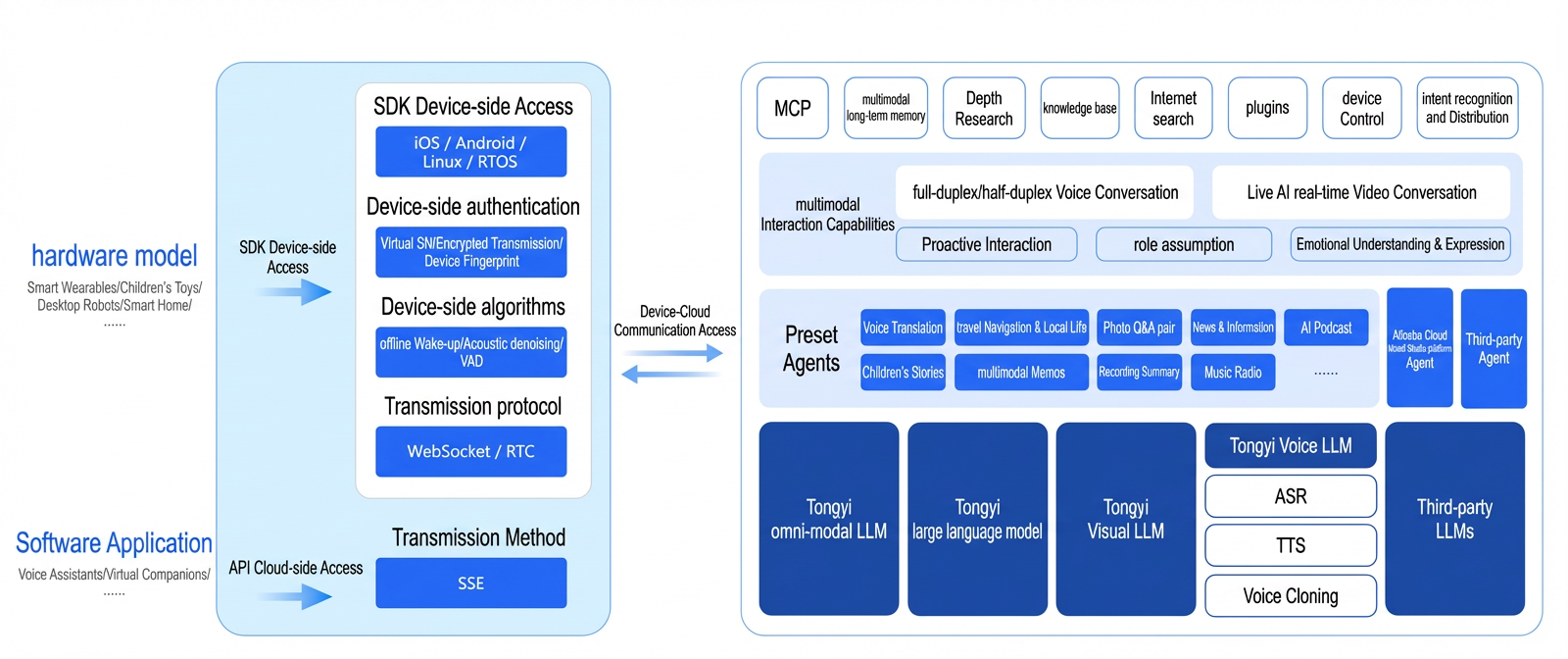
The Tongyi Multimodal Interaction Development Suite equips devices such as AI/AR glasses, educational devices, and smart robots with the ability to hear, see, and think. Through natural conversation, multimodal perception, and real-time interaction, it enables smart scenarios such as museum exhibit explanations, homework assistance, floral arrangement recommendations, and health management. This turns any object into an extension of the user's senses and a helpful life assistant.
Scenarios
-
Wearable devices: Devices such as smart glasses and smart headphones use voice commands and visual interaction to meet daily work and life needs. This includes voice translation and visual Q&A, which improve personal efficiency and experience.
