如何在大促中做好系统高可用是大家都非常关心的一个问题,特别是在双十一之前,在大促过程中做好系统高可用保障是有双十一大促的客户都会了解的一个内容。大流量、系统内部/下游不稳定、单机故障、热点请求等等一系列的问题都会导致一些非预期的情况。那么今天就围绕大促来谈谈,如何在非预期的情况下,始终保持我们的系统工作在最优解?
确定系统容量
我们需要基于大促的应用表现,确定我们的应用在一定的业务条件下的性能基线,以及系统的成本预算。因此我们在大促前需要不断进行多次性能评估以及性能优化,确保应用的性能。那么如何进行有效的压测来确定我们系统的容量呢?首先我们需要评估业务变化以及系统的变化,业务变化就比如这次业务相比之前是否有量级的提升,业务的玩法是否有变化比如618的预售以及抢红包、满减等业务玩法是否会对系统造成稳定性的风险,对用户动向进行分析;系统的变化有比如这一次大促相比之前有无引入新的技术或者新的架构,比如之前都是部署在虚拟机中,这一次大促是在容器上进行。总的来说,需要站从全局视角看系统的关键路径,保障核心业务,梳理强弱依赖。
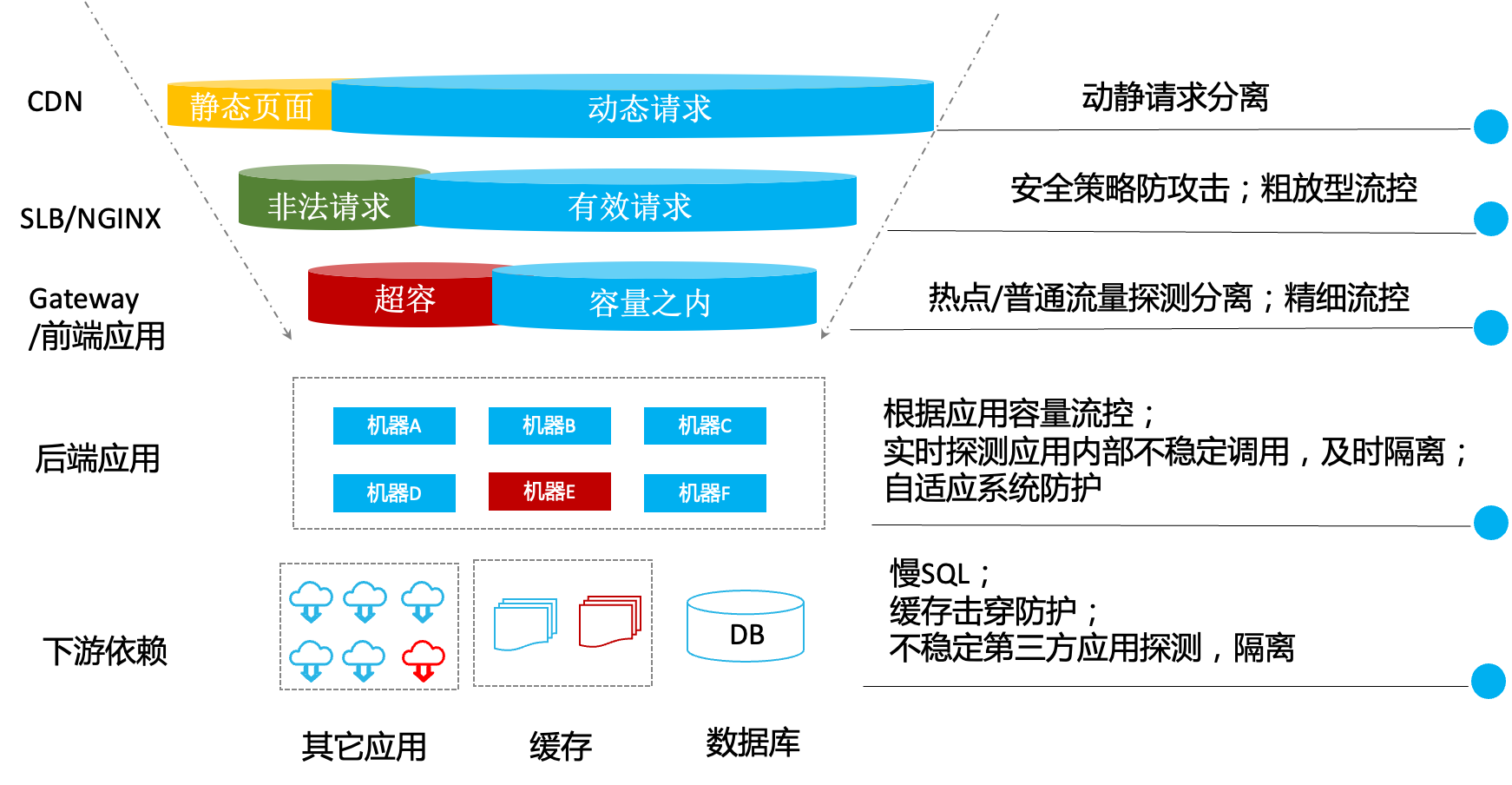
以上就列举了我们生产系统中的组件的情况,以及各个组件在大促时需要进行的防护,流量是从最外层CDN、Niginx到微服务网关、微服务应用最后再到缓存、数据库,因此流量访问路径上的每一环都需要做好大促的防护。如果任意一环节出问题,都会牵一发而动全身,导致我们这次大促的失败。
