Prometheus is a widely used open-source project for time series data monitoring and one of the most popular projects in the CNCF. It efficiently collects and stores metrics and provides a flexible query language, PromQL, to compute and analyze this time series data. However, because PromQL's syntax differs significantly from traditional SQL, developers often find its results confusing. This article explains the PromQL evaluation model with diagrams and step-by-step breakdowns of specific queries.
PromQL vs. SQL
Before we begin, it's important to understand a key point: PromQL is not SQL. It is an approximate query language with features such as backfilling via lookback, boundary extrapolation, and window-based evaluation. The following table summarizes the key differences.
| Dimension |
PromQL |
SQL |
| Data model |
Based on time series: metric name + labels + timestamp + value. |
Based on tables: rows + columns. |
| Index structure |
Uses efficient label-based indexes. No manual management required. |
Relies on database indexes, which require manual optimization. |
| Basic syntax |
No |
Built around |
| Time and filter conditions |
Time range is specified via API parameters ( |
Time range and filters are typically specified together in the |
| Data point pre-selection |
Before evaluation, data points are pre-selected based on parameters like lookback delta and window size. |
None. |
| Aggregation and grouping |
Supports various aggregation operators with |
Uses aggregate functions like |
| Joins and associations |
Uses operators like |
Uses |
| Subqueries |
Supports subqueries, for example:
|
Supports subqueries, for example:
|
| Result type |
Returns a vector or matrix. |
Returns tabular data (rows and columns). |
How PromQL works
All calculations in PromQL are based on the concept of a time series. In the context of time series, what is being measured is called a metric. For example, the metric process_resident_memory_bytes represents process resident memory usage. In the Prometheus data model, a single time series is represented by a set of Key-Value pairs and consists of a metric and a list of labels:
-
Metric: The
Keyis set to"__name__", and theValueis "MetricName", which represents the name of the metric. -
Labels: A list of key-value pairs that act as additional dimensional attributes. For example,
job="demo", instance="demo.promlabs.com:10000"means that the process name is demo and the machine instance IP is demo.promlabs.com:10000.
In addition to a Metric and Labels, a single monitoring data point also consists of a timestamp and a value, which represent the collection time and the numerical value of the data point, respectively. For example, the following figure (with the PromQL query process_resident_memory_bytes{}/1024/1024) contains three time series:
-
__name__="process_resident_memory_bytes", instance="demo.promlabs.com:10000", job="demo" -
__name__="process_resident_memory_bytes", instance="demo.promlabs.com:10001", job="demo" -
__name__="process_resident_memory_bytes", instance="demo.promlabs.com:10002", job="demo"
The value for each time series changes over time, effectively tracking how a monitored object changes.
The previous examples performed only a simple query on the process_resident_memory_bytes metric and did not cover various PromQL features, such as aggregation operators (avg/sum/count/max/min), window functions (rate/increase/avg_over_time/sum_over_time), non-window functions (abs/clamp/round/sort/label_replace), vector matching (group_left/group_right), binary expressions, and subqueries. For a complete list of supported syntax features, see Prometheus Querying.
