通过阿里云公共云OSS以及开源分布式文件系统或共享文件系统,解决线下IDC环境ClickHouse集群在存储空间上的弹性扩容和性能瓶颈问题。
概述
方案介绍
当下依旧有很多客户将业务部署在线下IDC机房,尤其是数据相关的集群因合规或安全考虑,客户往往选择将业务部署在云上,但将大数据或类似的数据分析集群(例如ClickHouse)部署在线下。
鉴于IDC环境中硬件设备的上架、下架、维护、利旧、成本等原因,经常导致数据分析集群的性能存在瓶颈,且数据分析所依赖的存储扩容问题往往成为运维的痛点和难点。
该方案在尽量不改变原有架构的前提下,解决数据分析集群中存储的弹性扩容和读写性能问题。
目标读者
适用于维护IDC环境部署ClickHouse运维工程师,以及相关解决方案架构师。
适用场景
ClickHouse集群部署在线下IDC环境,存在性能和存储问题,机房可与阿里云VPC专线打通。
方案架构
OLAP的优势与问题
OLTP与OLAP的基本区别:
OLTP:是传统的关系型数据库,主要操作增删改查,强调事务一致性,比如银行系统、电商系统。
OLAP:是仓库型数据库,主要是读取数据,做复杂数据分析,侧重技术决策支持,提供直观简单的结果。
OLAP的关键特征:
大多数是读请求。
数据总是以相当大的批(> 1000 rows)进行写入。
不修改已添加的数据。
每次查询都从数据库中读取大量的行,但是同时又仅需要少量的列。
对于简单查询,允许延迟大约50毫秒。
处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)。
每一个查询除了一个大表外都很小、查询结果明显小于源数据。
