Motivation
A recommendation system selects items to present to users, aiming for positive feedback like clicks or purchases. However, the system cannot predict a user's response, which makes it impossible to determine a recommendation's reward. The system can only learn by trying different options, collecting feedback, and refining its strategy. The goal is to minimize the potential loss of reward over time. This process is similar to a gambler playing slot machines. A gambler walks into a casino and sees a row of identical-looking slot machines. Each machine, however, has a different probability of paying out. The gambler does not know the payout distribution of any machine. How can they choose which machine to play at each turn to maximize their total winnings? This is the classic multi-armed bandit (MAB) problem.
The main challenge in the MAB problem is the exploration and exploitation dilemma. To achieve a high cumulative reward, you should more often play machines known to have a high payout probability (exploitation). However, you must also test unknown or less-played machines to discover potentially better options (exploration). However, more exploration comes with higher risk and opportunity cost.
Cold start problem
Newly listed items have no historical data. How should traffic be allocated to learn their potential and maximize user satisfaction?
The feedback loop problem in recommendation systems
The algorithm decides what content to show. The content shown influences user behavior. User behavior then provides feedback that trains the algorithm, creating a feedback loop. In this loop, the assumption from supervised learning that training and test data are independent and identically distributed does not hold. Without an effective exploration mechanism, the system can become trapped in local optima.
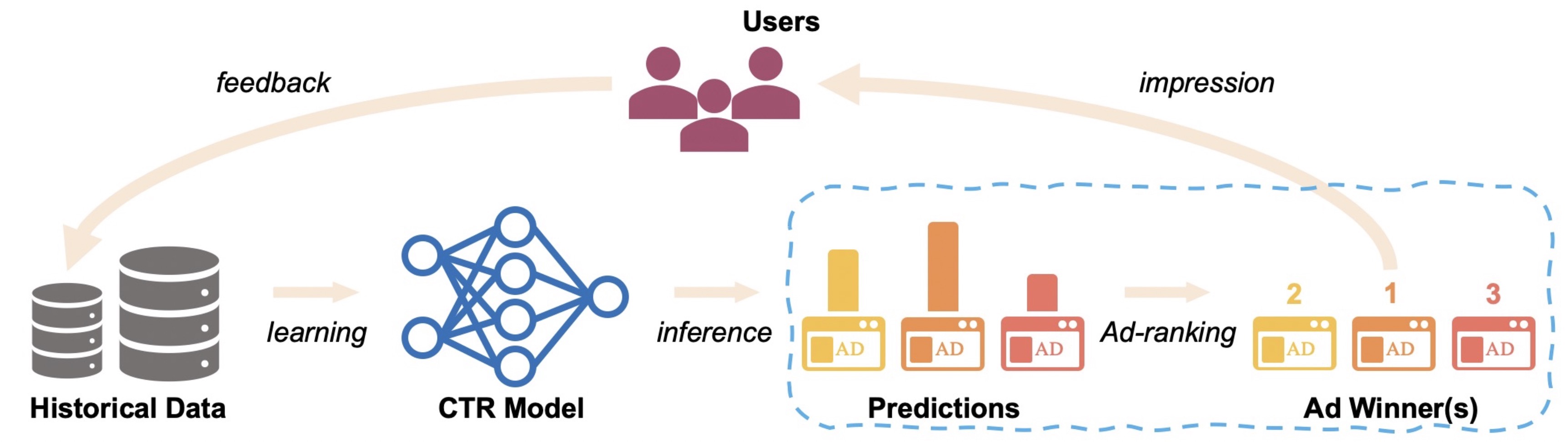
The feedback loop problem is especially pronounced in scenarios with sparse user behavior. With limited data, you cannot make predictions with absolute confidence. Exploration and exploitation are the key to breaking the feedback loop.
Algorithm overview
Bandit algorithms effectively balance exploration and exploitation. They handle the cold start problem without requiring a large amount of historical data. They also help avoid the Matthew effect, which arises when item weights are based solely on rewards versus impressions, a practice that leaves most long-tail and new items with no exposure. A recommendation system designed with bandit algorithms can effectively address these issues.
Algorithm pseudocode (single-play bandit algorithm):