A PromQL query API call primarily includes the following three parameters:
-
start/end: The time range for the query. -
query: The PromQL query string. -
step: The interval at which to evaluate the query for each round of computation.
The step concept
As mentioned earlier, PromQL is an imprecise query language. This is largely due to the step parameter in the PromQL execution engine. The step parameter specifies the interval at which calculations are performed within a given time range [start, end]. From the start time to the end time, a calculation is performed at each step interval. For example, if the start parameter is "10:00:00", the end parameter is "10:11:30", and the step parameter is "120s", the first calculation is performed at "10:00:00" and the sixth calculation is performed at "10:10:00". Because the seventh calculation would occur after the specified end time, only six calculations are performed in total.
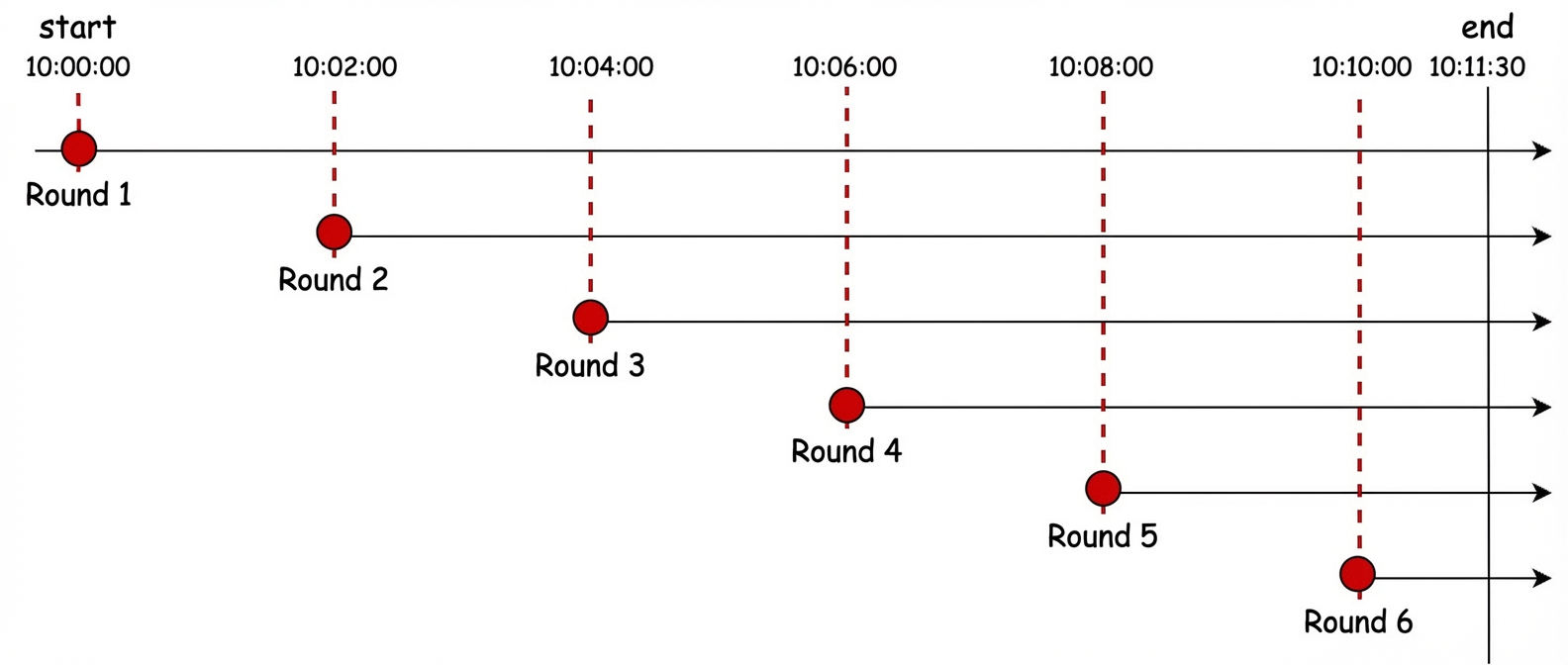
It is important to emphasize that in the Prometheus execution engine, every kind of PromQL evaluation—including all aggregation operators, functions, and binary expressions—follows the same rule: evaluate in multiple rounds at the given step interval. From a processing perspective, the step parameter can be seen as a design choice that trades precision for performance, especially for long-range queries where the step can be several hours (for example, 1h or 1d). In such cases, the evaluation process skips large time intervals, and the results only show the general trend of the metric.
The data point selection mechanism
In standard SQL calculations, all data points that fall within the input time range [start, end] and satisfy the WHERE clause are included in the calculation. Calculations in PromQL, however, are significantly different. For each evaluation step at a specified interval "step", the data points used in the calculation are selected based on a special 'point selection' logic. The two main 'point selection' methods are look-behind point selection based on the lookback-delta parameter, and range point selection based on the [xx] parameter of a window function.
Lookback-based point selection
Time-series data is typically collected and reported at fixed intervals. However, PromQL queries can be executed at any time, so their time parameters often do not align perfectly with the data reporting timestamps. The PromQL evaluation process runs from the startTime to the endTime specified in the query. If no raw data point exists at a specific evaluation time T, PromQL looks back to find the most recent data point and uses it as the value for time T. At time T2, no valid data point was selected.
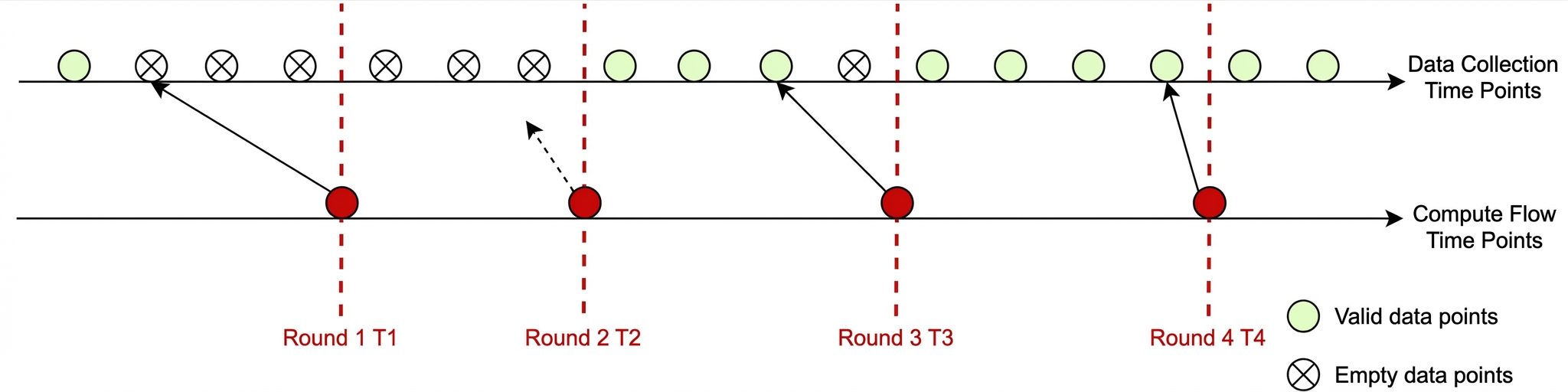
The following figure shows an end-to-end example of the point selection process for a single time series. This example uses the parameters start "10:00:00", end "10:11:30", and step "120s" and assumes that the original monitoring data is reported every 30s. The entire process involves six rounds of point selection. The six timestamps that are ultimately selected are "09:59:40", "10:01:40", "10:03:40", "10:05:40", "10:07:40", and "10:09:40". The PromQL-Engine then treats the data points at these six timestamps as the data points for "10:00:00", "10:02:00", "10:04:00", "10:06:00", "10:08:00", and "10:10:00" and uses them in the subsequent calculation process.