下面我将会从系统的各个层面谈一谈大促的高可用防护,让系统在非预期情况下始终工作在最优解上。
网关的大促高可用
大促场景下,网关做高可用防护为什么重要?一言以蔽之,网关具备将大促的各种不确定性因素转化为确定性因素的能力,并且这种能力是不可替代的。分别从三个方面来看:
第一点是应对流量峰值的不确定性,必须通过限流规则将不确定的流量变为确定。业务服务模块自己做限流很难实现这一点。因为实现限流防护有个前提,承载这突发流量的服务仍能保持正常的 CPU 负载。业务服务模块即使实现了应用层的 QPS 限流,在瞬时高并发场景下,仍可能因为网络层大量的新建连接导致 CPU 猛涨,限流规则也就形同虚设了。业务模块应该专注在应用层业务逻辑上,若要通过扩容去应对其不擅长的网络层开销,所需的资源成本是相当高的。而网关作为业务流量入口的地位,决定了其必须擅长应对高并发的网络流量,并且这块性能也是衡量网关能力的一个重要指标,应对高并发的性能越强,所需的资源成本就越低,将大促流量从不确定变为确定的能力就越强。
第二点是应对用户行为的不确定性,需要根据不同的大促场景,模拟用户行为进行多轮压测演练,提前发现系统的瓶颈和优化点。网关既是用户访问的流量入口,也是后端业务应答的最终出口。这决定了网关是模拟用户行为进行流量压测的必经一站,也决定了是观测压测指标评估用户体验的必须环节。在网关上边压测,边观察,边调整限流配置,对大促高可用体系的建设,可以起到事半功倍的效果。
