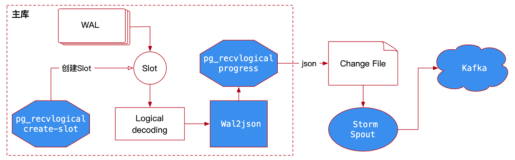
介绍基于流计算与消息中间件链路(Oracle->OGG->DataHub->Flink/Blink->ADB)实现的Oracle到ADB的数据实时同步架构潜在问题及处理方案。
数据流转架构
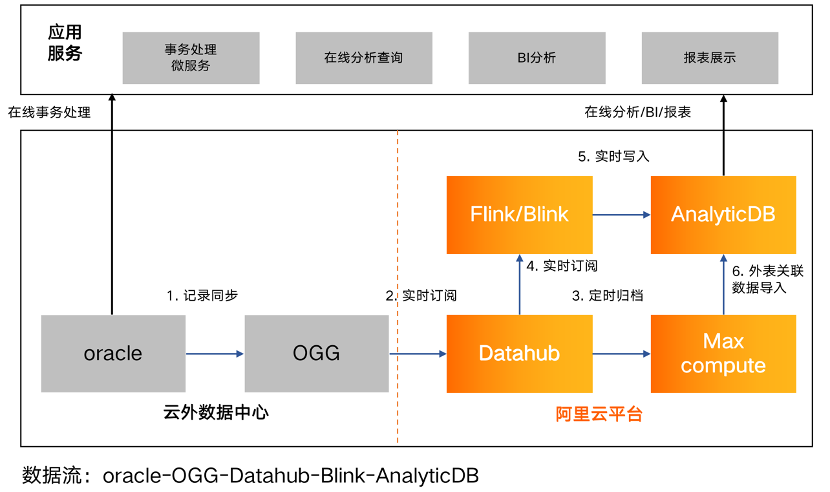
实时数仓架构及数据流转示意
如上图所示,某项目中基础全量数据从离线数仓的MaxCompute导入至ADB,而增量数据生产后经过了Oracle->OGG->DataHub->Flink/Blink->ADB 这样一个冗长的链路才最终复制到ADB中,由于链路串行,任意一个节点异常都可能导致数据复制的效率和稳定性出现问题,受多种原因影响,项目中各环节异常问题均有遭遇,我们花费了较多时间针对这些问题进行了逐一治理,接下来我们将介绍链路中主要组件的运行机制/限制及由此引发的问题,同时给出各问题的解决方案。
各组件的工作机制/限制
Oracle附加日志介绍&OGG订阅日志信息
Oracle附加日志开启后会在redo日志中添加额外信息到日志流中,以支持基于日志的复制工具,如逻辑standby、streams、GoldenGate、LogMiner等,附加日志支持按DB或Table级别设置生效范围,且附加日志一般分为MIN、PK/UK/FK、ALL等三个级别,不同级别下OGG拉取写入DataHub的日志记录内容差异如下:
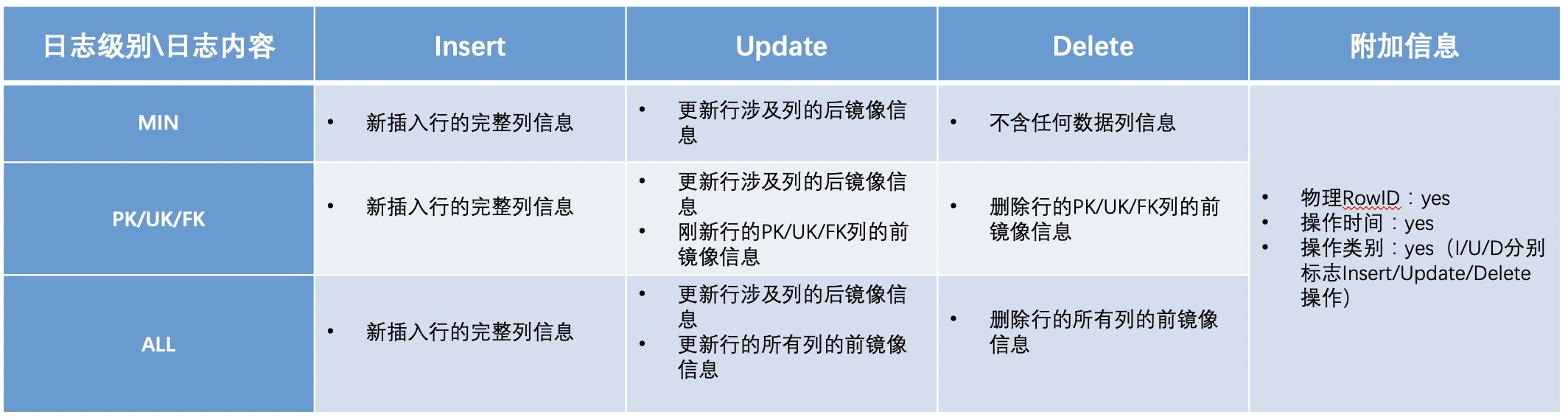
Oracle不同附加日志级别下DML操作的日志数据差异
DataHub数据分布规则
DataHub多shard分布时可指定某个字段列作为shardkey用户数据hash分布,如未指定shardkey对应列则默认生成隐式列自增行号用户数据hash分布。
Flink/Blink写入ADB机制
Blink在实现DataHub源表数据拉取写入ADB目标表时只支持Insert/Replace语法,不支持Delete&update操作,因此无论OGG写入DataHub的增量数据是哪种操作类型,均只能转换为Insert/Replace into语法写入ADB3.0,可参考下图理解:
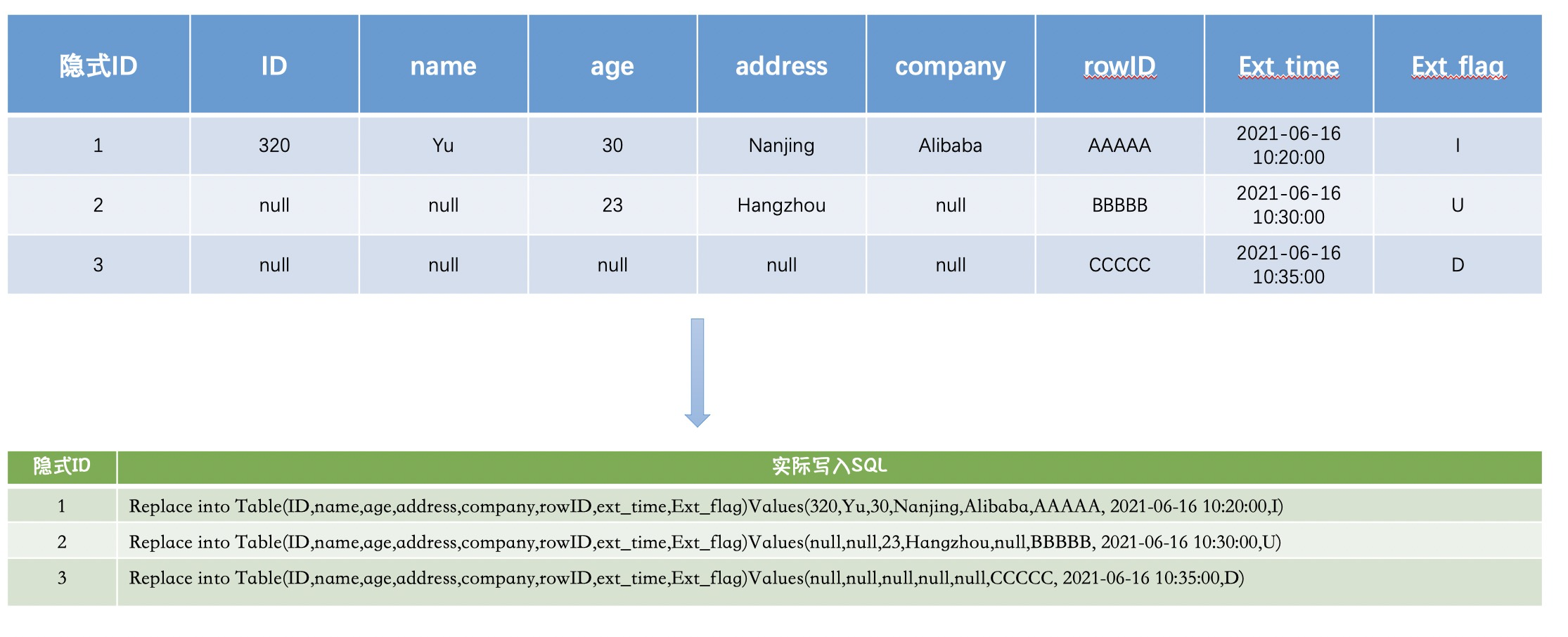
Flink/Blink写入ADB示意
潜在问题及解决方案
Oracle附加日志级别导致的数据冗余问题
基于前面介绍的不同附加级别下的数据内容差异及blink写入ADB3.0机制,实时报表改造项目中涉及的业务表客户的默认附加日志级别是MIN,这就导致了Delete/Update操作写入DataHub的信息大概率不包含PK/UK等唯一键信息,无法使用PK/UK做行定位,只能使用物理RowID做行定位,因此就会出现如下几个问题:
Case1:全量数据是从MaxCompute获取,MaxCompute也是早期基于Oracle复制,ODPS从Oracle逻辑复制全量时并无RowID信息,且全量复制后部分行数据始终未有更新操作,导致MaxCompute无法通过后续的数据合并等操作给该行附加上RowID信息,ADB从MaxCompute全量复制后对应数据行的RowID也是空,此时Oracle侧该行上发生了DML 操作,由于行数据在ADB全量数据中已存在,只是RowID列为空,Flink/Blink获取到增量操作数据尝试覆写进ADB时由于找不到对应RowID的行,因而直接新增写入,导致数据冗余。
Case2:Oracle的物理RowID一般情况下是不变的,但如果表为分区表且遭遇分区分裂或收缩等场景,引发行迁移,某一行的RowID会发生变更,而RowID变更后的增量操作无法在ADB找到对应行覆写,因而新增写入,导致数据冗余。
针对这个问题,解决方案如下:
Oracle附加日志级别调整,至少为PK/UK/FK,或为ALL,从而保证DML操作都会带上PK/UK列前镜像,之后Blink使用PK/UK做行定位,保证始终可以有效更新正确的行。
由于日志级别调整为ALL会记录完整的前镜像信息,导致日志体量增长较大,且有额外的IO压力,对Oracle性能可能有一定影响,故客户最终决定调整为PK/UK/FK级别。
Blink写入机制导致的数据质量问题
