日常生活中,存在一些邻居偷水电燃气的情况,但是单从一两个指标监控,无法判定该邻居是否存在这种行为,因此需要通过对多种指标进行相关性模型训练,并用于预测和挖掘大概率存在该行为的客户。本文通过大数据+机器学习一体化解决方案,介绍通用的DataWorks配合机器学习的具体用户场景解决方案的实施。
概述
日常生活中,通过大量多维度数据去训练和预测的案例比较多。本文提供一种通用的解决方案,通过数据工厂,数仓,机器学习三大产品的配合,形成一套完整,自闭环的大数据+机器学习场景实施方案。
适用场景
需要以大量数据为基础进行训练和预测的业务。
通过机器学习来提升工程效率,节约人力成本的业务。
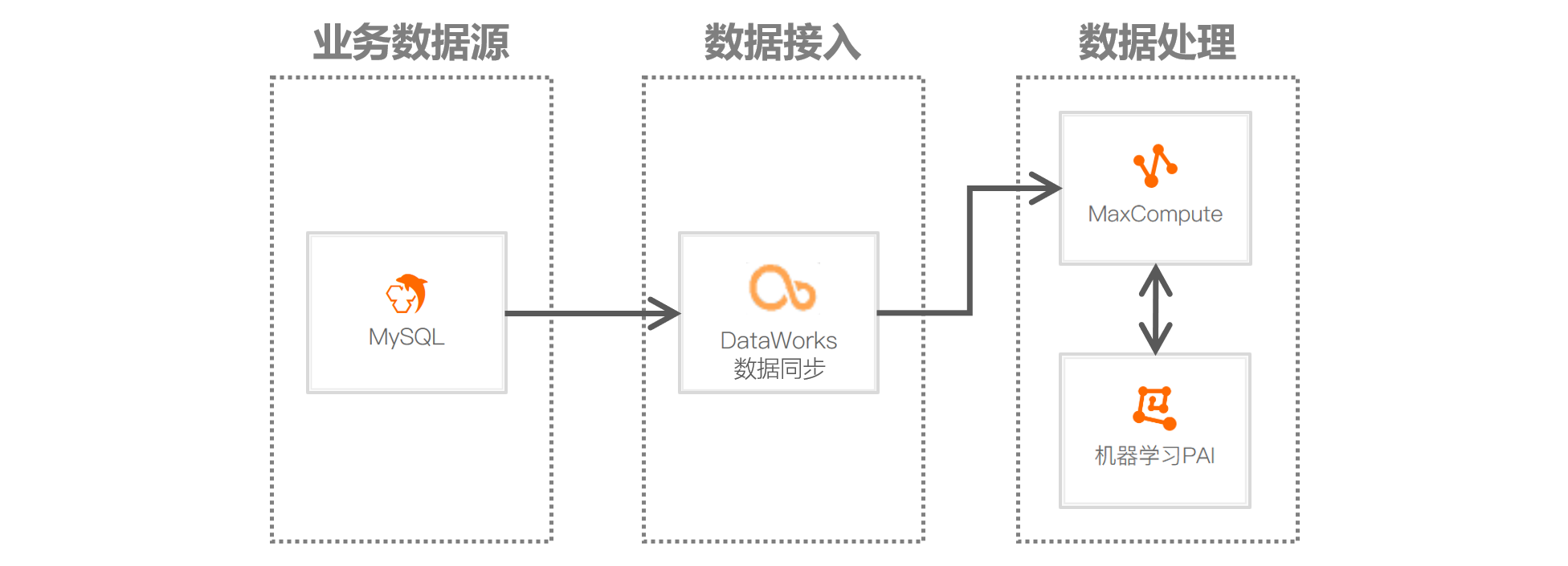
技术架构
本实施方案基于如下图所示的技术架构和主要流程编写操作步骤:
方案优势
支持离线EB量级数据计算,2w以上并发作业,支持灵活调度多任务并发。
支持一站式数据工场,提供丰富的数据清洗/聚类/ETL相关功能,做到灵活调度。
支持可视化建模,提供优质丰富的机器学习算法,做到训练/预测/模型评估一体化。
方案实施
新建表
主要创建训练数据表,清洗数据表,汇聚数据表。用于存储相关训练数据和处理后用于机器学习训练和预测的数据,相关创建表的ddl语句如下:
用户水表下降趋势数据:
CREATE TABLE clean_trend_data (
uid bigint,
trend bigint
)
PARTITIONED BY (dt string)
LIFECYCLE 7;用户水表指标数据:
CREATE TABLE clean_indicators_data (
uid bigint,
xiansun bigint,
warnindicator bigint
)
COMMENT '*'
PARTITIONED BY (ds string)
LIFECYCLE 36000;用户水表偷窃指标数据:
CREATE TABLE clean_steal_flag_data (
uid bigint,
flag bigint
)
COMMENT '*'
PARTITIONED BY (ds string)
LIFECYCLE 36000;汇聚后用于训练的数据:
CREATE TABLE data4ml (
uid bigint,
trend bigint,
xiansun bigint,
warnindicator bigint,
flag bigint
)
COMMENT '*'
PARTITIONED BY (ds string)
LIFECYCLE 36000;配置数据清洗节点
需要对原始采集的客户数据进行清洗,代码如下:
INSERT OVERWRITE TABLE clean_trend_data PARTITION(dt=${bdp.system.bizdate})
SELECT uid
,trend
FROM trend_data
WHERE trend IS NOT NULL
AND uid != 0
AND dt = ${bdp.system.bizdate}
;
INSERT OVERWRITE TABLE clean_steal_flag_data PARTITION(ds=${bdp.system.bizdate})
SELECT uid
,flag
FROM steal_flag_data
WHERE uid != 0
AND ds = ${bdp.system.bizdate}
;
INSERT OVERWRITE TABLE clean_indicators_data PARTITION(ds=${bdp.system.bizdate})
SELECT uid
,xiansun,warnindicator
FROM indicators_data
WHERE uid != 0
AND ds = ${bdp.system.bizdate}
;配置数据汇聚节点
清洗后需要进行数据汇聚,用于机器学习训练数据,代码如下:
INSERT OVERWRITE TABLE data4ml PARTITION (ds=${bdp.system.bizdate})
SELECT a.uid
,trend
,xiansun
,warnindicator
,flag
FROM
(
SELECT uid,trend FROM clean_trend_data where dt=${bdp.system.bizdate}
)a
FULL OUTER JOIN
(
SELECT uid,xiansun,warnindicator FROM clean_indicators_data where ds=${bdp.system.bizdate}
)b
ON a.uid = b.uid
FULL OUTER JOIN
(
SELECT uid,flag FROM clean_steal_flag_data where ds=${bdp.system.bizdate}
)c
ON b.uid = c.uid
;配置数据任务流
然后配置数据工程任务流,通过base将数据处理流程串联起来如下图: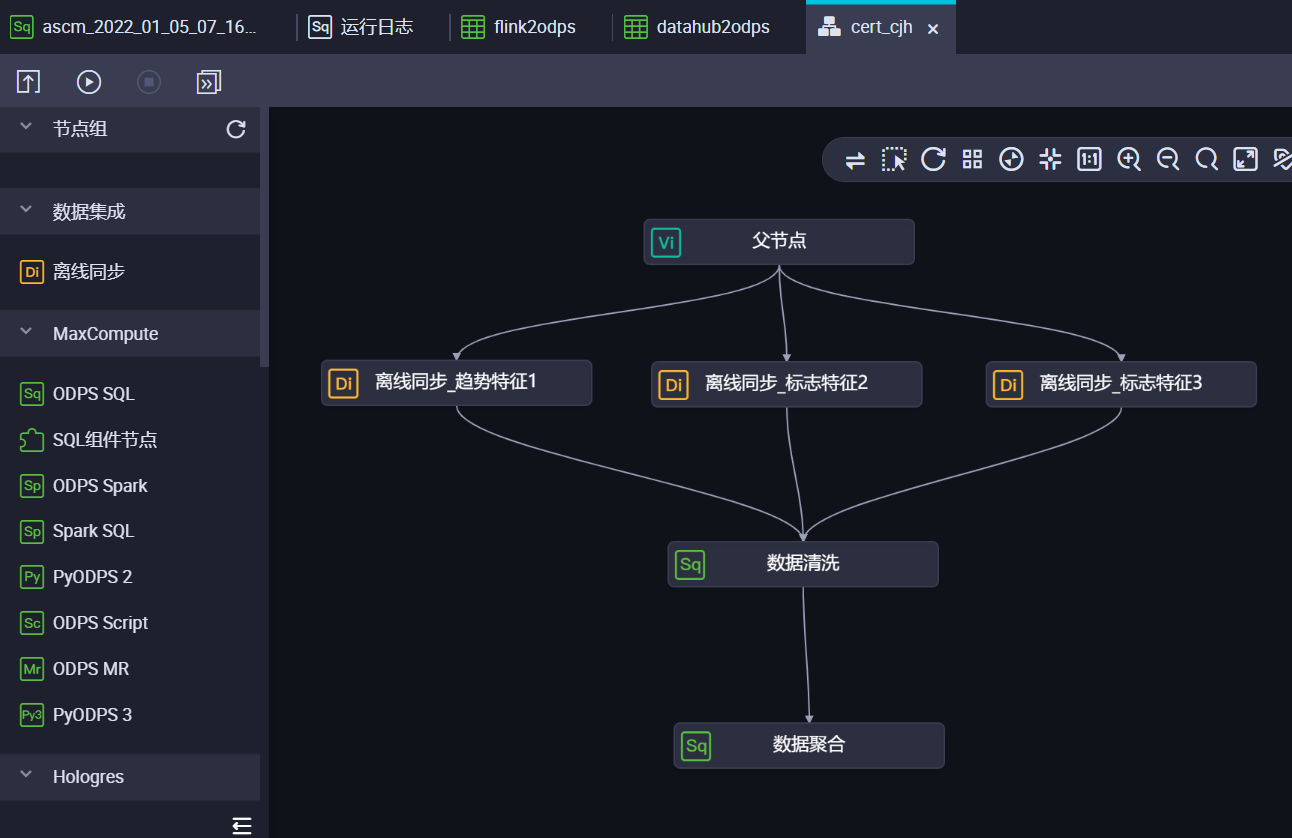 产出的数据,将用于机器学习建模
产出的数据,将用于机器学习建模
机器学习建模
接下来完成机器学习建模,首先新建实验: 接下来载入数据集
接下来载入数据集 载入后即可查看数据集