第三点是应对安全攻击的不确定性。大促期间也通常是黑灰产活跃的时间,异常的刷单流量很可能触发限流规则,从而影响正常用户的访问。基于网关的流量安全防护能力,例如 WAF 等功能,通过识别出异常流量提前拦截,以及将异常 IP、cookie 自动加入黑名单等手段,既可以使这部分流量排除在限流阈值之外,也可以保障后端业务逻辑安全。这也是大促高可用防护必不可少的一环。
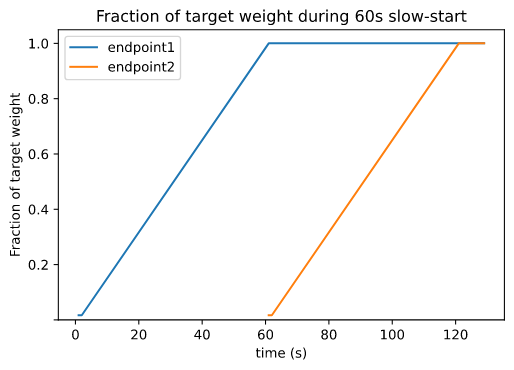
MSE 云原生网关内置了 Alibaba Sentinel 高可用模块,历经多年双十一流量考验,提供了丰富的限流防护能力,包括流控规则、并发规则、熔断规则,可以全面保障后端业务高可用;此外,MSE 云原生网关还具备流量预热能力,通过小流量预热方法,可以有效解决大促场景下,资源初始化慢所导致的大量请求响应慢、请求阻塞问题,避免刚扩容的节点无法提供正常服务,影响用户体验。
微服务系统的大促高可用
面对突增的大流量
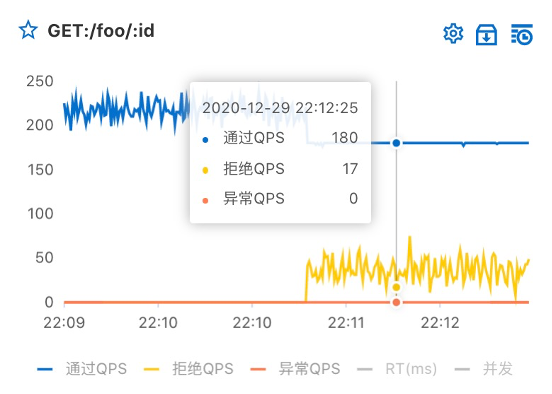
在大促过程中,如果某个时刻激增的脉冲流量到达系统(抢购/秒杀),那么服务可能被打挂。同时另外再考虑一个场景:服务间 RPC 调用需要进行细粒度管控,如服务 A 的调用来源有服务 B 和 C,其中 C 是重点业务,需要优先保障调用;但服务 B 有时会有较大并发调用,影响整体稳定性。因此对于微服务系统来说,特别是在大促过程中,我们需要一种应用的安全气囊--流控能力来保障我们系统的稳定性。面对大促突发的流量,流控能力可以将超出系统服务能力以外的请求拒绝掉,我们在微服务层进行 API、接口、方法、参数粒度控制,只让容量范围内的请求通过。
