This tutorial shows how to build a news classification pipeline in Platform for AI (PAI) using the preset Text Analysis-News Classification template in Machine Learning Designer—no code required.
Manually labeling news is labor-intensive. PAI's text analysis components automate this process using word segmentation, stop word filtering, topic modeling with the Partially Labeled Dirichlet Allocation (PLDA) algorithm, and KMeans clustering.
In this tutorial, you:
Create a news classification pipeline from a preset template in Machine Learning Designer.
Run the pipeline and inspect the clustering results.
Identify how to improve classification accuracy.
The dataset used in this tutorial is for experimental purposes only.
Prerequisites
Before you begin, make sure you have:
Activated Machine Learning Designer and created a workspace. See Activate PAI and create a default workspace.
Associated MaxCompute resources with the workspace. See Manage workspaces.
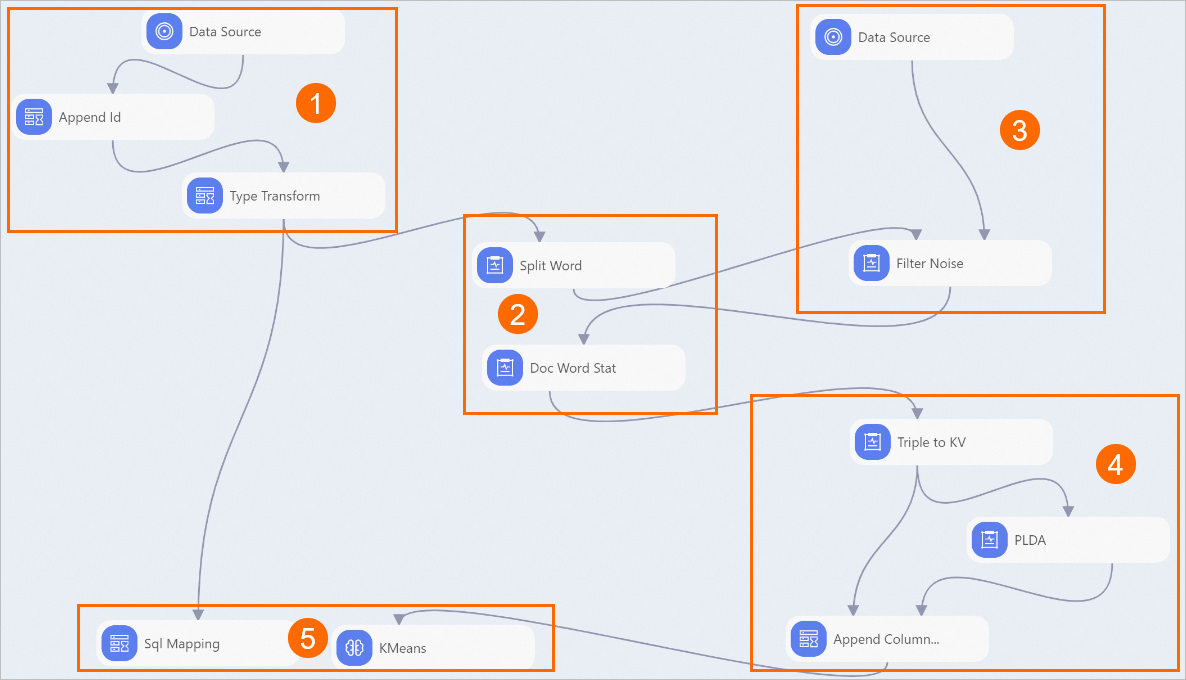
How the pipeline works
The pipeline runs five stages:
Add IDs — The Append Id component adds a unique
append_idto each news record. Downstream algorithms rely on this ID to track individual records.Tokenize — The Split Word component breaks each news article's
contentfield into individual words. The Doc Word Stat component then counts how often each word appears.Filter stop words — The Filter Noise component removes stop words—punctuation marks and grammatical particles that carry no topical meaning.
