For a left join, semi-join, or anti-join, you can only hint the left table.
-
For a right join, you can only hint the right table.
-
The SkewJoin hint is not supported for a full join.
Use this hint only for joins with known data skew, as it introduces some overhead by running an aggregation query.
The data types of the join keys on the left side of the join must match the data types of the join keys on the right side. Otherwise, the SkewJoin hint does not take effect. For example, the data type of
a.c0must match the data type ofb.c0, and the data type ofa.c1must match the data type ofb.c1. You can cast the join keys in a subquery to ensure that their data types match. The following is an example:CREATE TABLE T0(c0 int, c1 int, c2 int, c3 int); CREATE TABLE T1(c0 string, c1 int, c2 int); -- Method 1: SELECT /*+ skewjoin(a) */ * FROM T0 a JOIN T1 b ON cast(a.c0 AS string) = cast(b.c0 AS string) AND a.c1 = b.c1; -- Method 2: SELECT /*+ skewjoin(b) */ * FROM (SELECT cast(a.c0 AS string) AS c00 FROM T0 a) b JOIN T1 c ON b.c00 = c.c0;When you add a SkewJoin hint, the optimizer runs an Aggregate operation to retrieve the top 20 hot values.
20is the default value, and you can change it by running theset odps.optimizer.skew.join.topk.num = xx;command.-
The SkewJoin hint can only be applied to one side of the join.
-
A hinted Join must have a
left key = right keycondition. Cartesian product Joins are not supported. -
You cannot add a SkewJoin hint to a join that already uses a MAPJOIN hint.
-
-
Modulo join with a multiplier table
This solution uses a different approach. Instead of divide and conquer, it creates a multiplier table with a single
intcolumn containing values from 1 to N, where N reflects the degree of skew. The multiplier table expands the user behavior table by N times, and the join then uses two keys: the user ID andnumber. Adding thenumberkey reduces skew caused by a single user ID to1/Nof its original level, at the cost of expanding data by N times.SELECT eleme_uid, ... FROM ( SELECT eleme_uid, ... FROM <viewtable> )t1 LEFT JOIN( SELECT /*+mapjoin(<multipletable>)*/ eleme_uid, number ... FROM <customertable> JOIN <multipletable> ) t2 ON t1.eleme_uid = t2.eleme_uid AND mod(t1.<value_col>,10)+1 = t2.number;You can also limit the inflation to hotspot records only, leaving non-hotspot records unchanged. First, identify the hotspot values. Then, add a column named
eleme_uid_jointo both the traffic and user behavior tables. For hotspot user IDs,concatthe ID with a random integer from a predefined range (such as 0 to 1000); for other IDs, keep the original value. Useeleme_uid_joinas the join key. This reduces skew for hotspot values without inflating non-hotspot data. However, the resulting SQL becomes much harder to read and maintain, so this method is not recommended.
-
-
Group by
The following sample query uses a Group By clause.
SELECT shop_id
,sum(is_open) AS open_days
FROM table_xxx_di
WHERE dt BETWEEN '${bizdate_365}' AND '${bizdate}'
GROUP BY shop_id;To resolve data skew, use one of the following three solutions:
|
No. |
Solution |
Description |
|
Solution 1 |
Set the parameter to handle |
|
|
Solution 2 |
Add a random number |
Split the keys that cause the long tail. |
|
Solution 3 |
Create a rollup table |
Reduces I/O and resource use by pre-aggregating data. |
-
Solution 1: Set the parameter to mitigate data skew in
Group Byoperations.SET MaxCompute.sql.groupby.skewindata=true; -
Solution 2: Add a random number.