上下游依赖不稳定
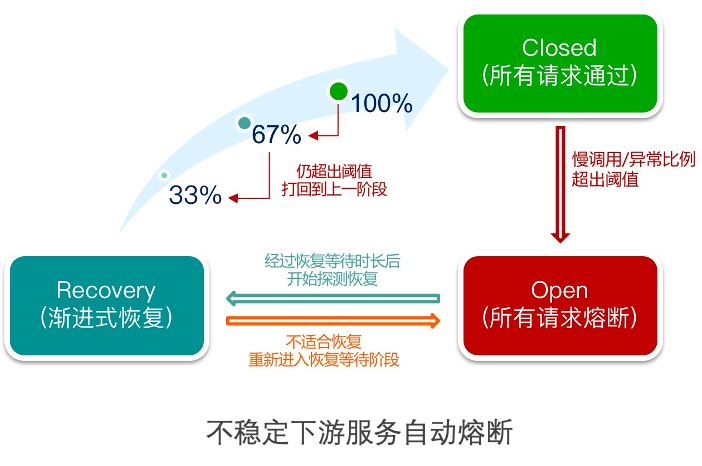
业务高峰期,某些下游的服务提供者遇到性能瓶颈,甚至影响业务。我们对部分非关键服务消费者配置自动熔断,当一段时间内的慢调用比例或错误比例达到一定条件时自动触发熔断,后续一段时间服务调用直接返回Mock的结果,这样既可以保障调用端不被不稳定服务拖垮,又可以给不稳定下游服务一些“喘息”的时间,同时可以保障整个业务链路的正常运转。
单机异常
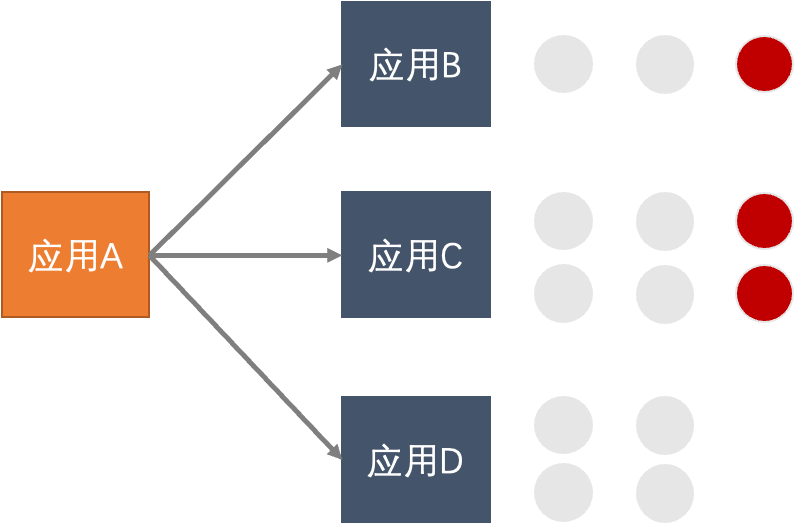
在大促的过程中,应用的某几台机器由于磁盘满,或者是宿主机资源争抢导致load很高,导致客户端出现调用超时,从而影响系统的整体稳定性。我们可以通过配置离群实例摘除规则,可以自动摘除异常的实例,从而保证整体的服务治理。
流量平滑:异步批量任务平滑处理,避免过载
异步任务或消息批量分发到处理端,大促过程中面对批量数过大或某些任务重负载情况,处理端将会无法及时处理任务,从而造成任务堆积,系统负载飙高,影响任务正常处理。

我们可以采用MSE流量治理提供的流量平滑能力(匀速排队流控模式),将大批量的并发任务/请求进行平滑,控制相邻任务的处理时间间隔,多余的任务会排队等待处理,而不会直接拒绝。让系统能够更平缓地处理任务。流量平滑能力可以配合消息队列RocketMQ使用,把超过消费端处理能力的消息均摊到后面系统空闲时去处理,可以让MQ消费端负载保持在消息处理水位之下,同时尽可能处理更多消息,达到削峰填谷的效果。