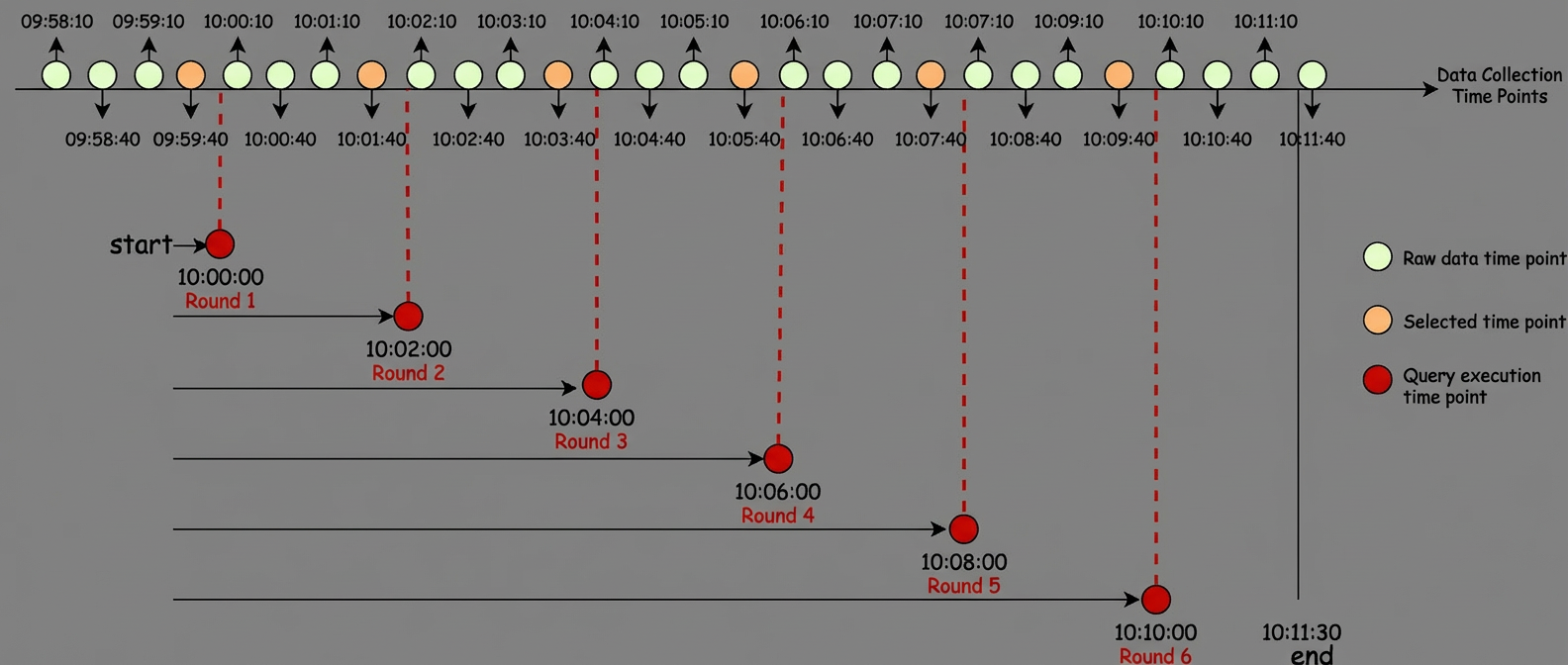
In the example above, the maximum lookback period for selecting a data point is controlled by the lookback-delta parameter, which defaults to 5 minutes in Prometheus and 3 minutes in MetricStore. For example, for the timestamp '10:00:00', the system looks back a maximum of 3 minutes. If no data point is found within the '09:57:00' to '10:00:00' time range, it means that no data for the '10:00:00' timestamp proceeds to the next stage of calculation. This selection method corresponds to the InstantVectorSelector in Prometheus, which is defined as VectorSelector in the Prometheus source code.
Window function point selection
As the name suggests, "window function point selection" means that this type of "point selection" logic exists only within the calculation process of window functions. For example, consider the same parameters as before, start "10:00:00", end "10:11:30", and step "120s", and assume that the window parameter for the window function is [5m], which represents 5 minutes.