Unlike Solution 1, this method requires rewriting the SQL query to add a random number. Splitting long-tail keys is a highly effective way to resolve
Group Bydata skew.For the query
Select Key,Count(*) As Cnt From TableName Group By Key;, without a Combiner, Mappers shuffle data to Reducers, which then perform theCOUNToperation. This corresponds to anM->Rexecution plan.If you have identified the long-tail key, you can redistribute its workload as follows:
-- Assume the long-tail key is 'KEY001' SELECT a.Key ,SUM(a.Cnt) AS Cnt FROM(SELECT Key ,COUNT(*) AS Cnt FROM <TableName> GROUP BY Key ,CASE WHEN KEY = 'KEY001' THEN Hash(Random()) % 50 ELSE 0 END ) a GROUP BY a.Key;The modified query changes the execution plan to
M->R->R. Although this adds a stage, the overall execution time can decrease because the skewed key is processed in two stages. The resource consumption and performance are similar to Solution 1. However, in real-world scenarios, there is often more than one skewed key. Considering the effort to identify skewed keys and rewrite the SQL, Solution 1 is cheaper to implement. -
Solution 3: Create a rollup table.
For core cost optimization, the primary requirement is to retrieve merchant data from the past year. For online tasks, reading all partitions from
T-1toT-365each time is a significant waste of resources. Creating a rollup table reduces the number of partitions that are read without affecting data retrieval for the past year. The following is an example.First, 365 days of merchant business data is initialized by using a Group By aggregation and saved as table
awith a marked update date. Subsequent online tasks are then switched to joining theT-2day tableawith thetable_xxx_ditable and performing another Group By aggregation. As a result, the amount of data read each day is reduced from 365 to 2 days, the duplication of the primary keyshopidis greatly reduced, and resource consumption is also lowered.--Create a rollup table CREATE TABLE IF NOT EXISTS m_xxx_365_df ( shop_id STRING COMMENT, last_update_ds COMMENT, 365d_open_days COMMENT ) PARTITIONED BY ( ds STRING COMMENT 'date partition' )LIFECYCLE 7; -- Assume the 365-day period is from 2021-05-01 to 2022-05-01. First, perform a one-time initialization. INSERT OVERWRITE TABLE m_xxx_365_df PARTITION(ds = '20220501') SELECT shop_id, max(ds) as last_update_ds, sum(is_open) AS 365d_open_days FROM table_xxx_di WHERE dt BETWEEN '20210501' AND '20220501' GROUP BY shop_id; -- The subsequent online job runs the following: INSERT OVERWRITE TABLE m_xxx_365_df PARTITION(ds = '${bizdate}') SELECT aa.shop_id, aa.last_update_ds, 365d_open_days - COALESCE(is_open, 0) AS 365d_open_days -- Prevents open days from rolling up indefinitely FROM ( SELECT shop_id, max(last_update_ds) AS last_update_ds, sum(365d_open_days) AS 365d_open_days FROM ( SELECT shop_id, ds AS last_update_ds, sum(is_open) AS 365d_open_days FROM table_xxx_di WHERE ds = '${bizdate}' GROUP BY shop_id UNION ALL SELECT shop_id, last_update_ds, 365d_open_days FROM m_xxx_365_df WHERE dt = '${bizdate_2}' AND last_update_ds >= '${bizdate_365}' GROUP BY shop_id ) GROUP BY shop_id ) AS aa LEFT JOIN ( SELECT shop_id, is_open FROM table_xxx_di WHERE ds = '${bizdate_366}' ) AS bb ON aa.shop_id = bb.shop_id;
Count(distinct)
Consider a table with the following data distribution.
|
Ds (partition) |
Cnt (record count) |
|
20220416 |
73025514 |
|
20220415 |
2292806 |
|
20220417 |
2319160 |
The following query is susceptible to data skew:
SELECT ds
,COUNT(DISTINCT shop_id) AS cnt
FROM demo_data0
GROUP BY ds;The following solutions address this issue:
|
No. |
Solution |
Description |
|
Solution 1 |
Parameter tuning |
|
|
Solution 2 |
General two-stage aggregation |
Append a random number to the partition field value. |
|
Solution 3 |
Manual two-stage aggregation |
First, apply a GROUP BY to both grouping fields |
-
Solution 1: Parameter tuning
Set the following parameter.
