Compatibility
This function can be used in filter, sort, and formula expressions.
Document fields used as function parameters must be created as an attribute.
tag_match: Tag matching for scoring
1. Overview
The tag_match function fulfills many query and document matching requirements. It is especially useful for personalizing search results. For example, you can prioritize stores that a user has liked or display sports and entertainment news that a user prefers. The basic functionality of tag_match is to store a series of key-value pairs in an array field of a document. You can then pass corresponding key-value information in the query through the kvpairs clause. The tag_match function searches the document for the keys specified in the query, calculates a score for each matched key, and then combines these scores into a final score. This result can be used for scoring and weighting or for filtering.
The calculation process is as follows: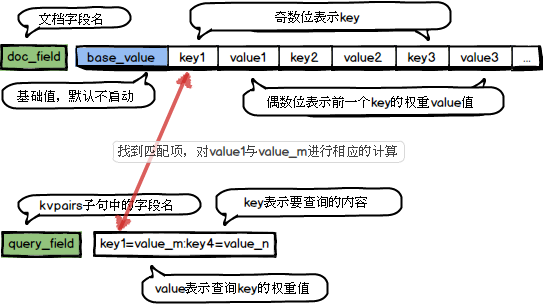
2. Usage
Basic Syntax:
tag_match(query_key, doc_field, kv_op, merge_op)
Advanced Syntax:
tag_match(query_key, doc_field, kv_op, merge_op, has_default, doc_kv, max_kv_count)
3. Parameters
query_key: Specifies the key-value pairs from the query used for matching. These pairs are passed through the kvpairs clause. Keys and values are separated by an equal sign (=), and multiple key-value pairs are separated by colons (:). For example,
kvpairs=query_tags:10=0.67:960=0.85:1=48indicates that thequery_tagsparameter contains three elements (10, 960, and 1) with corresponding values (0.67, 0.85, and 48). The query can also contain only a list of keys, such askvpairs=cats:10:960:1.doc_field: Specifies the field in the document that stores key-value pairs. This field must be an integer array (
int_array) or a floating-point array (float_array,double_array). If you use a floating-point array, the key values are cast toint64for matching. The array stores keys and values in an alternating sequence:[key0, value0, key1, value1, ...]. Keys are at even-numbered indices (0, 2, etc.), and their corresponding values are at the subsequent odd indices.kv_op: The operation performed on the values of the query and document keys when they match. Supported operators include:
max(maximum),min(minimum),sum(sum),avg(average),mul(product),query_value(uses the value from the query key),doc_value(uses the value from the document), andnumber(a specified constant).merge_op: Merges the results from multiple key matches. Supported operators include:
max(maximum),min(minimum),sum(sum),avg(average), andfirst_match(uses the result of the firstkv_opcalculation and ignores the rest).has_default: A boolean value that specifies whether to use an initial score. The default value is
false. If set totrue, the first value in thedoc_fieldis treated as a default value, similar to a base score. The structure becomes[init_score, k0, v0, k1, v1, ...].doc_kv: A boolean value that specifies the structure of the
doc_field. The default value istrue, which means the field contains key-value pairs. If set tofalse, the field contains only keys.max_kv_count: The maximum number of key-value pairs that can be passed in the query. The default value is 50. You can increase this limit, but it cannot exceed 512.
4. Return Value
Returns a double value representing the final score. If has_default is false and no matches are found, it returns 0. To return an int64 result, use the int_tag_match function. The int_tag_match function is functionally identical to tag_match, but it cannot be used in a ranking expression.
5. Use Cases
Scenario 1: In a large online forum, posts can be assigned various tags (comedy, sports, news, music, science, etc.). When you send documents to OpenSearch, you can assign a tag ID to each tag (for example, comedy: 1, sports: 5, news: 3, music: 6) and store these tags in a tag field. If you preprocess the posts, you can even determine a weight for each tag. For instance, a post about funny sports news might have a comedy weight of 0.5, a sports weight of 0.5, and a news weight of 0.1. The tag field for this post would be [1, 0.5, 5, 0.5, 3, 0.1]. For registered users, you can learn their interest tags over time.
For example, a user named nba_fans is interested in sports and comedy, with corresponding weights of 0.6 and 0.3. When this user performs a query, you can add this information to the query using the kvpairs clause. If the kvpairs clause is named user_tag, its value for nba_fans would be 5=0.6:1=0.3. By configuring tag_match(user_tag, tag, mul, sum) in the fine-ranking expression, you can boost posts that match the user's interests, ranking them higher.
