The PAI-RAG Web UI lets you configure models, knowledge base chunking, the Code sandbox, search services, and MCP tools. These settings allow you to fine-tune the retrieval and question-answering behavior of your RAG system.
Configure models
Click Settings > Model in the lower-left corner. On the LLM tab, add a model.
All-in-one deployments generate a model configuration record automatically. You can add models from other sources.
-
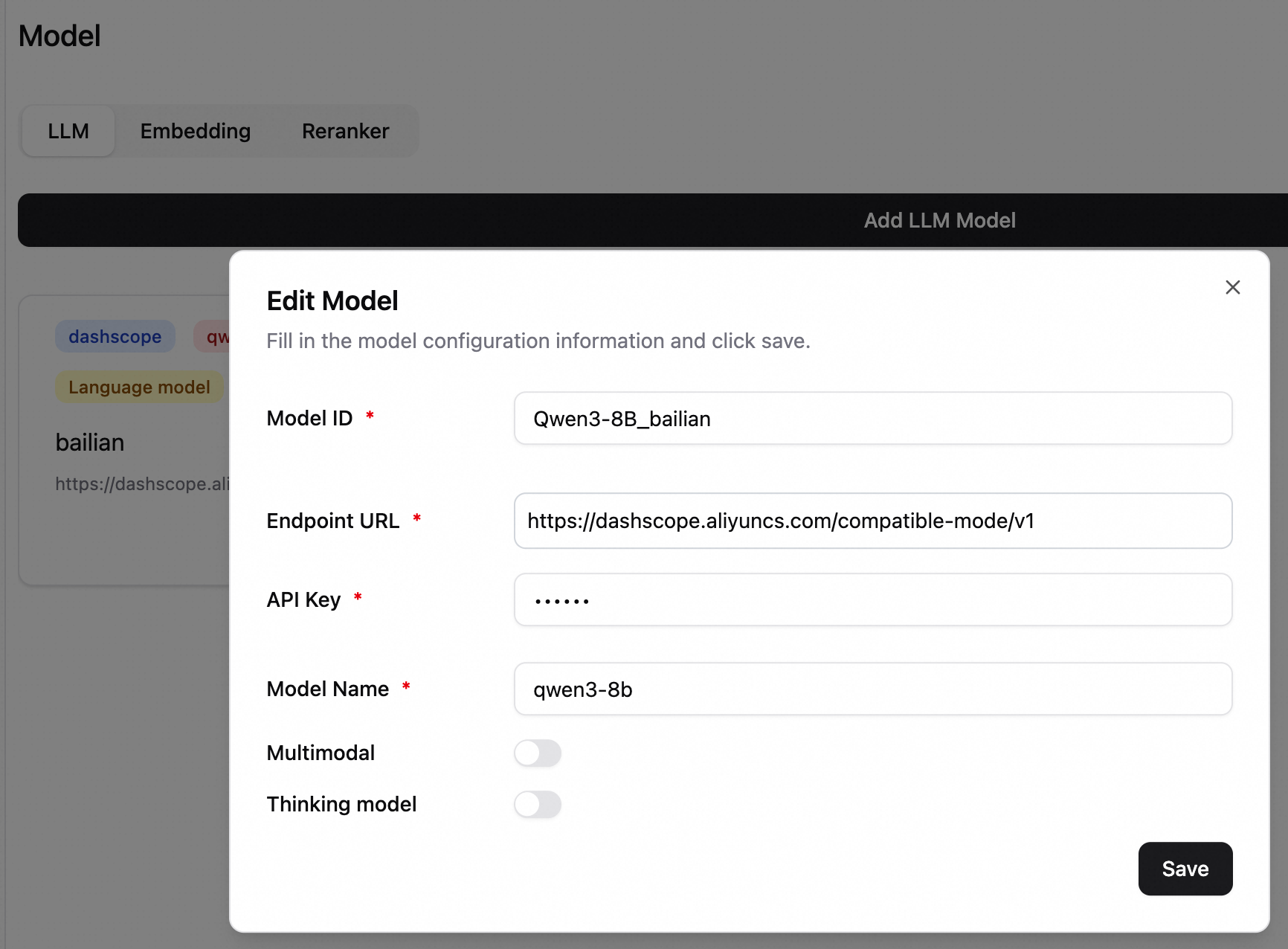
Model ID: Identifies a model configuration.
-
Endpoint URL: The service endpoint of the model.
Note-
Alibaba Cloud Model Studio models are billed separately. Billing of Alibaba Cloud Model Studio.
-
For EAS model services, go to the service details page, click Basic Information, and then click View Endpoint Information. Append
/v1to the endpoint URL.-
Internet endpoints require the RAG service to have public network access configured in the VPC.
-
VPC endpoints require the RAG service and LLM service to be in the same VPC.
-
-
-
API Key: For Alibaba Cloud Model Studio, obtain an API key. For EAS services, enter the token from the endpoint information.
Model Name: The value depends on your deployment. If your LLM service is deployed on EAS with the vLLM inference engine, enter the specific model name, which you can retrieve by using the
/v1/modelsAPI. For all other deployment modes, set this todefault.Multimodal model: Select this option if you are using a multimodal model. This option is cleared by default.
Thinking model: For models that support both thinking and non-thinking modes, use this option to enable or disable thinking. This option is cleared by default.
