With its high-throughput sequential writes and smart caching mechanism, ossfs 2.0 significantly improves the efficiency of downloading, storing, and deploying large models in the cloud. It supports efficient model loading in both single-GPU and multi-GPU concurrent deployment scenarios. This topic describes how to download models using ossfs 2.0, provides tuning practices for deploying safetensors models with vllm/sglang frameworks, and describes considerations for deploying other model types.
Download models to OSS
ossfs 2.0 supports high-throughput sequential writes, which is ideal for large-file upload scenarios like downloading large models. You can use tools such as ModelScope to write models from a repository directly to an OSS bucket using ossfs 2.0.
Mount an OSS bucket to a specified directory using the standard ossfs 2.0 configuration. For configuration examples, see Common configuration examples.
Download the model.
Use the following ModelScope command to download the DeepSeek-R1-0528 model to the ossfs 2.0 mount point.
modelscope download --model deepseek-ai/DeepSeek-R1-0528 --local_dir /mnt/oss/DeepSeek-R1-0528 --max-workers=32When you use ModelScope to download a model on an ECS instance, it first attempts to download from an internal repository. If the ECS instance has sufficient network bandwidth, ossfs 2.0 efficiently uses network resources to reach the default OSS upload bandwidth limit of 20 Gbps.
Deployment scenarios
AI models come in a wide variety of types and file formats, including common ones like safetensors (secure and efficient), PyTorch (versatile), and GGUF (suitable for local inference). To maximize model loading performance from OSS, configure ossfs 2.0 based on your specific deployment architecture.
In typical deployment scenarios based on GPU count, the recommended ossfs 2.0 configurations are as follows:
Single-GPU deployment
For a single-GPU model deployment, the default mount configuration of ossfs 2.0 already provides good loading performance.
Multi-GPU concurrent deployment on a single machine
When loading the same model concurrently on a multi-GPU machine, multiple processes read different shards of the same model file at the same time, which can cause bandwidth amplification. To solve this issue, enable a fixed-size memory cache in ossfs 2.0 using the
--memory_data_cache_sizemount option. After this option is enabled, the model file is downloaded from OSS only once, and multiple processes share the local cached data. This significantly reduces network load and loading latency.NoteThe memory cache mode in ossfs 2.0 primarily optimizes bandwidth amplification when multiple processes access the same file concurrently. The cached data for a process is released synchronously after the last file handle is closed. This mode does not affect the data loaded into the operating system PageCache after being read. PageCache data is cached as it is in standard mode. For more information, see Mount option descriptions.
Correctly configuring ossfs 2.0 improves the loading efficiency and deployment stability for various large models in the cloud. For more information, see Deploy safetensors models and Deploy models in other formats.
Deploy safetensors models
Models in the safetensors format are secure and load quickly, which makes it a mainstream storage format for large models. ossfs 2.0 provides optimized deployment solutions for these models.
Test environment
Test environment: An 8-GPU Lingjun node with 192 vCPUs, 2 TiB of memory, 200 Gbps of bandwidth, and an OSS download bandwidth limit of 100 Gbps.
Software versions: ossfs 1.91.8, ossfs2 2.0.5, Python 3.12, and SGLang 0.5.5.
Mount methods
ossfs 1.0 mount command
ossfs <bucket> /mnt/oss -o url=http://<endpoint> -o parallel_count=64ossfs 2.0 configuration file and mount command
Configuration file
Create the
/etc/ossfs2.confconfiguration file, add the following content, and then save the file. Replace the bucket name, endpoint, and AccessKey information in the example with your actual values.--oss_bucket=<bucket> --oss_endpoint=http://<endpoint> --oss_access_key_id=<ak> --oss_access_key_secret=<sk> # Configure a 16 GiB memory cache to reduce bandwidth amplification from concurrent reads --memory_data_cache_size=16gMount command
ossfs2 mount /mnt/oss -c /etc/ossfs2.conf
Deployment methods
safetensors models support direct service startup or deployment using the PageCache prefetch method.
Direct deployment
This method is suitable for scenarios with limited memory resources. Use the following test command to specify the model file path and start the model service:
python -m sglang.launch_server --model-path <model> --tensor-parallel-size <tp>(Recommended) PageCache prefetch deployment
This method is suitable for production environments with sufficient memory. The prefetch mechanism preloads model files into the operating system's PageCache. This approach converts random (out-of-order) reads into a hybrid mode of 'sequential read preloading + in-cache random access', which significantly reduces OSS network requests and latency.
Use the following commands to prefetch data and start the model service:
# Prefetch the data. This command starts 16 concurrent processes to cat the files in the model directory. After the cat command is complete, the data resides in the operating system's PageCache.
find "<model>" -type f -print0 | xargs -0 -I {} -P "16" sh -c 'cat "{}" > /dev/null && cat "{}" > /dev/null'
# Start the service.
python -m sglang.launch_server --model-path <model> --tensor-parallel-size <tp>PageCache is managed by the operating system. If a node has insufficient free memory or if a container has limited memory, prefetched data might be reclaimed prematurely. Ensure that the available memory exceeds the total model size, and reserve some additional memory for the model service process and the ossfs 2.0 process. After the data is loaded, this cached data is automatically managed by the operating system and does not permanently consume system resources.
Ensure that no other services that read large files are running on the model service's node. Otherwise, the prefetched data might be reclaimed prematurely due to system memory pressure.