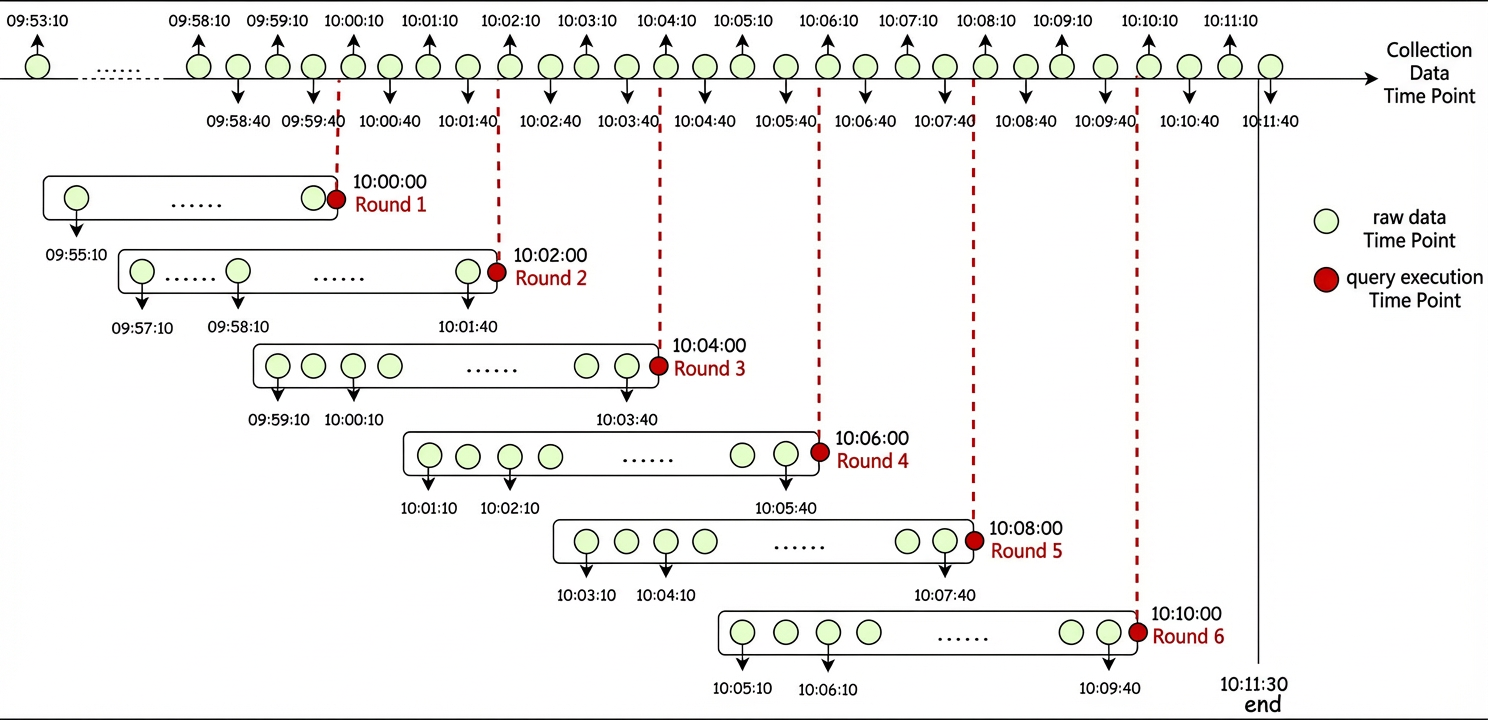
As shown in the figure, each round of data point selection retrieves all data points within the preceding 5-minute window. For example, in the first round of selection at "10:00:00", the 10 data points within the "09:55:00" to "10:00:00" window ("09:55:10", "09:55:40", "09:56:10", "09:56:40", "09:57:10", "09:57:40", "09:58:10", "09:58:40", "09:59:10", and "09:59:40") are all included in the subsequent computation. This selection mode corresponds to Prometheus's RangeVectorSelector, defined as MatrixSelector in the Prometheus source code.
Execution engine
Before we dive into specific PromQL computations, let's reiterate the fundamental principle: every type of PromQL evaluation—including all aggregation operators, functions, and binary expressions—runs in multiple rounds at the given step interval. This section uses illustrations to explain several common types of computations in PromQL.
Filter queries
This type of basic query statement does not involve any operators or functions. It supports adding filter conditions to any label by using only the =, !=, =~, or !~ matching operators. These filter conditions are typically pushed down to the storage layer, which means that the data is filtered before it enters the computation process.
The subsequent operations on the metric data are straightforward: they simply select data points based on the lookback-delta mechanism. Here are a few example queries for reference.
http_requests_total{replica="rep-a"}
http_requests_total{replica!~".*a"}
http_requests_total{environment=~"staging|testing|development",method!="GET"}If you do not want to specify a particular metric and want to include the metric name in the fuzzy matching conditions, you can use the following examples.
-
Note: Fuzzy matching on metric names is inefficient and generally not recommended for production use.
{__name__="http_requests_total", replica="rep-a"}
{__name__=~"http.*", replica="rep-a"}
{__name__=~".+", instance=~"127.*"}Aggregation operators
-
Note: The evaluation flow for all aggregation operations can be summarized as "first, select data points using the lookback-delta mechanism, and then aggregate them across time series."
PromQL currently supports the following aggregation operators: sum, avg, min, max, bottomk, topk, group, count, count_values, stddev, stdvar, quantile, limitk, and limit_ratio. This section uses the max and count operators and the following three time series as examples to describe the calculation process of aggregation operators.
timeseries 1: __name__="request_total_count", instance="127.0.0.1:10000", job="prometheus"
timeseries 2: __name__="request_total_count", instance="127.0.0.1:10001", job="vm-agent"
timeseries 3: __name__="request_total_count", instance="127.0.0.1:10002", job="vm-agent"
The query parameters are set as follows:
start: 10:00:00
end : 10:11:30
step: 120s
Max operator
This topic uses the query query: max ( request_total_count ) by ( job ) as an example to describe the calculation process of the max operator. As shown in the following figure, each evaluation step is divided into two stages: point selection and aggregation calculation. The point selection stage follows the lookback point selection mechanism. Then, the maximum (max) value is calculated for each group as specified in the by clause. The final result contains two time series, which correspond to the two distinct values of the job label.

Count operator
Change the query statement to query: count ( request_total_count ) by ( job ) . The count operator is used to count the number of data points in each category. For the detailed calculation process, see the figure below.

The three time series in Phase 1 are grouped by job into only two groups, job="prometheus" and job="vm-agent", which correspond to group-1 and group-2 in Phase 2. You can then perform aggregate calculations based on these groups.
Functions
Functions in PromQL can be divided into two categories: window functions and non-window functions. For a detailed list of supported functions, see Prometheus Query functions. Functions that have an input parameter type of (v instant-vector) are non-window functions, and functions that have an input parameter type of (v range-vector) are window functions. Note that the primary difference between functions and aggregation operators is that aggregation operators perform aggregations across time series, whereas functions operate on the values or labels within a single time series.
