Python官方即将停止维护Python 2,MaxCompute已支持Python 3,对应版本为CPython-3.7.3。本文为您介绍如何通过Python 3语言编写UDAF。
UDAF代码结构
您可以通过MaxCompute Studio工具使用Python 3语言编写UDAF代码,代码中需要包含如下信息:
- 导入模块:必选。
至少要包含
from odps.udf import annotate和from odps.udf import BaseUDAF。from odps.udf import annotate用于导入函数签名模块,MaxCompute才可以识别后续代码中定义的函数签名。from odps.udf import BaseUDAF为Python UDAF的基类,您需要通过此类在派生类中实现iterate、merge、terminate等方法。当UDAF代码中需要引用文件资源或表资源时,需要包含
from odps.distcache import get_cache_file(文件资源)或from odps.distcache import get_cache_table(表资源)。 函数签名:必选。
格式为
@annotate(<signature>),signature用于定义函数的输入参数和返回值的数据类型。更多函数签名信息,请参见函数签名及数据类型。自定义Python类(派生类):必选。
UDAF代码的组织单位,定义了实现业务需求的变量及方法。您还可以在代码中引用MaxCompute内置的第三方库或引用文件、表资源。更多信息,请参见第三方库或引用资源。
- 实现Python类的方法:必选。
Python类实现包含如下4个方法,您可以根据实际需要进行选择。
方法定义 描述 BaseUDAF.new_buffer()返回聚合函数的中间值的buffer。 buffer必须是Marshal对象(例如LIST、DICT),并且buffer的大小不应该随数据量递增。在极限情况下,buffer在执行对象序列化后的大小不应该超过2 MB。BaseUDAF.iterate(buffer[, args, ...])将 args聚合到中间值buffer中。BaseUDAF.merge(buffer, pbuffer)将中间值 buffer和pbuffer合并的结果存放在buffer中。BaseUDAF.terminate(buffer)将 buffer转换为MaxCompute SQL的基本类型。
UDAF代码示例如下。
#导入函数签名模块及基类。
from odps.udf import annotate
from odps.udf import BaseUDAF
#函数签名。
@annotate('double->double')
#自定义Python类。
class Average(BaseUDAF):
#实现Python类的方法。
def new_buffer(self):
return [0, 0]
def iterate(self, buffer, number):
if number is not None:
buffer[0] += number
buffer[1] += 1
def merge(self, buffer, pbuffer):
buffer[0] += pbuffer[0]
buffer[1] += pbuffer[1]
def terminate(self, buffer):
if buffer[1] == 0:
return 0.0
return buffer[0] / buffer[1]avg的MaxCompute UDAF的实现逻辑及计算流程如下。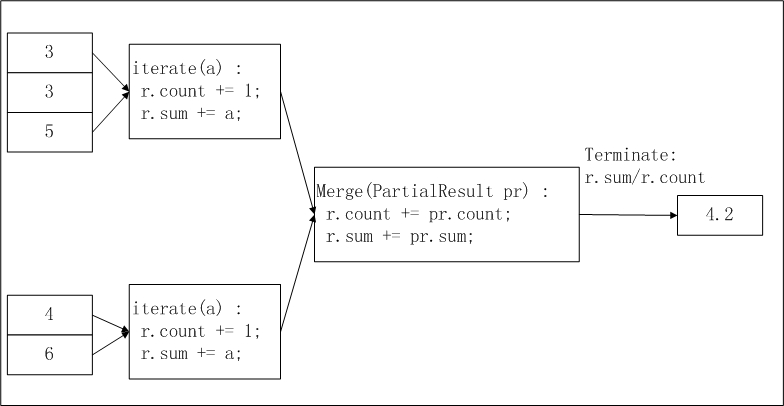
pbuffer相当于上图中的pr,buffer相当于上图中的r。Python 2 UDAF与Python 3 UDAF区别在于底层Python语言版本不一致,请您根据对应版本语言支持的能力编写UDAF。
注意事项
Python 3与Python 2不兼容。在您使用Python 3之前,需要考虑兼容性问题,在一个SQL中不允许同时使用Python 3和Python 2。
Python 2 UDAF迁移
Python 2官方即将停止维护,建议您根据项目类型执行迁移操作:
全新项目:新MaxCompute项目,或第一次使用Python语言编写UDAF的MaxCompute项目。建议所有的Python UDAF都直接使用Python 3语言编写。