载入后即可查看数据集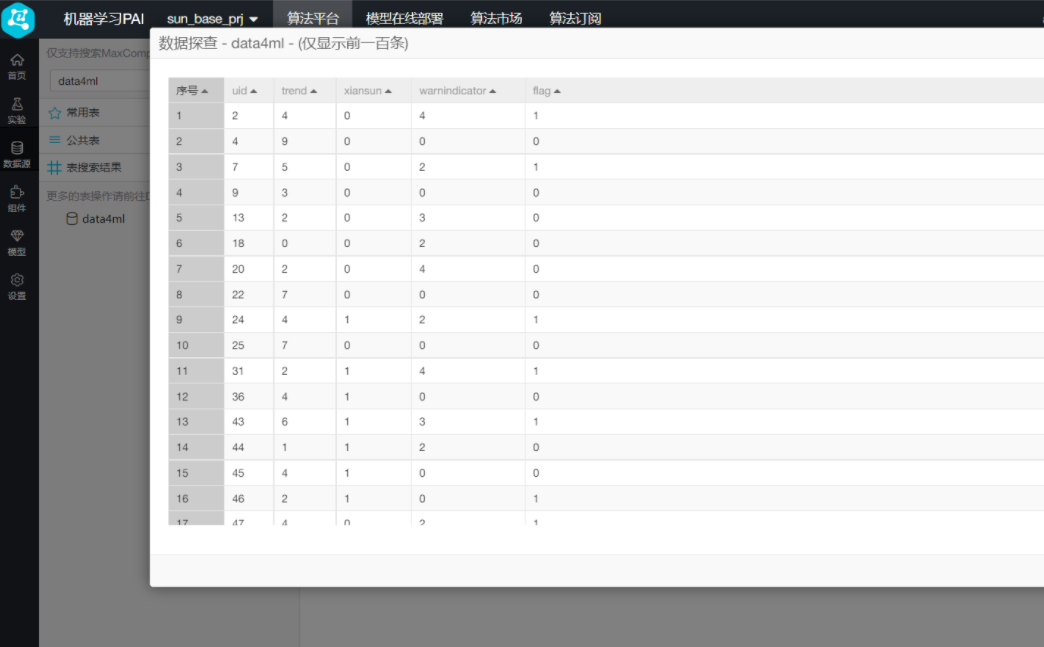
接下来进行相关性分析: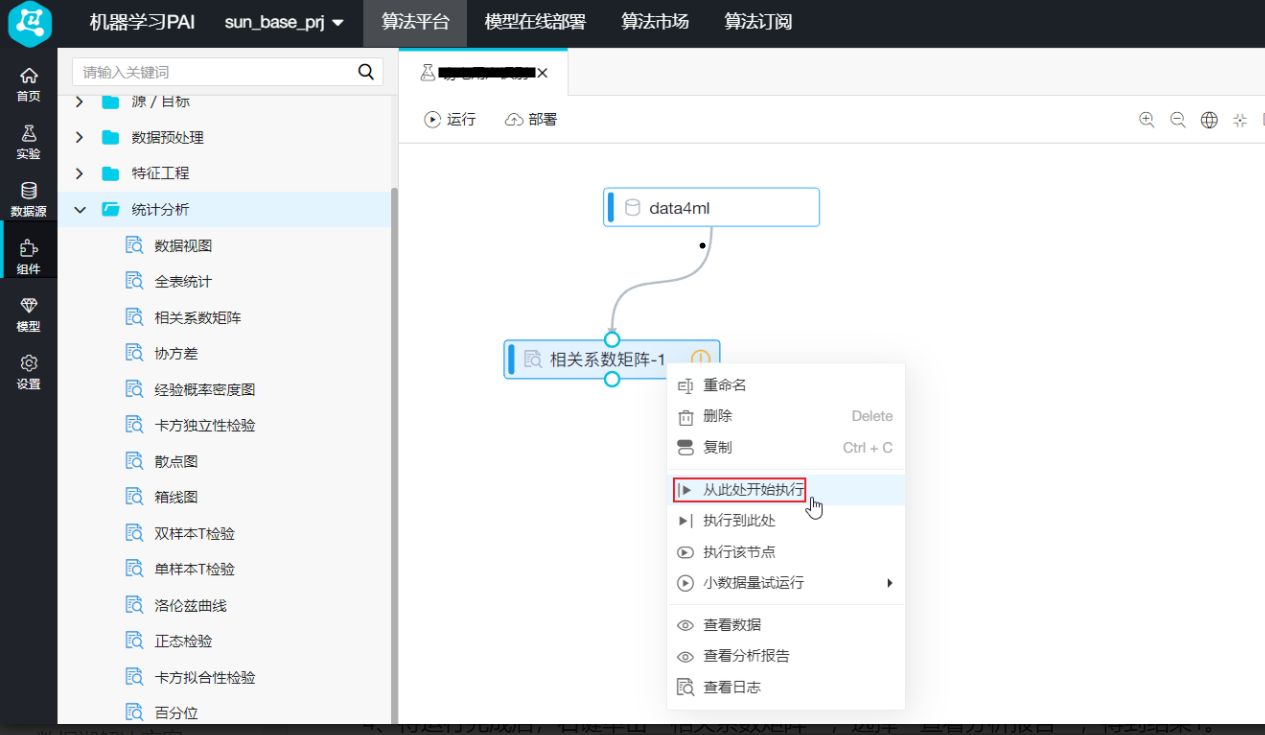
分析结果如下
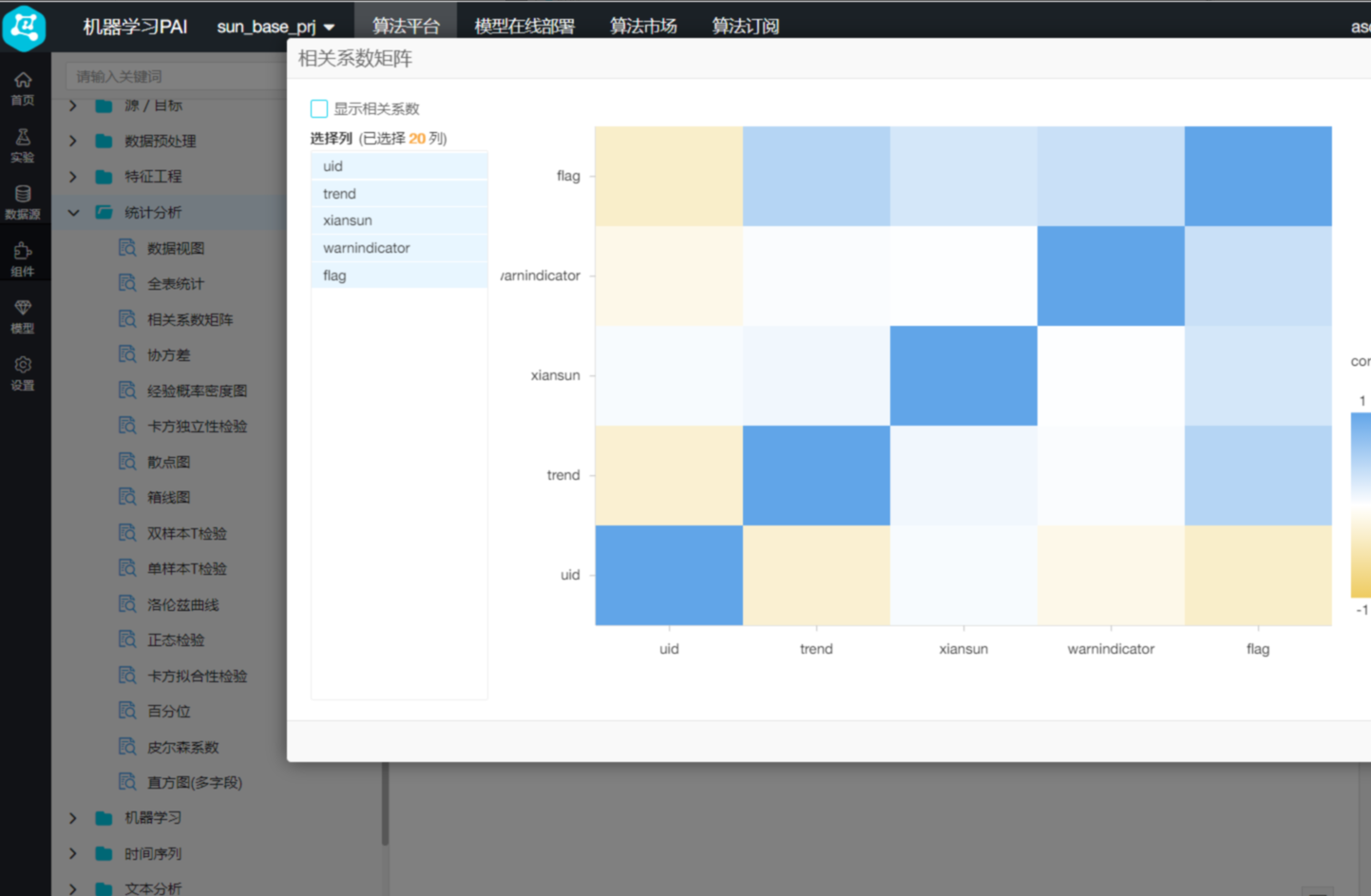
从结果来看三个单一指标对结果的相关性并不明显,即三个单维度特征均无法形成对结果的判定。
接下来进行特征分析,即通过统计分析里的数据视图来查看各维度特征关联关系。
点击左侧导航栏中的“组件”,拖拽“统计分析 -> 数据视图”至右侧画布,连线“读数据表”中ODPS源的输出和“数据视图”的输入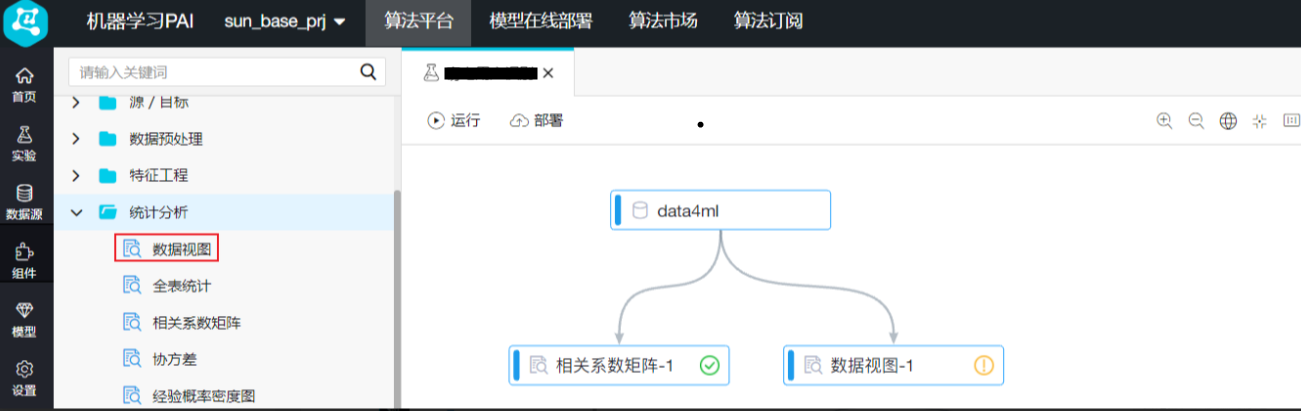 接下来选择特征字段,选择需要分析的三个特征字段。
接下来选择特征字段,选择需要分析的三个特征字段。 接下来设置目标字段:
接下来设置目标字段: 右键单击画布中的“数据视图”,选择“从此处开始执行”,待运行完成后,右键单击“数据视图”,选择“查看分析报告”,得到结果如下:
右键单击画布中的“数据视图”,选择“从此处开始执行”,待运行完成后,右键单击“数据视图”,选择“查看分析报告”,得到结果如下: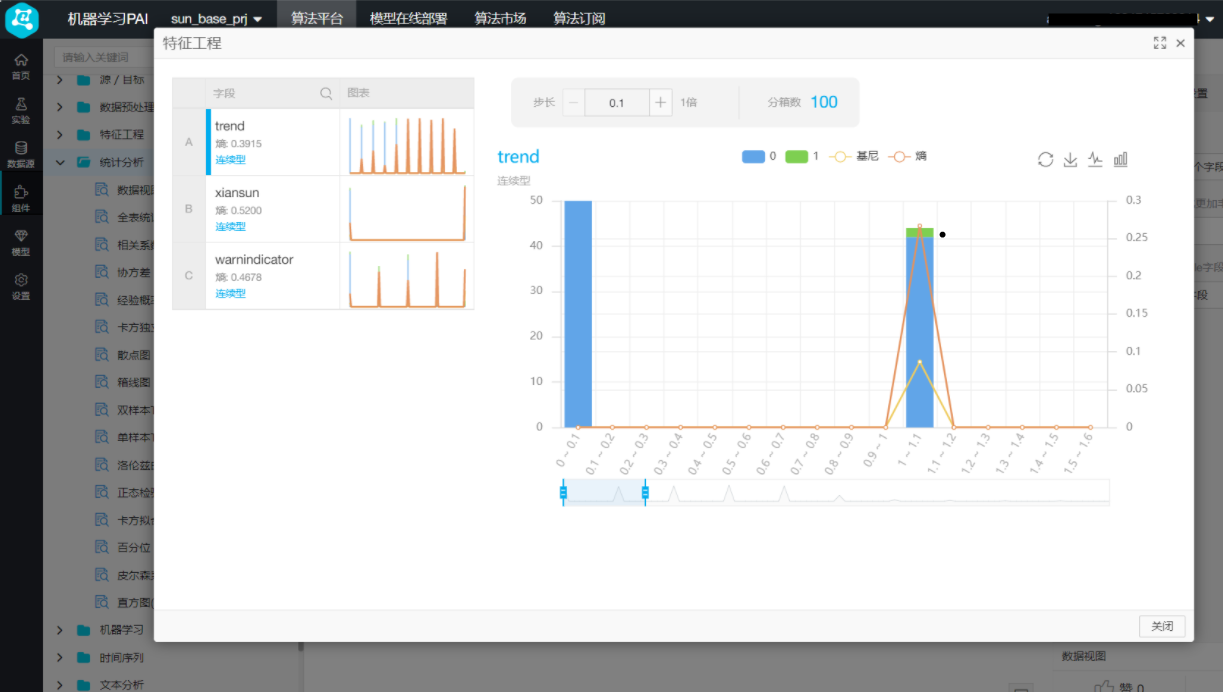 分析报告如下图所示,可查看各个特征和标签列在数据分布上的关系