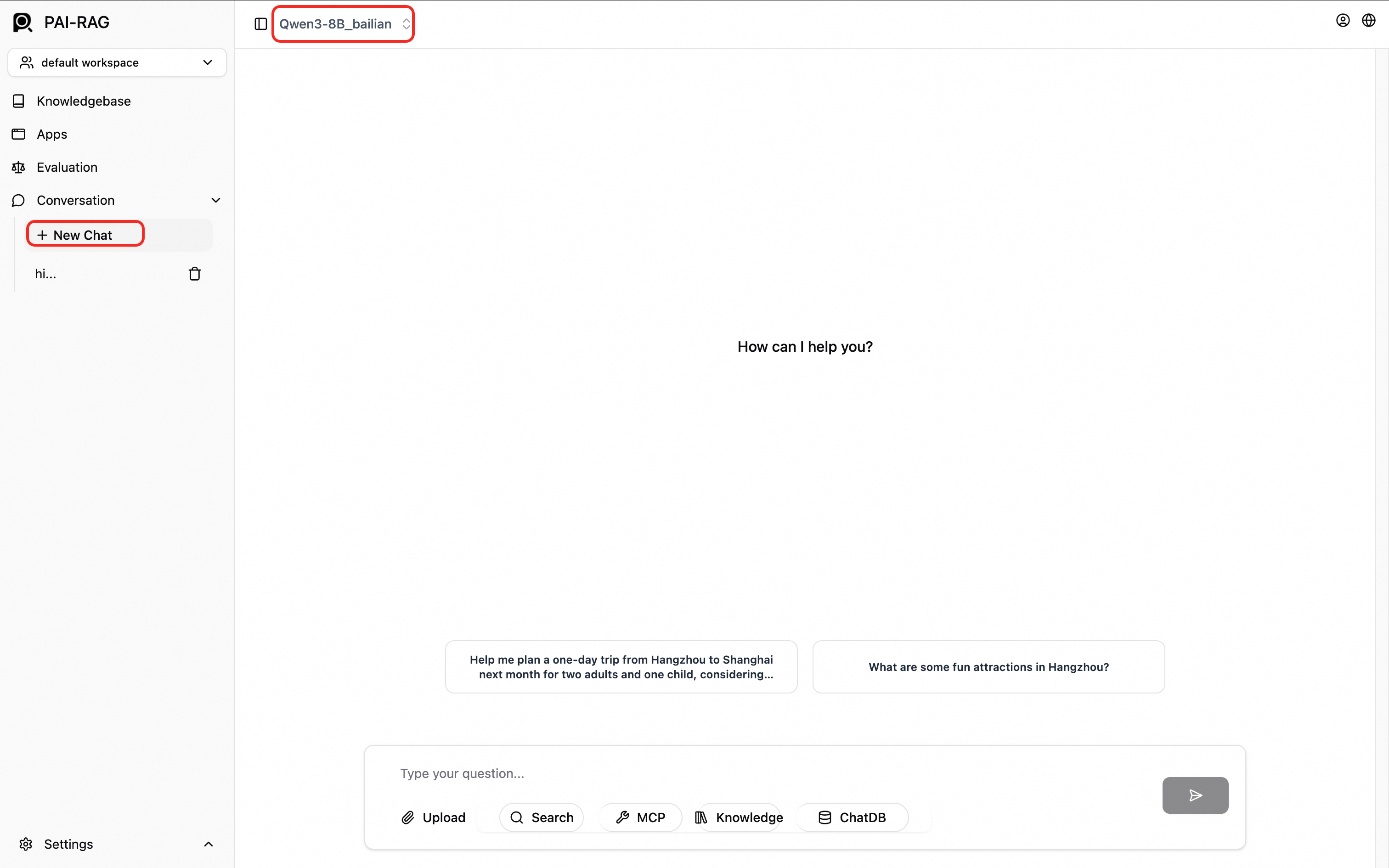
After configuring the model, test it. Click New Chat in the left navigation pane, select the model at the top of the chat page, and start a conversation.
Configure MCP
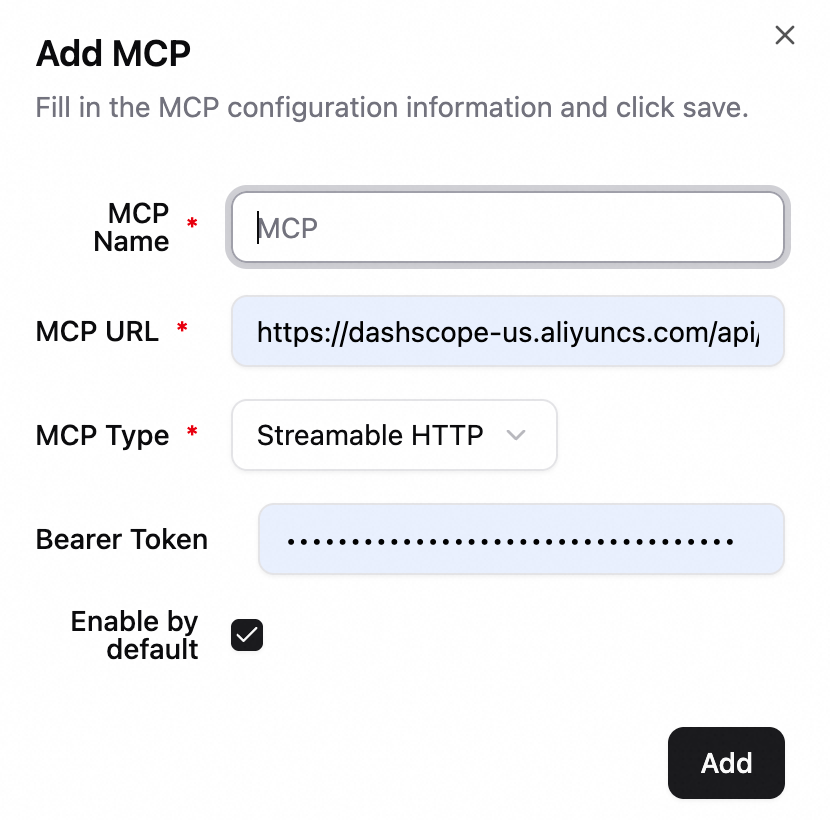
Click Settings > MCP in the lower-left corner to add an MCP.
-
MCP Link: The MCP service endpoint URL.
-
MCP Type: SSE, STDIO, or Streamable HTTP.
-
Bearer Token: (Optional) Access token for Bearer token authentication.
Configure search
If the knowledge base lacks the information to answer a user's question, or if the answer requires real-time information, enable a search service (Tavily or Alibaba Cloud General Search).
Click Settings > Search in the lower-left corner.