Loading time comparison
These results show only the model loading time during deployment (lower is better). The test results do not include service initialization or subsequent model prefetch steps.
When loading the DeepSeek-R1-0528 model, ossfs 1.0 fills up the system disk and causes the system to freeze. An additional 800 GiB of local disk space is required to support the write operations.
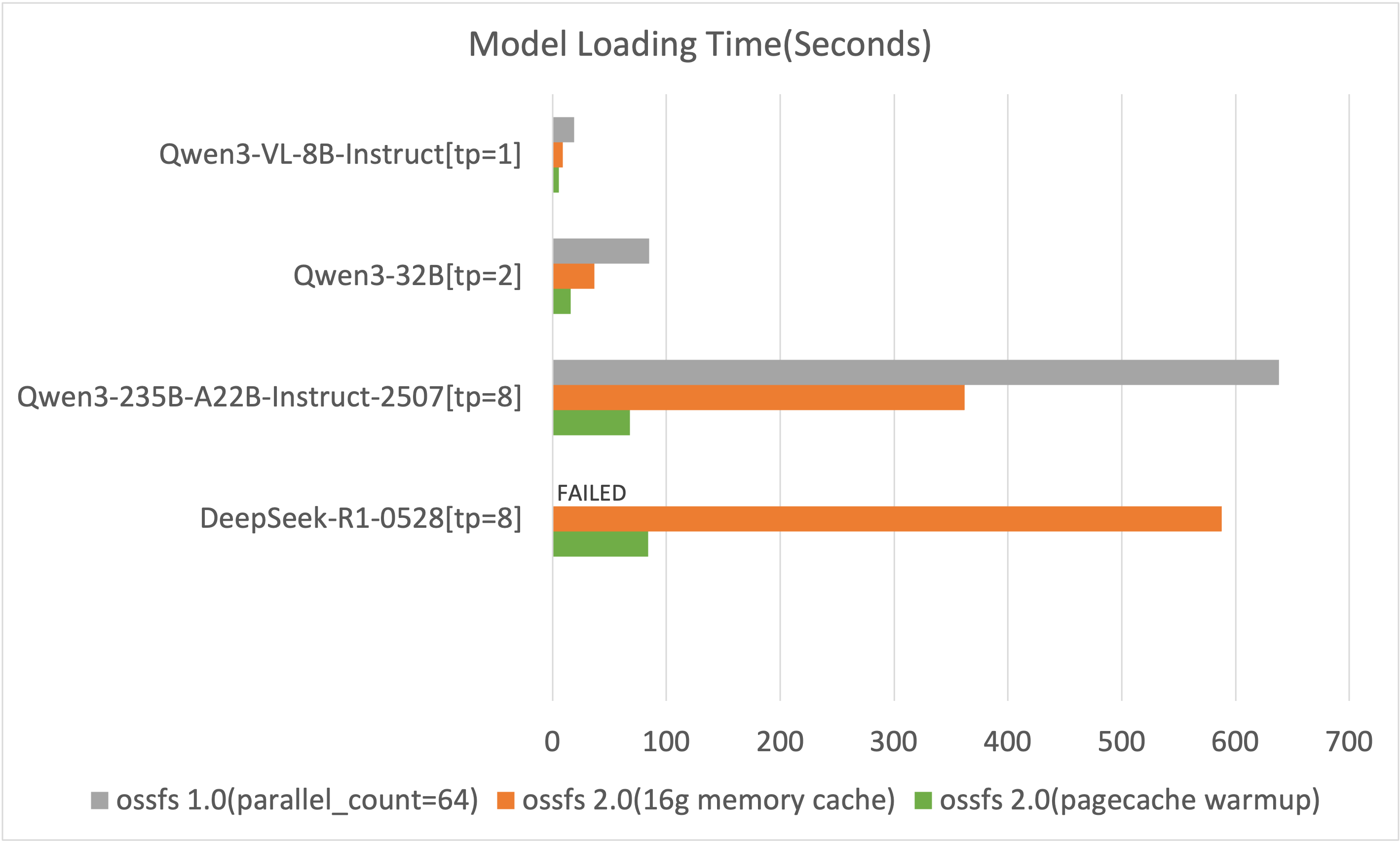
As shown in the figure above, ossfs 2.0 significantly reduces model loading time compared with version 1.0.
Deploy models in other formats
Deploying GGUF models
When a file is opened, ossfs 2.0 pre-allocates some memory for data prefetching and releases this memory after the file is closed. However, the llama.cpp framework currently does not close file handles after it finishes reading. For model repositories with a large number of files, memory is not available to prefetch subsequent files, which degrades loading efficiency.
When you use ossfs 2.0 to load this type of model, two optimization solutions are available:
PageCache prefetch solution: For more information, see PageCache prefetch deployment.
Unlimited prefetch memory solution: Configure
--prefetch_chunks=-1. With the default configuration, this uses up to approximatelynumber of model files × 1.5 GiBof additional memory.
If the GGUF model you are using is large and you cannot use either of the preceding solutions, use OSS Connector for AI/ML for model loading.
Deploying PyTorch models
When deploying a PyTorch model using EasyRec in a multi-GPU scenario, each GPU sequentially loads the entire model file once. Configuring the --memory_data_cache_size=4g mount option effectively reduces bandwidth amplification from concurrent reads and accelerates overall model loading.