基于以上特征,在大规模ClickHouse集群中,数据的存储量很容易达到PB级以上,亦意味着如何优化数据成本且尽量不影响CK性能成为CK工程师的一大难题。
ClickHouse on IDC部署架构
ClickHouse可以在任何具有x86_64,AArch64或PowerPC64LE CPU架构的Linux,FreeBSD或Mac OS X上运行。
生产环境中为了提供弹性,建议每个分片应包含分布在多个可用区或数据中心(或至少机架)之间的2-3个副本。 此外,ClickHouse支持无限数量的副本。
ClickHouse分布式架构图
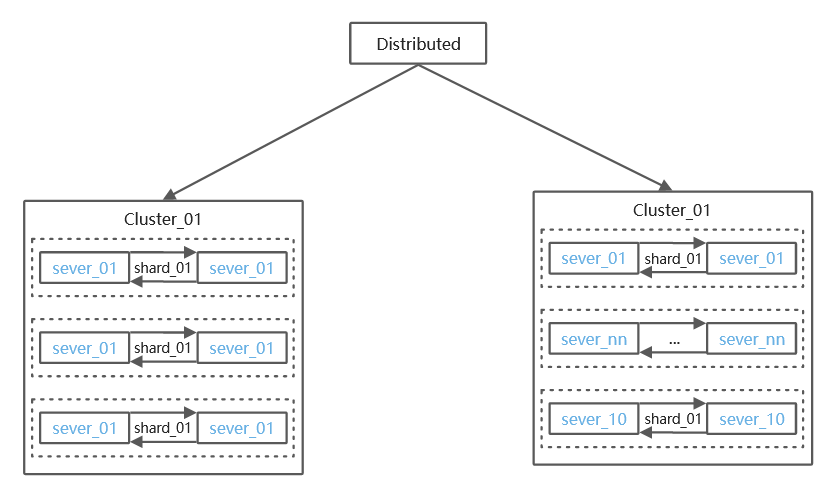
架构说明:
CK的分片与副本功能完全靠配置文件实现,无法自动管理,所以当集群规模较大时,集群运维成本较高。例如, 采用多Shards、2 Replicas的方式,允许一个shard一台服务器down机数据不丢失。 另外, 为了接入不同规模的日志,我们将集群分成6台、20台两种规模的多个集群,也可按照实际情况规划集群规模。
数据副本依赖ZooKeeper实现同步,当数据量较大时,ZooKeeper可能会称为瓶颈。
ClickHouse跨IDC分布式架构图
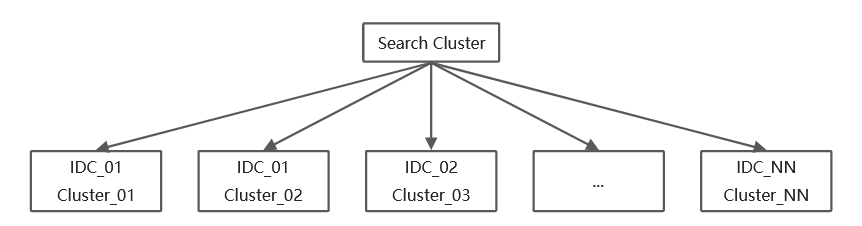
实际生产环境且在IDC部署CK集群需要考虑:
不同业务部署在不同IDC或机柜,需要考虑CK的就近部署问题。
不通IDC网络质量不通,需要考虑互联互通、latency等问题。
IDC的物理扩容空间有限,甚至存在被迫搬迁。
硬件设备因购入年限不同,存在集群稳定性问题,以及成本上的利旧或新购问题。