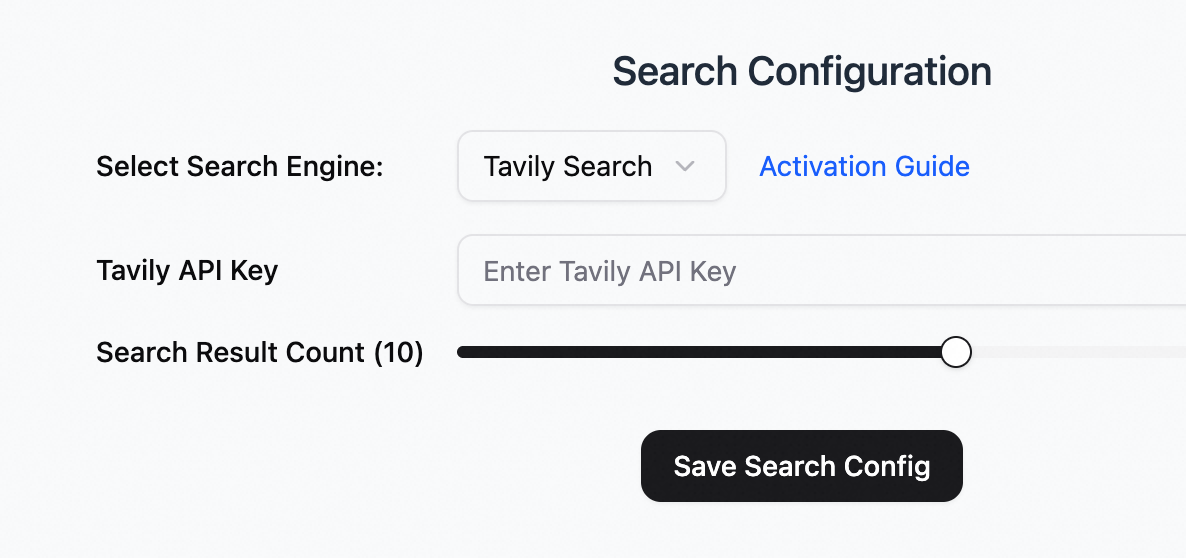
Tavily search
Register at the official Tavily website and obtain an API key.
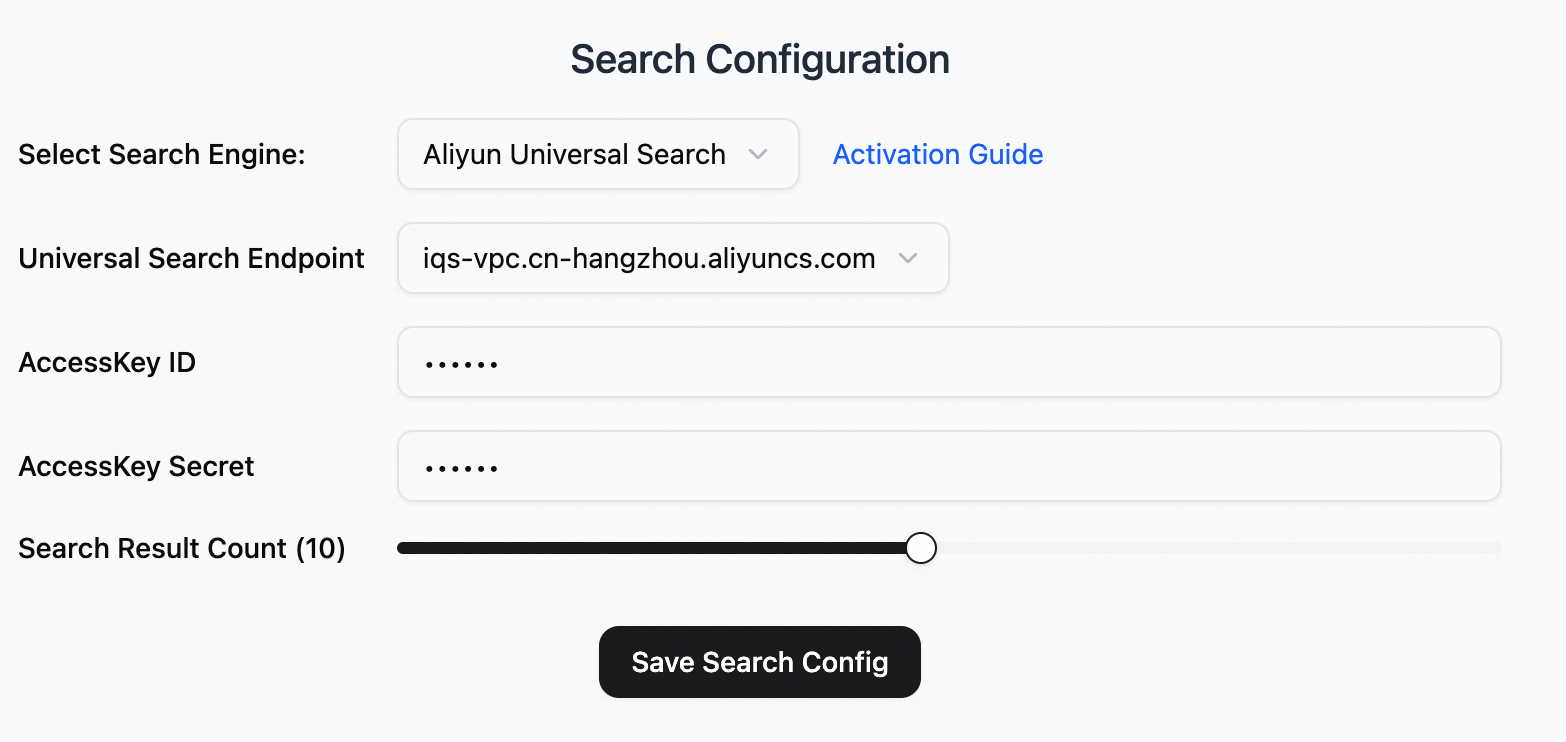
Alibaba Cloud General Search
General Search Endpoint:
-
VPC access is recommended. For regions without VPC support, use a public endpoint. Endpoints.
-
Public endpoints require the RAG service to have public network access configured in the VPC.
AccessKey ID and AccessKey secret:
-
Create a RAM user and grant permissions. For access mode, select Use permanent AccessKey for access. After the user is created, copy the AccessKey ID and AccessKey secret.
You must grant the AliyunIQSFullAccess permission to the RAM user. Otherwise, search operations will fail.
Configure the Code sandbox
The Code sandbox provides a secure Python code execution environment. When enabled, the AI assistant automatically uses the Code sandbox to run code.
Scenarios
-
Data analytics: Statistics, aggregation, and filtering. Example: "Analyze sales data and calculate the average sales per region."
-
Data visualization: Chart generation and trend plotting. Example: "Plot the sales trend for the past year."
-
Mathematical operations: Complex calculations and equation solving. Example: "Calculate the standard deviation of this sequence."
-
File processing: Parse CSV, Excel, and other files to extract and transform data.
-
Other tasks that require code execution
Prerequisites
Before configuring the Code sandbox, complete the following steps:
-
Activate Function Compute: Go to the Function Compute console and follow the prompts to activate it.
-
Create an AgentRun interpreter: Go to the AgentRun console. Choose Sandbox in the left navigation pane. Create a sandbox template with type Code Interpreter.
NoteThe default Network Type is Allow the default NIC to access the public network, which requires the RAG service to have public network access.
