本文介绍从Oracle迁移到PolarDB过程中常遇到的中文排序问题的解决方案。
背景
字符集问题是异构数据库迁移的常见问题,在中国Oracle常用字符集是zhs16gbk,排序规则一般是binary,也就是按照二进制编码进行排序,在PolarDB线下输出的版本中只支持UTF8,并不支持GBK,字符集的不同会导致排序不一致,存在兼容性问题,本文以实际项目中遇到的案例来介绍下PolarDB的字符集配置,供大家参考。
过程问题
源库:Oracle 11g
目标库:专有云PolarDB Oracle引擎 11.2
在做功能测试过程中发现排序sql在源库和目标库不一致。
Oracle:

PolarDB
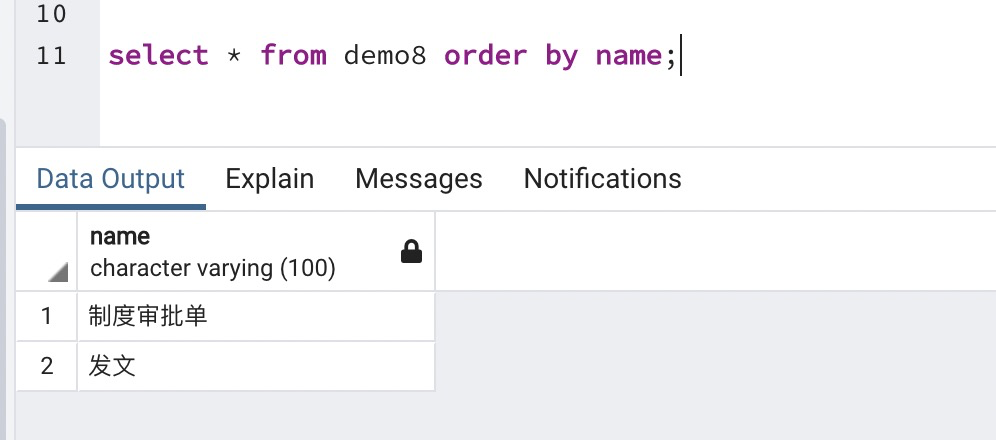
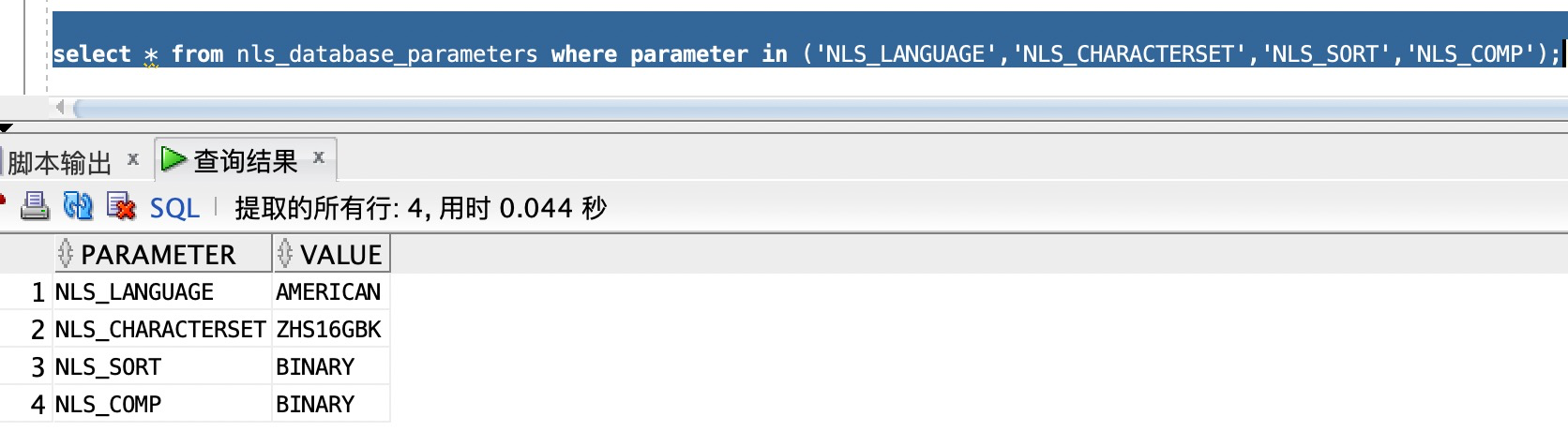
数据库查询中影响排序结果的因素一般是字符编码和校对规则,所以分别查看两个库的字符集和校对规则。
Oracle:
PolarDB:
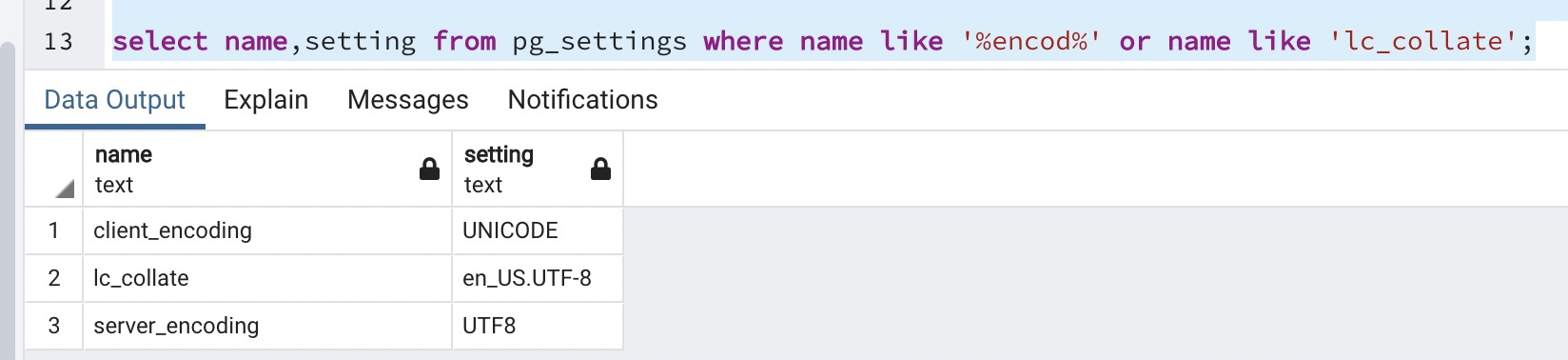
可以看到两个数据库的字符编码是不同的, Oracle是GBK,PolarDB是UTF8,Oracle排序规则是binary,也就是按照二进制编码进行排序,PolarDB字符校对规则是en_US.UTF8,基本也可以等同于按照二进制编码比较。所以目前看起来最大的不同是字符编码的不同,我们具体看一下字段内容的16进制编码。
Oracle(encoding:zhs16gbk)
DECLARE
a varchar2(100);
a_hex varchar2(200);
CURSOR cur is select name from demo8 order by name;
BEGIN
open cur;
dbms_output.put_line('start');
Loop
fetch cur into a;
EXIT when cur % NOTFOUND;
select rawtohex(a) into a_hex from dual;
dbms_output.put_line(a||' #### '||a_hex);
end loop;
close cur;
END;
得到结果集:
发文 #### B7A2CEC4
制度审批单 #### D6C6B6C8C9F3C5FAB5A5Oracle(encoding:UTF8):
得到结果集:
制度审批单 #### E588B6E5BAA6E5AEA1E689B9E58D95
发文 #### E58F91E69687PolarDB(encoding:UTF-8):
select name||' #### '||upper(encode(name::bytea,'hex'::text)) from demo8 order by name;
得到结果集:
制度审批单 #### E588B6E5BAA6E5AEA1E689B9E58D95