运维大规模CK跨IDC集群痛点
CK作为高性能列式分布式数据库管理系统,在数据分析(OLAP)领域,既可作为常规日志存储分析,也可进一步作为UBT分析,CK集群规模势必越来越大,遇到的问题也越来越多:
当每天新增上千张表,累计十多亿数据更新,CK集群需要保证的高可用和稳定要求。若部署在IDC环境,则需要硬件层和虚拟化提供高可用保障。
CK本省具备高压缩,但是随着数据量的不断写入,以及因监管需要而要求数据存储时间更长,都导致存储层必须扩容。但是,因硬件服务器硬盘容量有限,若直接增加Cluster则成本较高,故往往陷入保证性能和优化成本的两难中。
当IDC中的CK集群规模达到成百上千台时,硬件层和虚拟化的维护会占用运维团队较多的精力,无法抽身专研技术,阻碍个人或团队技术能力的提升。
解决方案
ClickHouse on OSS混合云架构
阿里云OSS
一份存储、多种引擎:各种类型的数据用集中方式统一存储在OSS,解决数据孤岛,避免多份数据分散在多种不同的系统,无缝对接多种计算引擎,对Hadoop生态体系有良好支持。
数据无需处理、直接存储:支持结构化、半结构化、非结构化多种类型数据,数据可以按照原始产生的形态直接存储,在需要分析阶段,再通过数据引擎进行处理,对接多种数据输入源,提供便捷的数据接入和数据消费通道。
支持高吞吐,具备国内最大数据湖实施经验,可提供Tbps以上的带宽能力。
支持生命周期,可通过lifecycle批量管理存储类型来优化存储成本,也可支持通过API修改metadata来批量自定义存储类型。