前文我们介绍了Flink/Blink支持Insert/Replace写入操作,以上图Flink/Blink写入ADB示意所示结构为例,假如ID列是PK,调整后附加日志级别后我们已经可以固定获取到DML操作行的ID信息,假如此时Oracle侧对ID为5的行company列做了Tencent-> Alibaba 的更新,那么Blink实际重放的操作是这样操作的后果是ADB中ID=5的这行不仅company列被更新成了Alibaba,其他业务列也被 null 值覆盖了,这和Update操作逻辑相悖了,数据质量自然也无法保证了。
这个问题理论上有两个解决方案:
Case1:Flink/Blink从DataHub获取数据写入ADB时,如果获取到Update类型操作,则先回查ADB数据,将所有字段当前值都拉取到,和更新列新值拼接,之后再覆写ADB。
Case2:Flink/Blink端最终的数据操作实际是由sink connector组件(该组件为可定制的Jar包)执行,同时ADB具有upsert特性(当插入行检测已存在时,可以转换为Update操作,只更新有数据的列,Upsert特性只能单行逐行处理),因此可以定制专属的ADB sink connector,实现对Update/Delete 操作的Upsert转换。
Case1由于Flink/Blink回查ADB需要以ADB作为源表,但目前Flink/Blink暂时只支持ADB作为目标表,故方案不可行;最终选择Case2,通过定制sink Connector包并调整参数修改batchsize为1,逐行处理写入,验证该方案可行,但由于逐行处理,验证最高RPS为1500,可满足日常非高峰期增量处理效率(约日300W行更新)。
ADB sink Connector定制包的写入性能问题
定制包性能开发后验证可满足日常非高峰期性能要求,但临近项目上线期伙伴才逐步了解到个别报表月初高峰期会有持续数日的每日千万行级别的数据更新,定制包在高峰期处理效率无法满足该报表需求,且该报表主要作用也是月初大量更新时实时统计汇算,ADB增量入库性能问题亟待解决。
针对该问题同样有两个解决方案:
Case1:由于会对数据质量产生影响的操作只有Update操作,且Update操作较Insert/Delete操作数量差距巨大,因此可以调整ADB sink Connector定制包逻辑,对于Insert/Delete操作正常攒批batchinsert,仅当处理到Update操作时自动退化batchsize=1单步处理
Case2:推动客户再次调整Oracle附加日志级别为ALL,保证DML操作有完整的更新前镜像信息,针对未更新列的空值用前镜像补齐,之后正常攒批batchinsert
由于该问题发生时项目进度紧张,定制包开发迭代需要时间,且开发后需要做效率和数据质量验证,为保证项目进度,两个方案同步进行并分别做性能验证,最终验证Case1调整后RPS达到3W,Case2RPS约3.5W,Case1性能略差于Case2,但均完全满足客户月初日千万行数据更新效率要求,且数据质量均可保证。
DataHub默认分布的坑
如前文DataHub数据分布规则所述,DataHub多shard分区时如不指定shardkey,则会创建隐式列自动hash分区,该项目由于复用离线报表DataHub数据,离线报表链路设计时选择了默认分布,数据是自动分区的,因此导致相同主键的数据无法落在同一个shard内;Flink/Blink多线程从DataHub取数据时,多线程间无法保证全局有序,因此如果出现某行数据在短时间内多次更新,先更新的操作A在shard1中,后更新的操作B在shard2,Flink/Blink线程2先从shard2取了操作B的记录并在ADB执行,线程1随后取了shard1的操作A在ADB执行,结果是ADB最终数据反而是操作A的状态,数据质量无法保证,如下图
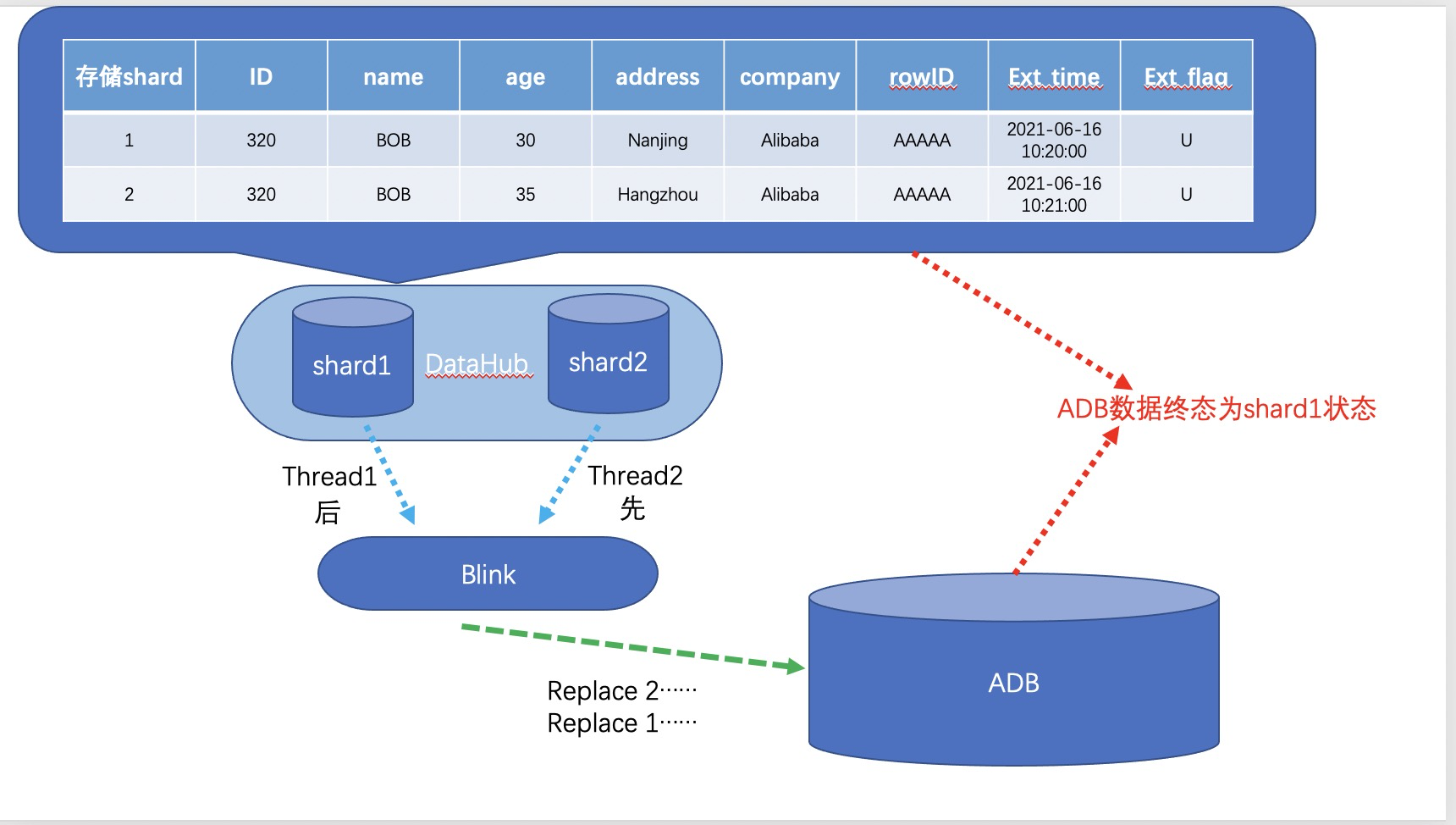
DataHub默认分布导致Flink写入ADB乱序
该问题解决方案有两个:
Case1:DataHub调整shardkey为PK,使数据重分布,重分布后相同主键操作记录在同一shard内,blink拉取时可单shard保序。
Case2:DataHub不做调整,ADB侧定期和Oracle做数据质量校验订正,保证数据质量。
项目中由于调整DataHub的Shardkey可能影响客户其他业务,Case1暂不具备变更条件,最终使用Case2并增加定期校验订正机制保证数据质量。