With the kv_op parameter set to mul, the function multiplies the values from the query and the document. The individual scores are calculated as follows: sports (0.5 * 0.6 = 0.3) and comedy (0.5 * 0.3 = 0.15). With the merge_op parameter set to sum, the function adds the scores for sports and comedy (0.3 + 0.15 = 0.45). This total score is added to the final ranking score. This way, you can apply scoring and weighting to posts based on the user's interests.
Scenario 2:
Products can have multiple attribute tags, such as 1 for "young adult" (age), 2 for "middle-aged" (age), 3 for "minimalist" (style), 4 for "fashionable" (style), 5 for "female" (gender), and 6 for "male" (gender).
Suppose you only want to mark a product's tags without assigning weights. You can store these tags in an options field. For example, a fashionable clothing item for young women would have an options field of [1, 4, 5]. Note that this array contains only tag keys, not values. Users also have their own attribute tags that correspond to the product tags. For instance, a young female user who often buys minimalist clothing might have a query like user_options=1:3:5. Note that this kvpairs clause also contains only tag keys.
To boost products that match the user's tag preferences, you can use tag_match(user_options, options, 10, sum, false, false) in the formula. Here, user_options and options specify the tag information from the query and the document, respectively. The kv_op is set to a constant value of 10, assigning a score of 10 to