支持OSS访问日志的离线和实时管理,既可将OSS Access LOG转存是Bucket,也原生对接SLS日志服务,具备CK计算层读写OSS实时分析的能力。
ClickHouse on OSS混合云架构图
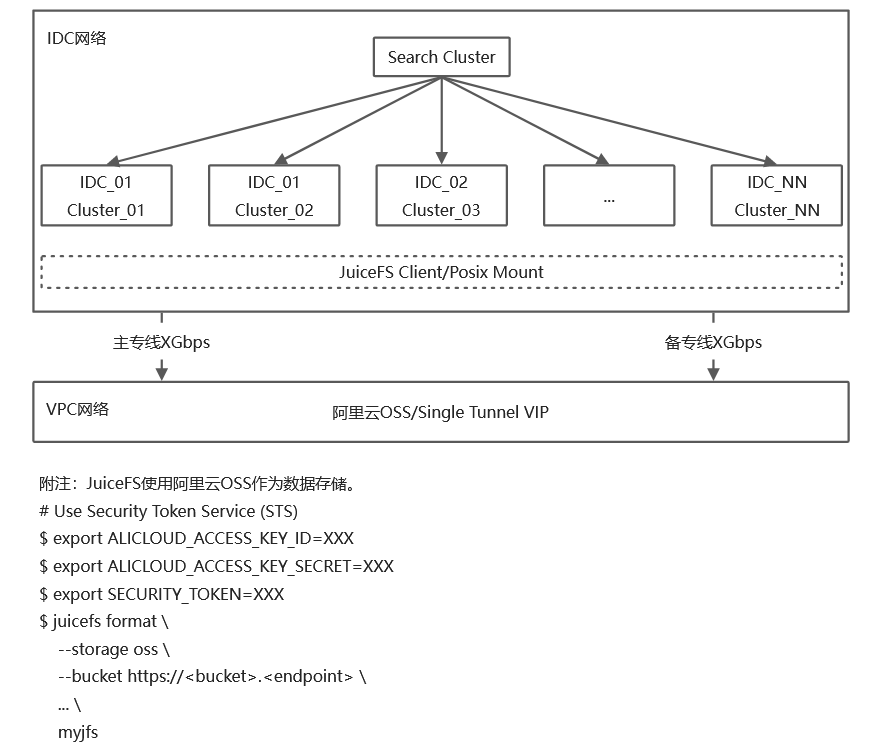
方案优势
不改变现有IDC集群架构,通过专线和OSS实现ClickHouse存储空间的弹性扩容,无需担心扩容空间,且能满足成本的高性价比。
通过OSS生命周期管理实现冷热分层,可以最大限度的保留数据,满足合规或业务等对存储时间的要求,且满足存储成本的高性价比。
OSS的版本控制和Policy等能力,原生支持数据的安全合规和灾备恢复的要求。
因数据已经在阿里云OSS,当客户考虑CK上云或其他AP DB上云时,无需再次迁移数据,仅需在云上重启DB既可。
方案实施
前提条件
已开通阿里云账号。
已创建OSS Bucket和VPC。
云上VPC已与线下IDC专线打通。
操作步骤
登录阿里云OSS控制台,创建OSS Bucket。
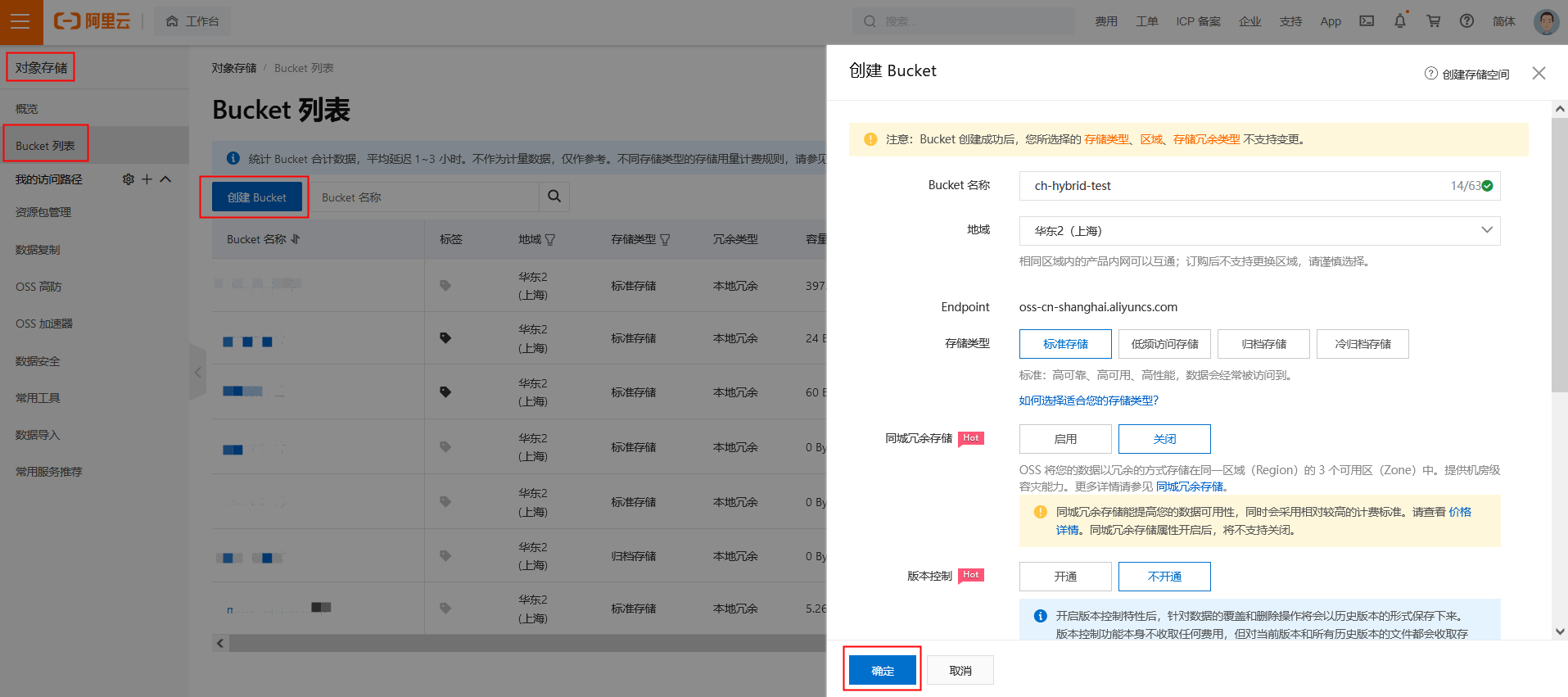
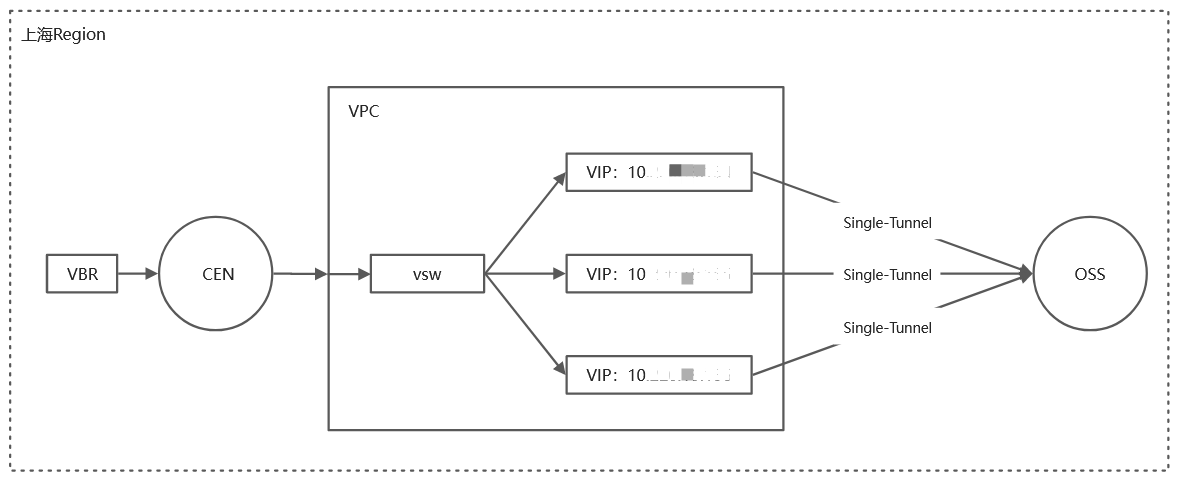
通过Singe Tunnel方式在VPC内创建OSS VIP。(该OSS_VPC_ VIP不同于Endpoint VIP,是VPC内10网段)
 备注:
备注:
(1)OSS Endpoint默认解析是100网段,且是随机VIP不固定,不适用于专线带宽稳定绑定的要求。
(2)通过Single Tunnel方式在VPC内部创建OSS_VPC_ VIP,不仅满足专线对VIP的要求,而且能将专线内网打通OSS。