存量项目:创建了大量Python 2 UDAF的MaxCompute项目。请您谨慎开启Python 3。如果您计划逐步将所有Python 2 UDAF迁移为Python 3 UDAF,推荐方法如下:
新作业和新UDAF:使用Python 3语言编写,在Session级别开启Python 3。开启Python 3方法,请参见开启Python 3。
Python 2 UDAF:改写Python 2 UDAF,使其可以同时兼容Python 2和Python 3。改写方法请参见将Python 2代码移植到Python 3。
说明如果您需要编写公共UDAF,并为多个MaxCompute项目授权UDAF的操作权限,建议UDAF同时兼容Python 2和Python 3。
开启Python 3
MaxCompute默认使用Python 2,如果您要使用Python 3,可以在Session级别设置如下属性开启Python 3,并与SQL语句一起提交执行。
set odps.sql.python.version=cp37;第三方库
MaxCompute内置的Python 3运行环境中未安装第三方库Numpy。如果您需要使用Numpy的UDAF,请手动上传Numpy的WHEEL包。从PyPI或镜像下载Numpy包时,包的文件名为numpy-<版本号>-cp37-cp37m-manylinux1_x86_64.whl。上传包的操作请参见资源操作或UDF示例:Python UDF使用第三方包。
函数签名及数据类型
@annotate(<signature>)signature为字符串,用于标识输入参数和返回值的数据类型。执行UDAF时,UDAF函数的输入参数和返回值类型要与函数签名指定的类型一致。查询语义解析阶段会检查不符合函数签名定义的用法,检查到类型不匹配时会报错。具体格式如下。'arg_type_list -> type'arg_type_list:表示输入参数的数据类型。输入参数可以为多个,用英文逗号(,)分隔。支持的数据类型为BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、CHAR、VARCHAR、复杂数据类型(ARRAY、MAP、STRUCT)或复杂数据类型嵌套。arg_type_list还支持星号(*)或为空(''):当
arg_type_list为星号(*)时,表示输入参数为任意个数。当
arg_type_list为空('')时,表示无输入参数。
type:表示返回值的数据类型。UDAF只返回一列。支持的数据类型为:BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、复杂数据类型(ARRAY、MAP、STRUCT)或复杂数据类型嵌套。
合法函数签名示例如下。
| 函数签名示例 | 说明 |
@annotate('bigint,double->string') | 输入参数类型为BIGINT、DOUBLE,返回值类型为STRING。 |
@annotate('*->string') | 输入任意个参数,返回值类型为STRING。 |
@annotate('->double') | 无输入参数,返回值类型为DOUBLE。 |
@annotate('array<bigint>->struct<x:string, y:int>') | 输入参数类型为ARRAY<BIGINT>,返回值类型为STRUCT<x:STRING, y:INT>。 |
为确保编写Python UDAF过程中使用的数据类型与MaxCompute支持的数据类型保持一致,您需要关注二者间的数据类型映射关系。具体映射关系如下。
MaxCompute SQL Type | Python 3 Type |
BIGINT | INT |
STRING | UNICODE |
DOUBLE | FLOAT |
BOOLEAN | BOOL |
DATETIME | DATETIME.DATETIME |
FLOAT | FLOAT |
CHAR | UNICODE |
VARCHAR | UNICODE |
BINARY | BYTES |
DATE | DATETIME.DATE |
DECIMAL | DECIMAL.DECIMAL |
ARRAY | LIST |
MAP | DICT |
STRUCT | COLLECTIONS.NAMEDTUPLE |
引用资源