Key differences from traditional methods:
-
Each candidate item has its own independent model. This avoids the sample distribution imbalance problem of traditional, monolithic models.
-
Traditional methods use a greedy policy that fully exploits learned knowledge. This easily leads to a filter bubble due to the Matthew effect. In contrast, bandit algorithms have an explicit exploration mechanism, giving less-exposed items a higher chance of being displayed through weighting.
-
As an online learning solution, the model updates in real time. Compared to A/B testing, it converges to the optimal policy faster.
To recommend multiple candidate items in a single request, use the multiple-play bandit algorithm.
Algorithm 2: Independent Bandit Algorithm
1 SPB_i : single-play bandit algorithm for
recommendation i
2 for t = 1, ..., T do
3 for i = 1, ..., m do
4 a_i ← selectItem(SPB_i, K\A_{t,i-1})
A_{t,i} ← A_{t,i-1} ∪ a_i
5 end
6 Display A_t to user, receive feedback vector X_t
7 for i = 1, ..., m do
8 Feedback:
z_i = { 1 if item a_i was clicked on
{ 0 otherwise }}
update(SPB_i, z_i)
9 end
10 endAlgorithm details
Bandit algorithms are a class of strategies that implement the exploration and exploitation mechanism. Depending on whether they use contextual features, bandit algorithms fall into two main categories: context-free bandit and contextual bandit.
1. UCB
There are many types of context-free bandit algorithms, such as epsilon-greedy, softmax, Thompson sampling, and upper confidence bound (UCB).

The upper confidence bound (UCB) algorithm uses the upper bound of the confidence interval of the mean reward (bonus) as the estimated future reward of an arm:
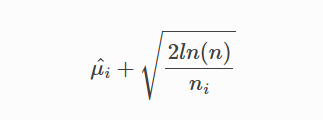