Alternatively, select Allow access to VPC and configure the same VPC for the RAG service.
-
Obtain the Alibaba Cloud account ID and Sandbox ID. If you configured access credentials, also obtain an API key.
Configuration
Click Settings > Code Sandbox in the lower-left corner and configure the following parameters:
-
Enable Sandbox: Turns the sandbox feature on or off.
-
Sandbox Type: Only Alibaba Cloud FC sandboxes are supported.
-
Alibaba Cloud ID: Your Alibaba Cloud account ID.
-
Interpreter ID: The sandbox ID.
-
Interpreter Name: The name of the code interpreter.
-
API Key: The AccessKey pair used for identity verification.
-
Default Timeout (s): Maximum code execution duration in seconds. Default: 50.
Configure the file chunking policy
Chunking settings define the chunking method for documents in a knowledge base. This determines how documents are split into chunks for vectorization and retrieval. Proper chunking settings can improve recall and answer quality.
Chunking can be configured at two levels:
Knowledge base chunking settings: Files uploaded to the knowledge base are parsed by using its default settings.

File level:
When you upload a file, you can specify its chunking parameters individually.
When you perform a reparse operation on an existing file, you can also specify new chunking settings to trigger reprocessing.
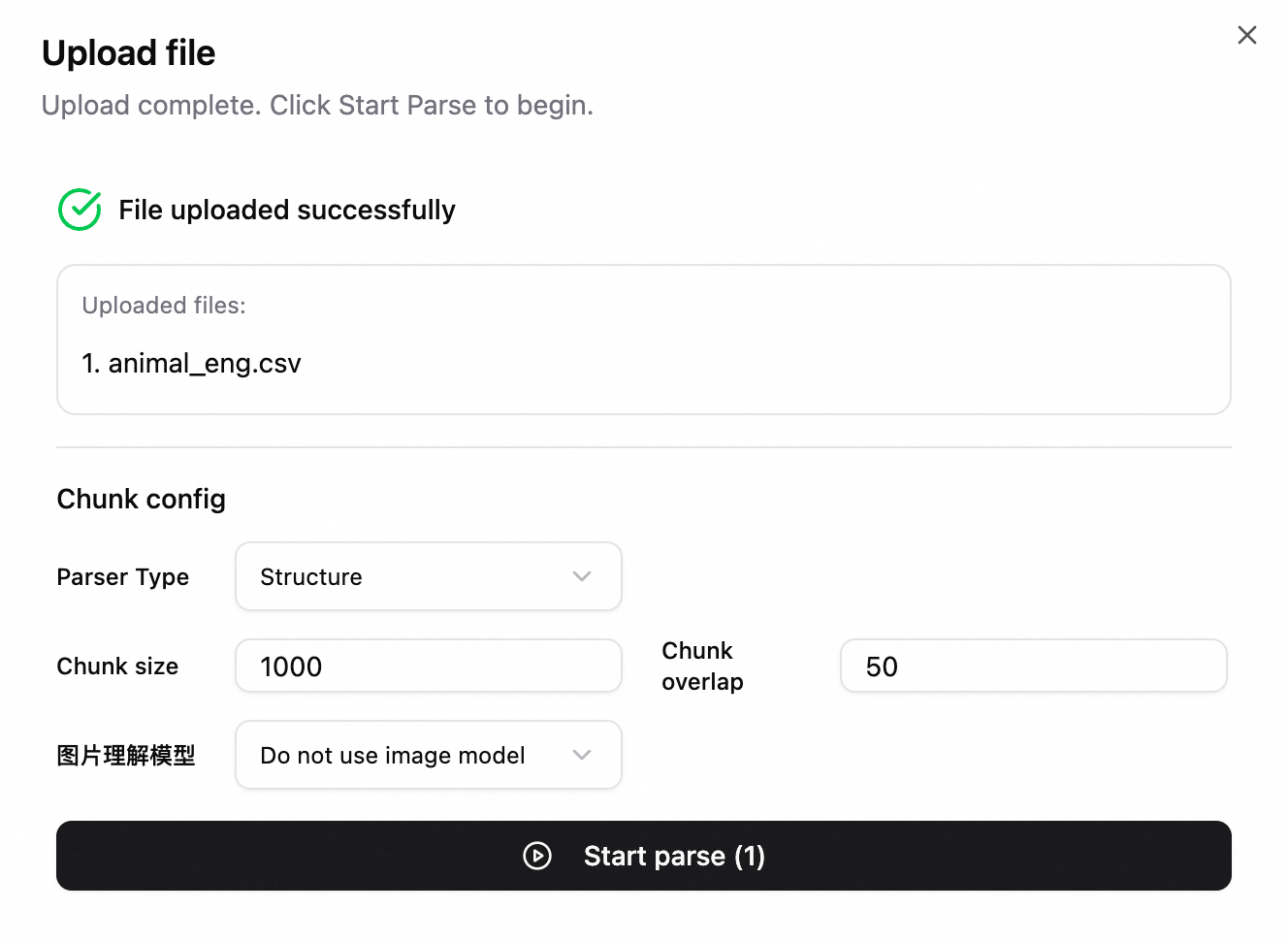
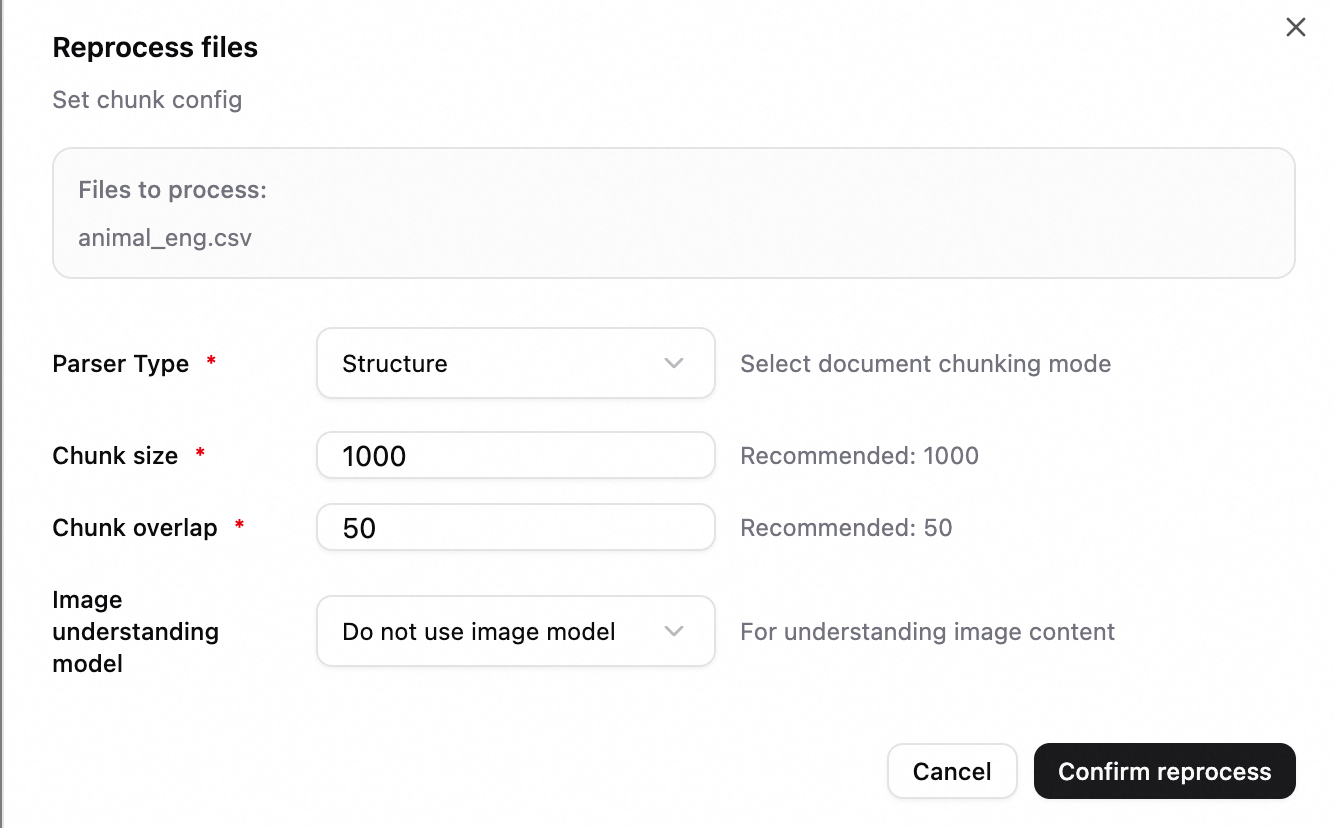
Prerequisites
Before you configure chunking settings, meet the following prerequisites:
-
A knowledge base: An active knowledge base exists in the system.
-
An embedding configuration: At least one embedding model is configured.
-
(Optional) A multimodal model: Required for image understanding. Configure a vision model in the system.
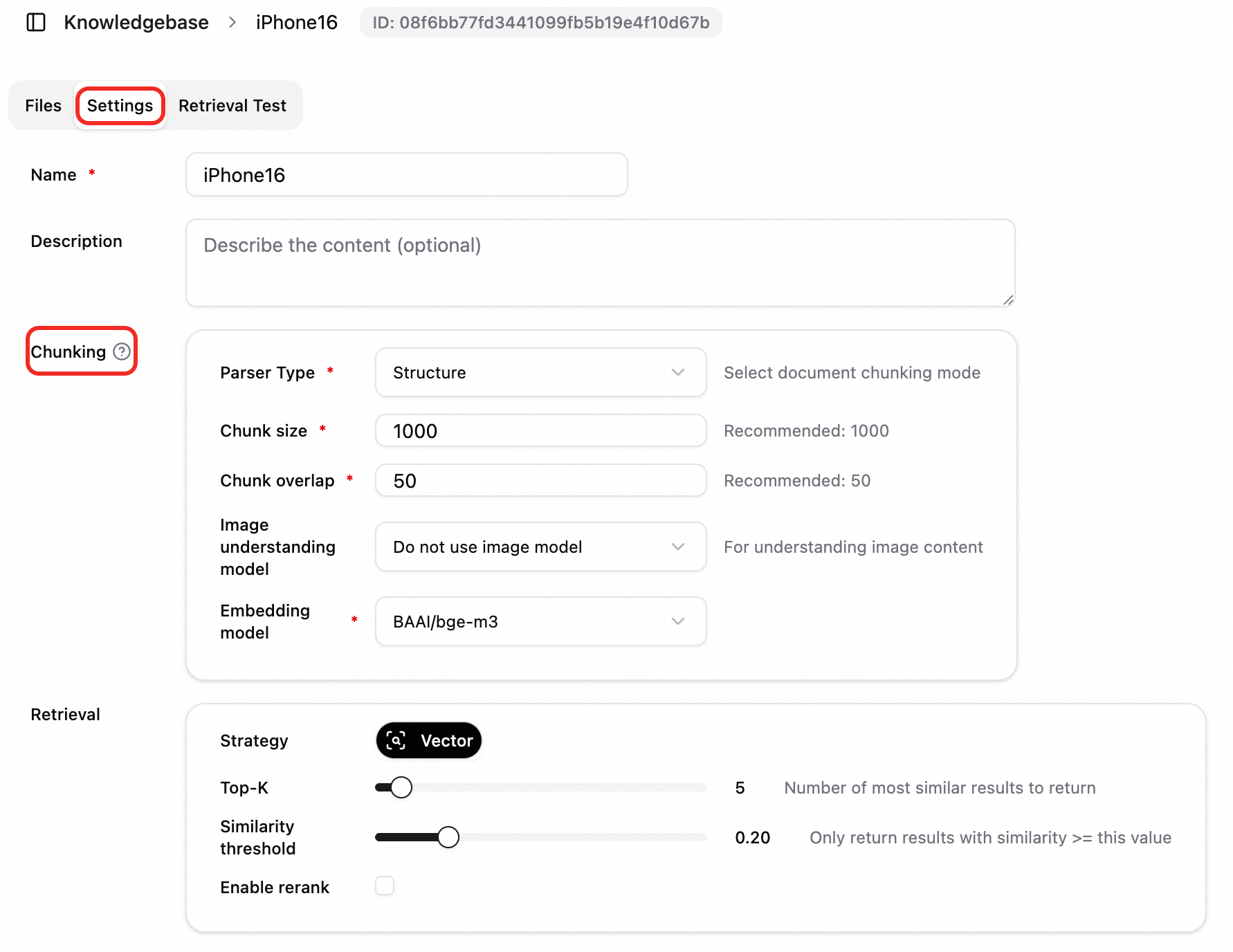
Parameter description
|
Parameter |
Description |
|
Chunk Type |
Select a chunk type based on document characteristics:
|
|
Chunk Size |
Maximum length of each chunk in characters or tokens, depending on the chunk type. Recommended: 1000. |
|
Chunk Overlap | The length of the overlap between adjacent chunks. This preserves context and prevents semantic breaks. Recommended: 50. Important
Chunk size must exceed chunk overlap. |
|
Image Understanding Model |
|
|
Vector Model |
|
Tuning suggestion: Upload a few documents with default settings first. Analyze recall and accuracy in the evaluation module, then adjust parameters based on the results.