This section continues to use the following three time series to explain how various functions work.
timeseries 1: __name__="request_total_count", instance="127.0.0.1:10000", job="prometheus"
timeseries 2: __name__="request_total_count", instance="127.0.0.1:10001", job="vm-agent"
timeseries 3: __name__="request_total_count", instance="127.0.0.1:10002", job="vm-agent"
The query parameters are set as follows:
start: 10:00:00
end : 10:11:30
step: 120s
Non-window functions
The calculation process for non-window functions is similar to that of the AGG aggregation operator. In the point selection phase, both follow the lookback mechanism. The overall calculation process can be summarized as "first selecting points based on the lookback-delta mechanism, and then performing the corresponding function operation on each data point". For example, the log2 function illustrates the calculation principle of non-window functions. This function calculates the base-2 logarithm, and its corresponding PromQL query is query: log2 ( request_total_count ).

In addition to functions that perform calculations on numerical values, PromQL also has functions that operate on labels, such as label_join and label_replace. These functions also first select data points based on the "lookback-delta" mechanism, and then perform join or replace operations on the label information of the time series.
label_replace(prometheus_build_info{}, "branch", "$1", "version", "(.)@.")The query above extracts the string before the "@" symbol from the label with the key "version" for each time series. This extracted string is then added as a new label with the key "branch" to the labels of the resulting time series.
Window functions
The difference between window functions and non-window functions is only their point selection logic. In each point selection operation, a window function includes all data points within a time window in the subsequent calculation process. The overall calculation process can be summarized as follows: First, select n data points based on a time window, and then perform the corresponding function operation on all data points within the window. The size of the time window is determined by the function's range parameter. For the parameter format, see duration.
This section uses the max_over_time function as an example to describe the calculation process of a window function. The corresponding PromQL query is query: max_over_time ( request_total_count[5m] ), where 5m represents a time window of 5 minutes.

The figure above uses timeseries 1 as an example to illustrate the calculation process of the max_over_time function. In each evaluation step, the function selects all data points within the last 5 minutes and performs a max operation on them. This process is then repeated for all other time series to complete the full PromQL query.
The special calculation behavior of some PromQL window functions, such as delta, rate, and increase, can produce unexpected results if the functions are used improperly or misunderstood.
-
The delta function
The delta function calculates the difference between the first and last data points in a time window. It requires at least two data points in the window; otherwise, it returns no data. This function has a special design feature: it performs "boundary extrapolation" based on the data points in the window and the window parameter. This can cause a metric with only integer values (for example, request_total_count) to return a floating-point result.
-
The rate and increase functions
These two functions also calculate the difference between the first and last data points in a time window, but they also iterate through the remaining points. If a value decreases (a counter reset), the previous value is added to the final result. This can lead to an abnormally large final value. For details, see the source code. Additionally, the rate function computes the per-second rate of change, whereas the increase function computes the total increase over the window.
Binary expressions
PromQL supports three types of binary expressions: "Scalar <op> Scalar," "Vector <op> Scalar," and "Vector <op> Vector."
-
Scalar <op> Scalar
This type is easy to understand: it performs a binary operation on two scalar values. Here are some examples:
1024 * 1024
9 / 3
3 ^ 2
3 == 1-
Vector <op> Scalar
The evaluation for this type of binary expression is very similar to that of a non-window function. It can be summarized as "first, select a data point using the lookback-delta mechanism, and then perform the corresponding binary operation on that data point." For a visual explanation, refer to the "Non-window functions" section. Here are a few examples:
request_total_count_min / 60
process_resident_memory_bytes / 1024 / 1024
query_latency_seconds * 1000-
Vector <op> Vector
This type of binary expression operates on two metric vectors. The overall process can be summarized as "first, select data points for both the left and right expressions using the lookback-delta mechanism, then applies the calculation to pairs of time series with identical labels. Unmatched time series are dropped from the result."
Metric: request_total_latency_ms
timeseries 1: __name__="request_total_latency_ms", instance="127.0.0.1:10000", job="prometheus"
timeseries 2: __name__="request_total_latency_ms", instance="127.0.0.1:10007", job="vm-agent"
timeseries 3: __name__="request_total_latency_ms", instance="127.0.0.1:10002", job="vm-agent"
Metric: request_total_count
timeseries 4: __name__="request_total_count", instance="127.0.0.1:10000", job="prometheus"
timeseries 5: __name__="request_total_count", instance="127.0.0.1:10001", job="vm-agent"
timeseries 6: __name__="request_total_count", instance="127.0.0.1:10002", job="vm-agent"
The query parameters are set as follows:
start: 10:00:00
end : 10:11:30
step: 120s
This section uses an example with data from two metrics and six time series to explain the calculation process for this type of binary expression. The PromQL query is query: request_total_latency_ms / request_total_count.
This Query can be interpreted as a calculation of the average latency of all requests at a specific time. First, data points are selected from the expressions on the left and right sides based on the 'lookback-delta' mechanism. This operation is identical to the lookback point selection process. Then, calculations are performed on the data from the time series on both sides that have identical labels. The following figure uses timeseries 1 and timeseries 4 as an example to illustrate the complete calculation process.

In the example above, only two pairs of time series have perfectly matching Labels: timeseries 1 and timeseries 4, and timeseries 3 and timeseries 6. Because timeseries 3 and timeseries 5 do not have a matching time series, they are skipped in subsequent calculations. Therefore, the final result set contains only two time series.