each matching tag. The has_default parameter is false because we do not need an initial value. The doc_kv parameter is false, indicating that the document field stores only keys.
When the young female user queries for the clothing item described above, the "young adult" and "female" tags will match. The score for each match is 10. With sum as the merge_op, the final boost score for this product is 20. This method allows you to apply scoring and weighting to matched documents even without tag weight information.
Usage notes
Fields that are used as function parameters must be created as an attribute.
When using
tag_matchin afilterorsortclause, enclose thequery_key,kv_op,merge_op,has_default, anddoc_kvparameters in double quotes. For example:sort=-tag_match("user_options", options, "mul", "sum", "false", "true", 100).The
tag_matchfunction matches keys using integer comparison. Therefore, keys in both the query and the document should be integers. If a key is a floating-point number,tag_matchcasts it to an integer for comparison.
Examples
Assume that documents can have the following 10 types of tags:
1 - Finance
2 - Technology
3 - Sports
4 - Entertainment
5 - Fashion
6 - Education
7 - Travel
8 - Gaming
9 - Popular Science
10 - HealthcareExample 1: Same keyword, different tags
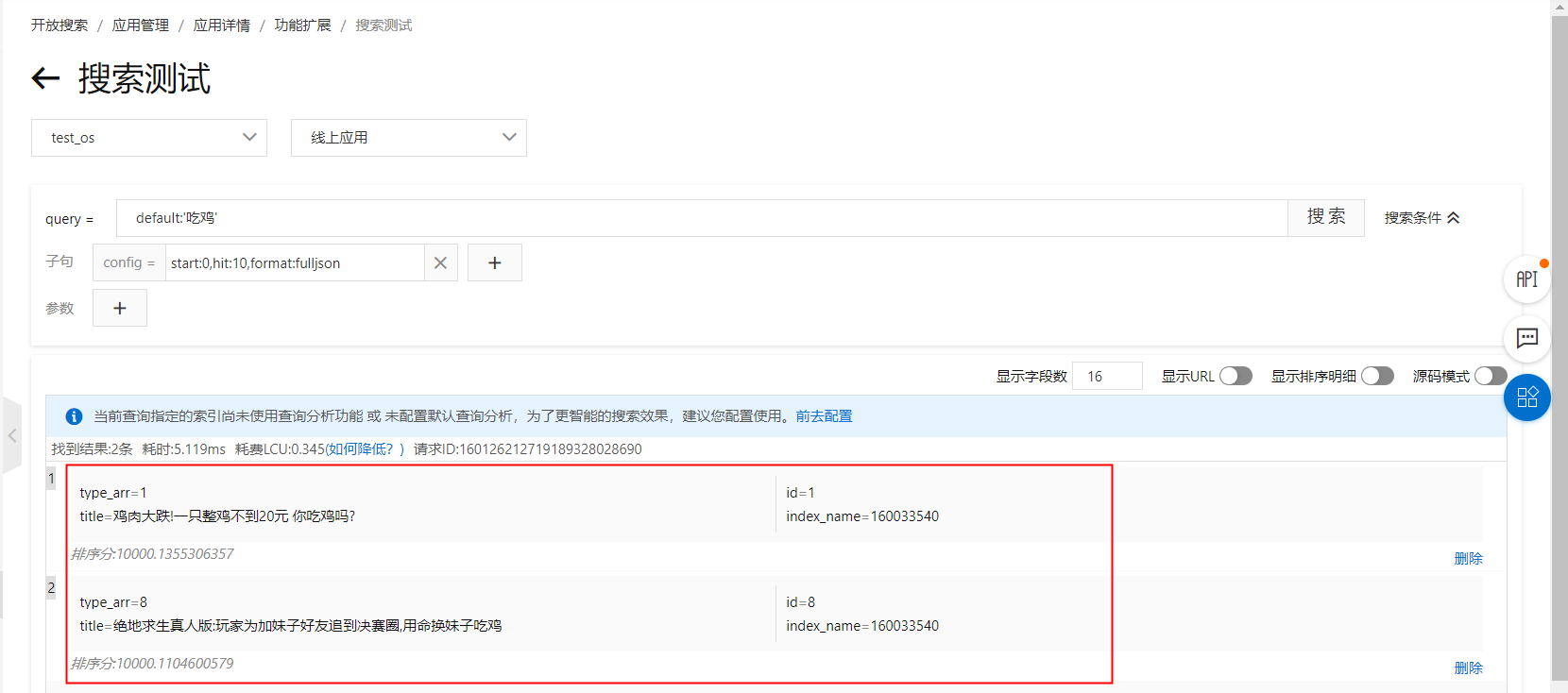 As shown in the figure above, a search for "battle royale" returns two documents. However, the documents are of different types: 1-Finance and 8-Game. If you want to display the document with the "Game" tag first, you can configure the tag_match function. The following sections demonstrate how to configure this function in a ranking expression and a sort clause:
As shown in the figure above, a search for "battle royale" returns two documents. However, the documents are of different types: 1-Finance and 8-Game. If you want to display the document with the "Game" tag first, you can configure the tag_match function. The following sections demonstrate how to configure this function in a ranking expression and a sort clause:
kvpairs: type:8
Ranking expression: tag_match(type, type_arr, 10, max,false,false)
sort clause: tag_match("type", type_arr, 10, "max","false","false")Result with ranking expression: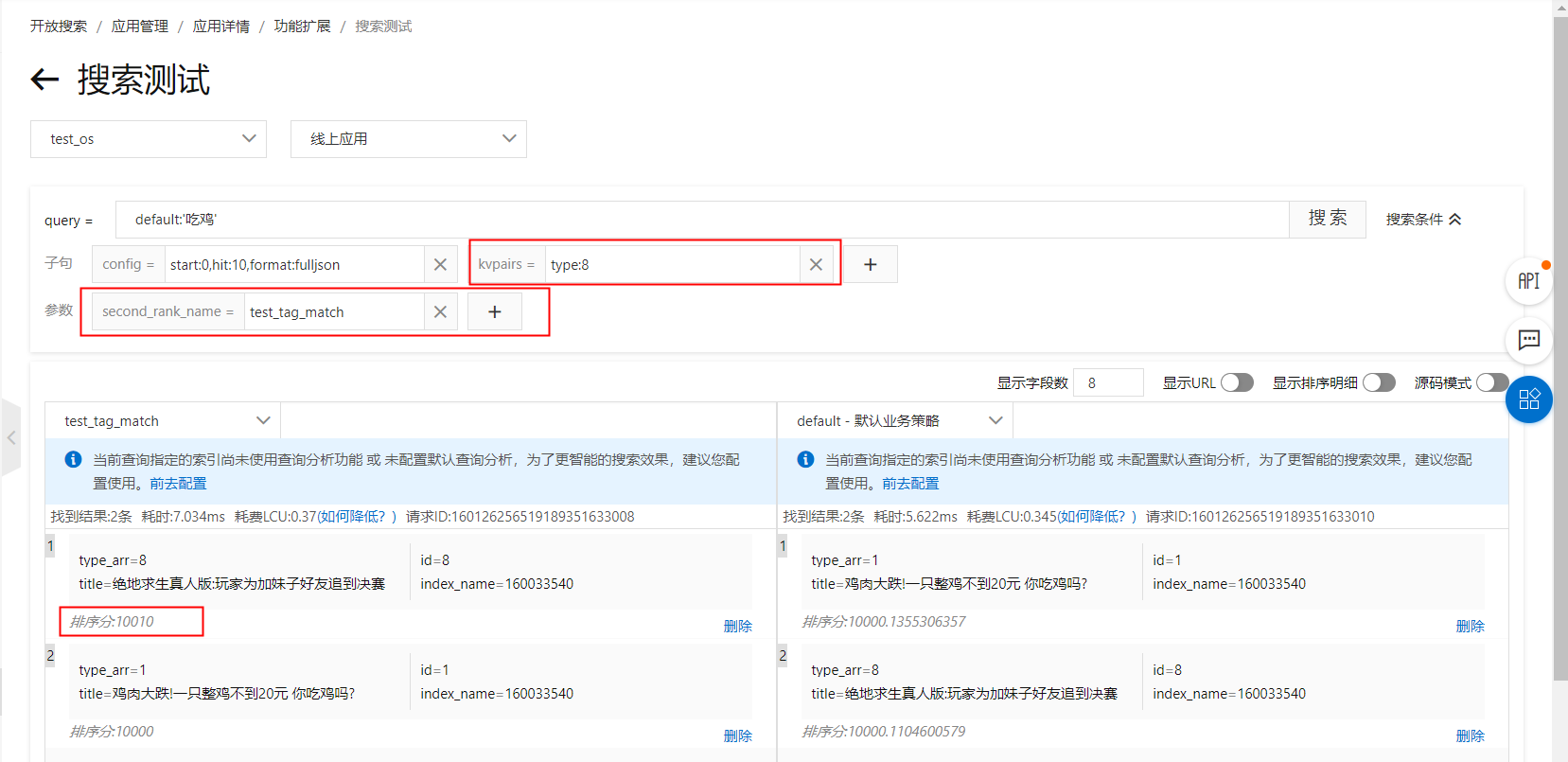 Result with sort clause:
Result with sort clause: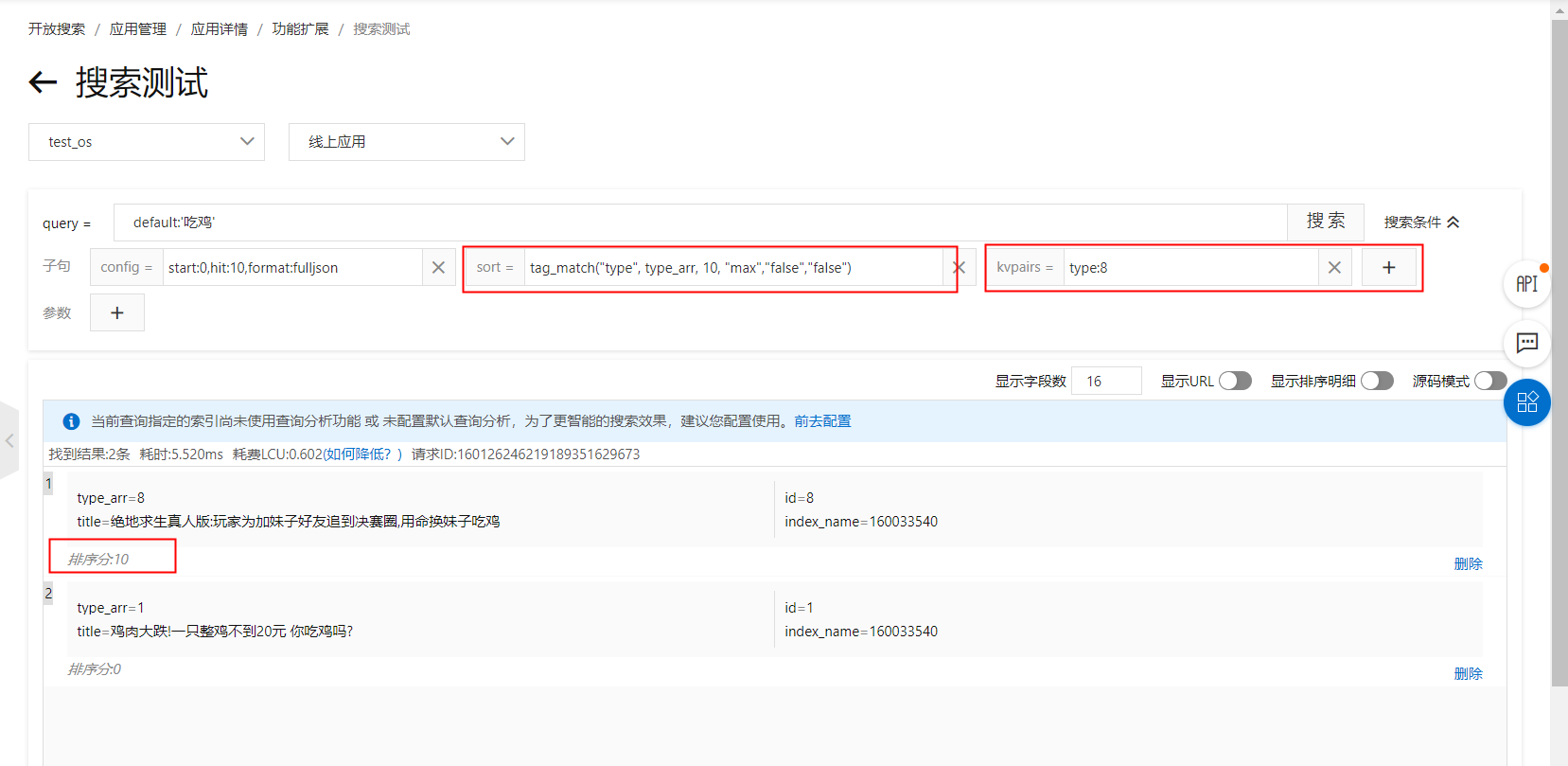
Example 2: Combined score for multiple tags (for user personalization)
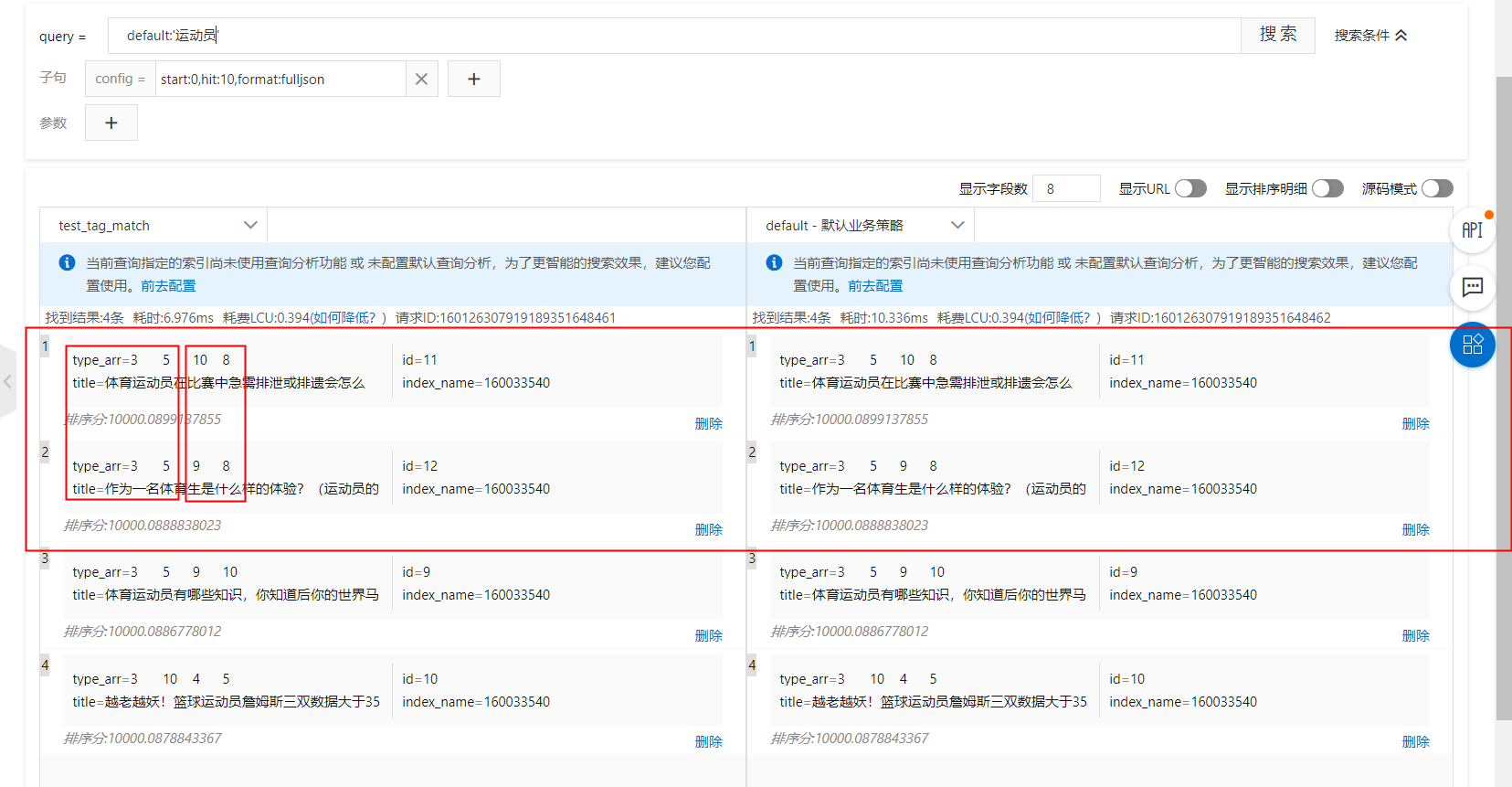 As shown in the image, when the primary tags are the same, you need to match the scores of secondary tags. The following examples show how to configure this in a ranking expression and a sort clause:
As shown in the image, when the primary tags are the same, you need to match the scores of secondary tags. The following examples show how to configure this in a ranking expression and a sort clause:
kvpairs: type:3=2:10=1
Ranking expression: tag_match(type, type_arr, 10, sum,false,true)
sort clause: tag_match("type", type_arr, 10, "sum","false","true")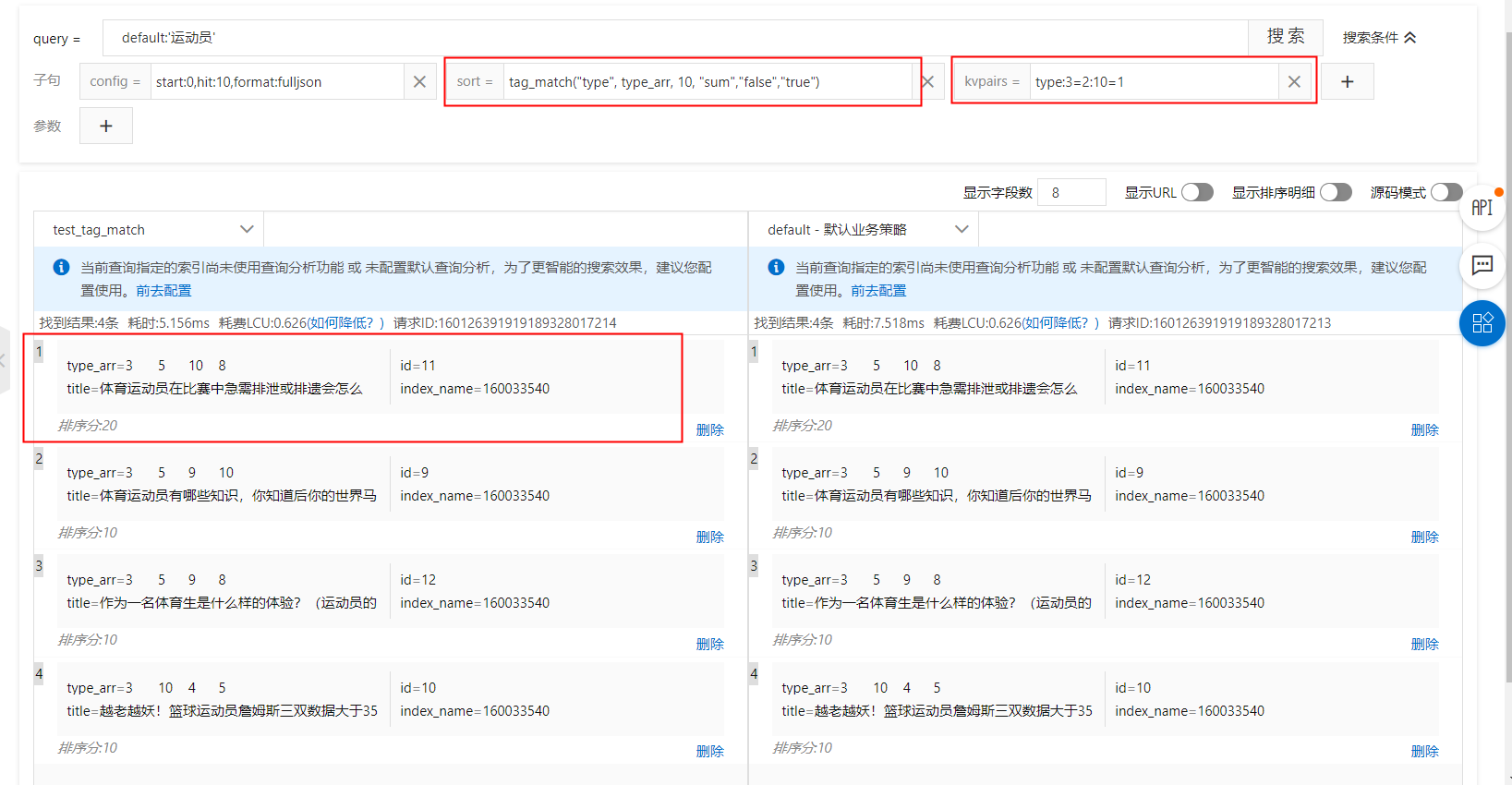