-
Emotional companionship: Devices such as desktop robots and AI toys provide emotional value and build lasting connections. They use realistic audio and video interaction, emotion perception, and proactive conversation.
-
Children's scenarios: Devices such as children's storytellers, educational devices, and children's toys combine fun audio and video interactions with high-quality content. They make learning enjoyable and serve as smart playmates for children.
-
Smart home: Devices such as smart home displays and smart speakers offer flexible control commands and access to a wide range of content. They make home life smarter and more convenient.
-
Mobile smart applications: Create mobile apps with multimodal interaction for scenarios such as emotional companionship, spoken language practice, and simultaneous interpretation. This enhances the interactive experience and practical value.
Benefits
Natural and human-like conversations
-
Ultra-low latency response: Provides fast responses with industry-leading low latency for video and voice conversations.
-
Smooth full-duplex conversations: The end-to-end streaming system supports full-duplex conversations. You can interrupt at any time, and the system instantly adjusts its strategy to provide a natural and smooth conversational experience.
-
Ultra-realistic voice tones and cloning: The Tongyi speech synthesis Large Language Model (LLM) provides a variety of emotional and highly human-like voice tones. It also supports voice cloning. You can clone a user's voice with just one sentence for more flexible application scenarios.
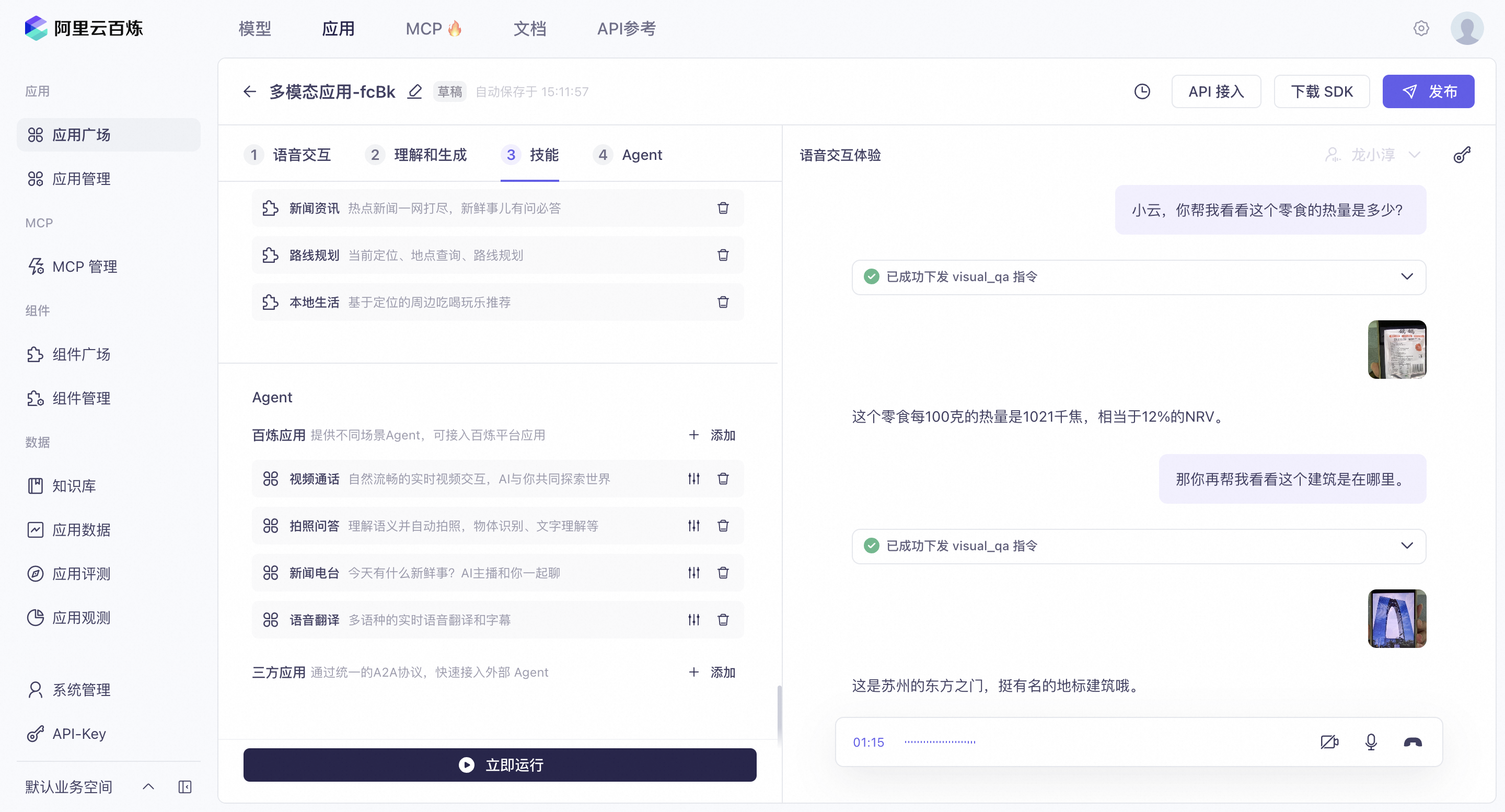
Real-time multimodal understanding and interaction
Use the leading visual, speech, and text understanding capabilities of the Tongyi series of LLMs to deeply understand the physical world. Interact with users in real-time to create useful and engaging multimodal experiences. Common scenarios include the following:
-
Museum exhibit explanations: When visiting museums or cultural sites, the device automatically identifies artifacts and explains their historical background and cultural value. This helps you easily learn the stories behind the artifacts.
-
Landmark recognition: When you encounter an interesting landmark while traveling, the device can quickly identify its name and style. This helps you learn about the information and significance of urban landmarks.