Vector matching
Vector matching is a core feature of PromQL syntax. Its structure is similar to a binary expression, but it allows for binary operations between two or more data vectors with different labels. Vector matching extends basic binary expressions by supporting the on and ignore operators to enable binary operations when labels do not match on both sides. The on operator matches only specific labels, whereas the ignore operator ignores specific labels. However, one-to-many, many-to-one, or even many-to-many relationships can exist between the labels on either side of an expression. The group_left and group_right operators are introduced to handle these scenarios.
Based on the matching results of labels from the left and right sides, there are three main scenarios: One-to-One, One-to-Many, and Many-to-One (Many-to-Many is not supported). This section uses the following six time series as an example to explain the calculation process for these three scenarios.
Metric: request_total_latency_ms
timeseries-1: __name__="request_total_latency_ms", instance="127.0.0.1:10000", job="prometheus", code="200" 90
timeseries-2: __name__="request_total_latency_ms", instance="127.0.0.1:10002", job="vm-agent", code="200" 20
timeseries-3: __name__="request_total_latency_ms", instance="127.0.0.1:10007", job="vm-agent", code="200" 60
Metric: request_total_count
timeseries-4: __name__="request_total_count", instance="127.0.0.1:10000", job="prometheus" 10
timeseries-5: __name__="request_total_count", instance="127.0.0.1:10002", job="vm-agent" 20
timeseries-6: __name__="request_total_count", instance="127.0.0.1:10007", job="sls-ilogtail" 30
One-to-One
This type of matching requires that the labels in the result sets of the left and right expressions have a one-to-one correspondence.
request_total_latency_ms / on(instance) request_total_count
--> Evaluation process:
timeseries-1 / timeseries-4 --Result--> instance="127.0.0.1:10000", 90/10
timeseries-2 / timeseries-5 --Result--> instance="127.0.0.1:10002", 20/20
timeseries-3 / timeseries-6 --Result--> instance="127.0.0.1:10007", 60/30The example above is a query that uses the on operator. on(instance) specifies that only the "instance" label is considered when matching labels on both sides. Therefore, the query is also equivalent to request_total_latency_ms / ignore(job,code) request_total_count.
If you do not use the on operator, only the two time series pairs "timeseries 1 <--> timeseries 4" and "timeseries 2 <--> timeseries 5" in the sample data above can be matched for the subsequent binary operation.
-
Many-to-One and One-to-Many
When you use the on and ignore operators, one-to-many or many-to-one matching scenarios can occur between the labels on each side. These scenarios result in an error by default. To handle this, you must use the group_left or group_right operator. group_left allows multiple time series from the left vector to match a single series from the right vector, while group_right allows multiple time series from the right vector to match a single series from the left vector.
request_total_latency_ms / on(job) group_left(instance, code) request_total_count
--> Evaluation process:
timeseries-1 / timeseries-4 --Result--> instance="127.0.0.1:10001",job="prometheus",code="200", 90/10
timeseries-2 / timeseries-5 --Result--> instance="127.0.0.1:10002",job="vm-agent",code="200", 20/20
timeseries-3 / timeseries-5 --Result--> instance="127.0.0.1:10007",job="vm-agent",code="200", 60/20This example query uses the on operator with the group_left operator. When you use on(job), a many-to-one situation occurs, where both "timeseries-2" and "timeseries-3" on the left side can match "timeseries-5" on the right side. In this case, you must use group_left to allow this calculation. In addition, the group_left(instance, code) syntax specifies that the "instance" and "code" labels are preserved in the result set.
Other basic operations
Subquery
PromQL syntax requires that the input for a window function must be a raw metric and not the intermediate result of a calculation. If you want to run a window function on the result of an expression, you must use the subquery feature. The syntax is <instant_query> [ <range> : [<resolution>] ], where <instant_query> represents a sub-expression, <range> represents the window size parameter of the outer window function, and <resolution> represents the step parameter used by the inner sub-expression. If the <resolution> parameter is not provided, the execution engine internally calculates a step for the sub-expression by calling a function based on <range>. This function can be customized. For details on the logic for adjusting these execution parameters, see the source code.
The execution flow of a subquery is similar to that of a normal window function, but it adjusts the effective key parameters of its internal sub-expressions, such as start, end, and step. The following are two query examples where the step is set to 2m:
max_over_time(sum(process_resident_memory_bytes) by (instance)[10m:1m])
Query expression breakdown:
sum(process_resident_memory_bytes) by (instance) --> step is adjusted to "1m"
max_over_time(xxxx[10m:1m]) --> window range is "10m", outer step is still "2m"rate(sum(process_resident_memory_bytes) by (instance)[30m:30s])
Query expression breakdown:
sum(process_resident_memory_bytes) by (instance) --> step is adjusted to "30s"
rate(xxxx[30m:30s]) --> window range is "30m", outer step is still "2m"Offset modifier
The offset modifier is used to shift the time range of a query. The following example uses the PromQL query query: request_total_count offset 5m and the following query parameters to explain how offset is calculated. In this query, offset 5m shifts the query time range back by 5 minutes.
Query parameters:
start: 10:06:00
end : 10:11:30
step: 120s

The first evaluation round is at "10:06:00". The query time is shifted back to "10:01:00", and the lookback-delta mechanism selects the data point at "10:00:40". The subsequent two evaluation rounds select data points at "10:02:40" and "10:04:40", respectively.
In addition, the offset parameter also supports negative values. For example, offset -5m indicates an offset of 5 minutes into the future.
