准备工作期
1、相关推荐和猜你喜欢的区别是什么?
猜你喜欢主要应用于终端用户当前浏览意向不明确时,我们将根据终端用户的长期、短期行为表现出的兴趣进行学习与训练,基于已表现兴趣学习下的同时,综合内容推荐的多样性,达到终端用户兴趣探索与多样展现的效果。常见使用位置:首页,购物车页,订单页
相关推荐主要用于当终端用户的兴趣已基本确定时,我们将根据确定的兴趣集中点(某一个商品、某一篇文章)并根据终端用户海量行为计算与分析找到动态关联的推荐内容进行推荐,根据推荐内容之间的属性与特征相关度找到静态关联内容进行推荐。常见使用位置:详情页
相关推荐场景侧重于基于用户指定的item进行推荐,对于物品自身属性的完备性有一定要求,最好有title,content,tag等属性,如果物品自身属性过差,用户也可以选择不传入item,此时会退化为猜你喜欢场景;
猜你喜欢场景侧重于基于用户行为进行推荐,无需指定传入item。
2、要做商品和内容的混合推荐可以吗?
商品和内容是两个行业,两个模板也不一样,其中数据源表都是不一样的,目前只支持单行业推荐。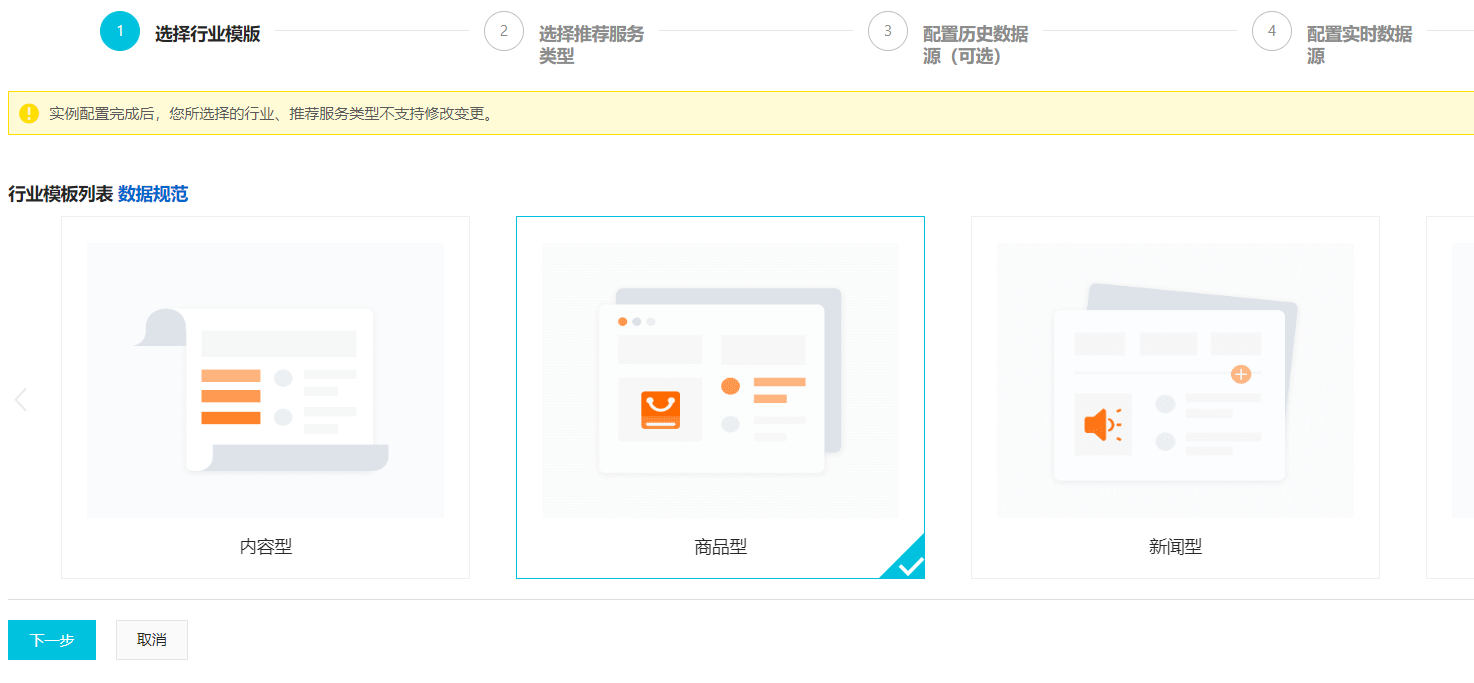
3、是否可提供用户画像?
暂未开放用户画像功能,目前用于内部模型,不可读。
4、推荐类型选错了,可以改吗?
应用激活前可以改,激活成功后,所选择的行业、场景模板不支持修改。如果选错了,需要申请退款重新购买。注意:参加100元试用活动不支持退款如下图:如果在配置实时数据源的时候,点击了下一步接下来无论点击“执行数据导入”或是“跳过”,行业和场景就都不可以修改了。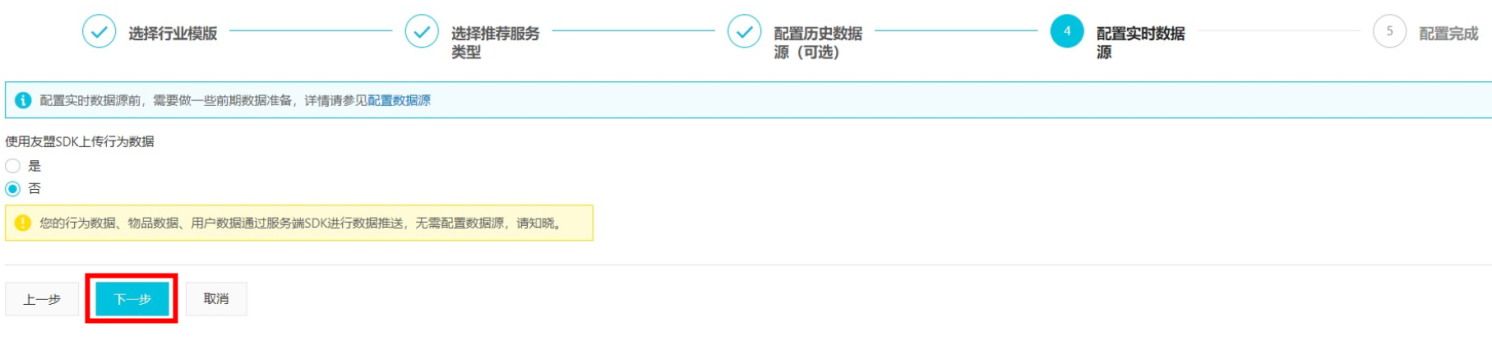
反馈
- 本页导读 (0)
文档反馈