多语言应用的大促防护
MSE 除了针对Java微服务的流量防护能力,还支持 Go 应用的流量防护能力。Go应用支持Dubbo、Gin Web、gRPC、go-micro等应用,我们只需接入SDK即可具备以上提到的对应的流量防护能力。

微服务访问数据库/缓存视角的大促高可用
对于我们的系统来说,数据库是非常重要的一块,微服务访问数据库的过程中常常会遇到一些问题:
某系统对外提供某查询接口,SQL语句涉及多表join,某些情况下会触发慢查询,耗时长达30s,最终导致 DB 连接池/Tomcat线程池满,应用整体不可用。
应用刚启动,由于数据库Druid连接池还在初始化中,但是此时已经大量请求进入,迅速导致 Dubbo 的线程池满,许多现场卡在初始化数据库连接的过程中,导致业务请求大量报错。
SQL语句处理时间比较长导致线上业务接口出现大量的慢调用,需要快速定位有问题的慢SQL,并且通过一定的治理手段进行隔离,将业务快速恢复。
针对大多数的后端应用来讲,系统的瓶颈主要受限于数据库,当然复杂度的业务肯定也离不开数据库的操作。因此,做稳做好微服务必不可少的一个部分就是做好微服务在访问数据库视角下的治理能力。目前 MSE 在微服务-数据库的治理方面支持 Mybatis、Druid、HikariCp 等组件,只要我们的框架中使用到相关组件,就可以具备以下提到的完整的治理能力。