@ modifier
The @ operation modifiers support three types: @start(), @end(), and @<timestamp>. @start() retrieves the input start parameter, @end() retrieves the input end parameter, and @<timestamp> directly retrieves the timestamp from the Query statement.
The logic of this modifier is simple: it fixes the evaluation timestamp for each step to start, end, or <timestamp>. The following example uses the PromQL query query: request_total_count @ start() and the query parameters below to explain how the @ modifier is calculated.
Query parameters:
start: 10:06:00
Query parameters:
start: 10:06:00

Advanced usage examples
The previous sections explained the principles of basic operators, functions, and expressions in PromQL. In real-world business monitoring, nesting various operators is often necessary to express the intended calculation. The PromQL execution process is similar to the SQL Volcano Model. Leaf nodes read the data, and calculations are passed up layer by layer for each stage. This section uses two complex PromQL queries to describe the detailed expression structure and calculation process.
max ( max_over_time( process_memory_bytes [10m] ) / 1024 / 1024 ) by ( instance )
The syntax tree for this query is shown in the figure above. The execution process is broken down into the following four stages:
-
Stage 1
expr_1: process_resident_memory_bytes{}[10m]In this stage, the window function selects all data points within a time window for each round.
-
Stage 2
expr_2: max_over_time(expr_1)This stage calculates the maximum value of all data points within the time window for a single time series in each calculation round.
-
Stage 3
expr_3: expr_2/1024/1024After the first two stages, this stage performs the /1024/1024 mathematical operation on each numerical point in every time series of the result set.
-
Stage 4
expr_4: max(expr_3) by (instance)This stage performs a cross-time series aggregation on the result set from Stage 3. In each round, it calculates the maximum value for each instance group.
(sum(delta(container_network_receive_packets_dropped_total{namespace=~"kube-system"}[1m] offset 1h)) by (namespace,pod)
/
sum(delta(container_network_receive_packets_total{namespace=~"kube-system"}[1m] offset 1h)) by (namespace,pod)) > 0.02
The syntax tree for the query is shown in the figure above. The process is recursive and calls are made layer by layer. For a binary expression, the left subtree is executed before the right subtree. All queries can be divided into execution levels this way. The VectorSelector or MatrixSelector nodes read the data. Then, the expressions at each level are executed from the bottom up.
Common "unexpected" scenarios
The previous section detailed the calculation principles of various operators in the PromQL execution engine. You may now have a sense of the "special" nature of PromQL syntax. This section describes several "unexpected" results caused by the special point selection design of "lookback-delta". Although the calculation results might confuse developers, they are actually "normal results" that fully comply with the PromQL design specification.
Time series data is written, but PromQL queries return no data
This scenario often occurs when the data reporting interval is long. For example, consider an aggregation task that runs hourly. Its result is represented by the metric "request_total_count_1h". When you query this metric using PromQL, if the input step parameter is large, it is highly likely that no data will be returned.
Assume that a data point for the original metric "request_total_count_1h" is written at the top of every hour. The following figure uses the calculation parameters start "10:30:00", end "15:30:00", and step "3600s" to illustrate why no data is returned.

In the figure above, each calculation round looks back three minutes to select the most recent data point. For example, at "10:30:00", no data point is selected in that round. Similarly, no data points are selected in any subsequent rounds. This results in no data in the final output.
Data is no longer written after a certain time, but PromQL can still query data for several minutes afterward
This phenomenon is also common. It usually happens after a collection agent stops collecting or reporting metrics, but the metric data can still be queried for several minutes. Assume a collection agent collects and reports the metric "request_total_count" every 30 seconds and stops after "10:02:00". The following figure uses the calculation parameters start "10:00:00", end "10:06:00", step "60s", and lookback-delta "3m" to illustrate the principle behind this unexpected behavior. Here, lookback-delta "3m" means the maximum lookback window is 3 minutes.

In the figure above, at the timestamps "10:02:00", "10:03:00", and "10:04:00", the query can look back 3 minutes and select the data point from "10:01:40". This causes the unexpected behavior described earlier. For this scenario, customize the "lookback-delta" parameter to reduce the maximum lookback window. This minimizes the effect of this point-filling behavior.
In scenarios with time series churn, PromQL aggregation operators produce results that are several times too high
Time series churn usually occurs in Kubernetes cluster environments. In these environments, components such as pods, nodes, and services are frequently created, updated, and destroyed. This dynamic nature leads to a large number of short-lived time series in the Prometheus monitoring data.
The following is a calculation example for the metric resource_count, which experiences frequent time series churn. If you use the sum(resource_count) statement, the result is twice as large as the result calculated by SQL. This is clearly incorrect. However, the result of the sum(last_over_time(resource_count[59s])) statement is nearly identical to the SQL result.
-
Result of sum(resource_count)
-
Result of sum(last_over_time(resource_count[59s]))
This unexpected result is also caused by the "lookback-delta" mechanism. The following example uses two churning time series to explain the reason for this result. Time series 1 disappears after "10:01:40", and time series 2 is added at "10:02:10".
In the example, the step parameter is set to "1m". If you use the sum(resource_count) statement, during the point selection process at "10:02:00", only the data point from time series 1 at "10:01:40" is selected. However, the point selection process at "10:03:00" not only re-selects the historical data point from time series 1 at "10:01:40", but also selects the data point from time series 2 at "10:02:40". This leads to an unexpected data result. The sum(last_over_time(resource_count[59s])) statement can be used to handle this scenario. In each point selection round, the last_over_time function selects the last numerical point within the most recent 59 seconds, and then the sum is calculated.