Python UDAF可以通过odps.distcache模块引用资源,支持引用文件资源和表资源。
odps.distcache.get_cache_file(resource_name):返回指定文件资源的内容。resource_name为STRING类型,对应当前MaxCompute项目中已存在的文件资源名。如果文件资源名非法或者没有相应的文件资源,会返回异常。说明 使用UDAF访问资源,在创建UDAF时需要声明引用的资源,否则会报错。- 返回值为File-like对象。在使用完此对象后,您需要调用
close方法释放打开的资源文件。
odps.distcache.get_cache_table(resource_name):返回指定表资源的内容。resource_name支持STRING类型,对应当前MaxCompute项目中已存在的表资源名。如果表资源名非法或者没有相应的表资源,会返回异常。- 返回值为GENERATOR类型,调用者以遍历方式获取表的内容,每次遍历可得到以数组形式存在的表中的一条记录。
具体使用方法请参见引用资源(Python UDF 3)和引用资源(Python UDTF 3)。
使用说明
按照开发流程,完成Python 3 UDAF开发后,您即可通过MaxCompute SQL调用Python 3 UDAF。调用方法如下:
在归属MaxCompute项目中使用自定义函数:使用方法与内建函数类似,您可以参照内建函数的使用方法使用自定义函数。
跨项目使用自定义函数:即在项目A中使用项目B的自定义函数,跨项目分享语句示例:
select B:udf_in_other_project(arg0, arg1) as res from table_t;。更多跨项目分享信息,请参见基于Package跨项目访问资源。
使用MaxCompute Studio完整开发及调用Python 3 UDAF的操作,请参见开发Python UDF。
UDAF的动态参数说明
函数签名
Python UDAF函数签名格式请参见函数签名及数据类型。
您可以在参数列表中使用
*,表示接受任意长度、任意类型的输入参数。例如@annotate('double,*->string')表示接受第一个参数是DOUBLE类型,后接任意长度、任意类型的参数列表。此时,您需要自己编写代码判断输入的个数和参数类型,然后对它们进行相应的操作(您可以对比C语言里面的printf函数来理解此操作)。说明*用在返回值列表中时,表示的是不同的含义。UDAF的返回值可以使用
*,表示返回任意个STRING类型。返回值的个数与调用函数时设置的别名个数有关。例如@annotate("bigint,string->double,*"),调用方式是UDTF(x, y) as (a, b, c),此处as后面设置了三个别名,即a、b、c。编辑器会认定a为DOUBLE类型(Annotation中返回值第一列的类型是给定的),b和c为STRING类型。因为这里给出了三个返回值,所以UDTF在调用forward时,forward必须是长度为3的数组,否则会出现运行时报错。说明这种错误无法在编译时报出,因此UDTF的调用者在SQL中设置alias个数时,必须遵循该UDAF定义的规则。由于聚合函数的返回值个数固定是1,所以这个功能对UDAF来说并无意义。
UDAF示例
from odps.udf import annotate
from odps.udf import BaseUDAF
@annotate('bigint,*->string')
class MultiColSum(BaseUDAF):
def new_buffer(self):
return [0]
def iterate(self, buffer, *args):
for arg in args:
buffer[0] += int(arg)
def merge(self, buffer, pbuffer):
buffer[0] += pbuffer[0]
def terminate(self, buffer):
return str(buffer[0])UDAF的返回值只能固定为1个,以上UDAF示例中,返回值是多个输入参数求和,然后多行聚合求和的结果,使用示例如下。
-- 根据输入多个参数求和
SELECT my_multi_col_sum(a,b,c,d,e) from values (1,"2","3","4","5"), (6,"7","8","9","10") t(a,b,c,d,e);
-- 返回值为 55- 本页导读 (1)