分析报告如下图所示,可查看各个特征和标签列在数据分布上的关系
接下来进行数据建模,首先将数据集进行划分,80%训练,20%预测,选择逻辑回归二分类方法建模: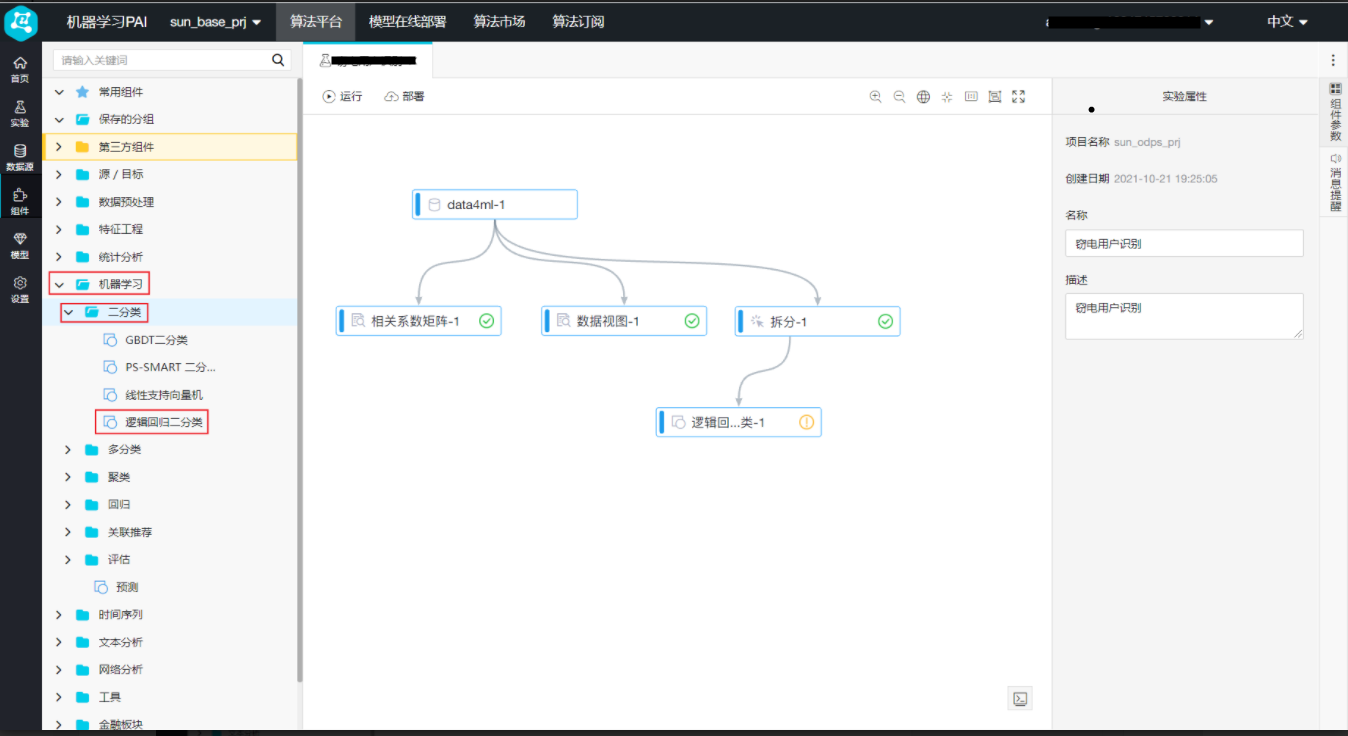 双击画布中的“逻辑回归二分类”,选择右侧的“字段设置 -> 选择特征列”,点击【选择字段】,弹出“选择字段对话框”,在对话框中,选择trend、xiansun和warnindicator这三个字段,点击【确定】
双击画布中的“逻辑回归二分类”,选择右侧的“字段设置 -> 选择特征列”,点击【选择字段】,弹出“选择字段对话框”,在对话框中,选择trend、xiansun和warnindicator这三个字段,点击【确定】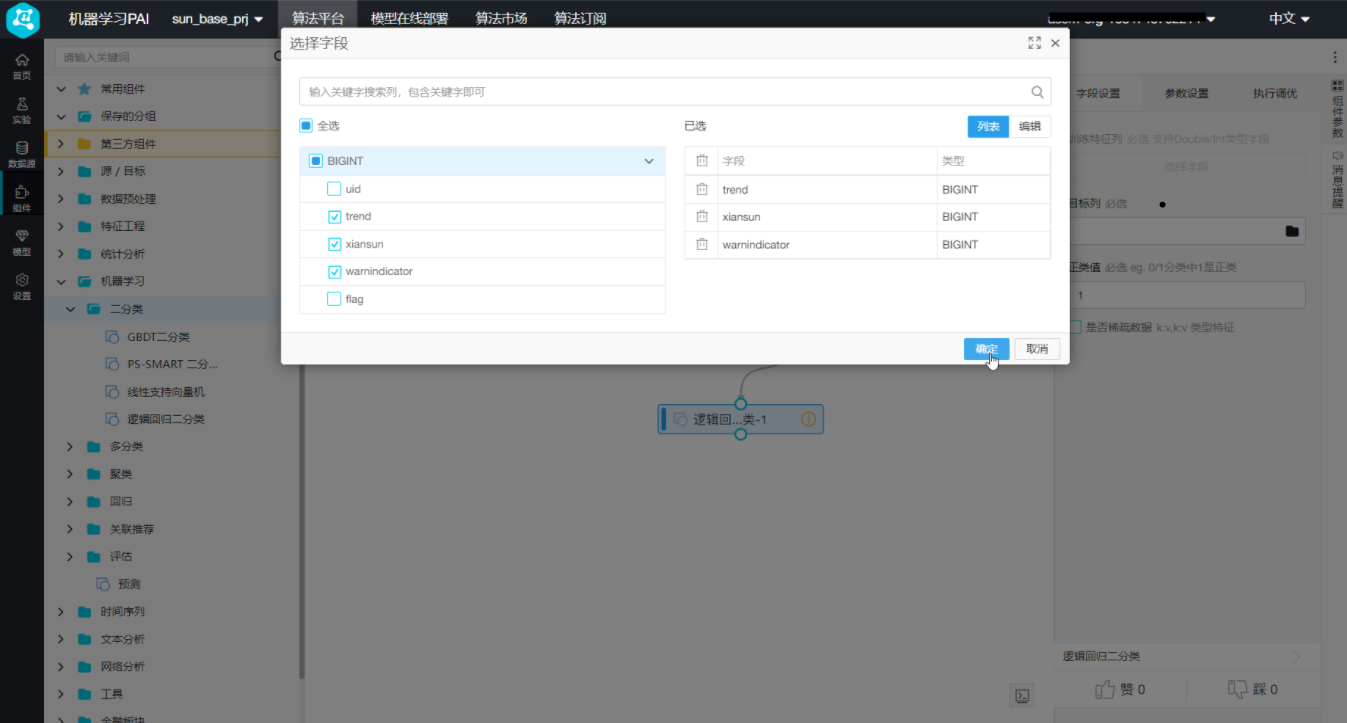 在“字段设置 -> 选择目标列”中,选择目标列为“flag”
在“字段设置 -> 选择目标列”中,选择目标列为“flag”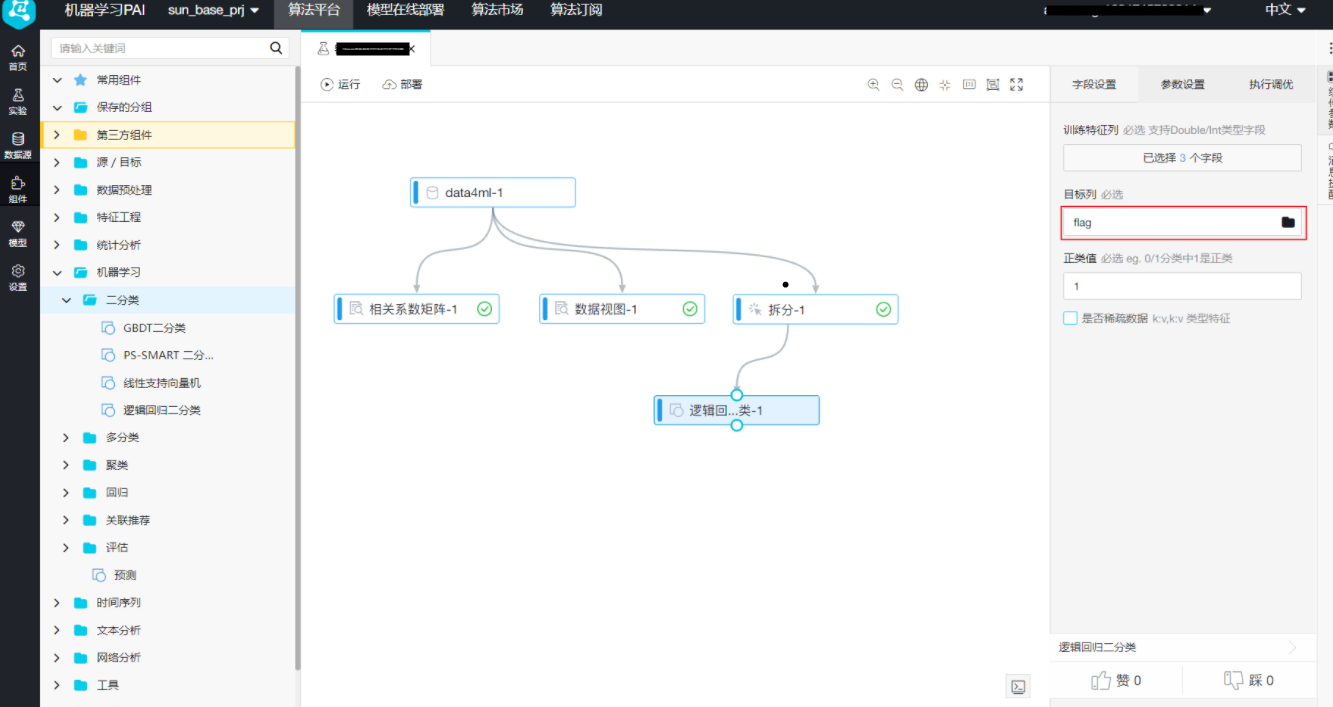 右键单击画布中的“逻辑回归二分类”,选择“从此处开始执行”,待运行完成后,右键单击“逻辑回归二分类”,选择“模型选项 -> 查看模型”,得到结果