Special design considerations
The StableNan identifier
Prometheus Engine defines a special float64 value called StableNan. This value identifies an invalid number. The identifier works as follows: If a data point with this value is selected based on the "lookback-delta" mechanism, the system considers that no valid point was selected in the current cycle. Note that a standard Math.NaN is a normal data point.
MetricStore supports writing StableNan values. The following example shows how to do this using the Go SDK for SLS:
var log = &sls.Log{
Time: proto.Uint32(uint32(time.Now().Unix())),
Contents: [ ]*sls.LogContent{
{Key: proto.String("__name__"), Value: proto.String("test_metric")},
{Key: proto.String("__labels__"), Value: proto.String("A#$#a|B#$#b")},
{Key: proto.String("__time_nano__"), Value: proto.String("1687943952000000000")},
// The fixed string "__STALE_NAN__" represents StableNan.
{Key: proto.String("__value__"), Value: proto.String("__STALE_NAN__")},
},
}
Other data types
-
Exemplar
Exemplar is a feature that enhances the observability of monitoring systems. It lets you attach references or metadata for specific events to time series data points. Examples include distributed tracing IDs or log entry IDs. This mechanism helps you quickly correlate abnormal behavior in metrics with specific events. This greatly simplifies troubleshooting and performance analysis. Client libraries that support this feature typically generate and attach Exemplars in the application. Prometheus then collects them during data scraping.
In distributed systems, you can integrate Exemplars with distributed tracing systems, such as Jaeger or Zipkin. This provides a direct link from metric anomalies to specific traces, making problem diagnosis more efficient and accurate. Grafana supports this feature. It lets you visually inspect and analyze these event correlations on metric graphs. This enhances the functionality and user experience of the entire monitoring system. Overall, Exemplars provide important visualization and analysis capabilities for monitoring and troubleshooting complex systems.
-
NativeHistogram
In Prometheus, the traditional Histogram model relies on user-defined, fixed bucket boundaries. It uses multiple metrics, such as _bucket, _sum, and _count, to record data distribution. This method can lead to inaccurate distribution representations. This is especially true when you are unsure of the actual data distribution and find it difficult to define appropriate buckets. In addition, using multiple metrics increases the complexity of data storage and queries. You must process these separate metrics to get complete distribution information.
In contrast, the NativeHistogram model uses an adaptive bucket partitioning algorithm. It dynamically adjusts buckets to fit the actual data distribution. You no longer need to manually define bucket boundaries. It merges the multiple metrics into a single data structure. This significantly reduces the data volume and query complexity of monitoring metrics. Data is no longer represented as simple floating-point numbers. Instead, it is stored as a more complex byte array. This allows you to directly save a snapshot of the entire distribution at a specific point in time. NativeHistogram provides higher accuracy and efficiency. It simplifies the use and management of monitoring systems. It is especially useful for handling complex and highly variable data distribution scenarios.
Why does MetricStore not yet support these data types?
-
Exemplar
Essentially, Prometheus lacks general-purpose storage capabilities. This is why the special Exemplar data type was designed. Its query interface is similar to the PromQL query interface. It also reads the entire Exemplar data based on the metric name and label conditions. The general-purpose storage capabilities of Log Service (SLS) Logstores are a perfect fit for this scenario and offer higher storage and query efficiency.
-
NativeHistogram
This feature has been experimental since its introduction in Prometheus v2.40.0. You must enable it using --enable-feature=native-histograms. Each release may introduce breaking changes, leading to unstable APIs and storage formats. In addition, the supporting tool ecosystem is insufficient. For example, components such as Exporter and AlertManager do not support it. Derived storage products, such as Mimir and VictoriaMetrics, also do not support this feature. MetricStore will consider gradually adopting this feature after its API becomes stable, its performance is optimized, and its toolchain matures.
Introduction to APIs
Query APIs
Prometheus supports the /query and /query_range HTTP APIs to query and analyze time series data.
The /query_range API performs range queries. It accepts a PromQL statement along with start time, end time, and step parameters. The API returns the data series within the specified time range. All execution processes described earlier fall under the /query_range API. This API is suitable for analyzing historical data and observing trends, such as generating charts to view resource usage over time.
The /query API primarily performs instant queries, returning metric values at a specific point in time. Simply put, the /query execution process is a subset of the /query_range process. /query performs only a single calculation at a specified time. This API is commonly used for real-time alerting.
Metadata APIs
Prometheus also supports metadata query APIs. These APIs retrieve label and metric information related to time series without fetching specific timestamps and numerical data. The /labels API provides a list of all label names in the current storage. The /label/<label_name>/values API provides all possible values for a given label name. The /series API returns time series metadata that matches specific label conditions. These APIs provide a convenient way to explore and understand the structure of Prometheus data by retrieving metrics, labels, and label values for a time period without fetching the raw data points.
Front-end tools such as Grafana mainly use metadata APIs to implement features like PromQL auto-completion and dynamic configuration. If you call the API without a proper match[] parameter to limit the query scope, the storage layer might process millions of time series to build the result. This can increase query time from hundreds of milliseconds to tens of seconds, and raise memory usage to the gigabyte level. In large-scale production environments, an improper match[] parameter can even cause query timeouts or make the service unavailable. Always use the match[]=<metric_selector> parameter to restrict the query to specific time series.
For more information about the HTTP APIs and error codes that MetricStore currently supports, see MetricStore HTTP API details and MetricStore HTTP API return values.