本文主要介绍如何在Oracle迁移PolarDB过程中,如何做全量校验,以及实现原理。
背景
在交付大型OLTP迁移PolarDB的项目中,一般会要求做数据库一致性校验,用于确保数据一致性,这是做割接的前置条件。我们有很多种数据校验手段,常见的有全量校验、指标聚合校验、抽样校验、行数校验等,在实际的项目中我们一般会组合多种校验手段来完成数据校验。本文主要介绍Oracle迁移PolarDB的一种全量校验简易实现方式。
原理
数据同步原理
在政企客户的项目交付中,经常遇到大量无主键表的场景,我们使用ROWID来作为唯一键,来解决无主键表的数据一致性问题,DTS完整支持基于ROWID的迁移,逻辑如下:
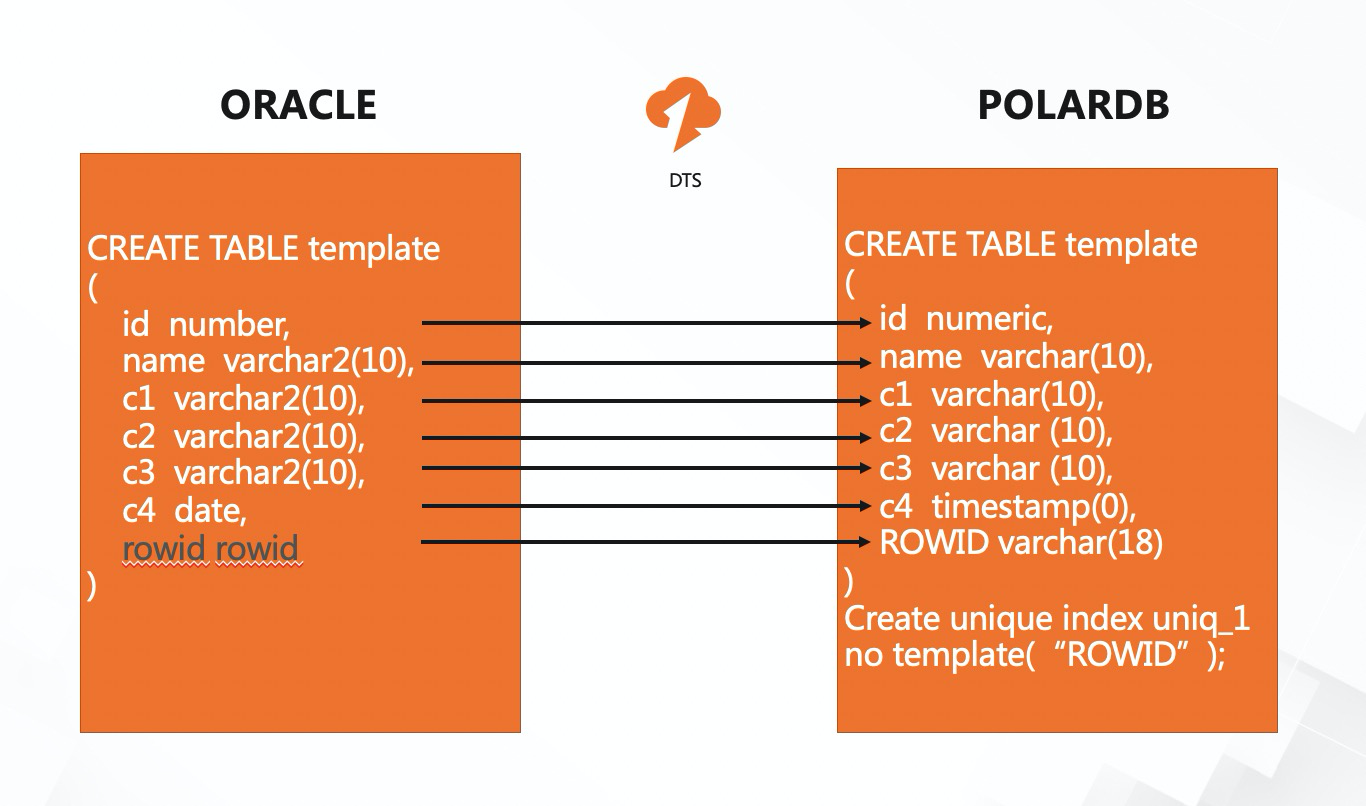
数据校验原理
基于前文的数据同步原理,相应的也可以通过ROWID的唯一性来实现一致性校验,基于ROWID的顺序性和唯一性,我们完全可以通过rowid来切分数据,进行并行校验。
切分逻辑
对于大表,为充分利用CPU,我们一般把单表按照规则拆成多个任务并行校验。常见的切分逻辑,除了对有值部分的切分,还需要覆盖无值区间,不然会出现超出值区间的数据校验覆盖不到的问题,逻辑如下:

但是这样的切分逻辑对oracle和polardb并不适用,理由是oracle 的rowid排序和polardb的rowid排序不是一个概念,oracle的排序是物理ROWID的顺序,而polardb的排序是基于ROWID字符串的排序,两者逻辑不等,且结果不一致。该问题导致我们没办法用相同的between逻辑来取数,同样也无法处理上图中的slice0 和slice 4 两种边界值的问题。所以重新设计切分逻辑,例如oracle minus polardb,按照下图设计切分逻辑。