Model topics — Two components work in sequence:
Triple to KV converts word frequency data into the key-value format that PLDA requires. Each key is a numeric word ID; each value is the word's occurrence count.
PLDA trains a topic model across 50 topics. Its fifth output port produces the probability that each article belongs to each of the 50 topics.
Classify by clustering — After topic modeling, each article is represented as a 50-dimensional topic vector. The KMeans component clusters articles based on the distances between these vectors, producing the final news categories.
Why PLDA + KMeans? PLDA surfaces latent topics across the corpus without requiring labeled training data. KMeans then groups articles whose topic distributions are similar. Together, they enable unsupervised news classification—useful when manually labeled datasets are unavailable.
Create and run the news classification pipeline
Step 1: Open Machine Learning Designer
Log on to the PAI console.
In the left-side navigation pane, click Workspaces. On the Workspaces page, click the name of the workspace you want to use.
In the left-side navigation pane, choose Model Training > Visualized Modeling (Designer).
Step 2: Create the pipeline from a preset template
On the Visualized Modeling (Designer) page, click the Preset Templates tab.
In the Text Analysis-News Classification section, click Create.
In the Create Pipeline dialog box, review the parameters. The default values work for this tutorial. The Pipeline Data Path specifies the Object Storage Service (OSS) bucket path where the pipeline stores temporary data and models during a run.
Click OK. The pipeline takes about 10 seconds to create.
In the pipeline list, double-click Text Analysis-News Classification to open it.
The canvas shows all pipeline components, arranged in the order they run:
| Component | Role |
|---|---|
| Append Id | Adds a unique append_id to each news record |
| Split Word | Tokenizes the content field into words |
| Doc Word Stat | Counts word occurrences after stop word filtering |
| Filter Noise | Removes stop words (punctuation, grammatical particles) |
| Triple to KV | Converts word frequency data to key-value format for PLDA; parameters: append_id (unique news ID) and key_value (word ID : occurrence count) |
| PLDA | Trains a 50-topic model; the fifth output port outputs per-article topic probabilities |
| KMeans | Clusters articles by topic vector distance to produce final categories |
| Sql Mapping | Filters the output to display specific news records by append_id |
Step 3: Run the pipeline and view results
In the upper-left corner of the canvas, click Run.
After the run completes, right-click KMeans on the canvas and choose View Data > Output Clustering Table. The output table includes two fields:
Field Description cluster_indexThe assigned category name append_idThe unique ID of the news record 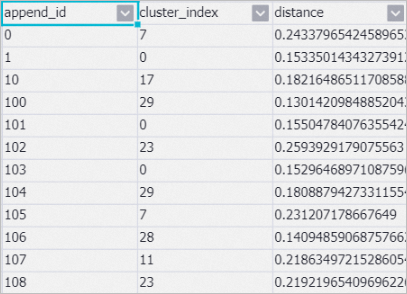
Right-click Sql Mapping on the canvas and choose View Data > Output Port to inspect four sample articles:
append_id115, 292, 248, and 166. The preset Filter Criteria for Sql Mapping is:
Interpret and improve the results
With the experimental dataset, the pipeline groups two sports articles, one financial article, and one science and technology article into the same category—the accuracy is limited. This is expected for small experimental datasets.
To improve classification quality, consider the following approaches:
| Approach | When to use it |
|---|---|
| Use a larger dataset | When the corpus is too small to surface distinct topic distributions. More articles give PLDA stronger signal to separate topics. |
| Apply feature engineering | When raw word counts carry too much noise. Applying feature engineering or parameter tuning on the dataset can sharpen topic boundaries. |
| Tune parameters | When the number of topics (currently 50) does not match the natural structure of your data. Reduce the topic count if categories are too granular, or increase it if categories blend together. |
What's next
To apply this pipeline to your own news dataset, replace the input data source and adjust the Pipeline Data Path to point to your OSS bucket.
To explore other text analysis use cases in PAI, see Machine Learning Designer overview.