Example 3: Multiple tags of the same type with different scores
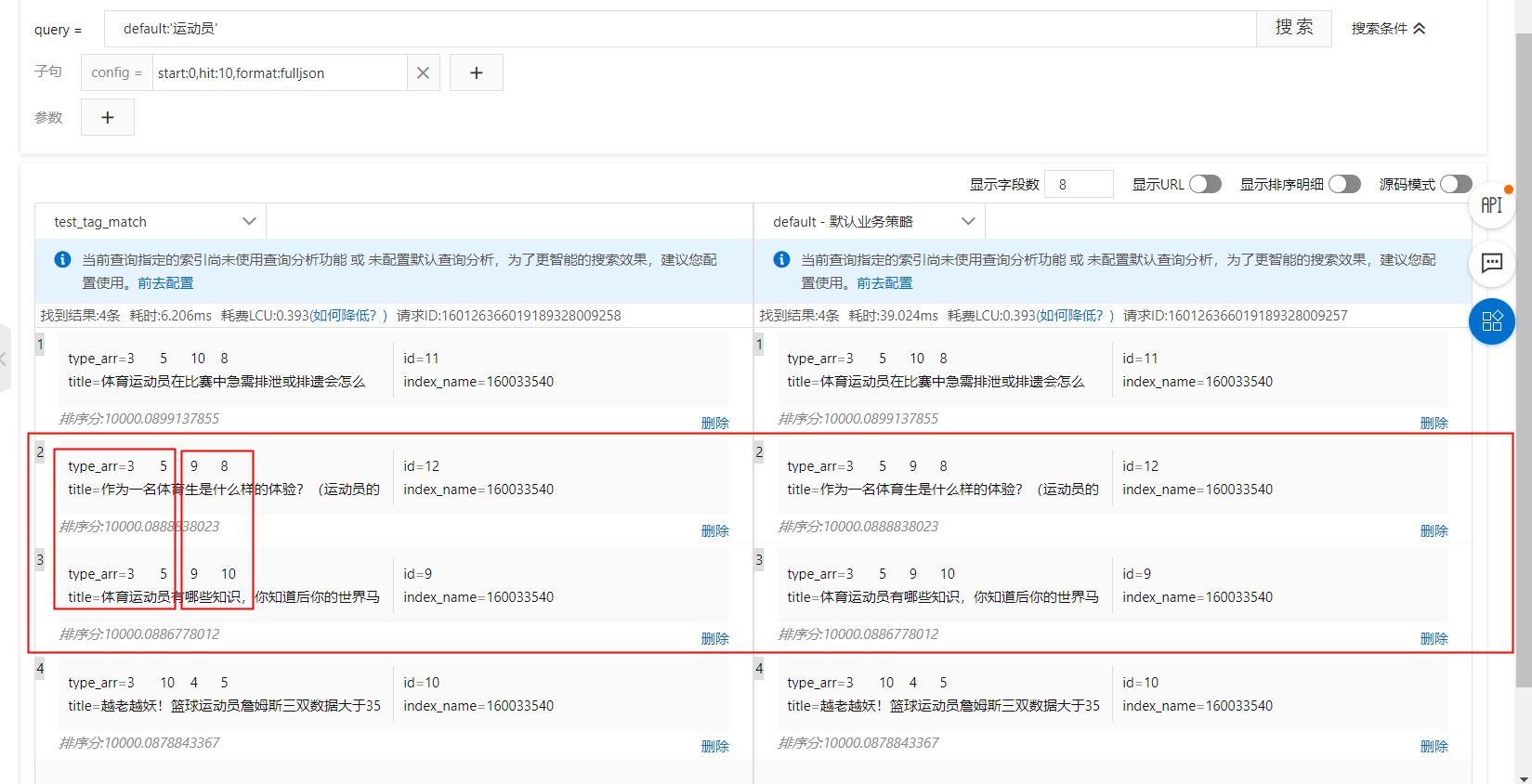 As shown in the image, the content highlighted in red has the same tags, but each tag has a different score. The following examples show how to configure this in a ranking expression and a sort clause:
As shown in the image, the content highlighted in red has the same tags, but each tag has a different score. The following examples show how to configure this in a ranking expression and a sort clause:
kvpairs: type:3=2:9=2
Ranking expression: tag_match(type, type_arr, sum, sum,false,true)
sort clause: tag_match("type", type_arr, "sum", "sum","false","true")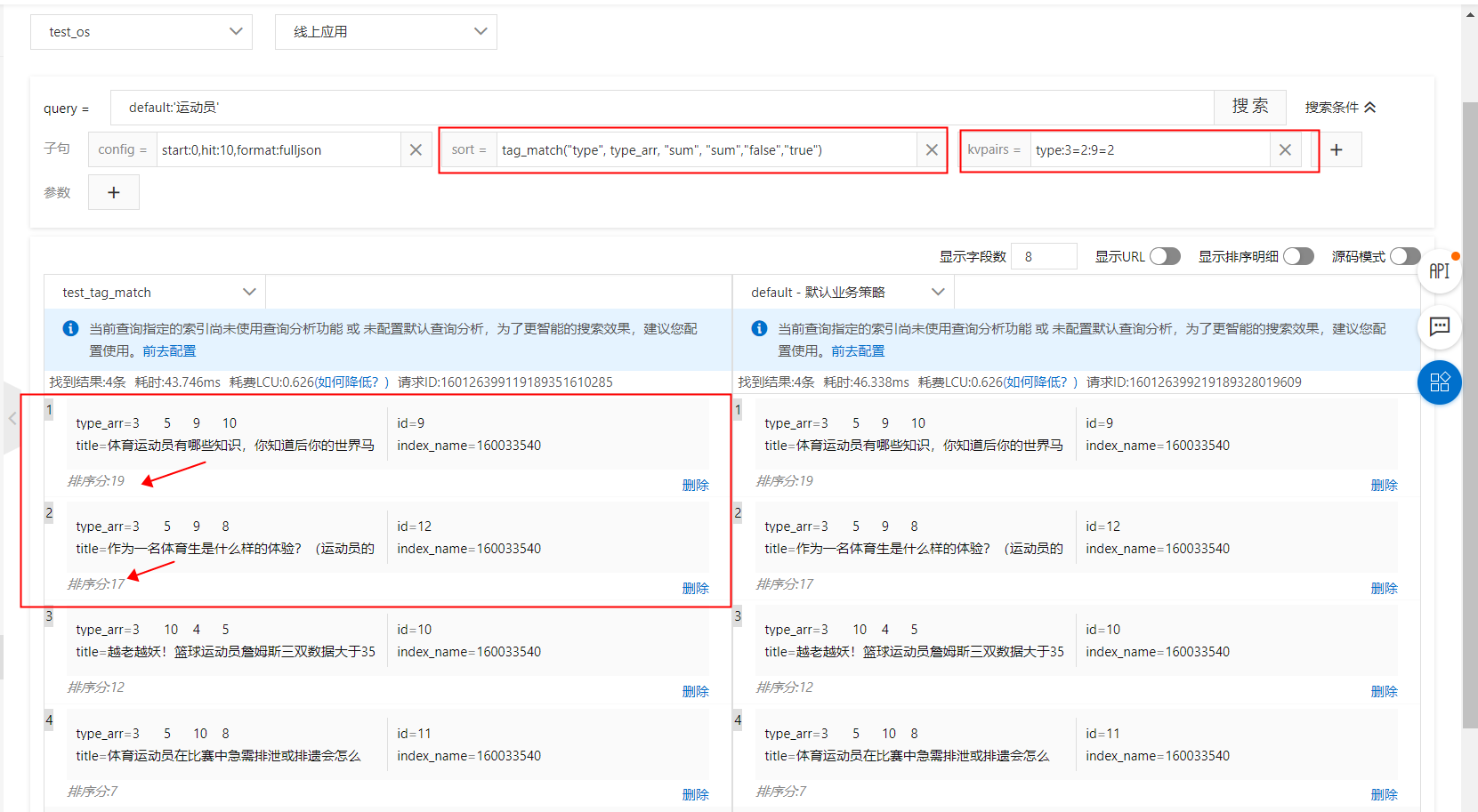
Java SDK Example: Java SDK Search Demo