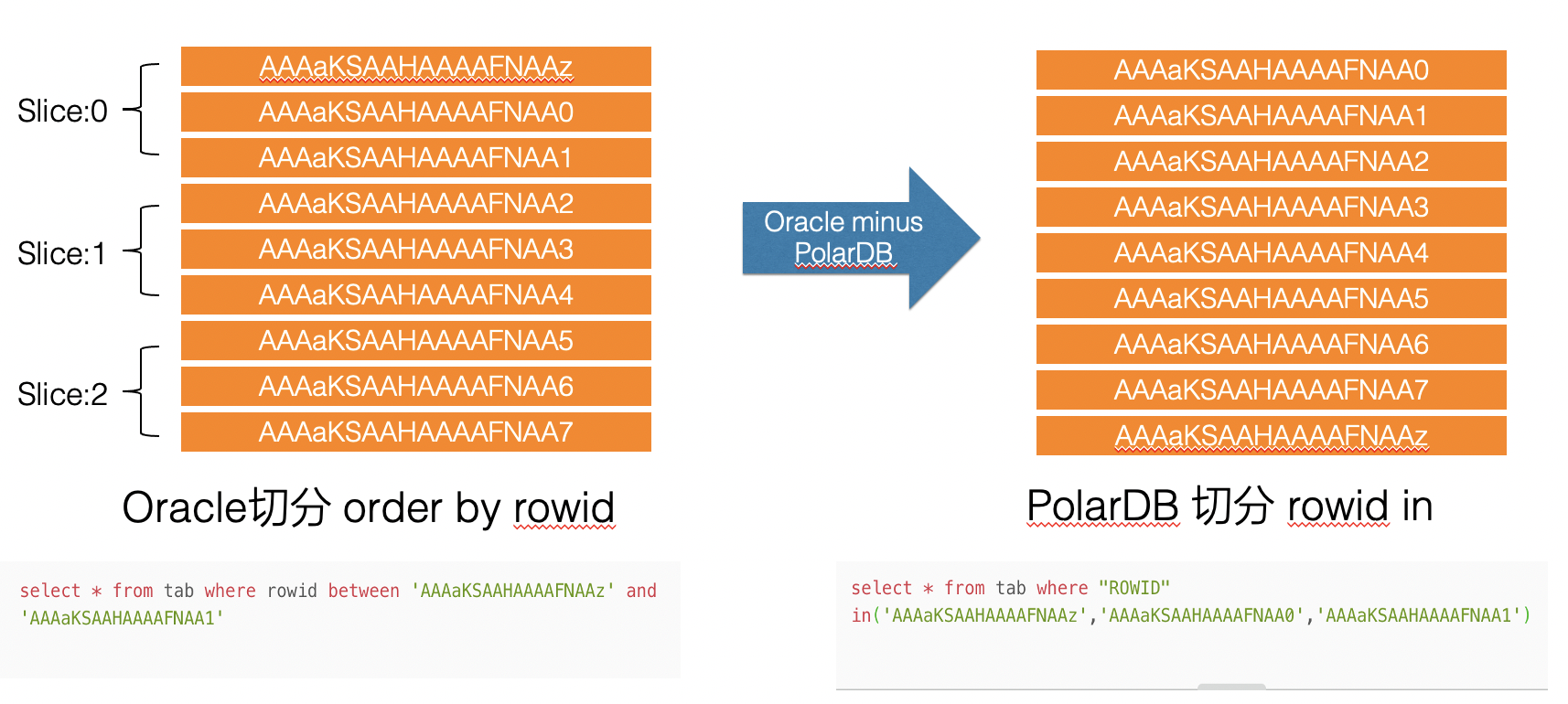
在oracle侧基于oracle rowid顺序切分,然后在polardb侧,基于oracle查询的rowid list 获取对应数据,这样做避免了两边排序不一致带来的问题,在polardb侧切分也遵循同样的原理。在实现该切分方法时,还需要重点关注oracle的切分效率,常见的基于rowid排序分页会存在严重的性能问题,分页切片SQL如图:
set autotrace on;
select * from (select ROWID from zkk.demo where ROWID>'AAAaKSAAHAAAAGCAA0' order by "ROWID" ) where rownum<100;执行计划如图
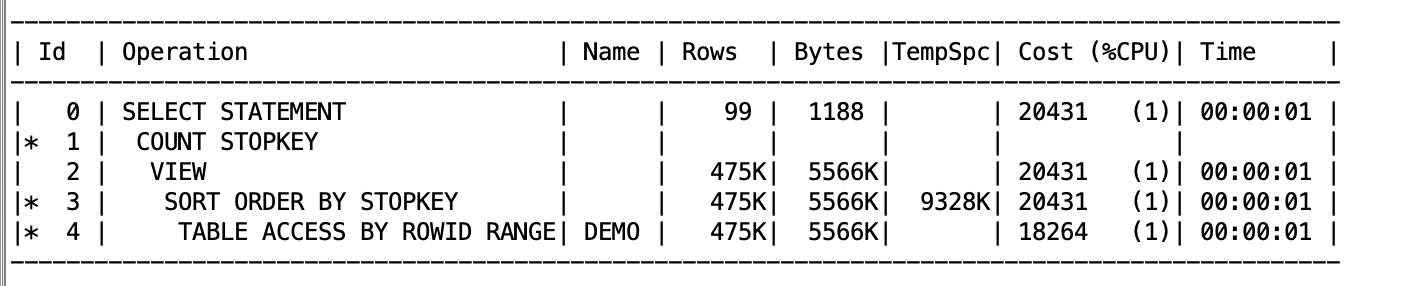
能看到发生了排序操作,存在性能问题,随着数据量和页数的推进,性能会越来越差,此时有两种方法解决该问题:
在本地缓存oracle ROWID,执行sql:select ROWID from tab order by ROWID asc,全表基于ROWID排序不会产生排序操作。然后把结果集存入本地文件,通过本地文件分段读取的方式进行切片。
在polardb端根据ROWID切分,字符串的排序不会出现排序性能的问题。
以上两种方式均能解决切分性能问题,但是遗留下另外一个问题,无法处理边界值问题,例如在polardb端切分,无法解决oracle比polardb数据多的问题,这个问题我们放到数据校验实现模块解决。
校验逻辑