At each step, UCB chooses the arm with the highest upper confidence bound. The advantage of this strategy is that it gives less-tested arms a higher chance of being selected, allowing for a more accurate assessment of their potential.
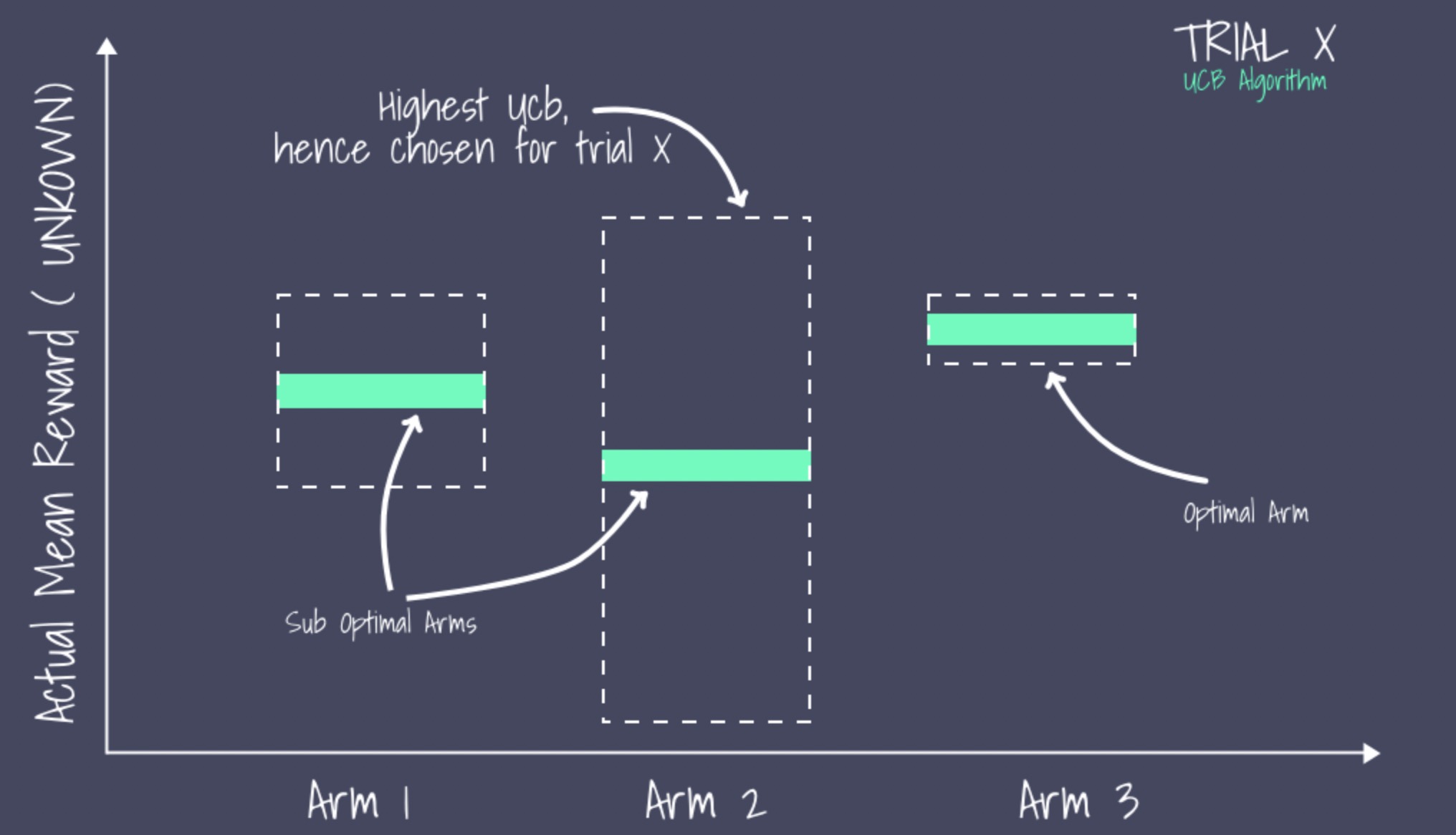
Image and some content are from "Experiences and Pitfalls of Deploying Contextual Bandit (LinUCB) Algorithms in Production Recommendation Systems" on zhihu.com.
-
For an unknown or rarely tried arm, even if its mean reward is low, its high uncertainty results in a wide confidence interval. This makes the upper bound large, increasing the probability of triggering exploration.
-
For well-known arms that have been tried many times, the policy tends to trigger exploitation: if the mean reward is high, the arm gets more pulls; otherwise, it gets fewer.
2. LinUCB
In a recommendation system, the items to be recommended are typically treated as the arms of the MAB problem. Context-free algorithms like UCB do not fully utilize the contextual information available in a recommendation scenario. This approach ignores that users have different interests, preferences, and purchasing power. The appeal of the same item can vary greatly among different users and in different situations. Therefore, context-free MAB algorithms are generally not used in real-world recommendation systems.
In contrast to context-free MAB algorithms, contextual bandit algorithms consider contextual information when balancing exploration and exploitation. This makes them better suited for real-world personalized recommendation scenarios.

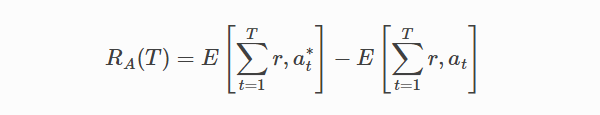
Here, T is the total number of trials, and at* is the arm with the maximum expected reward at time step t, which is unknown.




Advantages of the LinUCB algorithm:
-
Computational complexity scales linearly with the number of arms.
-
It supports a dynamic set of candidate arms.
References
-
Implementation and Application of Contextual Bandit Algorithms in Recommendation Systems
-
Experiences and Pitfalls of Deploying Contextual Bandit Algorithms in Production Recommendation Systems
-
Using Multi-armed Bandit to Solve Cold-start Problems in Recommender Systems at Telco
-
A Multiple-Play Bandit Algorithm Applied to Recommender Systems
-
Adapting multi-armed bandits polices to contextual bandits scenarios