Usage suggestions
-
RAG for long documents: Set Chunk Type to Structured, Chunk Size to 1000, and Chunk Overlap to 50. This controls chunk length while preserving context.
-
Strict chunking by separator: Use Paragraph chunking with a custom separator.
Tabular data: Select the Table (table) chunk type, then configure the header rows and row delimiter. If you do not select Merge rows, the system chunks data by row. If you select Merge rows, the system merges rows into blocks based on the chunk size limit.
-
Multimodal documents: Enable Image Understanding Model to include image content from PDFs and other documents in retrieval and answer generation.
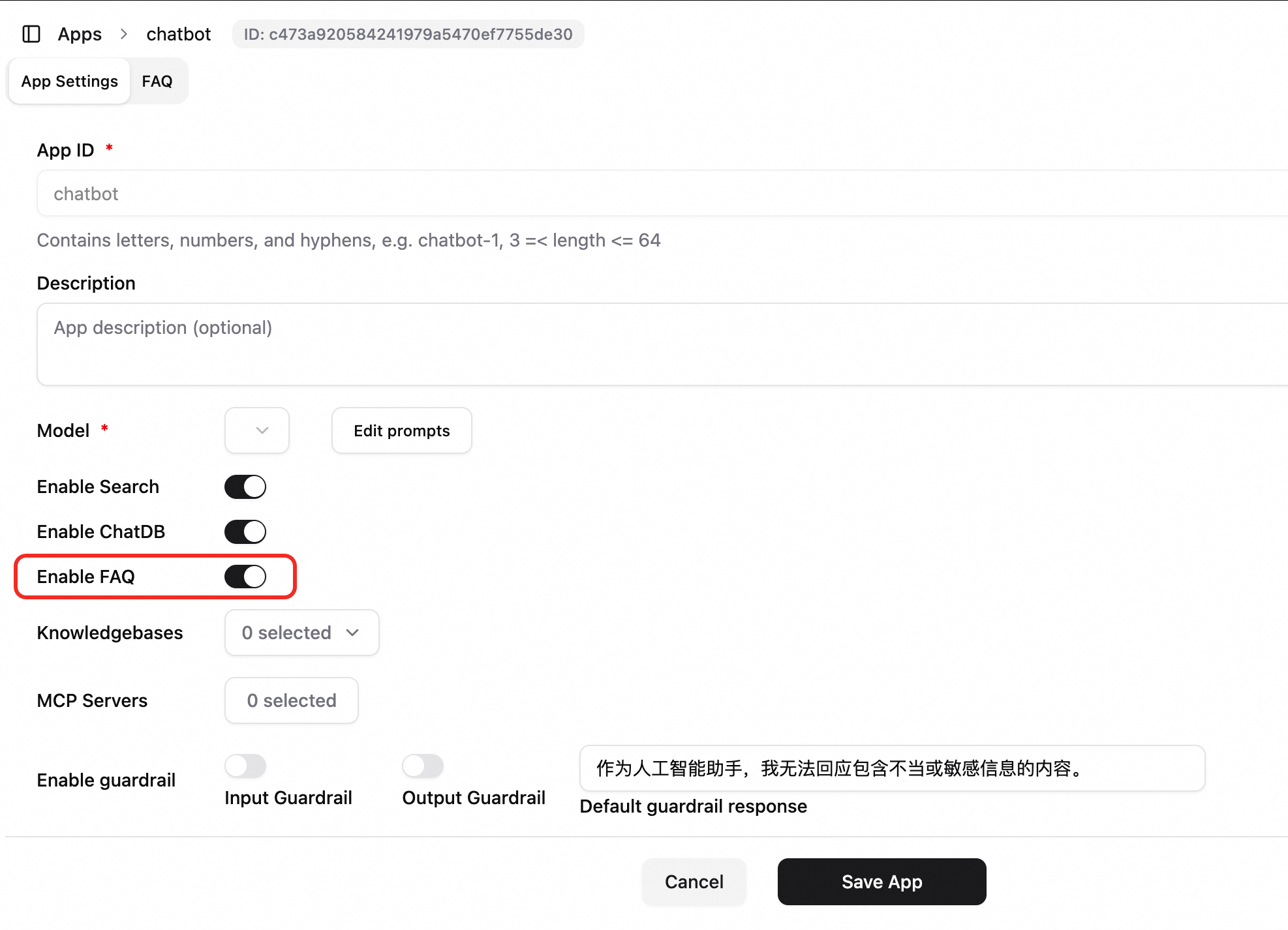
Configure the application FAQ
The FAQ feature maintains a question and answer knowledge base per application. Use it for product manuals, customer service scripts, and frequently asked questions.
With FAQ enabled and entries configured, conversations follow this flow:
-
The AI assistant retrieves the FAQ entry most similar to the user's question.
-
If a match meets the similarity threshold, the system either returns the FAQ answer directly or generates an answer with the model based on the FAQ result, depending on the configuration.
-
If no match is found or the direct return option is not enabled, the system falls back to other capabilities such as the knowledge base and search.
Configuration:
-
Log on to the system and go to the configuration page of the target application.
Enable FAQ: In the application configuration, enable the Enable FAQ switch and save your changes.