理论上为校验A和B的数据一致性,我们一般做两次操作:A minus B;B minus A。这样既能解决存量数据对比,也能解决在前文提到的数据边界问题。但是在实际工程实现上,两次minus操作存在大量的重复计算,且minus效率低。所以我们把minus转换成hash join,ROWID作为join键,只做一次正向对比,然后在对比一次A和B的数据行数即可。如果A hash join B 一致 ,且A和B 数据行数一致,我们认为全量对比一致。本文主要介绍全量比对,不对行数比对做过多介绍,接下来介绍下怎么用最简单的办法实现全量数据校验。
我们使用spark来解决数据的抽取和校验,能节省大量的编码工作。在切分策略上选择基于Oracle进行切分,这样做的原因是如果基于PolarDB切分,那么就需要在oracle做where "ROWID" in的操作,Oracle限制IN的条数不超过1000,而PolarDB没有这个限制,选择Oracle切分可避免该问题。按照生产者消费者逻辑进行程序设计,整体逻辑如下图:
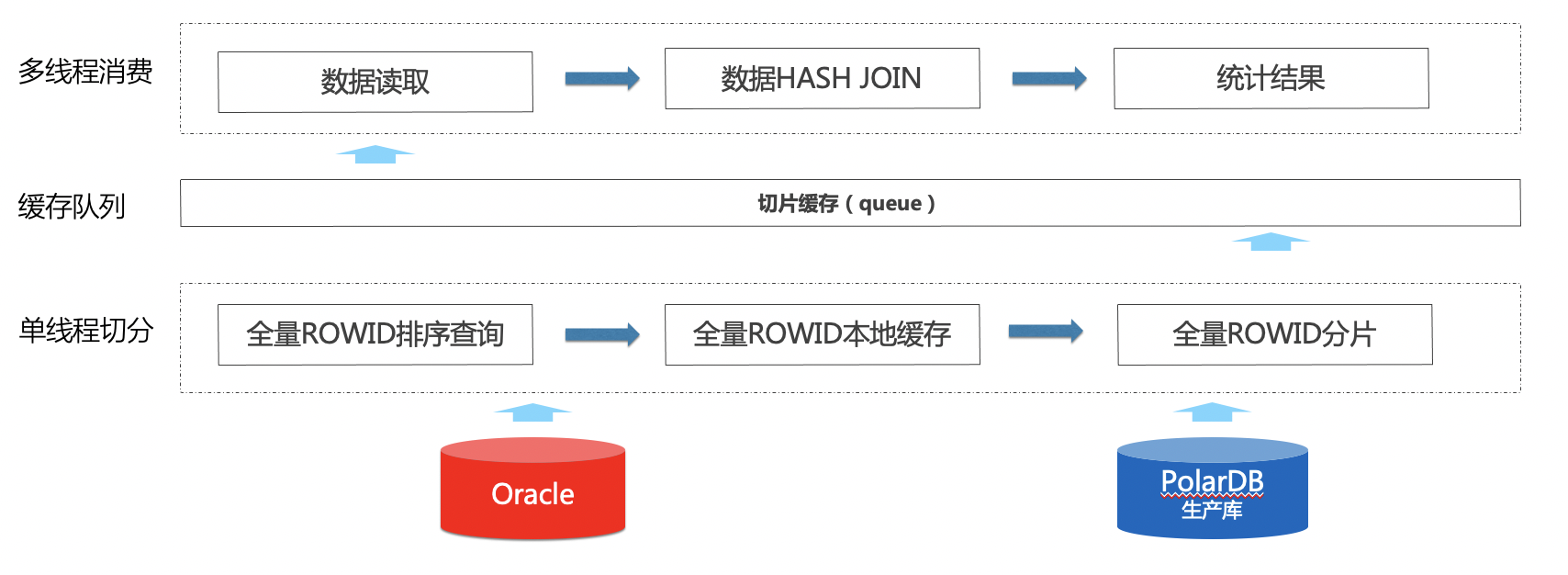
对于大部分的场景,我们都可以复用spark的数据结构来解决结果集的对比问题,但是依然存在一些问题需要解决。在Oracle迁移PolarDB过程中,需要特别关注浮点数类型,浮点数类型一般都做了相应的转换,例如源库binary_float类型,目标库转化为double;源库float类型,目标库转化为real,我们需要在spark层把数据类型统一。
binary_float 转化为double,理论上double比binary_float精度更高,所以我们需要从双精度转换成单精度,才能正常校验binary_float类型。
#使用spark本身的能力,把polardb结果集中的double转换成float