SET odps.sql.groupby.skewindata=true; -
Solution 2: General two-stage aggregation
If the data in the
shop_idfield is skewed, Solution 1 might not be effective. A more general method is to append a random number to the partition field value.-- Method 1: Append a random number, for example, CONCAT(ROUND(RAND(),1)*10,'_', ds) AS rand_ds SELECT SPLIT_PART(rand_ds, '_',2) ds ,COUNT(*) id_cnt FROM ( SELECT rand_ds ,shop_id FROM demo_data0 GROUP BY rand_ds,shop_id ) GROUP BY SPLIT_PART(rand_ds, '_',2); -- Method 2: Add a new random number column, for example, ROUND(RAND(),1)*10 AS randint10 SELECT ds ,COUNT(*) id_cnt FROM (SELECT ds ,randint10 ,shop_id FROM demo_data0 GROUP BY ds,randint10,shop_id ) GROUP BY ds; -
Solution 3: Manual two-stage aggregation
If data is evenly distributed across the ds and shop_id fields, you can optimize the query by first grouping by both fields and then using the
count(distinct)function.SELECT ds ,COUNT(*) AS cnt FROM(SELECT ds ,shop_id FROM demo_data0 GROUP BY ds ,shop_id ) GROUP BY ds;
ROW_NUMBER(): TopN
The following query retrieves the top 10 records.
SELECT main_id
,type
FROM (SELECT main_id
,type
,ROW_NUMBER() OVER(PARTITION BY main_id ORDER BY type DESC ) rn
FROM <data_demo2>
) A
WHERE A.rn <= 10;To resolve data skew, use one of the following solutions:
|
No. |
Solution |
Description |
|
Solution 1 |
Two-stage aggregation in SQL. |
Add a random column and use it as an additional partition key. |
|
Solution 2 |
Two-stage aggregation with a UDAF. |
Optimize the query by using a UDAF that implements a min-heap priority queue. |
-
Solution 1: Two-stage aggregation in SQL
To ensure data is distributed as evenly as possible across groups in the map phase, add a random column and use it as an additional partition key.
SELECT main_id ,type FROM (SELECT main_id ,type ,ROW_NUMBER() OVER(PARTITION BY main_id ORDER BY type DESC ) rn FROM (SELECT main_id ,type FROM (SELECT main_id ,type ,ROW_NUMBER() OVER(PARTITION BY main_id,src_pt ORDER BY type DESC ) rn FROM (SELECT main_id ,type ,ceil(110 * rand()) % 11 AS src_pt FROM data_demo2 ) ) B WHERE B.rn <= 10 ) ) A WHERE A.rn <= 10; -- 2. An alternative implementation: SELECT main_id ,type FROM (SELECT main_id ,type ,ROW_NUMBER() OVER(PARTITION BY main_id ORDER BY type DESC ) rn FROM (SELECT main_id ,type FROM(SELECT main_id ,type ,ROW_NUMBER() OVER(PARTITION BY main_id,src_pt ORDER BY type DESC ) rn FROM (SELECT main_id ,type ,ceil(10 * rand()) AS src_pt FROM data_demo2 ) ) B WHERE B.rn <= 10 ) ) A WHERE A.rn <= 10; -
Solution 2: Two-stage aggregation with a UDAF
The SQL approach can be verbose and hard to maintain. A cleaner alternative is a UDAF that implements a min-heap priority queue, retaining only the TopN elements in the
iteratephase and merging only N elements in themergephase. The process is as follows.-
iterate: Pushes the first K elements. Then, each subsequent element is compared with the smallest element at the top of the heap and swapped with an element in the heap. -
merge: Merges two heaps in-place and returns the top K elements. -
terminate: Returns the heap as an array. -
The SQL query then uses
LATERAL VIEW EXPLODEto unnest the array into separate rows.