Open the FAQ management page to perform the following:
-
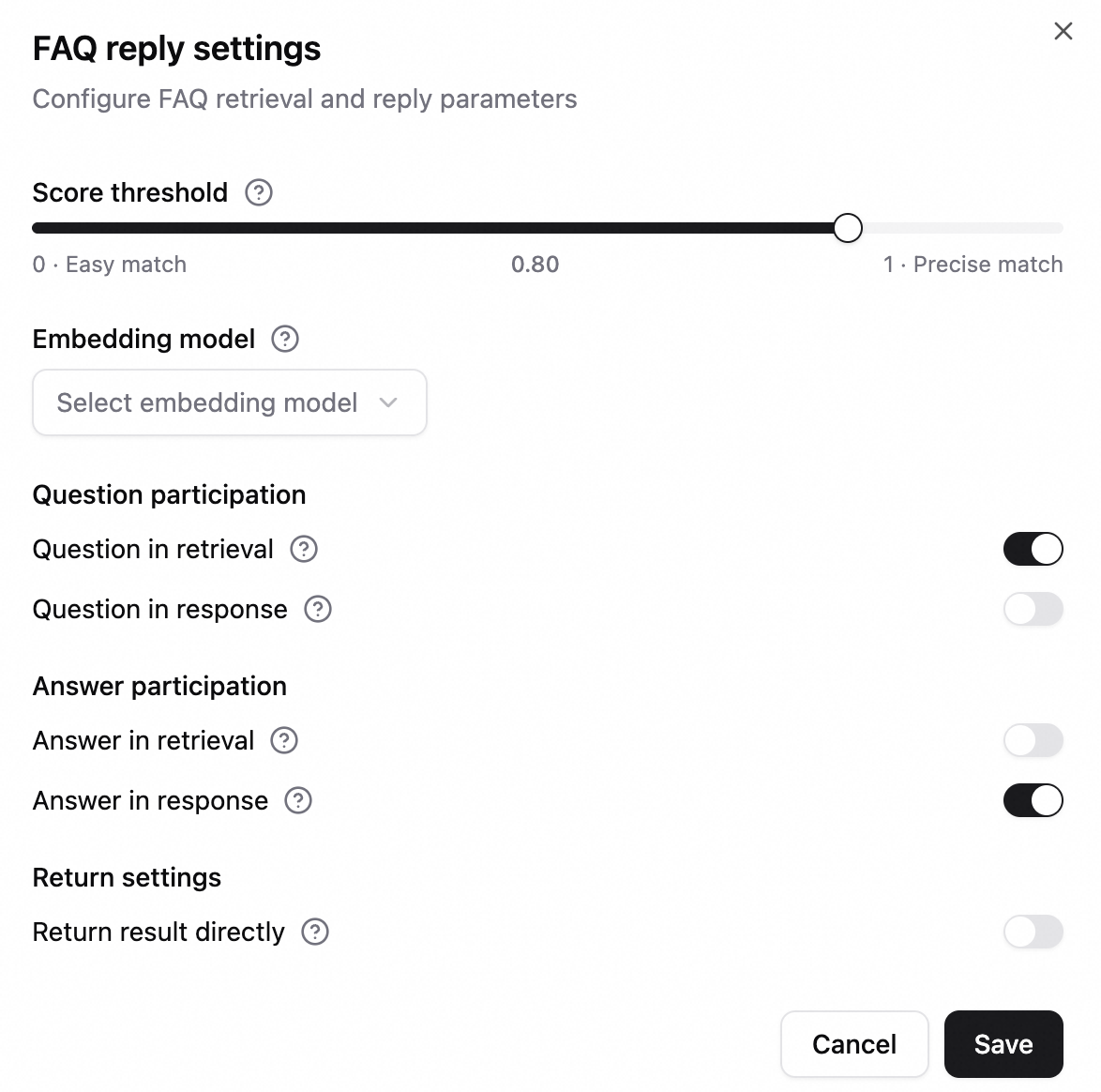
FAQ Reply Settings: Click Settings. Configure the similarity score threshold (0.8 to 1.0 recommended), the embedding model, whether to include questions or answers in retrieval and display, and whether to return tool results directly.
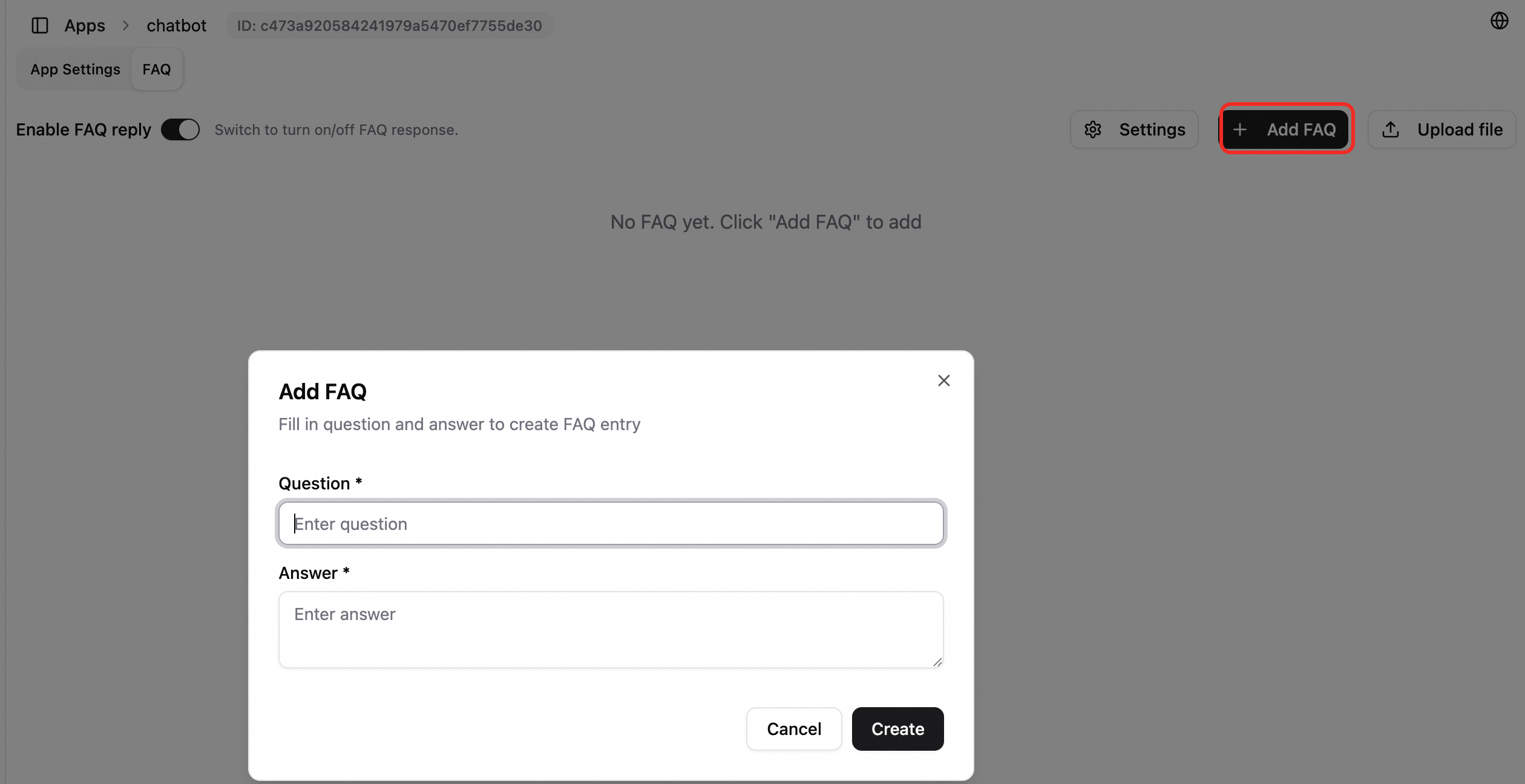
