JOIN operations are common in distributed systems, but they are also costly in terms of time and resources. The shuffle operation is particularly expensive in large-scale data scenarios. To address this, MaxCompute optimizes the shuffle operation by leveraging the properties of equi-joins.
How it works
A typical SQL statement that includes a JOIN is as follows:
SELECT * FROM (table1) A JOIN (table2) B ON A.a = B.b;In scenarios with small datasets, the dynamic filter takes effect only when used with MergeJoin. To ensure proper execution, set the following flags:
set odps.optimizer.enable.conditional.mapjoin=false;set odps.optimizer.cbo.rule.filter.black=hj;
Based on the equality conditions of a JOIN, MaxCompute can generate a filter from the data in Table A to filter data in Table B before a shuffle or JOIN operation. MaxCompute can even push the filter down to the underlying storage to filter data at the source. This feature of dynamically generating filters at runtime is called a dynamic filter (DF).
The following diagram shows the execution plan for the preceding SQL statement before and after the dynamic filter is enabled.

Use cases
The dynamic filter feature leverages the properties of equi-joins to generate filters at runtime. This allows data to be filtered before the shuffle or JOIN operation, thereby accelerating query execution. This feature is ideal for scenarios where a dimension table is joined with a fact table.
Dynamic range or Bloom filters
As shown in the preceding diagram, no filter exists in the original execution plan. The system automatically generates a filter based on the properties of the JOIN. This filter checks whether elements from table B exist in the set generated from table A and removes those that do not.
In practice, a dynamic filter can use a Bloom filter or other data filtering methods, such as a range filter based on [min, max] values or an IN predicate.
A dynamic filter follows a typical producer-consumer model, as shown in the following diagram.
DFP (Dynamic Filter Producer) operator: The producer of the dynamic filter. It uses data from the smaller table to generate a Bloom filter and obtain the
minandmaxvalues (for the range filter) of the join key. It then sends this information to the DFC.DFC (Dynamic Filter Consumer) operator: The consumer of the dynamic filter. It uses the Bloom filter and range filter to filter data from the larger table. The range filter attempts to push the filter conditions down to the underlying storage to filter data at the source.
For different JOIN semantics, the tables in the join can take on different roles:
A JOIN B: Either A or B can act as the producer or the consumer.
A LEFT JOIN B: A can only act as the producer, and B can only act as the consumer.
A RIGHT JOIN B: A can only act as the consumer, and B can only act as the producer.
A FULL OUTER JOIN B: Dynamic filters cannot be used.
For information about how to use dynamic filters, see Enable dynamic filters.
Dynamic partition pruning
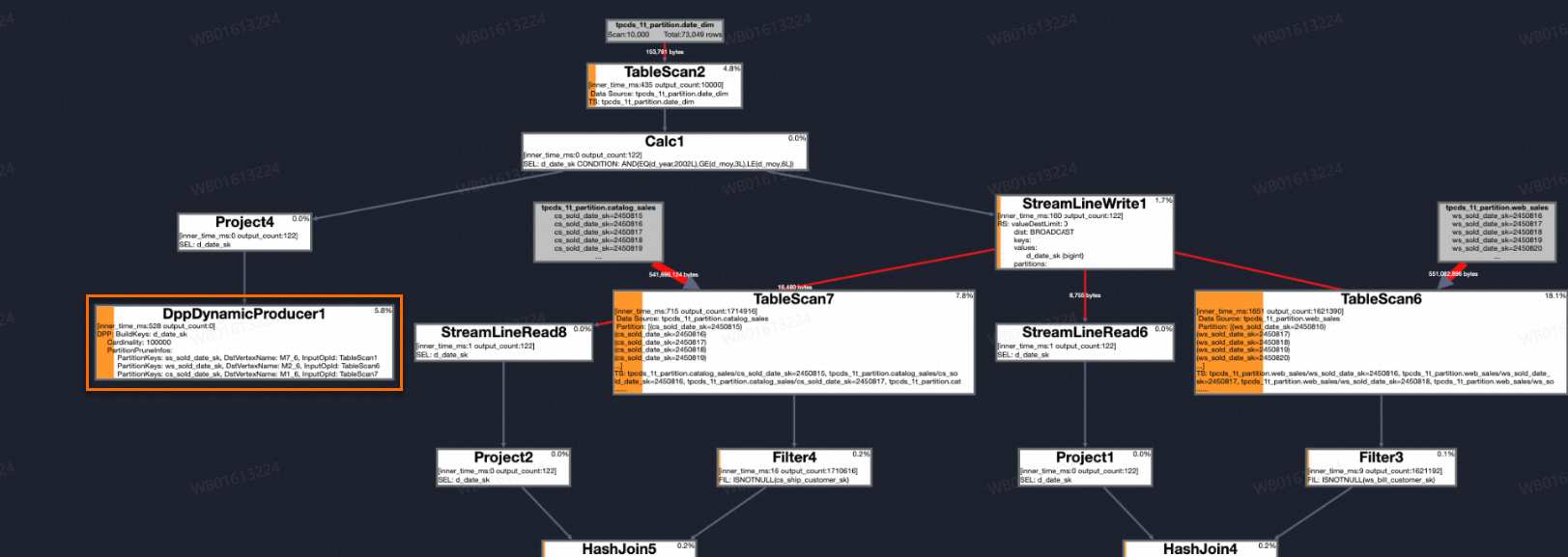
The preceding Bloom filter and range filter examples illustrate optimizations for non-partitioned tables, where the join key is not a partition key column. When the join key is a partition key column, dynamic range or Bloom filters can still be used. However, MaxCompute reads all the data in a partition before filtering it. This process can be optimized by pruning irrelevant partitions before reading them. This feature is called dynamic partition pruning (DPP).
For example, consider the following SQL statement that includes a JOIN:
-- A is a non-partitioned table. The value in column a is 20200701.
-- B is a partitioned table. The partition key column ds contains three partitions: 20200701, 20200702, and 20200703.
SELECT * FROM (table1) A JOIN (table2) B ON A.a= B.ds;After you enable dynamic partition pruning, the optimizer decides whether to apply it based on whether the table is a partitioned table. When dynamic partition pruning takes effect, MaxCompute collects data from the smaller table to generate a Bloom filter. It then filters the partition list of the larger table, identifies the partitions that need to be read and prunes the rest. If all of a process's target partitions are pruned, that process is not scheduled.
In the preceding example, because the only value in column a of table A is 20200701, enabling dynamic partition pruning prunes the 20200702 and 20200703 partitions of table B. This saves resources and reduces the job runtime.
For information about how to use dynamic partition pruning, see Enable dynamic partition pruning.
Enable dynamic filters
MaxCompute provides the following methods to enable dynamic filters:
Method 1: Force dynamic filtering at the session level. Submit the following command with your SQL statement:
set odps.optimizer.force.dynamic.filter=true;NoteThis property can also be set at the project level, but we recommend that you set it at the session level. This can reduce processing efficiency for JOIN jobs that do not benefit from filtering.
This method inserts a dynamic filter for every supported JOIN job.
Method 2: Allow the optimizer to intelligently decide when to use dynamic filtering at the session level.
set odps.optimizer.enable.dynamic.filter=true;When you use this method, the optimizer estimates whether inserting a dynamic filter offers sufficient benefits. If so, the optimizer inserts a dynamic filter; otherwise, it does not.
NoteThis method relies on metadata statistics, such as the number of distinct values (NDV). For more information about metadata statistics, see Collect information for the optimizer. Because metadata statistics are estimates from the optimizer, they may be inaccurate. As a result, the optimizer may not insert a dynamic filter as expected.
Method 3: Enable dynamic filters using a hint in the SQL statement.
The hint format is
/*+dynamicfilter(Producer, Consumer1[, Consumer2,...])*/. It allows one producer to filter multiple consumers. The following command is an example:select /*+dynamicfilter(A, B)*/ * from table1 A join table2 B on A.a= B.b;
Enable dynamic partition pruning
Enable dynamic partition pruning at the session level by submitting the following command with your SQL statement:
set odps.optimizer.dynamic.filter.dpp.enable=true;This property can also be set at the project level, but we recommend that you set it at the session level. If a JOIN job does not benefit from data filtering, this can reduce processing efficiency.
Verify the optimizations
After you enable the features as described in Enable dynamic filters or Enable dynamic partition pruning, you can use the following methods to verify that they are active:
Verify dynamic filter
After you run the SQL job, view its LogView information. If an operator similar to DynamicFilterConsumer1 appears in the LogView, the dynamic filter has taken effect.
Verify dynamic partition pruning
After you run an SQL job, check its LogView information. If an operator such as DppDynamicProducer that contains PartitionPruneInfos appears in the LogView, it indicates that dynamic partition pruning has taken effect.