@annotate('* -> array<string>') class GetTopN(BaseUDAF): def new_buffer(self): return [[], None] def iterate(self, buffer, order_column_val, k): # heapq.heappush(buffer, order_column_val) # buffer = [heapq.nlargest(k, buffer), k] if not buffer[1]: buffer[1] = k if len(buffer[0]) < k: heapq.heappush(buffer[0], order_column_val) else: heapq.heappushpop(buffer[0], order_column_val) def merge(self, buffer, pbuffer): first_buffer, first_k = buffer second_buffer, second_k = pbuffer k = first_k or second_k merged_heap = first_buffer + second_buffer merged_heap.sort(reverse=True) merged_heap = merged_heap[0: k] if len(merged_heap) > k else merged_heap buffer[0] = merged_heap buffer[1] = k def terminate(self, buffer): return buffer[0] SET odps.sql.python.version=cp37; SELECT main_id,type_val FROM ( SELECT main_id ,get_topn(type, 10) AS type_array FROM data_demo2 GROUP BY main_id ) LATERAL VIEW EXPLODE(type_array)type_ar AS type_val; -
Dynamic partition
Dynamic partitioning lets you insert data into a partitioned table by specifying a partition column name without providing its value. The value is instead derived from the corresponding column in the SELECT clause. Consequently, the specific partitions that will be created are unknown until the SQL statement executes. The system creates new partitions only after the statement finishes, based on the values generated for the partition column. For more information, see Insert or overwrite data in dynamic partitions (DYNAMIC PARTITION). The following is an example.
CREATE TABLE total_revenues (revenue bigint) partitioned BY (region string);
INSERT overwrite TABLE total_revenues PARTITION(region)
SELECT total_price AS revenue,region
FROM sale_detail;Tables with dynamic partitions are common and prone to data skew. When data skew occurs, use the following solutions to resolve it.
|
No. |
Solution |
Description |
|
Solution 1 |
Parameter tuning |
Configure parameters to optimize performance. |
|
Solution 2 |
Pruning optimization |
Identify partitions with a high record count, prune them from the main job, and insert their data separately to resolve the issue. |
-
Solution 1: Parameter tuning
Dynamic partitioning distributes data into different partitions based on column values, eliminating the need for multiple
INSERT OVERWRITEstatements. This simplifies code when dealing with many partitions, but can also cause the small file problem.-
Example of data skew
Consider the following simple SQL statement as an example.
INSERT INTO TABLE part_test PARTITION(ds) SELECT * FROM part_test;Assume the job has K map instances and N target partitions.
ds=1 cfile1 ds=2 ... X ds=3 ... ds=nIn an extreme case, this can generate
K*Nsmall files, which places a significant management burden on the file system. To address this, MaxCompute introduces an additional reduce task that routes data for the same target partition to a single (or a few) reduce instances. This prevents excessive small files and is always the final reduce task in the job. The feature is enabled by default:SET odps.sql.reshuffle.dynamicpt=true;While this default setting prevents the small file problem and avoids job failures from too many files per instance, it can introduce data skew. The extra reduce task also consumes additional compute resources, so you must weigh these trade-offs carefully.
-
Solution
Enabling
set odps.sql.reshuffle.dynamicpt=true;solves the small file problem. However, if the number of target partitions is small and there is no risk of excessive small files, this setting wastes compute resources and degrades performance. Disabling it withset odps.sql.reshuffle.dynamicpt=false;can significantly improve performance, as shown in the following example.INSERT overwrite TABLE ads_tb_cornucopia_pool_d PARTITION (ds, lv, tp) SELECT /*+ mapjoin(t2) */ '20150503' AS ds, t1.lv AS lv, t1.type AS tp FROM (SELECT ... FROM tbbi.ads_tb_cornucopia_user_d WHERE ds = '20150503' AND lv IN ('flat', '3rd') AND tp = 'T' AND pref_cat2_id > 0 ) t1 JOIN (SELECT ... FROM tbbi.ads_tb_cornucopia_auct_d WHERE ds = '20150503' AND tp = 'T' AND is_all = 'N' AND cat2_id > 0 ) t2 ON t1.pref_cat2_id = t2.cat2_id;If you run the preceding code with the default parameter, the job takes about 1 hour and 30 minutes to complete. The final reduce task takes about 1 hour and 20 minutes, accounting for approximately
90%of the total runtime. The additional reduce task distributes data unevenly, leading to long-tail data skew.