在大促过程中,一些SQL语句处理时间比较长导致线上业务接口出现大量的慢调用,我们需要快速定位有问题的慢SQL;同时这些慢SQL最终会导致应用线程池满,从而使得应用整体不可用。我们需要有秒级的 SQL 洞察能力,可以帮助我们观察应用和资源API维度的实时数据,从而可以有效地评估系统的整体表现。
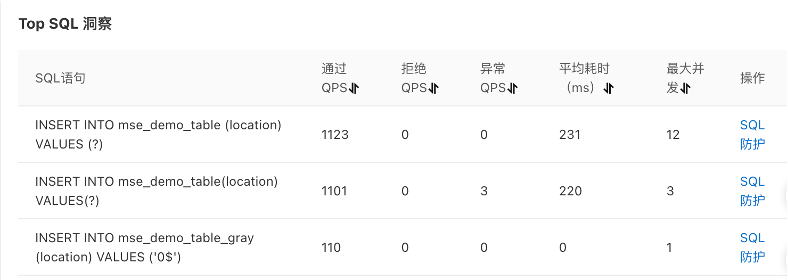
MSE 提供的SQL 洞察能力,可以分析SQL语句是否写得合理,通过SQL执行的 TopN 列表可以快速定位并发、RT、请求量过大的SQL请求。定位了慢SQL之后,我们需要有一定的治理手段进行隔离,将业务快速恢复。当流量近似稳态时:并发线程数 =QPS * RT(s) ,RT 升高,并发线程数升高,代表服务调用出现堆积。
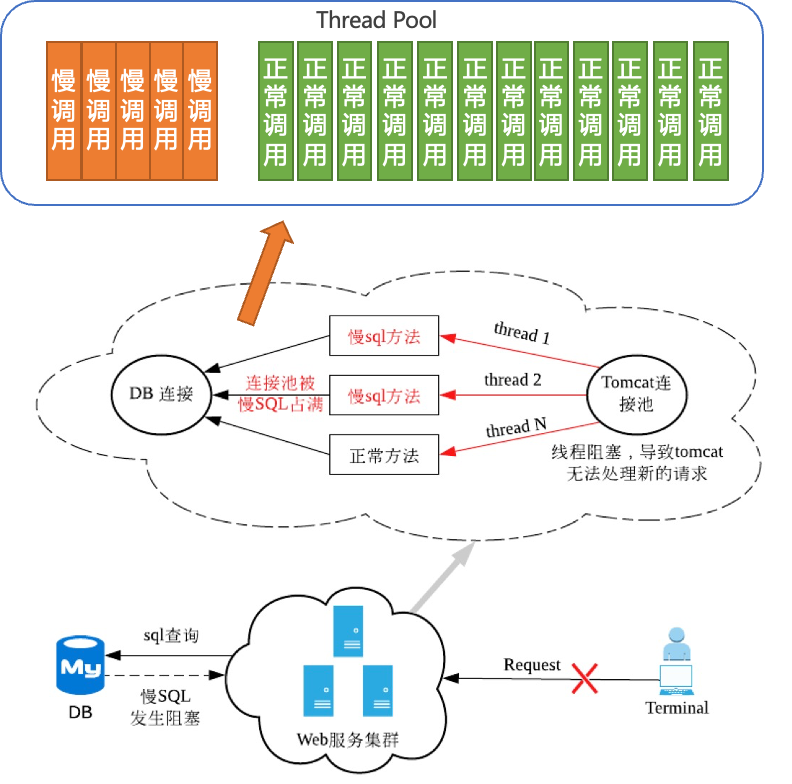
我们可以通过SQL洞察快速定位并发大的SQL,并配置服务并发隔离能力,相当于一道“软保险”,防止慢调用的SQL挤占正常服务资源,保证服务整体的稳定性。
另外还有一些突发的场景:在大促活动中涌现一批“黑马”热点商品,事先无法准确预知热点商品,无法提前预热。这些突发的热点流量会击穿缓存,使 DB 抖动甚至崩溃,影响了正常流量的业务处理。
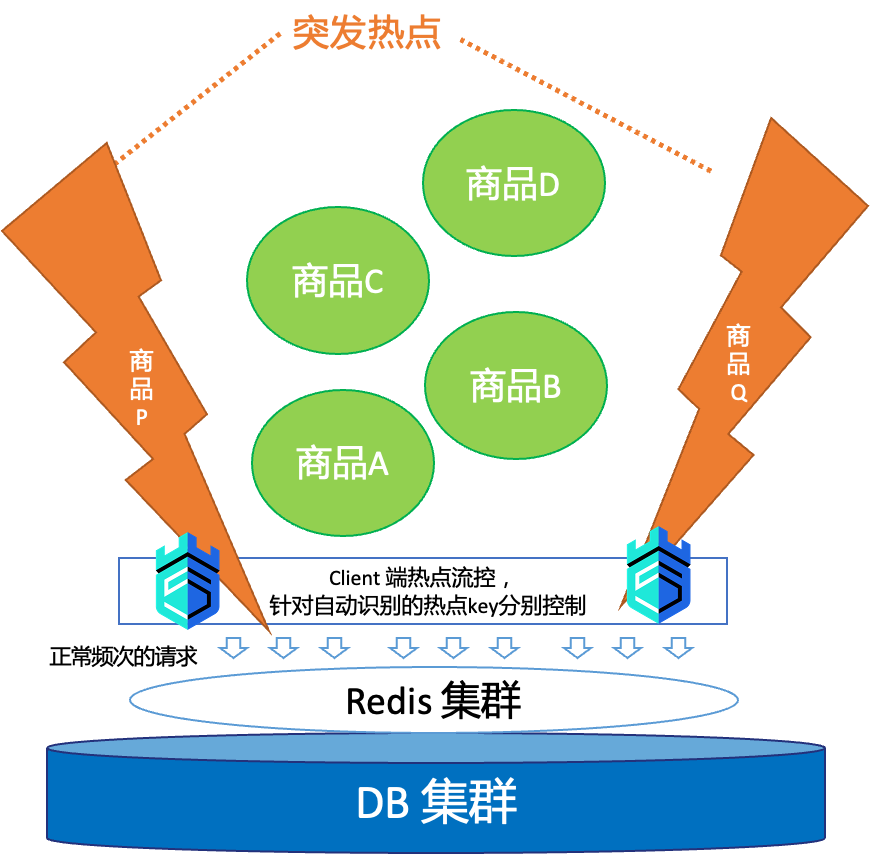
通过MSE的热点参数流控能力,自动识别参数中的 TopN 访问热度的参数值,并对这些参数进行单独流控,避免单个热点访问过载;并且可以针对一些特殊热点访问(如极热门的抢购单品)配置单独的流控值。热点限流能力支持任意业务属性的参数、我们可以在SQL层面配置规则,有效保障我们应用访问数据库时的稳定性。