发文 #### E58F91E69687为对比结果,我们新部署了一个UTF8字符集的Oracle。可以看到 PolarDB(encoding:UTF-8)的排序结果、字段内容16进制结果和Oracle(encoding:UTF8)一致,ORACLE(encoding:zhs16gbk)排序结果以及字符串16进制结果是不同的,并且也能看到中文UTF8编码是3个字节,中文GBK编码是2个字节。中文字符在不同系统编码环境中的表现不一致,会带来很多问题,不仅仅是影响数据的显示顺序,某些场景下还会导致数据不能正常显示,比如在某保险信创项目中,客户侧对数据进行排序后,只取TOP 10的值给用户进行选择,迁移到PolarDB后,中文排序表现不一致,会导致用户看不到想要的内容,导致业务异常。
解决方案
解决方案有多种,最简单就是把字符编码保持一致,也就是在PolarDB侧修改字符编码为GBK,但是很不辛,当前线下输出的PolarDB还未支持GBK字符集。当然很快研发就会支持GBK字符集。
第二种方案就是修改PolarDB 校对规则,改成本地化语言的方式来进行字符排序,在PolarDB中相关参数是lc_collate和lc_ctype,在创建数据库的时候可以设置,例如字符集设置为UTF-8,lc_collate和lc_ctype设置为zh_CN.utf8。
create database test05 with encoding 'UTF-8' template template0 lc_collate='zh_CN.utf8' lc_ctype='zh_CN.utf8';为确保实验可观测性,我们新插入多条数据:
insert into demo8 values('a');
insert into demo8 values('ca');
insert into demo8 values('1');
insert into demo8 values('哈哈啊');
insert into demo8 values('你');
insert into demo8 values('你好');
insert into demo8 values('张三');
insert into demo8 values('李四');
commit;分别查看排序SQL运行结果:
Oracle(encoding:zhs16gbk)
1 #### 31
a #### 61
ca #### 6361
发文 #### B7A2CEC4
哈哈啊 #### B9FEB9FEB0A1
李四 #### C0EECBC4
你 #### C4E3
你好 #### C4E3BAC3
张三 #### D5C5C8FD
制度审批单 #### D6C6B6C8C9F3C5FAB5A5PolarDB(encoding:UTF-8,lc_collate:zh_CN.UTF8)
1 #### 31
a #### 61