-
Bouquet arrangement: Based on the user's needs for an occasion, the device automatically identifies available flower types. It then provides suggestions for flower selection and combination to create a beautiful and suitable bouquet.
-
Medication information: The device automatically identifies the name of a medication and explains its effects, usage, and precautions.
-
Calorie recommendations: The device identifies and analyzes food calorie information. It then provides meal suggestions based on your current physical condition and dietary goals.
-
Picture book reading: The device recognizes the text in picture books and reads it aloud, providing an enjoyable time for children.
Efficient, low-consumption interaction
-
Integrated hardware and AI design: The device-side SDK seamlessly connects camera and microphone input to the LLM.
-
Device-side algorithm enhancement: The suite provides device-side algorithms such as Voice Activity Detection (VAD), echo cancellation, and voice activation. These algorithms improve multimodal interaction and significantly reduce latency and power consumption.
Quick integration and deployment
-
Wide compatibility with mainstream hardware: Access all capabilities through a standardized SDK/API. The suite supports systems such as Android, iOS, Linux, and RTOS, and adapts to various software and hardware needs. This greatly shortens the developer cycle.
-
Visual configuration management: Use a visual, no-code interface to configure models, prompts, knowledge bases, agents, plugins, and device instructions. The suite provides scenario templates for mainstream hardware to quickly run a demo and perform real-time testing.
-
Pre-built agents, plugins, and device control instructions: The suite includes a wide range of ready-to-use components that cover common software and hardware scenarios. These include visual capabilities, children's scenarios, content services, and practical tools.
Flexible, extensible, and open ecosystem
-
On-demand model invocation and customization: Call and replace LLMs from the Alibaba Cloud Model Studio platform as needed.
-
Capability extension: The suite supports custom agent and plugin integration and is compatible with third-party communication protocols.