ds=ds.withColumn(columnDefineDO.getColumnName(), ds.col(columnDefineDO.getColumnName()).cast(FloatType$.MODULE$));float转化为real,理论上oracle的float是基于number实现,所以jdbc读取后的类型是BigDecimal,polardb 的real 类型在jdbc读取的类型是double,我们把double转换成BigDecimal。我们知道float(n) ,n的含义并不是10进制意义上的位数, 是二进制有效位数,我们在转换成成BigDecimal时要注意位数转换,转换公式:precision*0.30103,取整数位。
#使用spark本身的能力,把polardb结果集中的real转换成BigDecimal
int precision=new Double(floatPrecision*0.30103).intValue();
ds=ds.withColumn(columnDefineDO.getColumnName(), ds.col(columnDefineDO.getColumnName()).cast(new DecimalType(38,precision)));关注内存使用,注意配置批量拉取的行数,因为是多线程环境,数据需要放到内存中比对,数据量越大内存消耗越大,我们必须关注OOM风险。当前的设计架构只支持调整批量数据条数来控制内存,实际上这种方式存在缺陷,当遇到单行数据过大的场景,依然会出现OOM问题,最佳的方式是根据表的存储大小和表行数,来估算最佳的批量读取行数。
结果统计
最后我们做好数据统计,除了统计不一致的数据条目,还需要记录不一致数据的ROWID,方便问题的定位和排查。