通过阿里云访问控制创建RAM子账号。配置对应OSS Bucket(例如ch-hybird-test)的RAM Policy,作为后续访问OSS API而准备的Access Key ID 和 Access Key Secret。
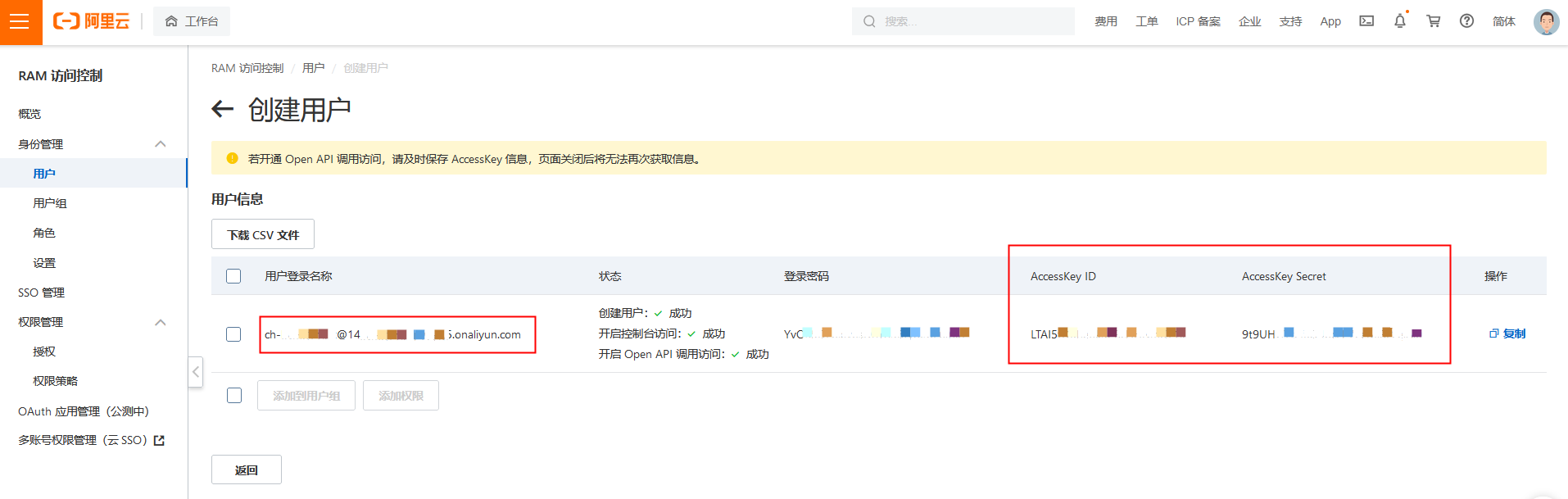 备注:具体OSS RAM Policy的权限配置可参照官方说明。
备注:具体OSS RAM Policy的权限配置可参照官方说明。在VM或物理机部署JuiceFS客户端。以阿里云上ECS部署JFS客户端为例。
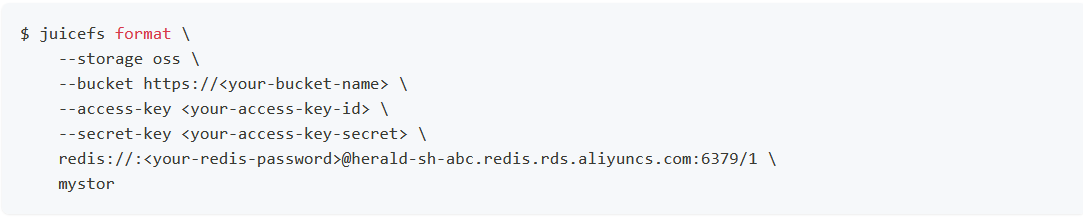 备注:具体如何创建和挂载OSS可参照JFS官方说明。
备注:具体如何创建和挂载OSS可参照JFS官方说明。安装ClickHouse后,可通过CK表引擎(推荐MergeTree)默认存储策略storage_policy配置JFS&OSS块存储。
(1)ClickHouse表引擎中,推荐MergeTree表引擎。
(2)MergeTree 系列表引擎可以将数据存储在多个块设备上。
方案验证
VM直接读写OSS测试。可通过OSSutil CP命令和调高jobs参数既可。
VM通过Posix读写OSS的基准测试。可通过开源FIO工具实现。(使用JFS挂载OSS的路径)
通过VM上部署的ClickHouse进行测试表级别的测试,作上下游联调验证测试。
常见问题
OSS Bucket带宽超默认10Gbps如何解决?可通过白名单方式,对大数据场景的Bucket提高带宽,阿里云OSS Bucket带宽能力可达Tbps以上。