This topic describes how to integrate third-party voice models for speech recognition and speech synthesis. It also explains how to use text-based input to trigger the interactive features of the multimodal interaction development suite and build a complete interaction flow.
The Alibaba Cloud Model Studio multimodal interaction development suite integrates Large Language Model (LLM)–based speech recognition and speech synthesis. It also provides audio algorithms such as Voice Activity Detection (VAD) and Acoustic Echo Cancellation (AEC) to enhance interaction quality.
If our built-in services do not meet your specific requirements—such as support for a particular language or voice timbre—you can integrate a third-party voice service. This service replaces the speech recognition and speech synthesis components in the Qwen multimodal interaction development suite. You can drive subsequent conversation flows using text input and receive responses in text-only mode.
Using a third-party voice model may increase voice conversation latency due to the model’s inherent characteristics. The actual performance depends on your test results.
Call flow
Flowchart for calling a third-party voice service
Use the output from a third-party speech recognition service to call the multimodal interaction service. Then, use the text response from that service to generate an audio reply with a third-party speech synthesis service.
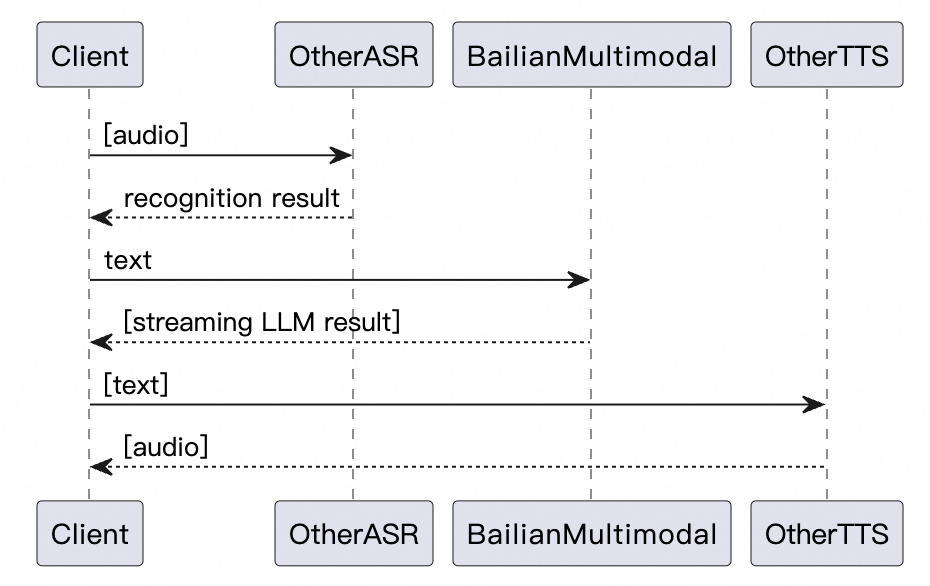
Request a conversation using third-party speech recognition (ASR) results
Call a third-party speech recognition service to transcribe spoken input. Then, use the transcription result to call the Alibaba Cloud Model Studio multimodal interaction service.
After you obtain the full speech recognition result, send a text-based request directly to the multimodal interaction service.
Send a requestToRespond request when the client is in the Listening state. Parameter description:
-
Set the `type` field in the request to "prompt".
-
Set the `text` field in the request parameters to the recognized text from the third-party service.
If the current state is not Listening, first call the Interrupt interface to stop the current playback.
// Create an UpdateParams object. The third parameter cannot be null.
UpdateParams params = new UpdateParams();
dialog.requestToRespond("prompt", "How is the weather today?", params);dialog.request_to_respond("prompt", "How is the weather today?", parameters=None)Json::Value root;
root["text"] = "How is the weather today?";
root["type"] = "prompt";
Json::StreamWriterBuilder writer;
writer["indentation"] = "";
ConvRetCode ret = conversation->SendResponseData(Json::writeString(writer, root).c_str());Request third-party speech synthesis (TTS) using text
When using the Alibaba Cloud Model Studio multimodal interaction service, configure the output format for conversation results to text-only. Use this text output to call a third-party speech synthesis service and generate speech.
The text output from the Alibaba Cloud Model Studio multimodal interaction service supports streaming output. For best results, use a third-party Text-to-Speech (TTS) service that also supports streaming synthesis. Stream each text segment from the multimodal conversation output to the speech synthesis service. The service then streams back the synthesized audio. This approach significantly improves system interaction speed.
For more information, see the Java SDK for Alibaba Cloud Model Studio CosyVoice speech synthesis.