Quick start
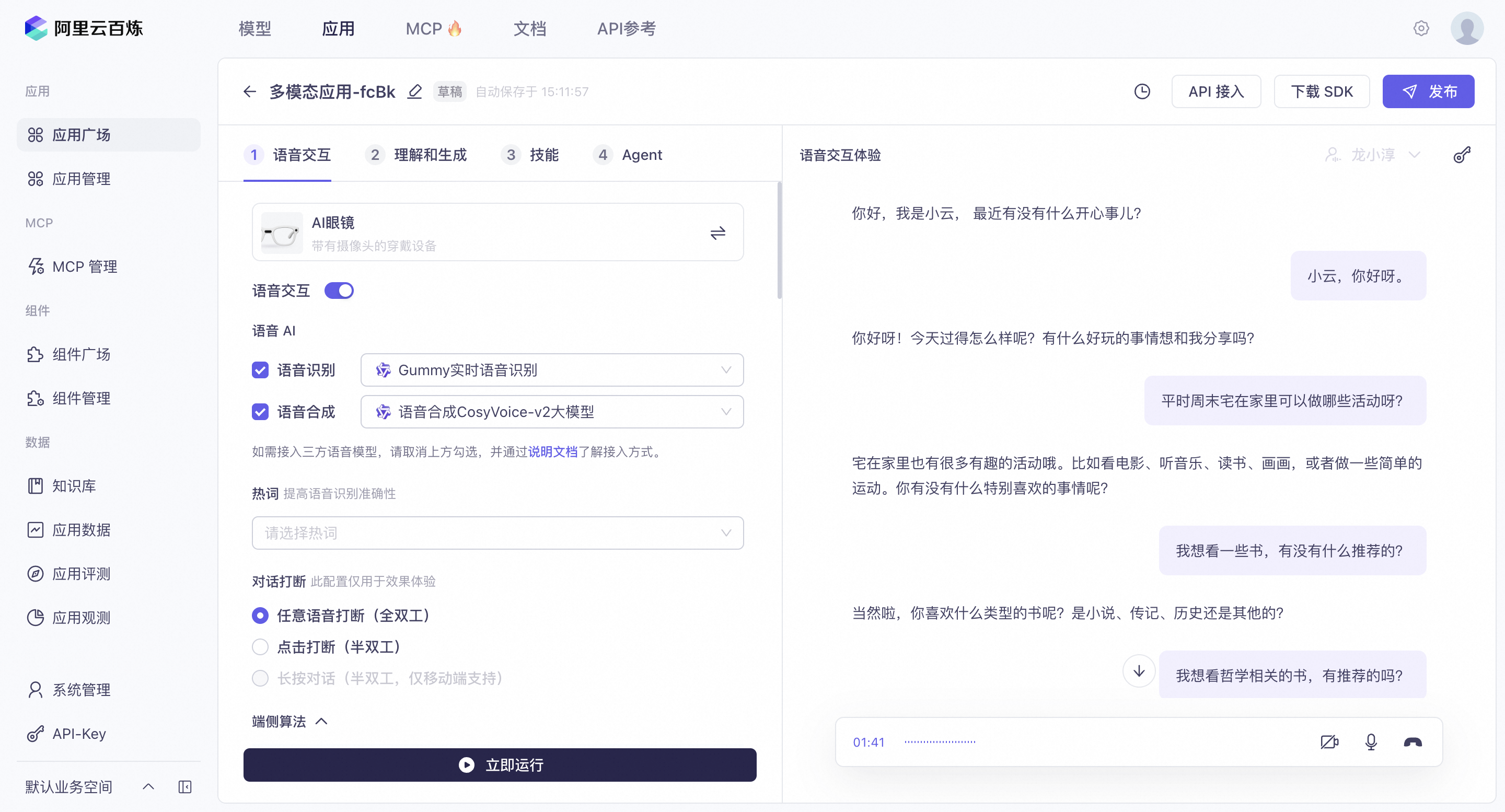
Run a no-code demo with just a few clicks to experience real-time multimodal interaction. For detailed configuration steps, see the User Guide.
For an open source demo, see the sample code on GitHub.