右键单击画布中的“逻辑回归二分类”,选择“从此处开始执行”,待运行完成后,右键单击“逻辑回归二分类”,选择“模型选项 -> 查看模型”,得到结果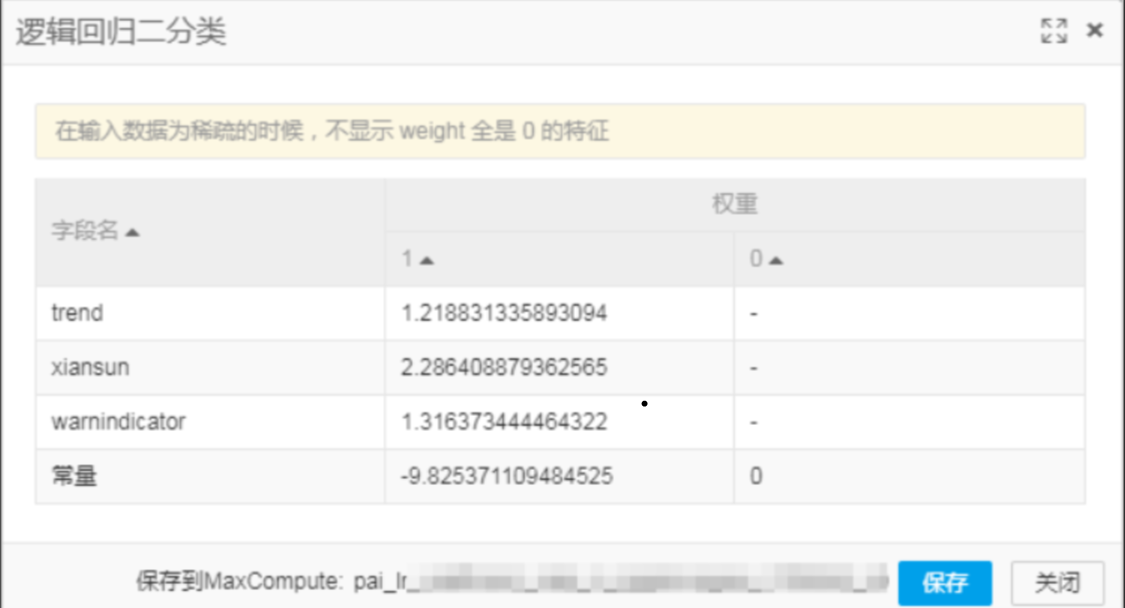
模型训练完毕后,需要用拆分的测试集进行预测,点击左侧导航栏中的“组件”,拖拽“机器学习 -> 预测”至右侧画布,连线“逻辑回归二分类”中的逻辑回归模型和“预测”中的模型结果输入。连线“拆分”中的输出表2和“预测”的预测数据输入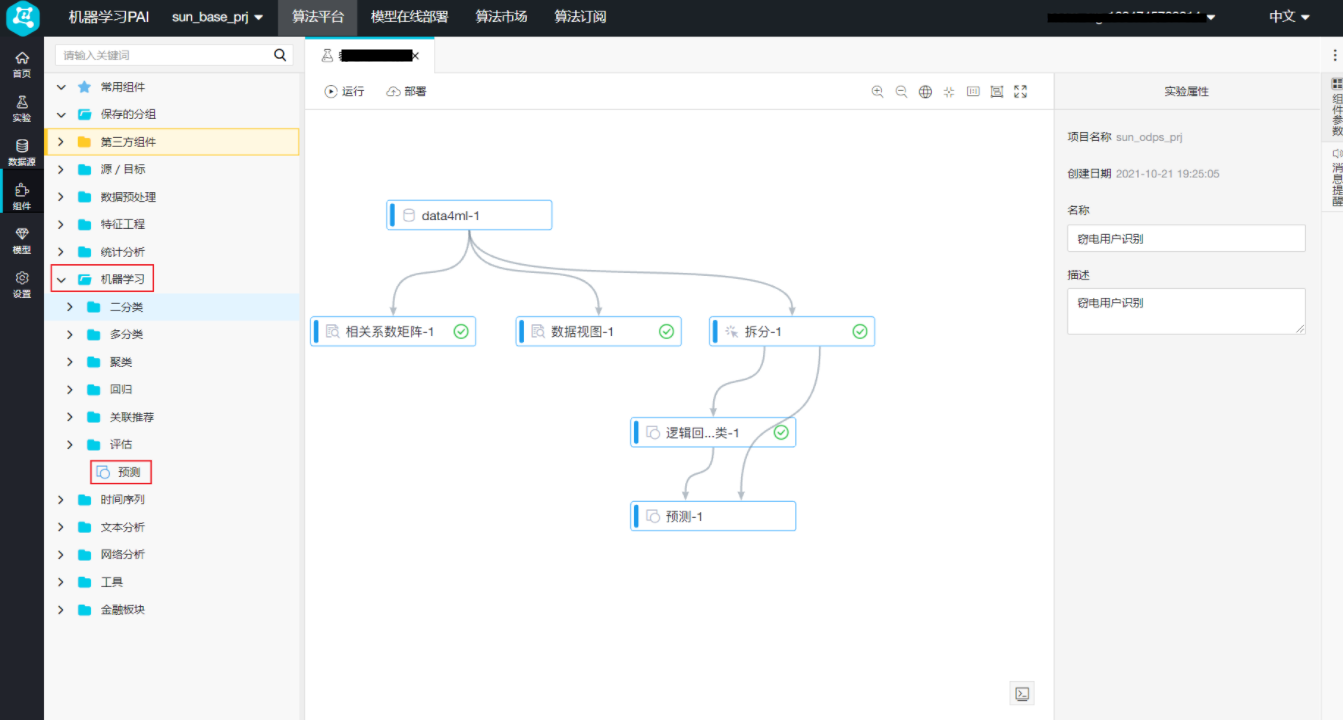 双击“预测”,找到右侧的“字段设置”页签,“特征列”默认全选,点击“原样输出列”下的【选择字段】
双击“预测”,找到右侧的“字段设置”页签,“特征列”默认全选,点击“原样输出列”下的【选择字段】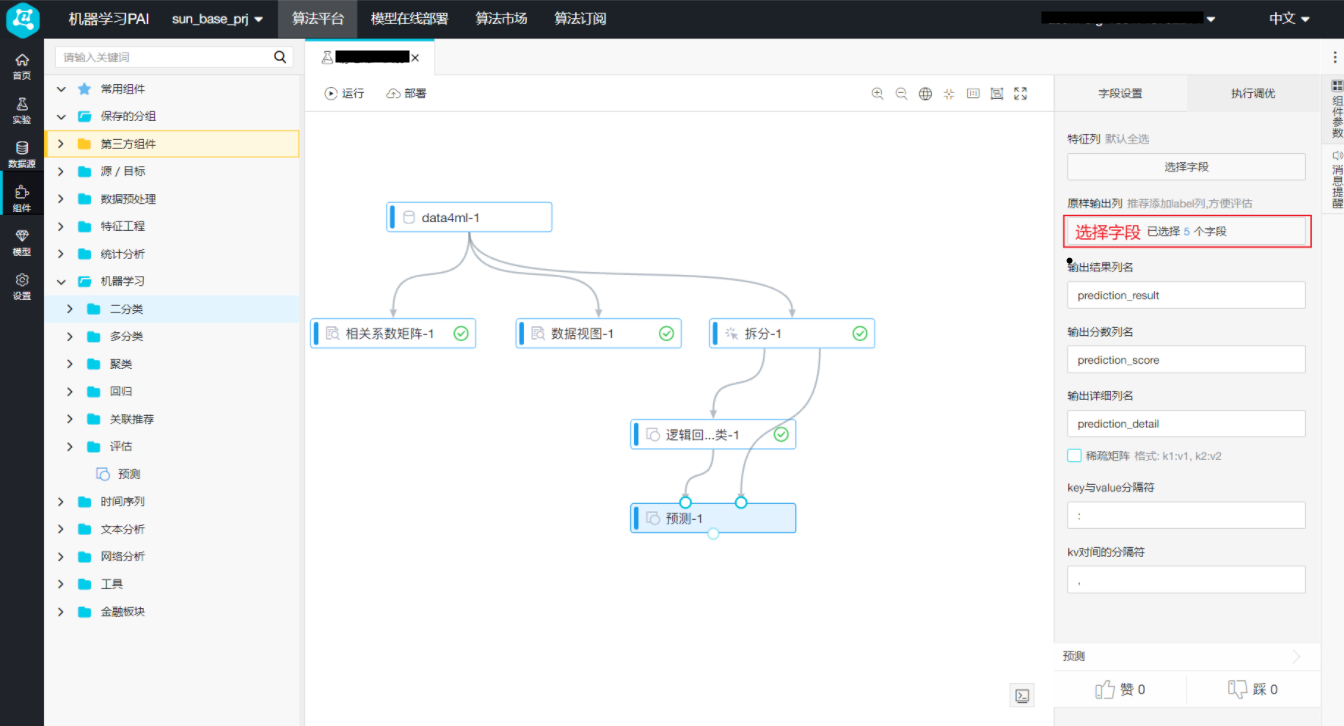 在弹出“选择字段”对话框中,全选5个字段,点击【确定】
在弹出“选择字段”对话框中,全选5个字段,点击【确定】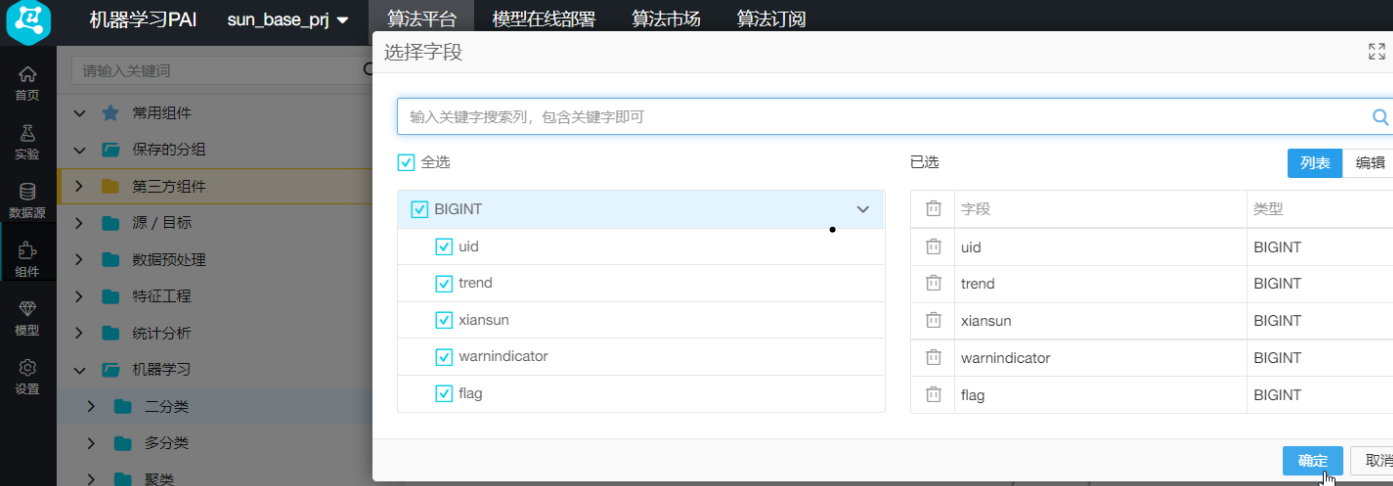 右键单击画布中的“预测”,选择“从此处开始执行”,待运行完成后,右键单击“预测”,选择“查看数据”,得到结果如下:
右键单击画布中的“预测”,选择“从此处开始执行”,待运行完成后,右键单击“预测”,选择“查看数据”,得到结果如下:
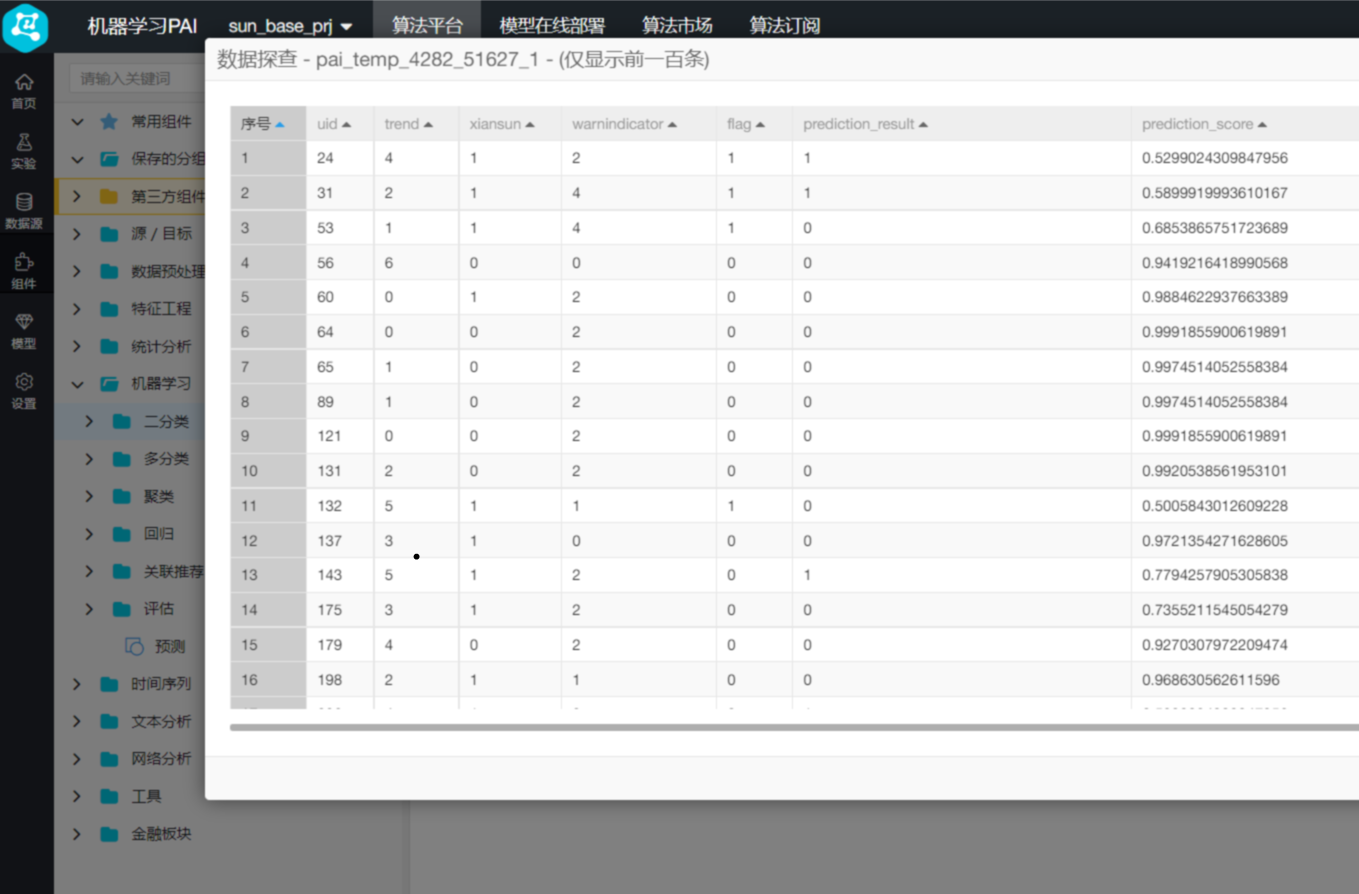
最后我们需要对此模型最终效果进行评估,通过二分类评估组件,获取模型效果。
首先点击左侧导航栏中的“组件”,拖拽“机器学习 ->评估 -> 二分类评估”至右侧画布,然后连线“预测”中的预测结果输出和“二分类评估”中的输入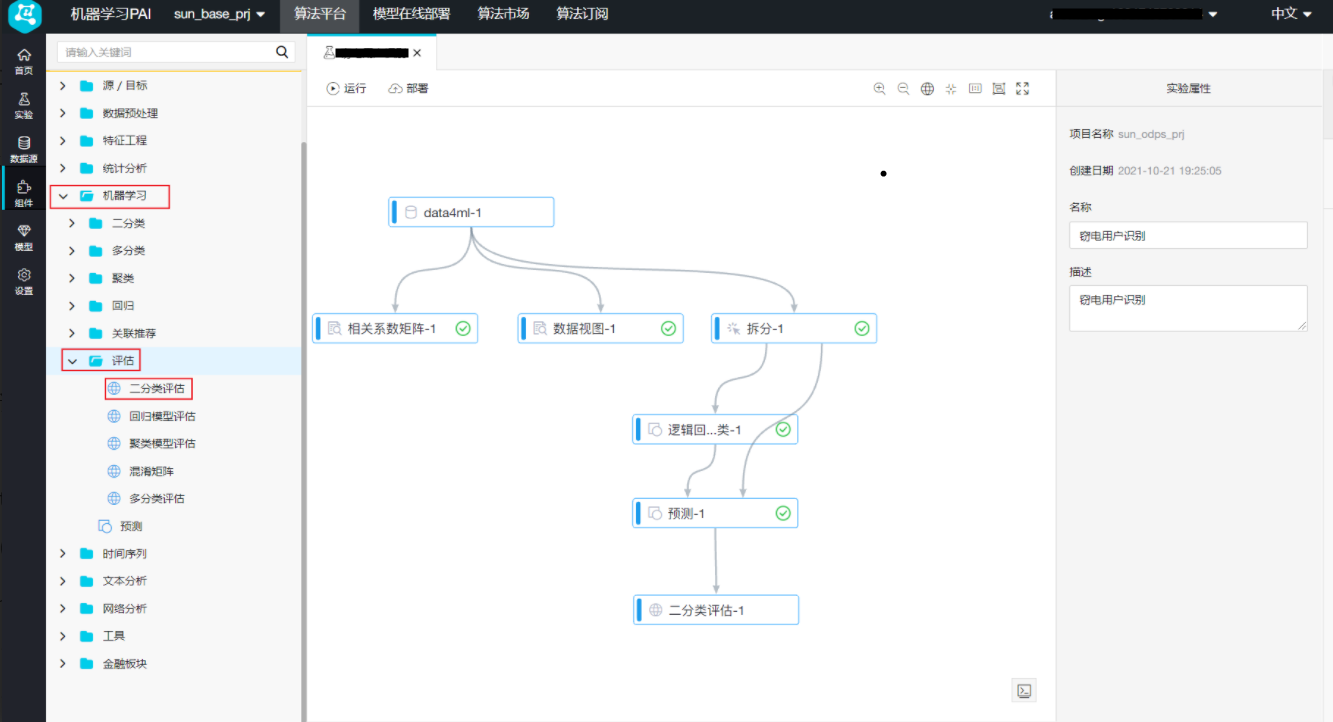 双击“二分类评估”,选择右侧的“字段设置 -> 原始标签列列名”为flag
双击“二分类评估”,选择右侧的“字段设置 -> 原始标签列列名”为flag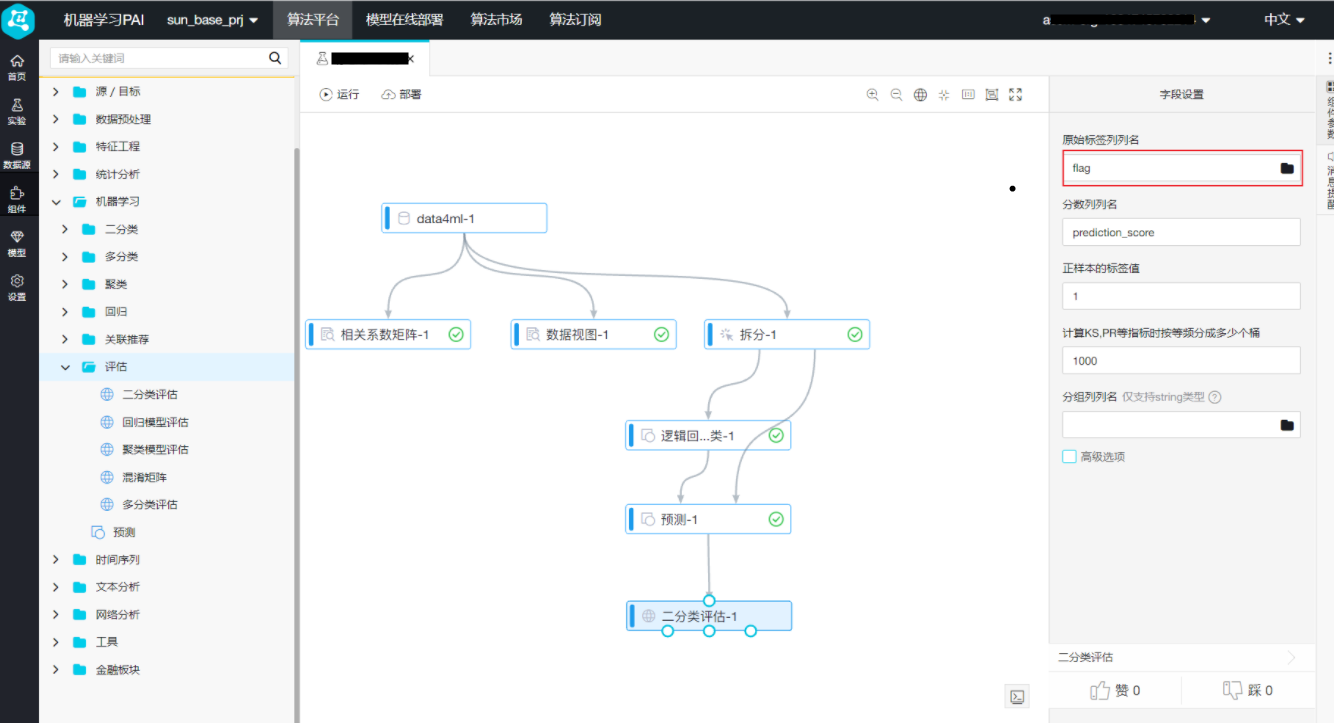 右键单击画布中的“二分类评估”,选择“从此处开始执行”,待运行完成后,右键单击“二分类评估”,选择“查看评估报告”,得到结果
右键单击画布中的“二分类评估”,选择“从此处开始执行”,待运行完成后,右键单击“二分类评估”,选择“查看评估报告”,得到结果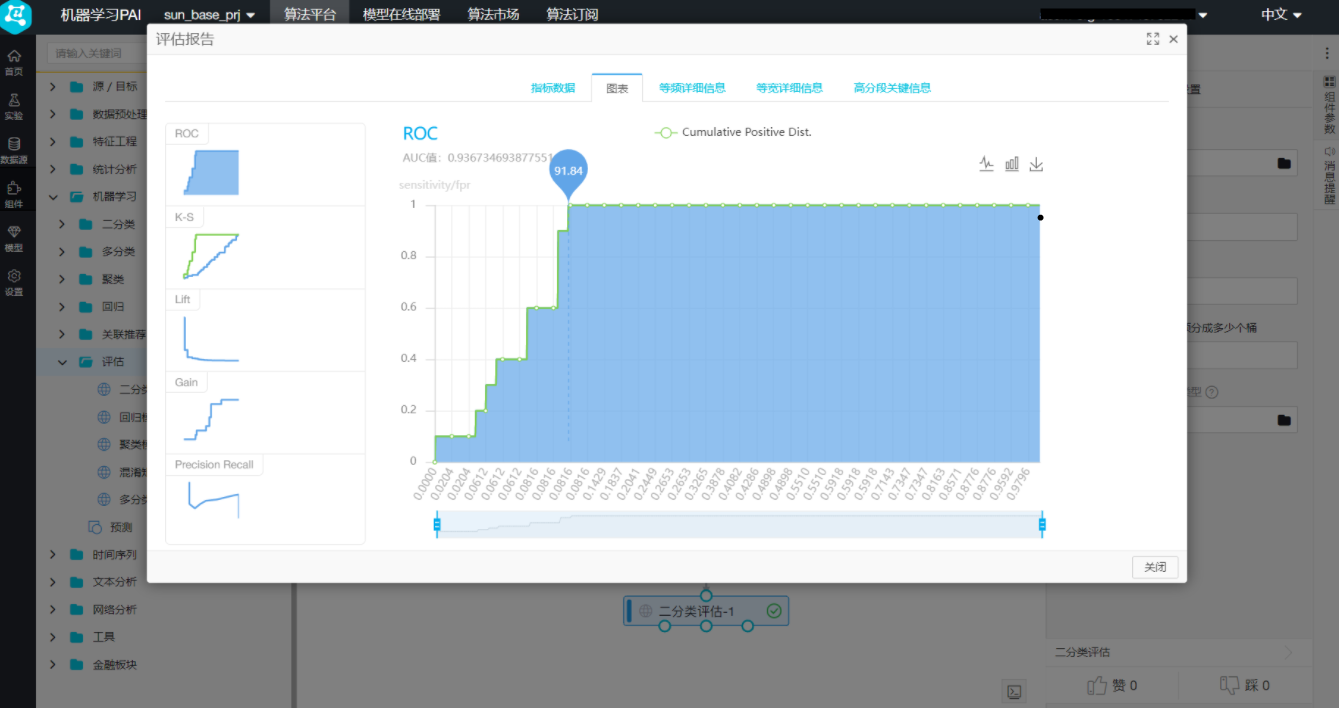 从ROC曲线来看,得分91.84,说明此模型训练是符合预期的。
从ROC曲线来看,得分91.84,说明此模型训练是符合预期的。
以上就是通过大数据结合机器学习的通用解决方案。