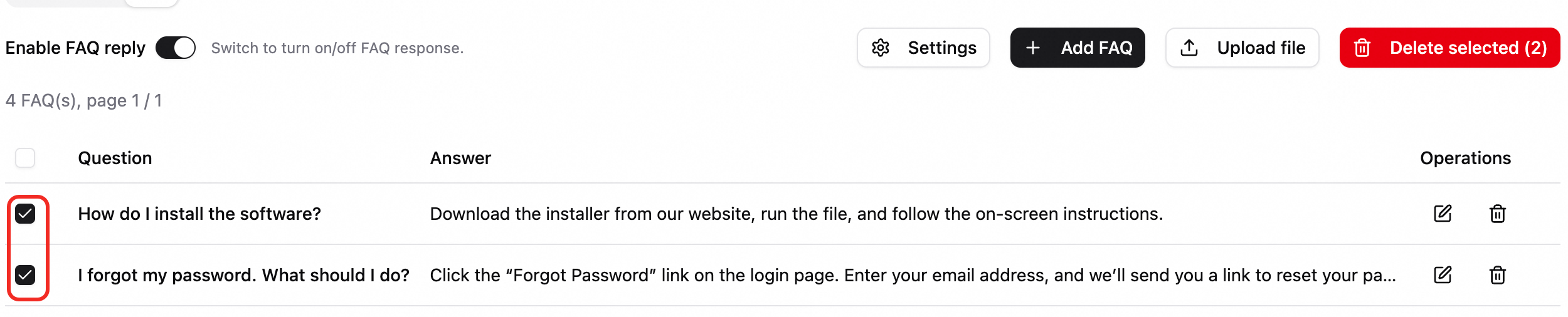
Manage FAQs:
Add, edit, or delete a single FAQ entry.
Delete entries in batches.
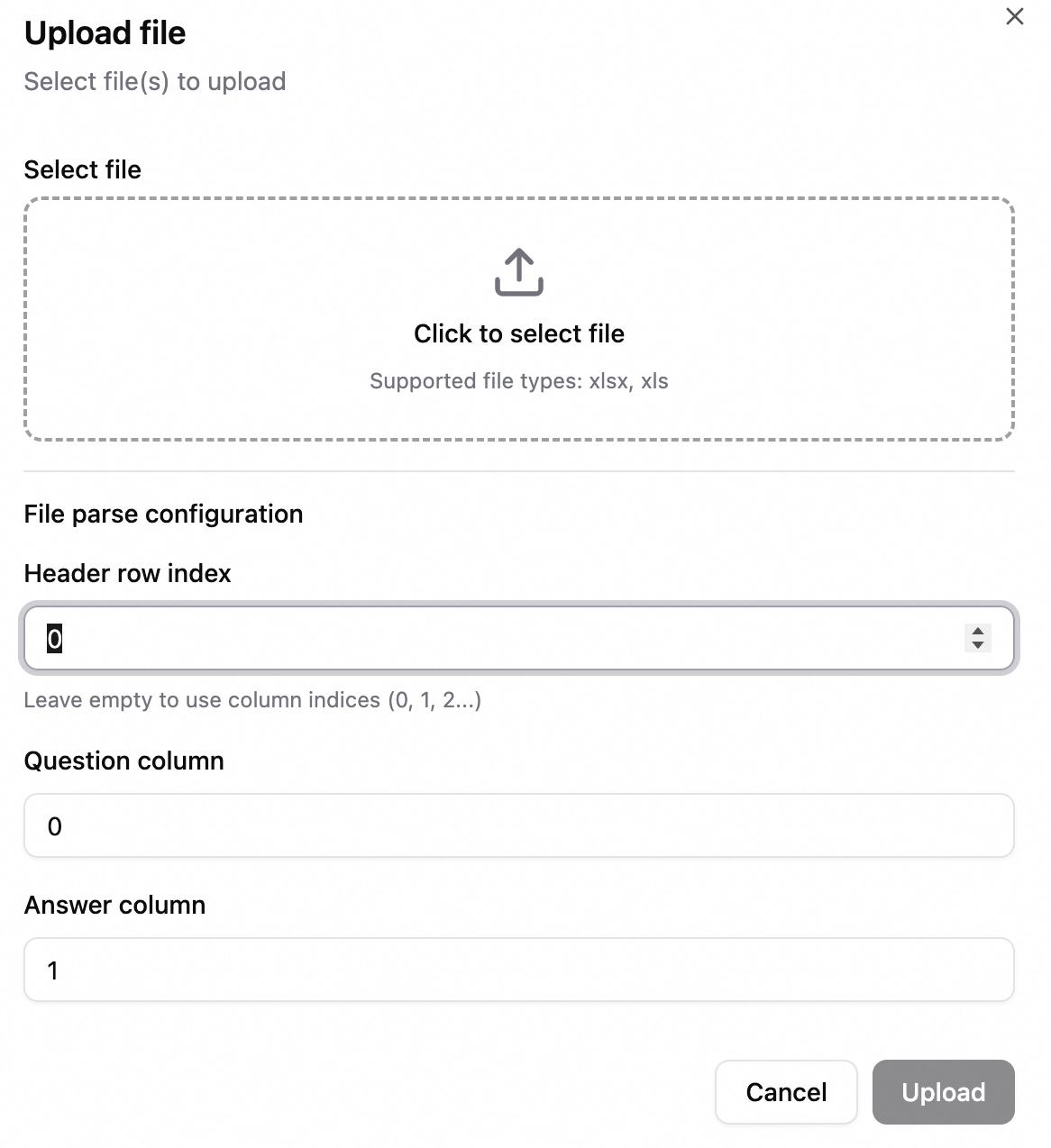
Batch import: Upload an Excel file, map the question and answer columns, and then import the entries with one click.
-
-
After saving, conversations in this application automatically prioritize FAQ retrieval.