ca #### 6361
发文 #### E58F91E69687
哈哈啊 #### E59388E59388E5958A
李四 #### E69D8EE59B9B
你 #### E4BDA0
你好 #### E4BDA0E5A5BD
张三 #### E5BCA0E4B889
制度审批单 #### E588B6E5BAA6E5AEA1E689B9E58D95PolarDB(encoding:UTF-8,lc_collate:en_US.UTF8)
1 #### 31
a #### 61
ca #### 6361
你 #### E4BDA0
你好 #### E4BDA0E5A5BD
制度审批单 #### E588B6E5BAA6E5AEA1E689B9E58D95
发文 #### E58F91E69687
哈哈啊 #### E59388E59388E5958A
张三 #### E5BCA0E4B889
李四 #### E69D8EE59B9B对比一下结果,Oracle(encoding:zhs16gbk) 和 PolarDB(encoding:UTF-8,lc_collate: zh_CN.UTF8)虽然编码不同,但是排序结果是一致的;Oracle(encoding:zhs16gbk) 和 PolarDB(encoding:UTF-8,lc_collate: en_US.UTF8)排序结果不一致,编码也不同。
PG支持在SQL级别定义校对规则,不同的校对规则会产生不同的结果,例如:
SELECT '制度审批单' < ('发文' COLLATE "zh_CN");
得到结果集:
false
######################################################
SELECT '制度审批单' < ('发文' COLLATE "en_US");
得到结果集:
true当然在排序中也可以自定义collate,例如:
PolarDB (encoding:UTF-8,lc_collate: en_US.UTF8)
select name||' #### '||upper(encode(name::bytea,'hex'::text)) from demo8 order by name collate "zh_CN";
得到结果集:
1 #### 31
a #### 61
ca #### 6361
发文 #### E58F91E69687
哈哈啊 #### E59388E59388E5958A
李四 #### E69D8EE59B9B
你 #### E4BDA0
你好 #### E4BDA0E5A5BD
张三 #### E5BCA0E4B889
制度审批单 #### E588B6E5BAA6E5AEA1E689B9E58D95PolarDB自定义校对规则的写法非常灵活,有兴趣的同学可参考:https://www.postgresql.org/docs/14/collation.html