考虑到热点商品引发的热点流量还会将我们的Redis缓存击穿,在微服务访问缓存的视角上,我们可以借助 MSE 缓存治理防击穿能力,只需配置单个 key 的最大访问量,MSE 可以自动识别 Rediskey 中的 TopN 访问热度的 key,并对这些参数分别进行流控,避免单个热点访问过载,影响整体。并且可以针对一些特殊热点访问(如极热门的抢购单品,有单独容量)配置单独的流控值。
总结
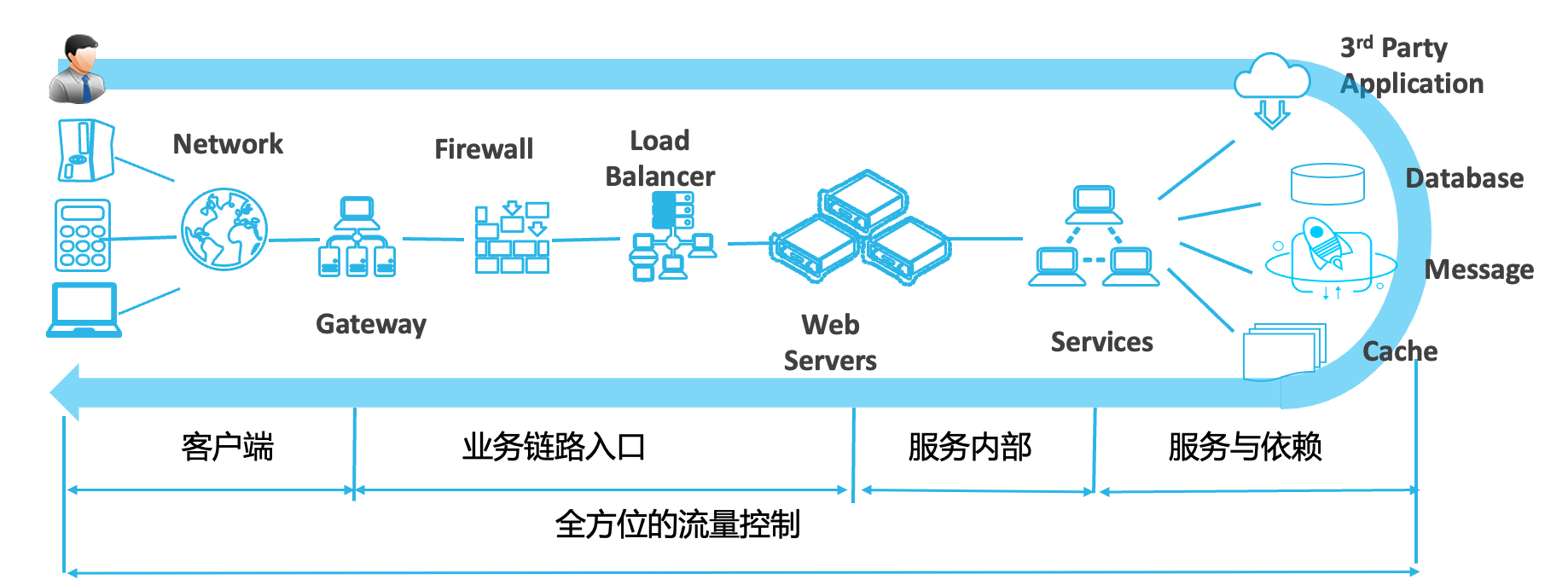
面对大促不确定的流量,我们需要做好全方位的流量控制与防护能力,确保我们的系统始终工作在预期的范围之内。首先我们需要有流量的实时监控以及水位诊断分析能力,确保我们知道当前系统所处的一个状态;在业务的链路入口,我们需要做好链路入口的容量评估以及峰值流量的限流配置、同时需要开启热点隔离能力,防止黑马商品、黑产刷单等不确定因素造成的稳定性影响;在微服务内部我们需要配置单机流控,针对微服务内部异步的流量我们可以配置流量平滑能力做到削峰填谷的效果;针对下游依赖的服务以及组件(数据库、缓存等),我们可以通过慢SQL发现以及熔断、慢调用隔离、热点探测等手段保障稳定性。
大促是一个项目,准备大促是为了将大促时将会面对的许许多多不确定风险转变成相对确定的事情,只有系统的每一个环节都做好了充足的准备,我们面对大促时才能做到胸有成竹。