Historical data shows that this job generates only about two dynamic partitions per day, so you can safely set
set odps.sql.reshuffle.dynamicpt=false;. With this change, the job completes in just 9 minutes — a dramatic improvement in performance and resource usage for a simple configuration change.This optimization applies to any job with a small number of dynamic partitions. Setting the
odps.sql.reshuffle.dynamicptparameter tofalsesaves resources and improves performance.You can optimize any node that meets all of the following conditions, regardless of its runtime:
-
The node uses dynamic partitioning.
-
The number of dynamic partitions is less than or equal to 50.
-
The parameter
odps.sql.reshuffle.dynamicptis not set tofalse.
You can determine the optimization urgency for a node based on the execution time of its last Fuxi Instance. The
diag_levelfield indicates urgency as follows:-
Last_Fuxi_Inst_Timeis greater than 30 minutes:Diag_Level=4 ('Severe'). -
Last_Fuxi_Inst_Timeis between 20 and 30 minutes:Diag_Level=3 ('High'). -
Last_Fuxi_Inst_Timeis between 10 and 20 minutes:Diag_Level=2 ('Medium'). -
Last_Fuxi_Inst_Timeis less than 10 minutes:Diag_Level=1 ('Low').
-
-
Solution 2: Pruning optimization
To address data skew that occurs in the map phase when inserting data with dynamic partitions, modify the map phase parameters as the following example shows:
SET odps.sql.mapper.split.size=128; INSERT OVERWRITE TABLE data_demo3 partition(ds,hh) SELECT * FROM dwd_alsc_ent_shop_info_hi;The results show that the job performs a full table scan. To further optimize this, disable the system-introduced reduce job, as the following example shows:
SET odps.sql.reshuffle.dynamicpt=false ; INSERT OVERWRITE TABLE data_demo3 partition(ds,hh) SELECT * FROM dwd_alsc_ent_shop_info_hi;To resolve data skew that occurs in the map phase when you use dynamic partitions to insert data, identify partitions with a large number of records, prune them from the main job, and insert them separately. Follow these steps:
-
Run the following command to find partitions with the highest record counts.
SELECT ds ,hh ,COUNT(*) AS cnt FROM dwd_alsc_ent_shop_info_hi GROUP BY ds ,hh ORDER BY cnt DESC;The following table shows some of the resulting partitions:
ds
hh
cnt
20200928
17
1052800
20191017
17
1041234
20210928
17
1034332
20190328
17
1000321
20210504
1
19
20191003
20
18
20200522
1
18
20220504
1
18
-
Use the following commands to first insert the data from the non-skewed partitions, and then insert the data from the skewed partitions in a separate statement.
SET odps.sql.reshuffle.dynamicpt=false ; INSERT OVERWRITE TABLE data_demo3 partition(ds,hh) SELECT * FROM dwd_alsc_ent_shop_info_hi WHERE CONCAT(ds,hh) NOT IN ('2020092817','2019101717','2021092817','2019032817'); set odps.sql.reshuffle.dynamicpt=false ; INSERT OVERWRITE TABLE data_demo3 partition(ds,hh) SELECT * FROM dwd_alsc_ent_shop_info_hi WHERE CONCAT(ds,hh) IN ('2020092817','2019101717','2021092817','2019032817'); SELECT ds ,hh,COUNT(*) AS cnt FROM dwd_alsc_ent_shop_info_hi GROUP BY ds,hh ORDER BY cnt desc;
-